AI 到底在“思考”吗?
Made by Mike_Zhang
AI 最迷人的地方,不是它真的像人一样有脑子,而是它明明不是人,却经常能说出很像人会说的话。
Intro
导言
第一次用豆包、ChatGPT 或类似 AI 工具的人,通常会经历一个很奇怪的心理过程:
- 它能把一个复杂概念讲得很清楚;
- 它能帮你改邮件、写代码、做计划;
- 它好像能理解你的情绪和语气;
- 但下一秒,它又可能把不存在的论文、餐厅、法律条文说得非常自信。
这就很割裂:
它到底是聪明,还是只是很会装聪明?
如果我们直接问“AI 会不会思考”,很容易吵成哲学问题。有人说它只是统计,有人说人脑也不就是一种预测机器吗。这个问题当然可以很深,但对普通使用者来说,更重要的是:
我应该如何理解它的能力边界?什么时候可以信它,什么时候必须查证?
所以这篇不讨论玄学,不讨论“AI 有没有灵魂”。我们先把大模型当成一个工程系统来看:输入一段文字,它如何一步步生成回答。
1. What is Token
1. “词元”是什么
很多人说大模型是在“预测下一个词”。严格一点说,它预测的不是中文里的“词”,也不一定是英文里的完整 word,而是前面说的词元。
词元可以理解为模型处理文本时的基本单位:
- 英文里,一个词元可能是一个单词,也可能是半个单词;
- 中文里,一个词元可能是一个字、一个词,或者一小段常见组合;
- 标点、空格、代码符号,也可能是词元。
你可以先不用纠结技术细节,只记住一句:
模型不是直接读“自然语言”,而是把文字拆成词元,再在词元序列上做计算。
比如你输入:
1 | |
模型看到的不是一个完整的“想法”,而是一串词元。然后它根据这串词元和前面的对话内容,计算接下来哪些内容更可能出现。
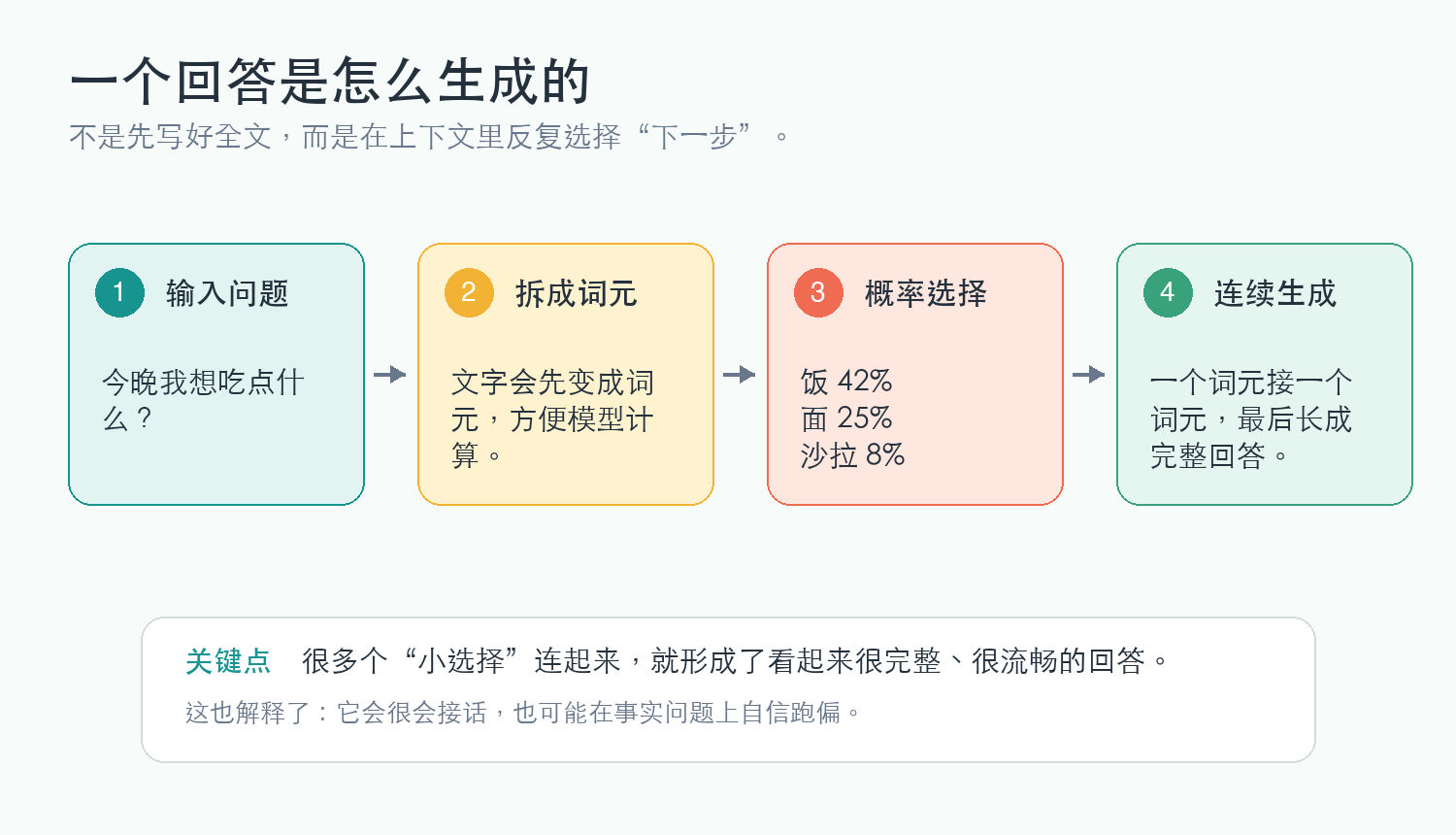
这也是为什么大模型生成回答时,并不是先在某个地方写好一整篇文章,然后复制给你。更接近的过程是:
- 看一眼上下文;
- 预测下一个词元;
- 把这个词元接到后面;
- 再看新的上下文;
- 再预测下一个词元;
- 重复很多次。
最后你看到的,就是一段完整回答。
2. Next Token Prediction
2. “预测下一个词”到底是什么意思
假设你看到一句话:
1 | |
你大概率会想到:
- 电影;
- 演出;
- 球赛;
- 展览;
- 或者别的活动。
大模型做的事情,本质上也类似。它会根据上下文,给很多候选词元一个概率。
如果你想找一个生活中的类比,最接近的其实是手机输入法的联想词。你打了前几个字,输入法会根据前文给出几个候选补全。大模型当然比输入法复杂得多,但这个例子可以帮助我们先建立直觉:它不是从脑子里“想出一个完整答案”,而是在当前上下文里不断选择更可能的下一步。
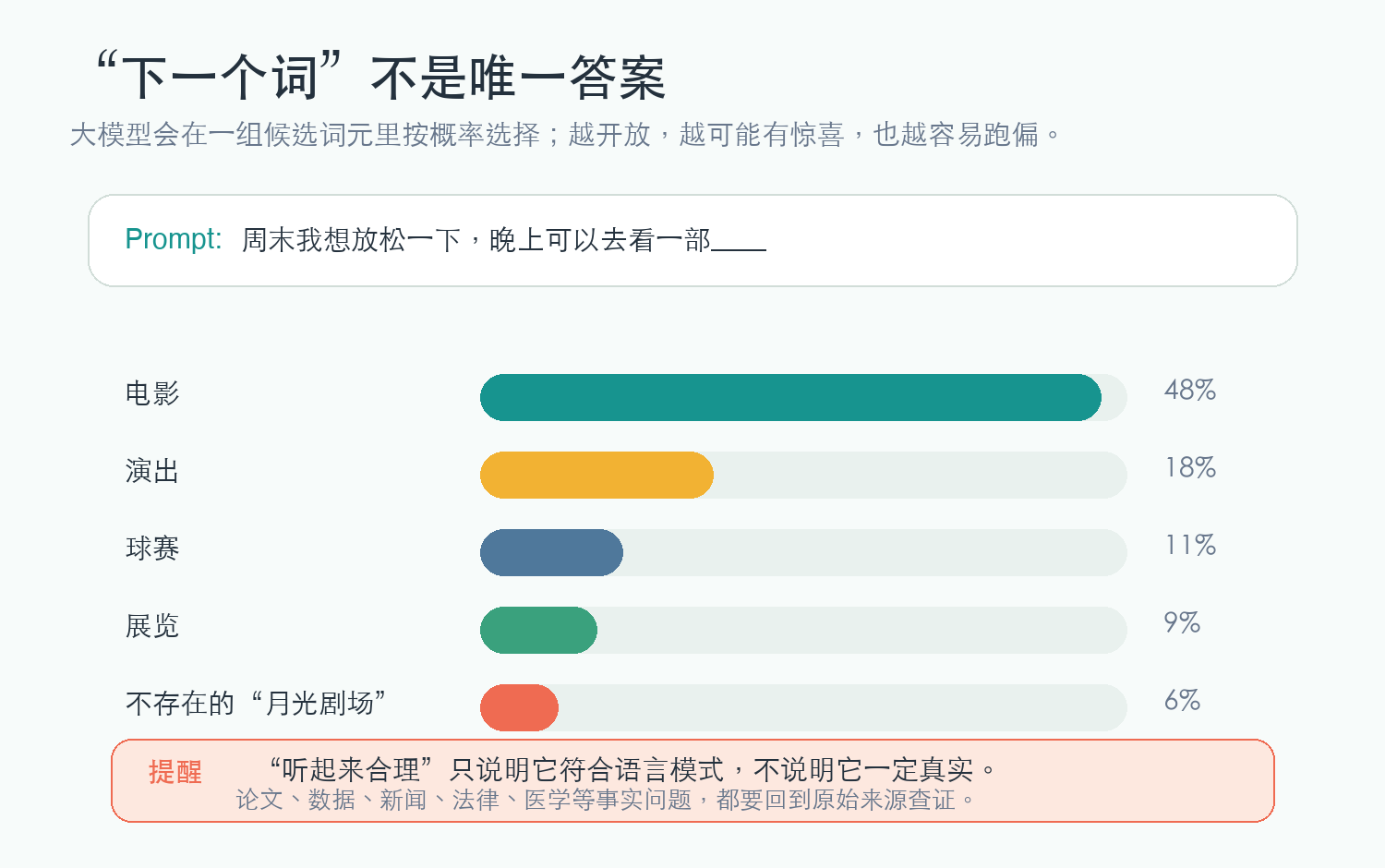
注意,这里不是只有一个“正确答案”。它是在很多可能答案中选择一个。
这就解释了几个常见现象:
2.1 为什么同一个问题,每次回答可能不一样
因为模型不是死板地查字典,而是在概率分布里生成答案。如果采样更保守,它会选更常见、更稳妥的表达;如果采样更开放,它的随机性更强,也更容易跑偏。
这也是很多工具里 temperature 这类参数的直觉含义。准确说,在支持这个参数的生成接口里,它控制的是采样时的随机程度:
- temperature 低:更聚焦、更确定,通常更稳定;
- temperature 高:随机性更强,可能更发散,也更容易跑偏。
2.2 为什么它会一本正经地胡说
从预训练阶段看,它学到的基础动作不是“我必须先证明这个事实是真的”,而是“在当前上下文里,下一个词元怎样最合理”。
后续的对齐和安全训练会努力降低这个问题,但不能彻底消除它。如果上下文里没有可靠资料,模型又被要求必须回答,它就可能生成一个听起来很像答案的答案。
这不是说它故意骗人。更准确地说:
它擅长生成合理文本,但合理文本不一定等于真实事实。
3. Why Prediction Looks Like Thinking
3. 为什么“接话”会看起来像思考
到这里你可能会觉得:
等等,如果只是预测下一个词元,那它为什么能写代码、讲物理、做计划、改论文?
关键在于:语言不是随机噪音。
我们写下来的语言里,包含了大量人类知识、逻辑关系、因果解释、写作套路、数学推导、代码模式、生活经验和社会规则。
比如:
- 菜谱里有“材料 -> 步骤 -> 火候 -> 成品”的结构;
- 论文里有“问题 -> 方法 -> 实验 -> 结论”的结构;
- 代码里有“输入 -> 处理 -> 输出 -> 错误处理”的结构;
- 邮件里有“称呼 -> 背景 -> 请求 -> 结尾”的结构。
大模型在训练时看过海量文本。它通常不是把所有文本逐字背下来,而是在训练中学到很多语言和知识的模式。当然,这不等于完全没有记忆风险:某些模型在特定条件下也可能复现训练数据中的片段,所以隐私和版权问题仍然需要严肃对待。
所以,当你问:
1 | |
它可以接出一套很像人类经验总结的流程:
- 先明确听众;
- 再确定核心问题;
- 选择 2-3 张关键图;
- 每张图只讲一个结论;
- 最后准备可能被问到的问题。
这看起来像思考,是因为它学到的语言模式背后,本来就压缩了大量人类思考的痕迹。
4. What Attention Does
4. attention 可以先理解成“看重点”
现代大模型大多和 Transformer 架构有关。Transformer 论文里最重要的机制之一,就是 attention (注意力机制)。
如果用最朴素的话说,attention 解决的是这个问题:
在当前这一步生成时,前面哪些内容更重要?
比如你问:
1 | |
模型在改写时,需要同时关注:
- “更礼貌”;
- “不要太正式”;
- “收件人是导师”;
- 以及邮件原文里每一句的意思。
attention 并不是人类的注意力,也不是意识。它更像一种计算机制:让模型在生成某个词元时,可以根据上下文中不同位置的信息调整权重。
这就是为什么上下文很重要。
如果你只问:
1 | |
模型只能猜你的目标。
如果你说:
1 | |
它就有了更多上下文,输出通常会明显更好。
5. Is It Thinking Like Humans
5. 它像人一样思考吗
我认为,不要急着给一个绝对答案。更有用的方式是拆开来看。
| 问题 | 人类 | 大模型 |
|---|---|---|
| 有没有主观体验 | 有感受、身体、记忆和生活经验 | 没有证据表明它有我们意义上的主观体验 |
| 如何产生回答 | 目标、经验、情绪、推理、社会语境混在一起 | 根据上下文生成词元 |
| 会不会犯错 | 会,而且会受偏见和记忆影响 | 会,尤其会生成看似合理但未经验证的内容 |
| 能不能推理 | 可以慢慢想、回头检查、现实验证 | 可以表现出推理步骤,但需要提示、工具或查证来增强可靠性 |
| 能不能负责 | 人需要为行动负责 | 模型本身不承担责任,使用者要负责判断 |
所以我更喜欢这个说法:
大模型不是“一个人在思考”,而是“一个语言系统在根据上下文生成看起来合理、可能有用的下一步”。
这句话听起来没那么酷,但更接近我们日常使用时需要知道的真相。
6. How Should We Use It
6. 我们应该怎么用
如果你把 AI 当成“会思考的权威”,你很容易被它带跑。
如果你把 AI 当成“完全没用的自动补全”,你又会错过很多效率提升。
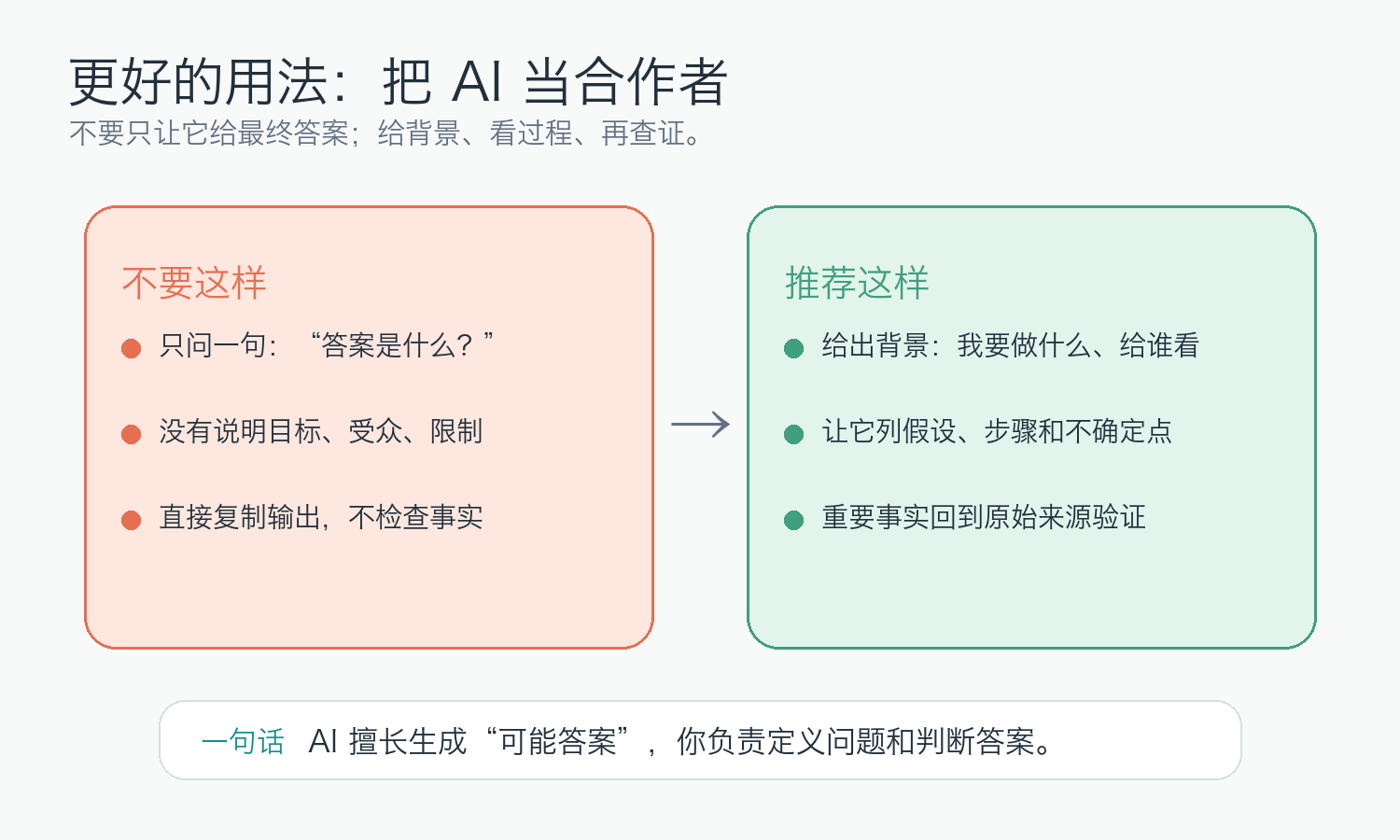
我更建议把它当成一个强大的协作者:
6.1 让它帮你生成候选答案
适合:
- 写文章标题;
- 整理演讲大纲;
- 生成学习计划;
- 改写邮件;
- 初步解释概念。
这些任务的共同特点是:你不需要它一次给出最终真理,而是需要它帮你打开思路。
6.2 让它列出中间步骤
不要只问:
1 | |
可以改成:
1 | |
这样做不是因为它的“思考过程”一定真实,而是因为中间步骤更容易让你发现问题。
6.3 对事实问题保持查证习惯
下面这些内容,不要直接信:
- 论文引用;
- 法律、医学、签证、税务建议;
- 最新新闻、价格、政策;
- 具体人名、日期、机构、数据;
- “某某研究证明”这种句子。
我的建议是:
让 AI 帮你找方向,但让原始来源帮你定事实。
7. A Small Exercise
7. 一个小练习
你可以试试下面这个 prompt:
1 | |
然后你再追问:
1 | |
你会发现,同一个问题,给不同读者、不同限制、不同目标,输出质量会差很多。
这就是我前面说的:
好问题不只是把一句话丢给 AI,而是给它足够好的上下文。
Summary
总结
大模型到底在“思考”吗?
这取决于你怎么定义“思考”。
如果你说的是人类那种有意识、有身体经验、有真实生活目标的思考,那目前的大模型不是。
但如果你说的是根据上下文组织信息、生成步骤、完成语言任务、在某些场景下表现出推理能力,那大模型确实已经非常强。
这篇文章最重要的结论是:
大模型的基础动作是预测下一个词元;它的强大来自规模、训练数据、上下文建模和 attention 等机制;它的风险也来自同一个地方:会生成合理文本,但合理不等于真实。
所以普通人使用 AI 时,最好的心态不是崇拜,也不是鄙视,而是:
- 用它打开思路;
- 给它清楚上下文;
- 要它展示步骤;
- 对事实回到原始来源查证;
- 最终判断由你负责。
References
Vaswani, Ashish, et al. Attention Is All You Need. https://arxiv.org/abs/1706.03762 (accessed June 16, 2026).
Brown, Tom B., et al. Language Models are Few-Shot Learners. https://arxiv.org/abs/2005.14165 (accessed June 16, 2026).
Carlini, Nicholas, et al. Extracting Training Data from Large Language Models. https://arxiv.org/abs/2012.07805 (accessed June 16, 2026).
OpenAI Help Center. What are tokens and how to count them? https://help.openai.com/en/articles/4936856-what-are-tokens-and-how-do-i-count-them (accessed June 16, 2026).
OpenAI API Reference. Create a model response. https://platform.openai.com/docs/api-reference/responses/create (accessed June 16, 2026).
OpenAI. GPT-4. https://openai.com/index/gpt-4-research/ (accessed June 16, 2026).
OpenAI. GPT-4 Technical Report. https://arxiv.org/abs/2303.08774 (accessed June 16, 2026).
SIL Global. What is a lexical model? https://help.keyman.com/developer/18.0/guides/lexical-models/intro/ (accessed June 16, 2026).
Keyman. keymanapp/keyman. https://github.com/keymanapp/keyman (accessed June 16, 2026).
原创文章,转载请标明出处
Made by Mike_Zhang
