System Programming Course Note
Made by Mike_Zhang
Notice | 提示
PERSONAL COURSE NOTE, FOR REFERENCE ONLY
Personal course note of COMP3438 System Programming, The Hong Kong Polytechnic University, Sem1, 2023/24.
Mainly focus on Unix, Unix Processes, Unix File System, Device Drivers, Compiler Design, Lexical Analysis, and Syntax Analysis.个人笔记,仅供参考
本文章为香港理工大学2023/24学年第一学期 系统编程(COMP3438 System Programming) 个人的课程笔记。
Unfold Study Note Topics | 展开学习笔记主题 >
0 Background for System Programs
0.1 Definition
- An operating system is an intermediary between a computer user and the hardware
- Make the hardware convenient to use
- Manages system resources
- Use the hardware in an efficient manner.
0.2 Types of OSs
Batch
- Single CPU
- User submits large number of tasks at one time
- OS decides what to run and when
- Back-to-back single tasking
- One-single task is running on the CPU at any time
- Need to wait for a task to finished before the next task can start
- Only runs in sequential order, not parallel
- Not interactive, need to wait for the whole batch to finish (pressing on a key, need to wait)
Time-Sharing
- Multiple users connected to a single CPU
- Many user terminals
- Multiple tasks run simultaneously using time-sharing, giving users the feeling of having multiple dedicated CPUs running in parallel
- More responsive to users (fake feeling to user), like TDMA, Round-Robin scheduling
Parallel
- N-CPUs in one computer
- simultaneously may be fake Parallel
- Multiple CPUs closely coupled to form one computer
- Higher throughput (multiple tasks running at same time) and better fault tolerance
- Each CPU can be running batch tasking or time-sharing multitasking
Distributed
- integrated multiple complete computer systems into one chip
- Multiple CPUs loosely coupled via networking
- Not flexible to actual demand
- May be rented to users on demand
- Like: grid computing, could computing
Real-time
- Very strict response time requirements
- Periodical tasks, every job of a task has a strict deadline
- Used in aviation, military, etc.
- In short time, need to finish the sensing, computing, and actuating, not miss the DDL
- TO guarantee the the Real-time, very hard, very expensive.
0.3 Single Tasking vs. Multitasking
Single Tasking System
- Each task, once started, executes to its very end without any interruption from other task(s).
- Simple to implement: sequential boundaries between tasks, and resource accesses.
- Few security risks
- Poor utilization of the CPU and other resources
- Example: MS-DOS
Multitasking System
- Very complex
- Serious security issues
- How to protect one task from another, which shares the same block of memory
- Much higher utilization of system resources
- Support interactive user/physical-world interface
- Example: Unix, Windows NT
0.4 Hardware Basics
OS and hardware closely tied together
Basic hardware resources:
- CPU
- Memory
- Disk
- I/O
0.4.1 CPU
CPU controls everything in the system
- It is involved in any work needs to be done
Most precious resource
- This is what you are paying for
- Users would usually prefer high utilization (from useful work)
Only one process running on a CPU at a time* (single-core)
Millions or even billions of machine instructions per second
- Getting faster all the time
0.4.2 Memory
Limited capacity
- Never enough, and expanding over the years
Temporary (volatile) storage
Electronic storage
- Fast, random access
- Not sequential, not like the tape
Any process to run on the CPU must first be loaded into memory
0.4.3 I/O
Many I/O devices
- Keyboard, mouse, monitor, printer etc.
Most I/O devices are painfully slow
Need to find ways to deal with high I/O latency
- Like multiprogramming
0.5 Protection and Security
OS must protect itself from users
- Reserved memory only accessible by OS
OS may protect users from one another
- Use hardware through system calls, constrained by OS routines
0.6 Interrupts
Modern OSs are event driven
Event is signaled by special hardware signal sent to the CPU
Two types of events
- Hardware Interrupts: caused by external hardware, can occur at anytime
- Software Interrupts (aka Exceptions, Traps): caused by software, synchronous to CPU clock
0.6.1 Interrupt Philosophy
- Use an interrupt table and special hardware to redirect CPU execution
- By the end of interrupt handling, the CPU can resume the interrupted process
0.6.2 Interrupt Table
Large array of addresses indicating what code to run (interrupt routine) for a given interrupt
Each interrupt has a corresponding number associated with it
- On Intel processors this is from 0 to 255
- This gives fixed size interrupt table
Use the interrupt number to index into the array to find out what code to run (interrupt routine)
0.6.3 Hardware to Support Hardware Interrupt
Programmable Interrupt Controller (PIC)
- Connected to I/O devices via Interrupt Request Lines (IRQ) or Bus (e.g. PCI Express)
PIC connected to the CPU by a special line or bus
CPU <==> PIC <==> I/O devices
<==> can be special signals via dedicated wire lines (IRQ), or special sequences of back-and-forth messages via bus(es) (virtual IRQ)
0.6.4 IRQ System Architecture (Conventional)
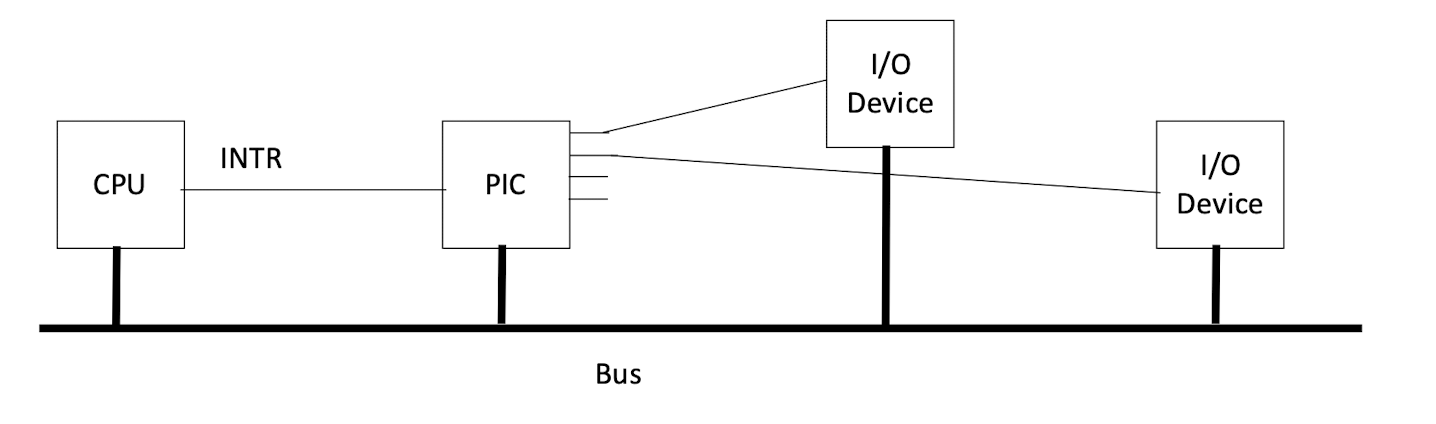
Example of Message Passing Virtual IRQ:
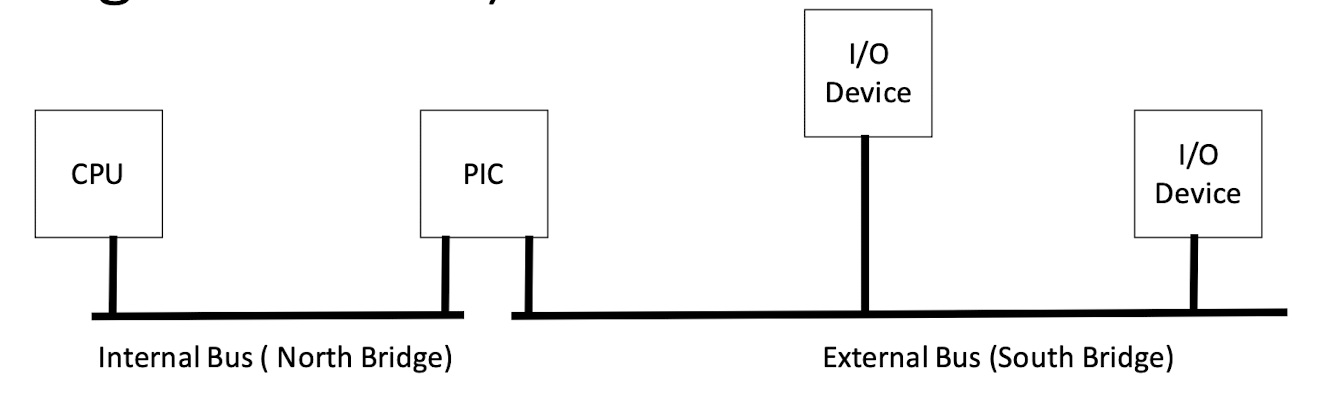
Hardware Handling of Interrupts (Conventional IRQ as an Example):
After each instruction executes, CPU checks if the IRQ pin voltage has been raised If so
- Sets the system into kernel mode (if not already there)
- Determine interrupt number (from PIC or instruction)
- Read appropriate interrupt table entry
- Special register contains base address of interrupt table
- Each entry in table is fixed size so easy to calculate where to
- look in memory (e.g.
memloc = iptr + 8 * intNum)
- Saves the process state to the stack (particularly, the program counter)
- Saves error code to stack (if it exists) (Program Counter)
- Loads the program counter with the value stored in the interrupt table
- This starts the CPU executing in the interrupt routine
0.7 Peripheral Devices
- Input Devices
- Output Devices
- Storage (memory is usually not considered as a peripheral)
0.7.1 Peripheral Devices for Embedded Systems
Embedded Systems: computer systems that do not look like a conventional computer systems, e.g. mobile devices, devices tightly coupled with the physical world (i.e. cyber-physical systems).
- Input Devices: Sensors
- Output Devices: Actuators
0.7.2 Historical Perspective
1. Application built on top of hardware
1 | |
Problems:
- Complexity: have to know the tedious low-level programming details of the hardware
- Inflexibility: when the hardware changes, the application has to change with it.
2. Application built on top of OS
1 | |
Ideal:
- OS application programming interface (API) hides the complexity and heterogeneity of hardware programming.
- As long as the OS API remain the same, the hardware can change.
Design goal conflict:
- Full exploitation of hardware features
- Versus
- Full platform independence and simple API
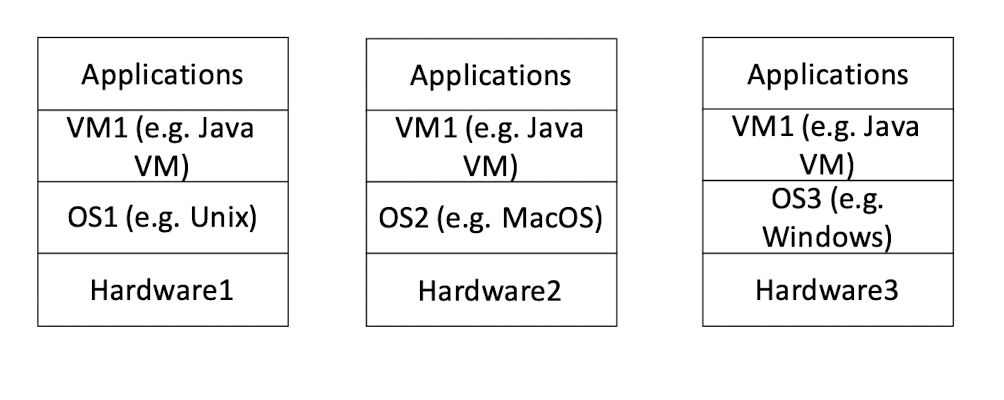
Want to exploit more features of the hardware: Application + OS
Want to be more platform independent and simpler API: Application + Virtual Machine (VM)
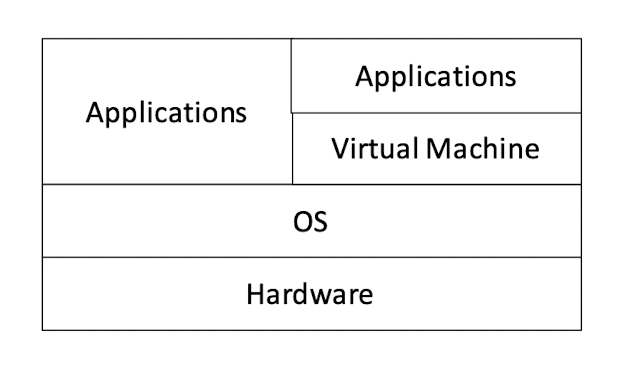
Virtual Machine (VM) can hide the heterogeneity of OS APIs
As long as the VM API remain the same, the OS (and hardware) can change, and the application can remain the same.
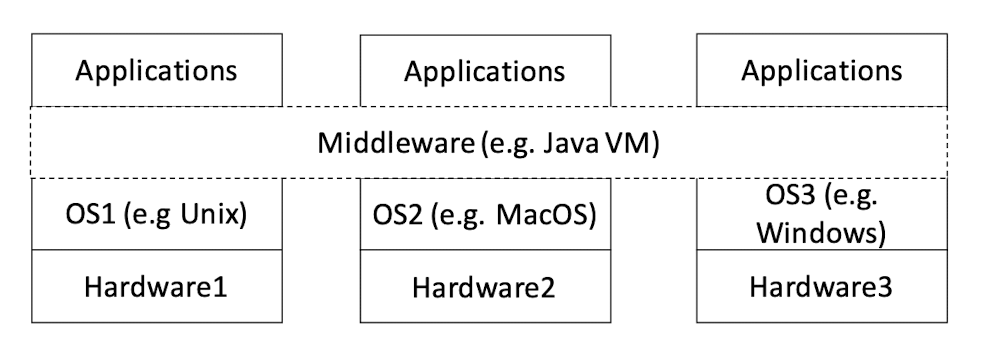
Middleware API (VMs can also be regarded as a kind of middleware) hides the heterogeneity of OS APIs
As long as the Middleware API remain the same, the OS (and hardware) can change, and the application can remain the same.
1 Overview of Unix
1.1 Unix
“Unix is a family of multitasking, multi-user computer operating systems that derive from the original AT&T Unix, development starting in the 1970s at the Bell Labs research center by Ken Thompson, Dennis Ritchie, and others.” — Wikipedia
1.1.1 Unix family tree
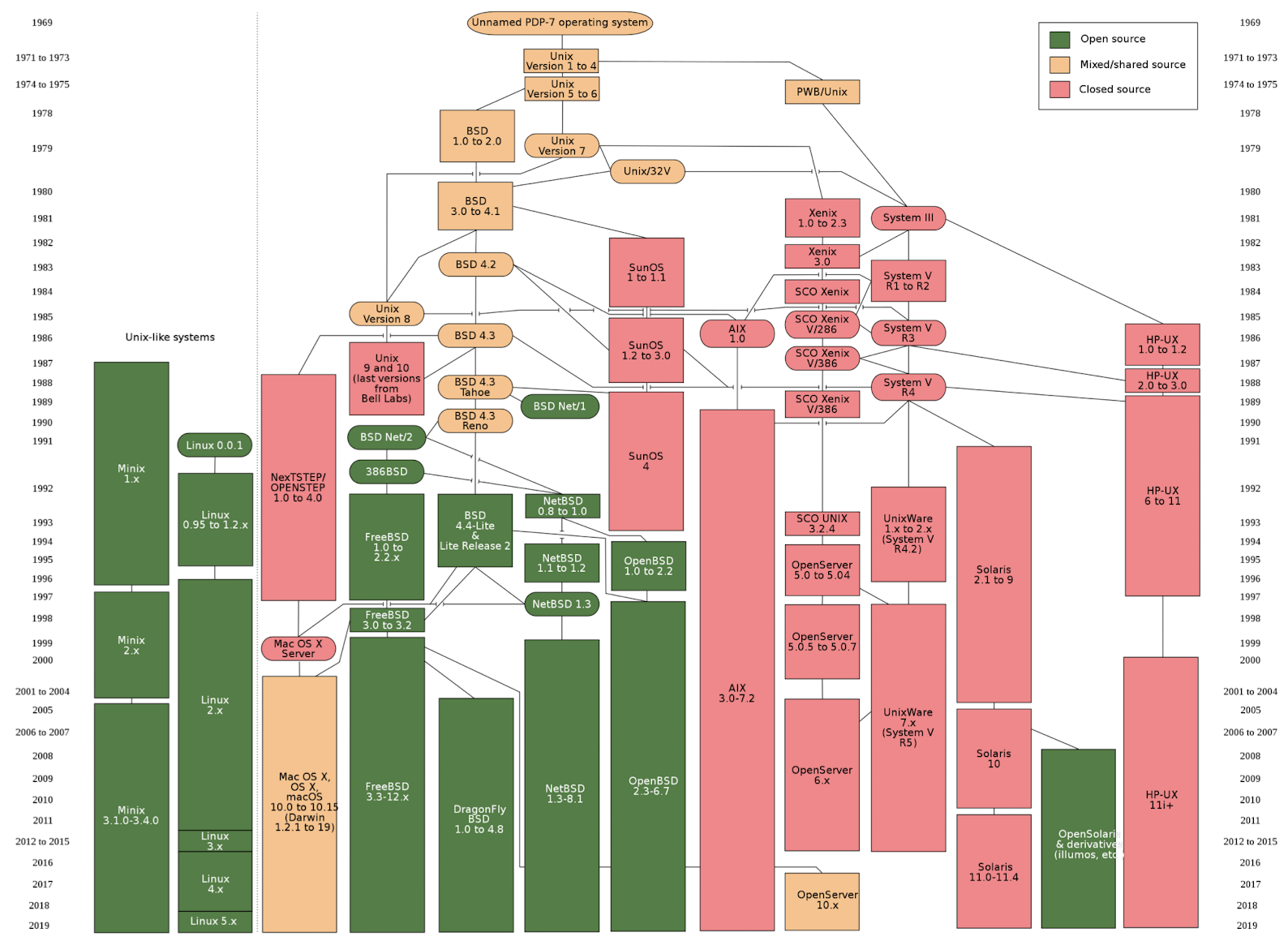
- Originally written in assembly
- In 1973, v4 was mostly rewritten in C, making it portable
- Portable Operating System Interface (POSIX) to unify Unix APIs
1.2 The Unix Philosophy
- Modular design
- A collection of simple tools, with limited well-defined functions
- File system
- Inter-process communication
- The tools can be easily composed (via >, >>, <, |, ``) by a shell to accomplish complex tasks
1.3 What makes up Unix
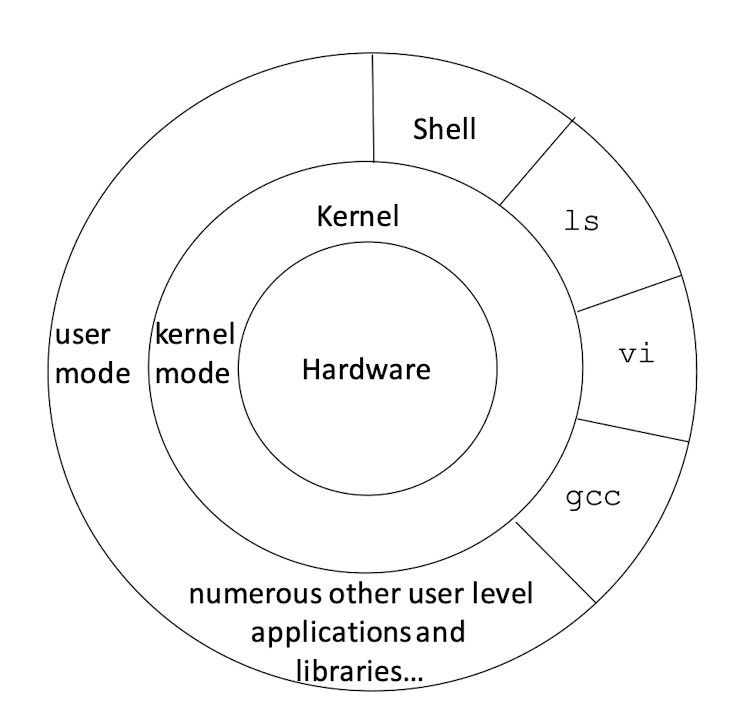
- Kernel is the heart of the OS. It interacts with the hardware and conducts key functions of the OS, such as memory management, task scheduling, file management.
- Shell is the utility that interacts with the user via command line. When you type a line command from your terminal input device, the shell interprets the command and executes the intended program (or composition of programs). The shell commands have a standard syntax. C Shell, Bourne Shell, and Korn Shell are the most famous shells, which are available in most Unix variations (Linux commonly uses the Bourne Shell – like bash).
- Commands and utilities support various day-to-day activities, e.g.,
ls, vi, gcc, cp, mv, cat, grep. - There are over 250 standard commands and utilities plus numerous other 3rd party software. Most commands and utilities come with various options. These build up a huge vocabulary to express all kinds of needs for users.
- Files and directories organize data. All files are organized into directories, and directories are further organized into a tree-like structure called the file system.
1.4 Unix Kernel
The kernel is the core of the Unix OS.
- Controls the hardware and performs various low-level functions.
- A collection of software modules that run in the privileged mode (full access to system resources).
- Main duties:
- process scheduling and management,
- inter-process communication,
- memory management,
- file management,
- network stack management,
- date and time services,
- system accounting,
- security,
- device management,
- interrupt and exception handling.
1.5 Unix Kernel and System Calls
Other parts of the Unix system, as well as user programs, request the kernel for various services through system calls.
- A system call is an entry point into the kernel, typically packaged as a function call, as part of the OS API.
- Inside the function call, the typical implementation:
- A software interrupt (trap) switches the CPU hardware to the kernel mode.
- Execute kernel routines.
- Return the kernel mode first, to the scheduler, to check the schedule of other tasks.
- Switch back (via scheduling) to the user mode to *resume the user application.
1.6 Unix Libraries
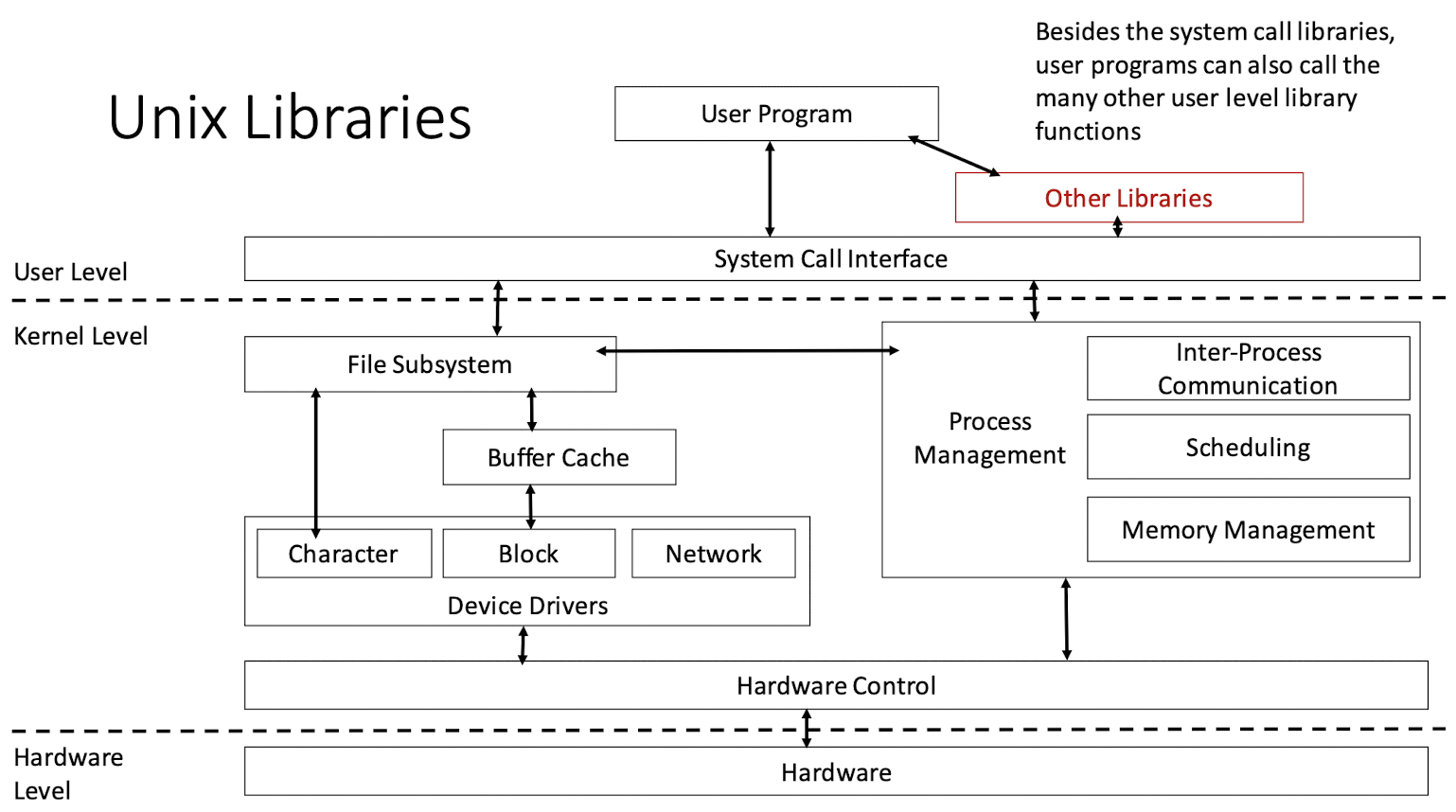
1.7 Unix Commands and Utilities
- A large set of tools for various basic user-level functions
- A vocabulary and a grammar, to combine basic user level functions to nearly arbitrary sophisticated functions
- Not part of the kernel, but a part of the OS
- Typically accessed via the Shell
1.8 Unix Shell
- A powerful command interpreter (a user level application) for Unix – accepts user text commands and carries them out
- Can combine various user-level applications to serve more sophisticated functionalities
- Multiple shells for the same user, or multiple shells for multiple users can co-exist
1.9 Unix Device Drivers
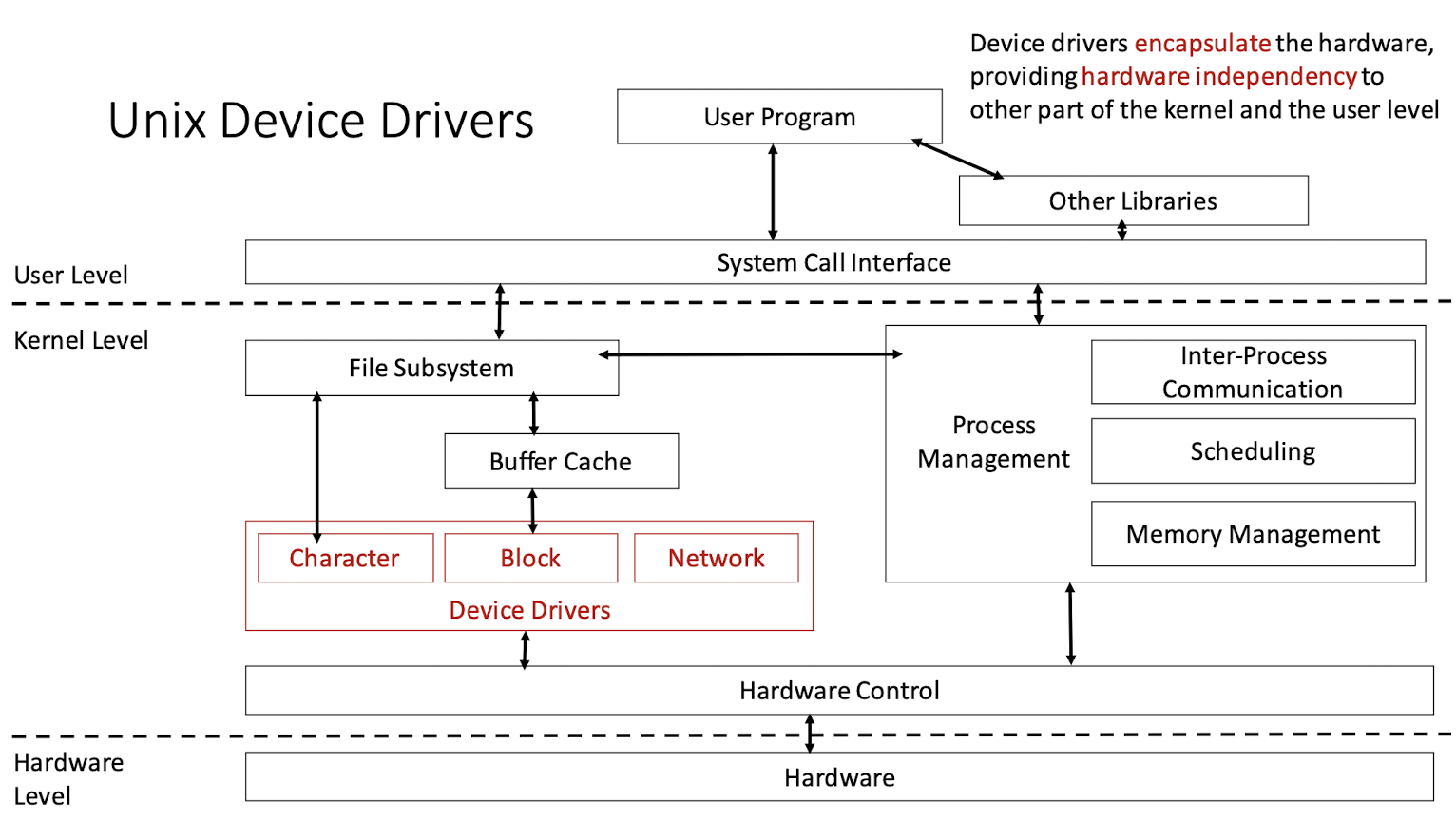
Device drivers encapsulate the hardware, providing hardware independency to other part of the kernel and the user level
- Character devices: looks like a file, read write it.
1.10 Features of Unix
- Portability
- Multiuser Operation
- Multitask Processing
- Hierarchical File System
- Powerful Shell
- Pipes
- Networking
- Robustness
1.11 Unix is Portable
Unix is a relatively hardware independent OS. Various mechanisms (device driver, various C program interfaces inside the kernel and to the user level) are designed to encapsulate the hardware specifics, facilitating porting between hardware platforms.
One key to the portability is the device drivers, specific modules that encapsulate the hardware details from the other parts of the kernel and the user level.
1.12 Unix supports multi-users
Unix is a multi-user, multi-tasking OS.
Multiple users may run multiple tasks concurrently. This is very different from conventional PC OSs, such as MS-DOS or Windows, which allows concurrent execution of multiple tasks, but not multiple users.
1.13 Unix supports multi-tasking
Unix is a multi-tasking OS.
Even for a single user, time sharing can still support multi-tasking.
Unix has some programs, such as the system-wide accounting programs, that automatically run from time to time.
Unix supports background processing, which allows a user to initiate a task “in the background” and then proceed to other activities. Unix time shares between the front-end commands and background jobs.
Unix allows the creation of new tasks from an existing task.
1.14 Unix has a hierarchical file system
Unix files are organized into separate directories.
Directories are themselves organized into a tree-like structure. There is one master directory, the so-called root directory, from which various sub-directories branch off.
The hierarchical structure offers a maximum flexibility for grouping information in a way that reflects its natural structure.
- A single user’s data may be grouped by activity
- Data from many different users can be grouped according to corporate organization
- As a result, stored data is easier to locate and manage
1.15 Unix shell is powerful
The Unix shell supports a number of convenient features, such as:
- Redirection of application input and output, e.g.
ls > myfiles - The ability to manipulate groups of files with a single command.
- Executing a sequence of commands stored in a text file, called a “shell script,” allowing us to build our own commands, which may be parameterized.
- Being used as a programming language that provides string-valued variables and control flow primitives including branching and iteration
1.16 Unix’s pipe is novel
One of the most famous Unix features is pipe.
A pipe passes the standard output of one command directly to another command, to be used as its standard input, e.g. who | sort.
- Allows any number of commands to be connected in a sequence, and automatically handles the data flow from one program to the next.
- Allows the combination of several simple programs to perform more complex functions.
- Eliminates the need for new software development.
Difference between pipe and redirection:
- <> online has one command
- piping has multiple commands
1.17 Unix supports networking
Networking support is built into the Unix system.
Supports TCP/IP protocols, and provides a new OS abstraction, the socket, that allows application-level programs to access the Internet.
The socket abstraction acts as an interface between application level programs and the underlying TCP/IP protocols.
1.18 Unix is robust
When encountered an error, a Unix program does not abort. Instead, the program receives a returned value indicating an error condition, and it is up to the program to check for the error and handle it.
Typically, a returned error value is negative if the return type is int, or a NULL if the return type is a pointer.
You can call the C library function perror() to output a message string to the standard error file, to further explain the error.
Example: the use of the open system call.
1 | |
The following output might be produced if my.file does not exist:
1 | |
1.19 Unix Variants
1.19.1 Linux
Strictly speaking, Linux source code is not inherited from the Unix family tree. Linux is a Unix-like OS.
But if you consider Portable Operating System Interface (POSIX) standards, then Linux can be regarded as a kind of Unix.
“Linux is a Unix clone written from scratch by Linux Torvalds with assistance from hackers across the Net” — official Linux kernel README file
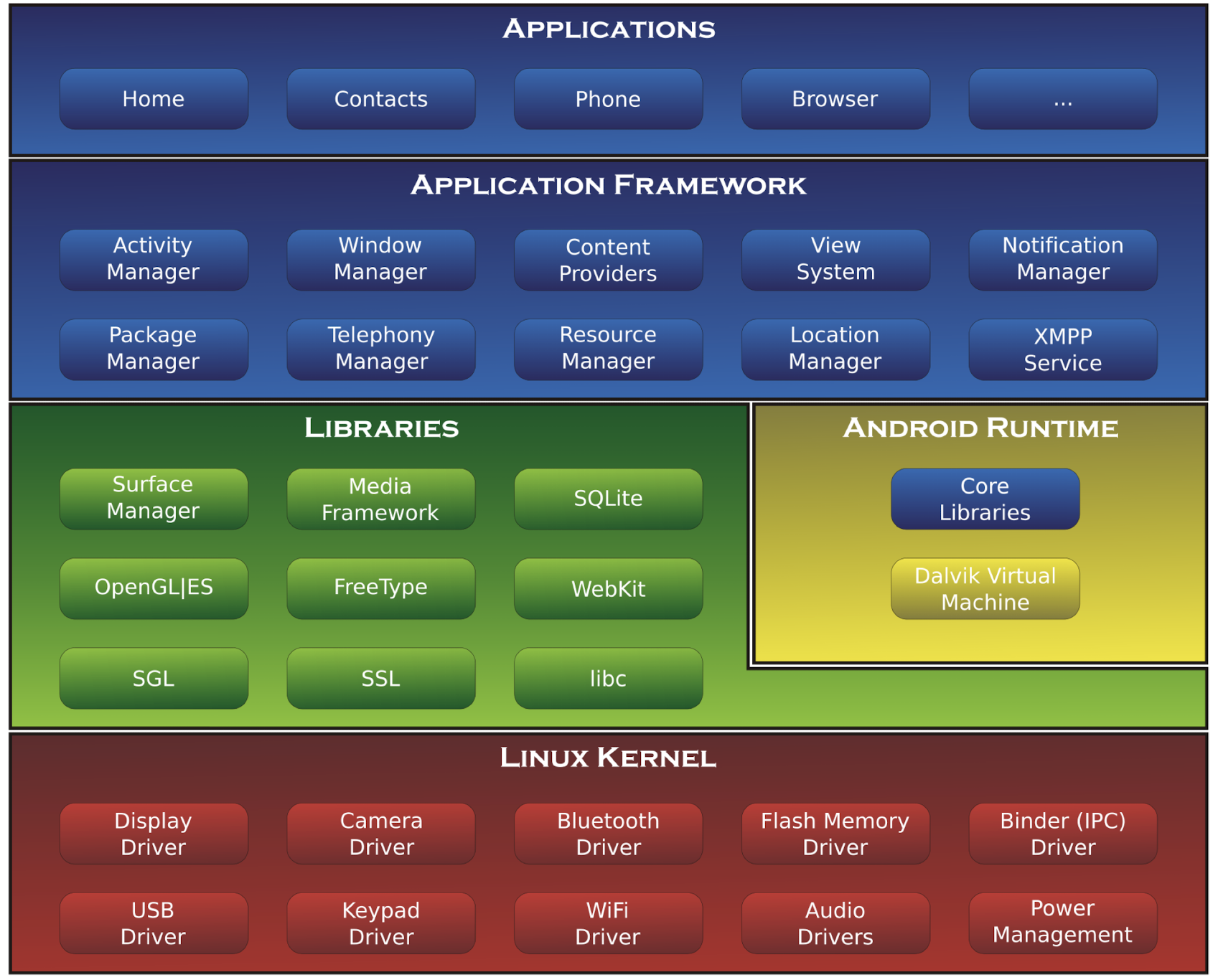
1.19.2 Android (based on Linux)
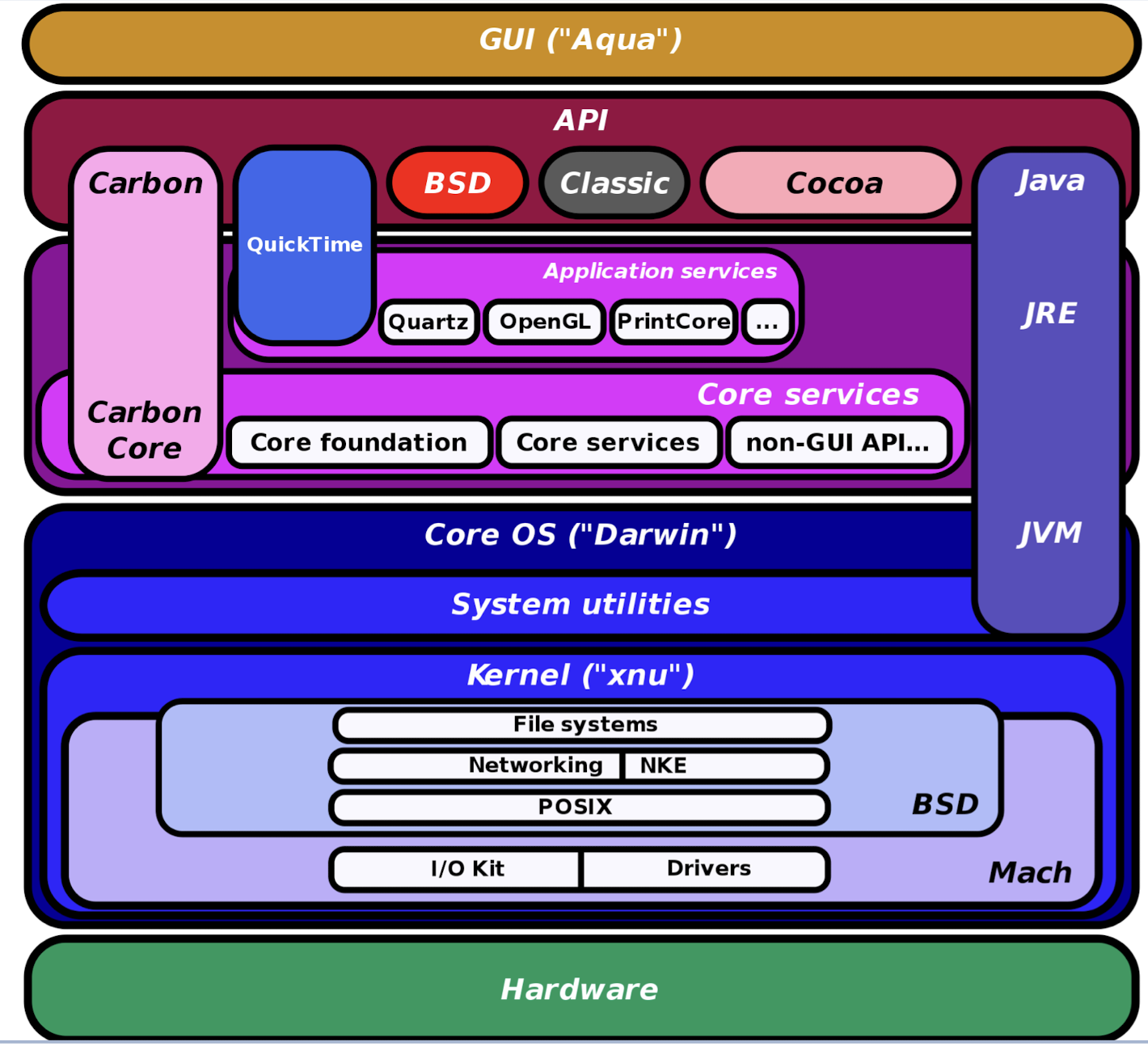
1.19.3 Mac OS X
2. Unix Processes
- What is a process?
- What does a process look like in the system?
- When is a process created? By whom?
- How is a process created? In how many ways?
- When does a process stop? Can we wait for a process to die?
- What is a process called if it never dies?
2.1 Unix Processes: common definition
A process is an instance of a program in execution (the execution of the program has started but has not yet terminated).
Process is dynamic while the program is static.
A process is the basic unit for competing the resources. In particular, it is the basic active entity to CPU scheduler.
2.2 Unix Processes: how to understand it?
State of a computer at clock tick (i.e. discrete time) i:
$S(i)$ = (register 1’s value, register 2’s value, …, 1st memory byte’s value, 2nd memory byte’s value, …, 1st hard disk byte’s value, 2nd hard disk byte’s value, …, peripheral 1’s register 1’s value, peripheral 1’s register 2’s value, …).
State of an execution $e$ at clock tick $i$:
$s(e, i)$ = (resources used by e at i, state of the resources used by e at i).
A process is the time sequence of ${s(e, i)}$, where every two consecutive states $s(e, j)$ and $s(e, j+1)$ have causal relationship determined by the program logic and the OS.
2.3 Unix Processes: how to turn a program into a process?
- The program is read into memory.
- A unique process ID is assigned.
- OS kernel creates a process structure instance to record information related to this process.
- Necessary resources to run the program are allocated.
- The initial state $s(e, 0)$ is set, which will trigger its next state $s(e, 1)$, which will trigger its next state $s(e, 2)$, … determined by the program logic and the OS.
2.4 Unix Processes: notion of threads (lightweight processes)
State of an execution e at clock tick i:
$s(e, i)$ = (resources used by e at i, state of the resources used by e at i).
A process is the time sequence of ${s(e, i)}$, where every two consecutive states $s(e, j)$ and $s(e, j+1)$ have causal relationship determined by the program logic and the OS.
In older OSs, each process has its exclusive set of resources, even for processes that are related (e.g. sharing data). This is wasteful.
Modern OSs propose the notion of “threads”. Threads are processes that have shared resources, typically created by the same ancestor process. Because the resource allocation is more thrifty, threads are also called “lightweight processes”.
2.5 Unix Processes: notion of threads (lightweight processes)
Multi-processes (fork()) vs. multi-threads (pthread,sharing global variables)
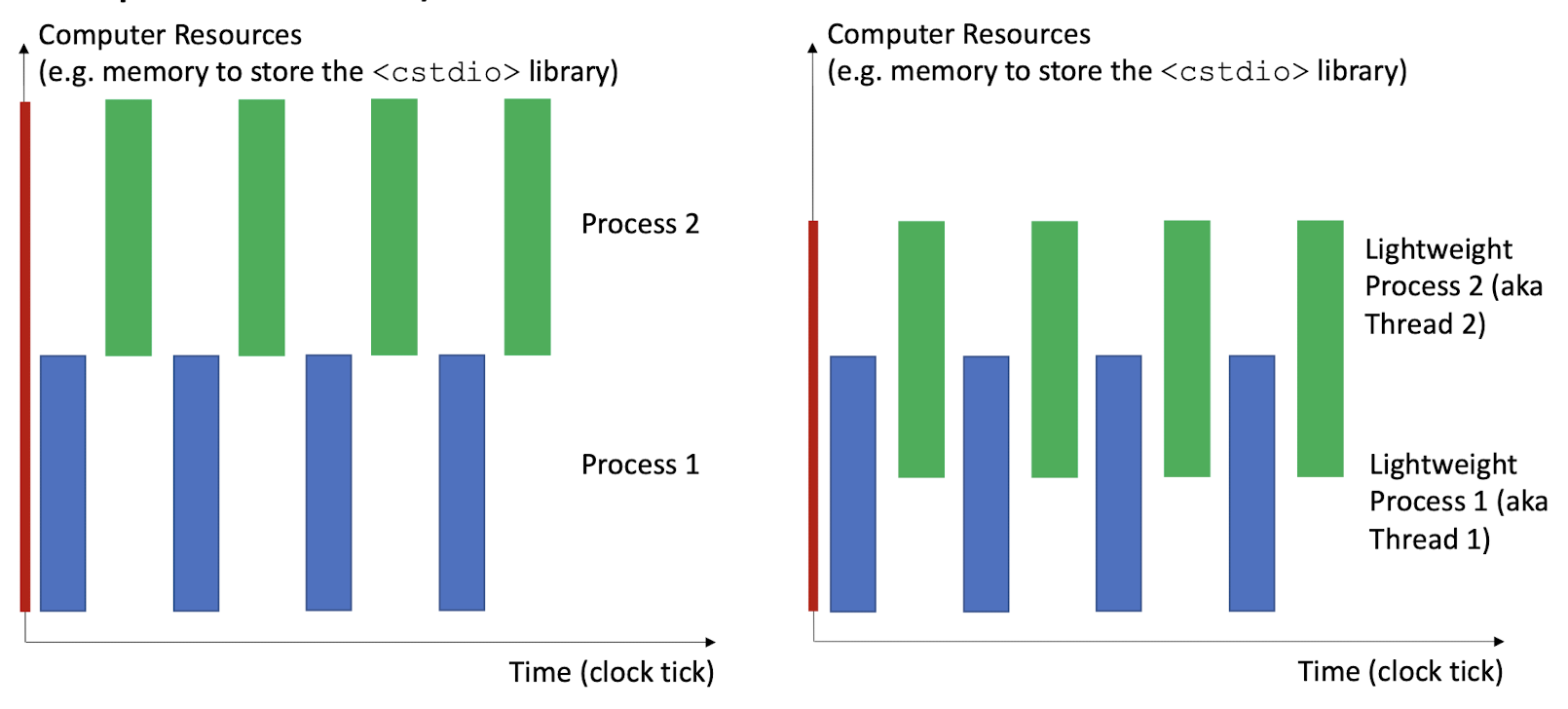
- However, in the kernel, all are multi-thread, but make the user has a fake feeling about multi-processes.
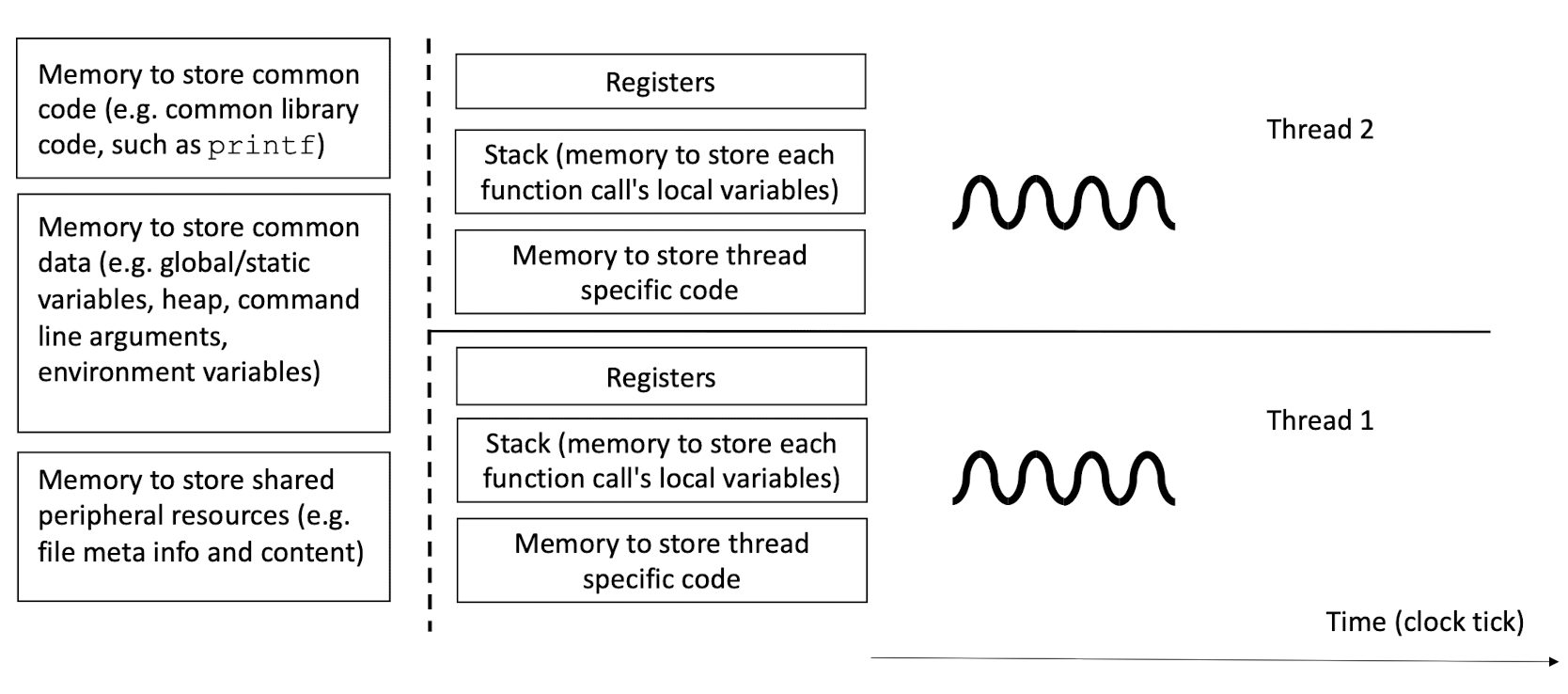
2.6 Unix Processes: what resources to share and what not to share?
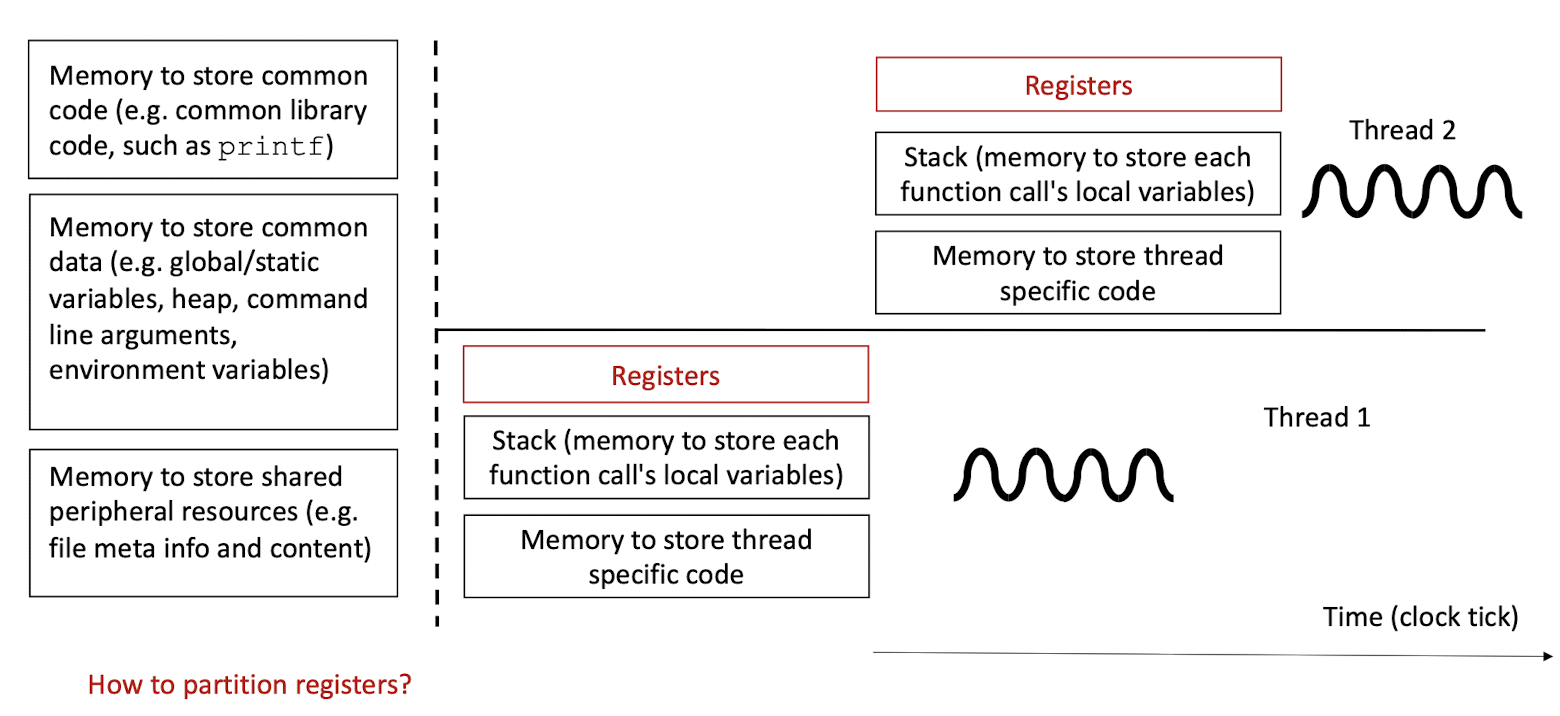
- Partitioning the Registers temporally
2.7 Unix Processes: thread realization and programming interface
All the previous slides on thread are just conceptual guidelines.
And at the user level, there is a de facto standard C thread programming interface: PThread (POSIX Thread).
But different OSs (even OSs belonging to the Unix family) have different ways to realize the concepts and the PThread programming interface.
For example, modern Linux no longer differentiate threads and processes, all are realized as copy-on-write (COW) processes (aka “task”). For example, every time the parent thread creates a new thread, in the Linux implementation, there is a parent COW process creating a child COW process.
2.8 Unix Processes: Process Image
Process Image
A snapshot of the current state of the process is called a process image, aka the process execution environment image, or (mainly refers to the memory part of the image) address space image.
Most important is to switch the
registervalues (PC,basefor page table are important)
2.9 Unix Processes: process management
Besides its image, a process has its corresponding meta data (in kernel) for the OS to manage it, e.g. process ID.
A Unix OS typically maintains a hierarchy of processes related by parent-child links:
- the process that requests to create another process is called the parent process,
- and the created process is called the child process.
Parent process can create multiple child processes, forming a tree-like structure. The first process created by the OS during system boot is called the init process, which serves as the root of the process hierarchy.
The process management operations include process creation, process termination, and process synchronization and communication.
2.10 Unix Processes: Common Process Management Meta Info
Process ID – integer PID
Parent process ID – an integer PPID
User process ID – an integer UID
In Unix, each user has a unique user ID.
Each process is associated with a particular user called the owner of the process, which executes the program.
The owner has certain privileges with respect to the process.
Use getpid, getppid, and getuid to determine the ID of the current, parent, and the owner.
Demo Task 1:
ps is the short for “process status“.
pslists your current processes in the current terminal.ps –alists more processes, including ones being run by other users and at other terminals (but not including the shells)ps –lprints longer, more information lines, including UID, PID, PPID, process status, etc.ps -Alist all the processes on the system.- 0: the process is in the kernel
- 1000: created by the user
2.11 Unix Processes: Related Portable OS Interface (POSIX) APIs
Demo Task 2
1 | |
in man:
- Shell commands:
User Commands - C system API:
Linux Programmer's Manual
The Portable Operating System Interface (POSIX) is a family of standards specified by the IEEE Computer Society for maintaining compatibility between OSs.
To create a new process, typically a parent process calls the fork() system call, which traps into the kernel and:
- Allocates a new chunk of memory and kernel data structure.
- Copies the parent process’s image and kernel data structure into the new process’s, with needed modifications (e.g. PID, PPID).
- The shared data is not duplicated.
- Adds the new process to the set of “Ready” processes.
- Returns control back to both processes (by setting the program counter in the respective image, and leaving the processes to the scheduler).
- Return twice: once to the parent, once to the child.
Demo Task 3
In-class demo: forking a process
1 | |
Example output:
1 | |
- Transient situation
- check
sleep()system call:man -S 3 sleep - check
sleepshell command:man sleep
Both the parent and child process continue execution at the instruction after the fork().
But creation of two completely identical processes would not be very useful. We want the parent and child to execute different code.
But how can the parent and child distinguish themselves?
The value returned by fork() allows the parent and the child to distinguish themselves.
fork():
- returns 0 to the child
- returns the child’s PID to the parent
Then the child can call exec family of functions to execute other programs; it can also retain and keep using the (copied) program code of the parent process.
Demo Task 4
1 | |
- The value of the assignment expression is the value assigned to the variable.
Demo Task 5
- In-class exercise: forking a chain of processes
1 | |
Demo Task 6
- In-class exercise: forking a fan of processes
1 | |
wait() system call
After fork, both parent and child proceed independently. If a parent wants to wait until the child finishes, it executes wait or waitpid system call:
1 | |
In general, the wait system call causes the caller process to ==pause== until a child terminates or stops, or until the caller receives a signal.
The call returns right away if the process has no children or if a child has already terminated or stopped but has not yet been waited for.
If a parent process terminates first without waiting for its children, the children processes become orphan processes.
The stat is a ==pointer== to an integer variable that stores the exit status (exit(0), exit(-1)) of the child.
It is almost always poor programming practice to create orphaned processes, because there may be no indication to the user there are still processes running. If one of the orphaned processes gets into an infinite loop, the user may be completely unaware of it; and the orphaned process may continue execution even after the user has logged out.
If wait returns because a child terminated, the return value is positive and is the PID of that child.
Otherwise, wait returns –1 and set errno.
errno == ECHILDindicates that there were no unwaited-for child processes, all children all are terminated;errno == EINTRindicates that the call was interrupted by a signal;
Demo Task 7
In-class demo: wait() example with process chain
Only one forked process is a child of the original process.
1 | |
- Use the macro
WEXITSTATUS()to extract the exit status as a byte-1as255
The fork system call creates a copy of the calling process. However, many applications require the child process to execute code different from the parent’s.
The exec family of system calls provides a facility for overlaying the calling process with a new executable module. exec loads a new executable and arguments into the process image and calls the main(…) function.
If successful, exec never returns; the calling process is ==completely overlaid by the new program== and is started from its beginning.
The traditional way to use the fork-exec combination is to have the child execute the new program while the parent continues to execute the original code.
Demo Task 8
In-class demo: execl example on creating a process to run ls -l
1 | |
Demo Task 9
In-class demo: execvp example on creating a process to run ls -l
1 | |
In-class demo: execle example on creating a process to run ls -l
1 | |
1. string in C
- One character takes One Byte
char * pis a tring- If we write
"AB"in C, it will automatically add aNULLat the end, so that"AB"takes Three Bytes.
2. const in C
1 | |
char * pis a string the character pointer, p, points toconst char * pmeans the string is a constantchar const * pmeans also the string is a constantchar * const pmeanspis a constantchar const * const pmeans not onlypbut also the string is a constant
3. ... in C
sequence of bytes
Six variations of the exec system cal
1 | |
path: C string representing the full path of the executable filefile: C string representing only the file name of the executable file; the path is searched from thePATHenvironmentarg0: should be the same as the file name, the 0th argument passed to main...: a list of char const * pointers, each pointing to a C string, as arguments passed to main; the list must end with a NULLargv: an array ofchar * constpointers, each pointing to a C string, as arguments passed to mainenvp: an array ofchar * const, each pointing to a C string of format “environment_variable_name=value“, likePATH=/testl: arguments are passed to main as a list ofchar * constpointers, each pointing to a C string; the list must end with a NULL, several args.v: arguments are passed to main as an array ofchar * constpointers, each pointing to a C string, only one arg array.e: an array of environment variable “environment_variable_name=value” pairs are explicitly passed to the new process image- All environment variables comes from the
earray; - If not specified, the new process image inherits the environment variables from the calling process image (terminal).
- All environment variables comes from the
p: use the PATH environment to search for the executable file- An opened file descriptor remains open in the new process image, unless was
fcntledwithFD_CLOEXECor opened withO_CLOEXEC. This is howstdin,stdout, andstderrare opened for the child process.
Demo Task 10
In-class demo: exec has no return
File oldimage.c
1 | |
File newimage.c
1 | |
Experiment:
1 | |
execdoes not have a return value because the new process image overlays the calling process image.- it will not create a new process.
In-class demo: execle
1 | |
File newimage.c
1 | |
1 | |
2.12 Unix Processes: process termination
Upon termination of a process, the OS de-allocates the resources held by the process, updates the appropriate statistics, and notifies other processes. Specifically, these include:
- Cancel pending timers and signals.
- Release virtual memory spaces.
- Release locks, closing open files.
- Notifying the parent in response to a wait system call.
What happens if the parent is not currently executing a wait()?
- The child process’s kernel management meta info (e.g., task struct) will remain there, though the child process image is gone. The child process hence becomes a zombie.
A normal termination occurs if there was:
- A return from main.
- Last line;
- An implicit return from main.
return 0;
- A call to the C function exit.
exit(0);
- A call to the _exit system call.
exit calls user-defined exit handlers and may provide additional cleanup before it invokes the _exit system call.
exit takes a single integer argument, called exit status, which will be made available to the parent process (which may be waiting). By convention, zero means success, and a non-zero value means something has gone wrong.
2.13 Unix Processes: abnormal process termination
A process can terminate abnormally by:
- Calling
abort, causing theSIGABRTsignal to be sent to the calling process. - Processing a signal that causes termination.
A code dump may be produced.
User-installed exit handlers will not be called upon abnormal termination.
2.14 Unix Processes: background processes
Recall that the shell is a command interpreter which:
- Prompts for commands.
- Reads the commands from standard input, forks children to execute the commands, and waits for the children to finish.
- A user can terminate execution of a command by pressing Ctrl-C.
Most shells interpret a command line ending with & as one that should be executed by a background process.
When a shell creates a background process, it does not wait for the process to complete before issuing a prompt and accepting additional commands.
Cannot send Ctrl-C to a background process via the command input. Try:
1 | |
versus
1 | |
tail
- Print the last 10 lines of each FILE to standard output. With more than one FILE, precede each with a header giving the file name.
-f, --follow[={name|descriptor}]- output appended data as the file grows;
2.15 Unix Processes: daemons
A daemon is a background process that normally runs indefinitely (has an infinite loop).
Unix relies on many daemon processes to perform routine tasks such as:
pageoutdaemon handling paging.- Move the data from hard disk to physical memory.
in.rlogindhandling remote login requests.- The web server daemon receiving HTTP connection requests.
- FTP daemon, mail daemon, etc.
- ssh daemon
Demo Task 11
1 | |
setsid
- creates a session and sets the process group ID
chdir
- chdir() changes the current working directory of the calling process to the directory specified in path.
umask
- Specifically, permissions in the umask are turned off from the mode argument to open(2) and mkdir(2).
- umask() sets the calling process’s file mode creation mask (umask) to mask & 0777 (i.e., only the file permission bits of mask are used), and returns the previous value of the mask.
- The effective mode is modified by the process’s umask in the usual way: in the absence of a default ACL, the mode of the created file is (mode &
~umask).
The daemon will not be killed after the terminal is closed.
But it will be kill after the user is logged out.
3. Unix File System
What is a file in Unix?
How many types of files?
How are the files in a file system structured?
How is a file represented in memory and disk?
How to find the file using its name?
How to access files from a Unix program?
3.1 Unix File System
File system provides abstractions of naming, storage, and access of files.
A file is a container of some information: data, program.
In Unix, devices (disks, tapes, CD ROMs, screens, keyboards, printers, mice, etc.) are also treated as files, so as to provide a unified and device independent interface to applications.
3.2 How to handle devices?
OS provides system calls to the programmer for performing control and I/O to devices. These system calls are handled by device drivers, which hide the details of device operation and protect the devices from unauthorized use.
Some OS provides specific system calls for each type of supported devices.
In contrast, in Unix, disk files and other devices are named and accessed in the same way as data files.
- Unix provides a uniform device interface (called file descriptors).
- Allow uniform access to most devices through file system calls – open, close, read, write, etc.
3.3 Types of files in Unix
Regular file: an ordinary data file on disk – contains bytes of data organized onto a linear array;
Special file: a file representing a device – located in the /dev directory
- Block special file: devices transferring info in blocks or chunks, just like disks, CD ROM.
- Character special file: devices transferring info in stream of bytes that must be accessed sequentially, e.g., keyboard, printer.
- FIFO special file: used for inter-process communications (e.g. pipe).
Directories: provided to allow names (not physical locations) of files to be used.
- User gives a file name and Unix makes a translation to the location of the physical file – done via directories.
3.4 Difference between regular and directory file
Contents: data vs file info
Operations: what can be done and who can do them
3.5 The ls –l command
For each file you can see ten characters before the user and group owner. The first character tells us the type of the file.
| First character | File type | |
|---|---|---|
- |
normal file | |
d |
directory | |
| `\ | ` | symbolic link |
p |
named pipe | |
b |
block device | |
c |
character device | |
s |
socket |
Next 9 characters represent access right assignment for user, group, and all.
| Permission | On a file | On a directory |
|---|---|---|
r read |
read file content (cat) |
read directory content (ls) |
w write |
change file content (vi) |
create files in (touch) |
x execute |
execute the file | enter into directory (cd) |
3.6 What are the differences between a regular file and a device file?
Demo Task 1
1 | |
1 | |
Copy to the tty, will print the content to the terminal.
tty is the device driver.
3.7 Hierarchical file organization
A Unix file system has a hierarchical tree structure where internal nodes are directories and leaf nodes are files
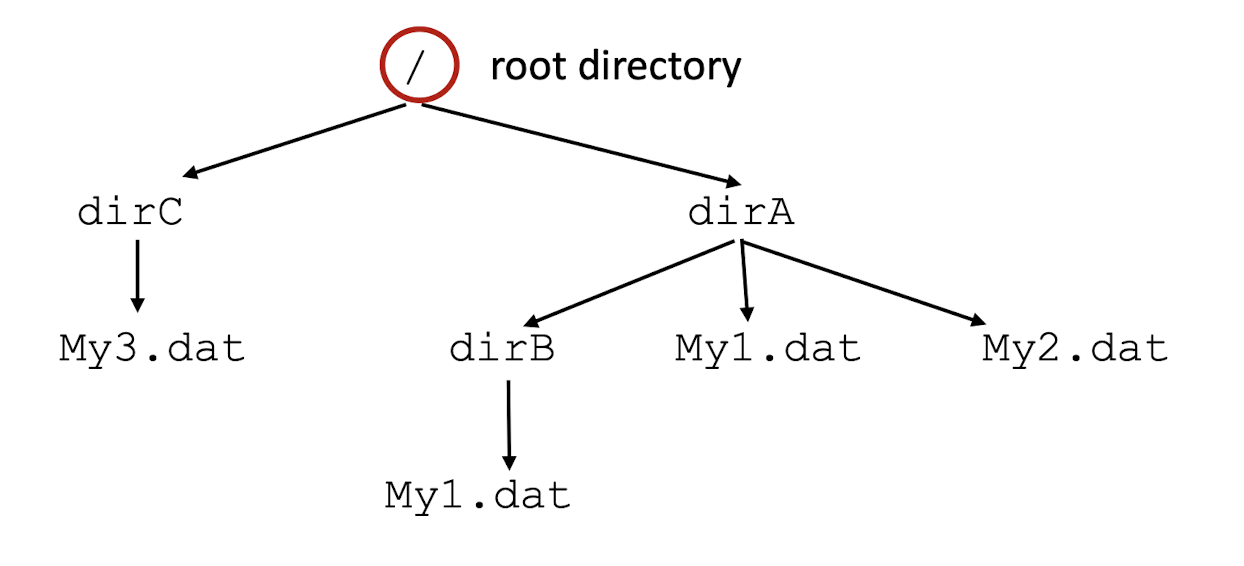
The absolute or fully-qualified pathname uniquely specifies a file, e.g. /dirA/My1.dat differs from /dirA/dirB/My1.dat.
We can also use a relative pathname, which begins from the current directory instead of the root directory, e.g., ../My2.dat (if current working directory is dirB).
3.8 Current working directory
At anytime, every process has an associated directory called the current working directory (cwd)
Denoted by a dot “.”, e.g., “mv ../file1 .“
The cwd associated with a user’s login shell is called the user’s home directory.
pwd prints the name of the cwd.
- present working directory:
pwd - current working directory:
cwd
A relative pathname always starts with the path to the cwd.
The C library function getcwd returns the pathname of the current working directory
1 | |
sizespecifies maximum length pathname.- If longer than the maximum, returns
NULLand setserronotoERANGE.
Demo Task 2
1 | |
3.9 File representation
Information about a filesystem structure is stored both on disk and main memory.
Unix uses a logical structure called i-node to store the information about a file on disk
- each file in a file system is represented by an i-node:
- Physically: i-node Stored in the disk;
- Conceptually: real data stored in the data block;
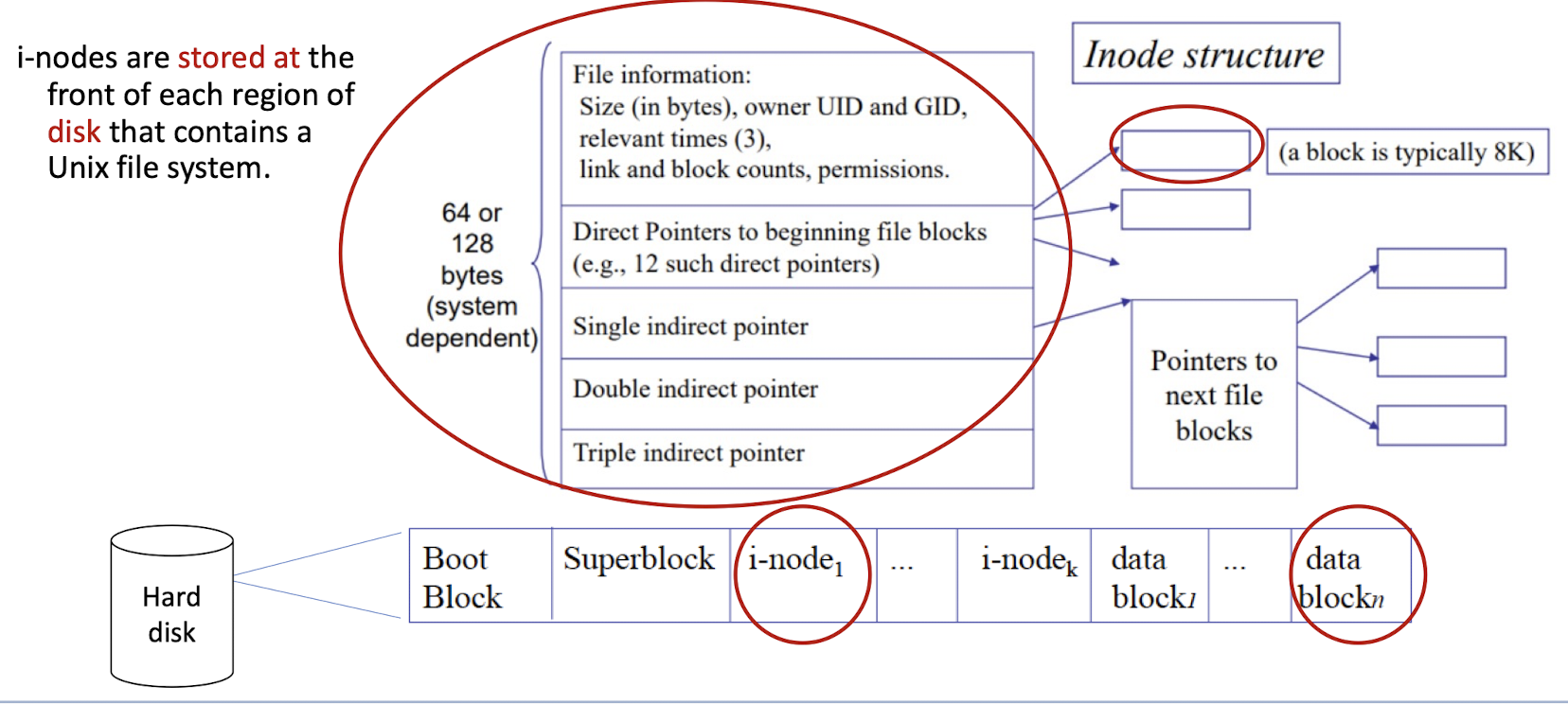
- Data blocks of one file are not contiguous on disk, need the i-node to point to the data blocks, put them together.
- If the file is too large, need to use the i-node to point to the i-nodes of the data blocks, and we can put the pointers in the data block.
- Like a tree, hierarchical structure.
3.10 Where is i-node stored? And how can we find the i-node of a file?

i-nodes are stored at the front of each region of disk thatcontains a Unix file system.
A regular file has a number called the i-number, which is an index into an array of the i-nodes on disk.
- i-number is a concepatual number, not a physical number.
- But the i-node is a physical structure, stored in the disk.
Each i-node corresponds to a unique i-number (index).
How can we find the i-number of a file, given the file name?
- A directory contains a list of entries mapping file names to i-numbers (hence the i-node).
- A
<name, i-node>pair is called a link. You can create many links for a file (multiple names). - i-nodes are the hidden part, while directories are the visible structure of the Unix file system.
- Hence, the correspondence between a file name and its i-node is stored in the directory file.
3.11 An example directory file
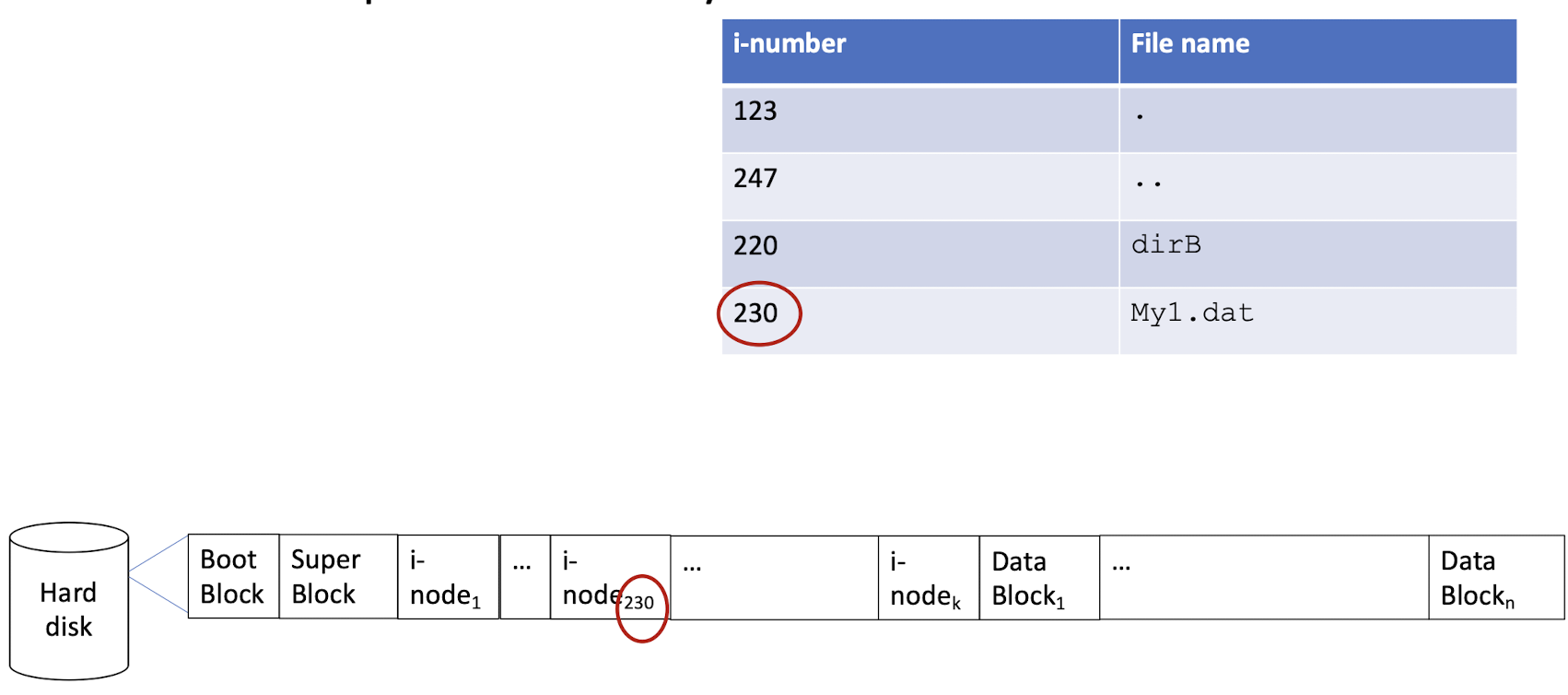
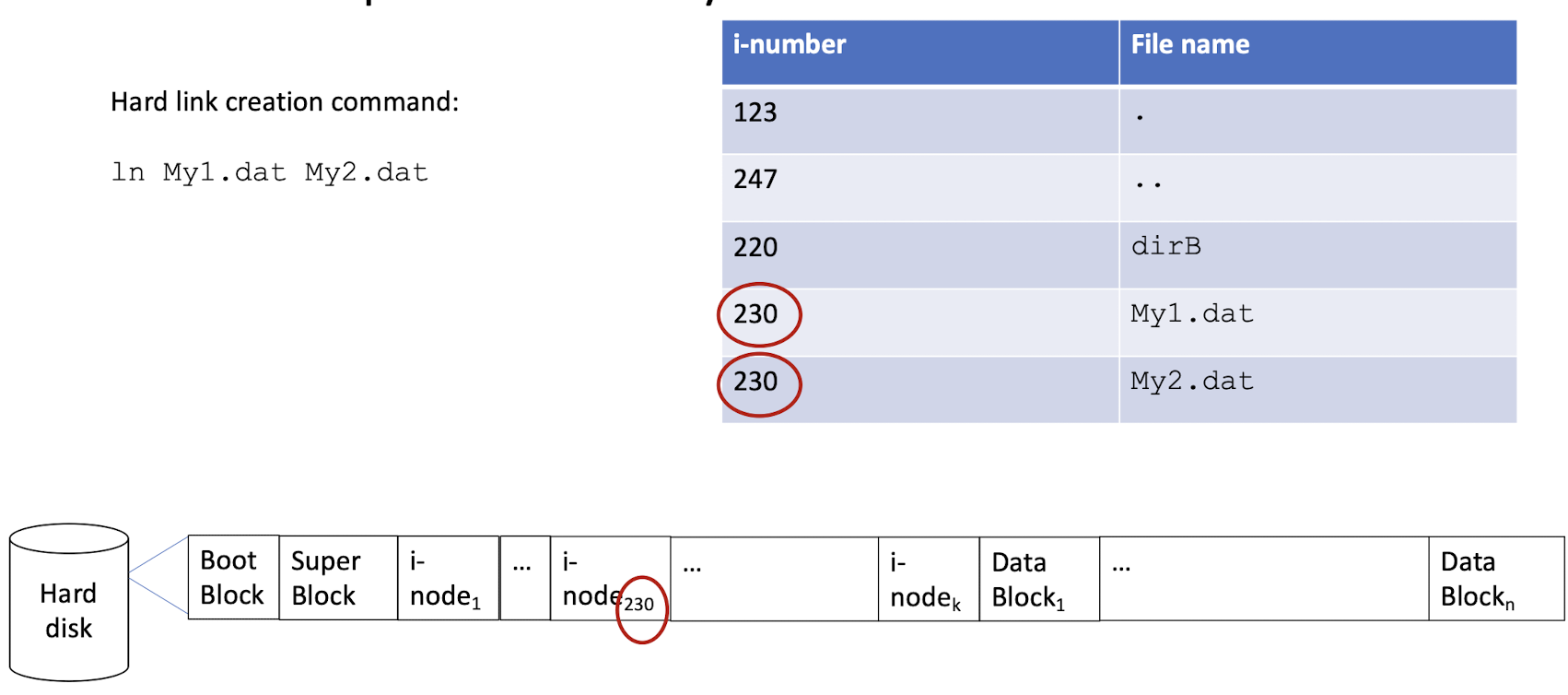
3.12 An example directory file: hard link
- Duplicate the of the i-node of the file to be linked.
1 | |
linkName -> target
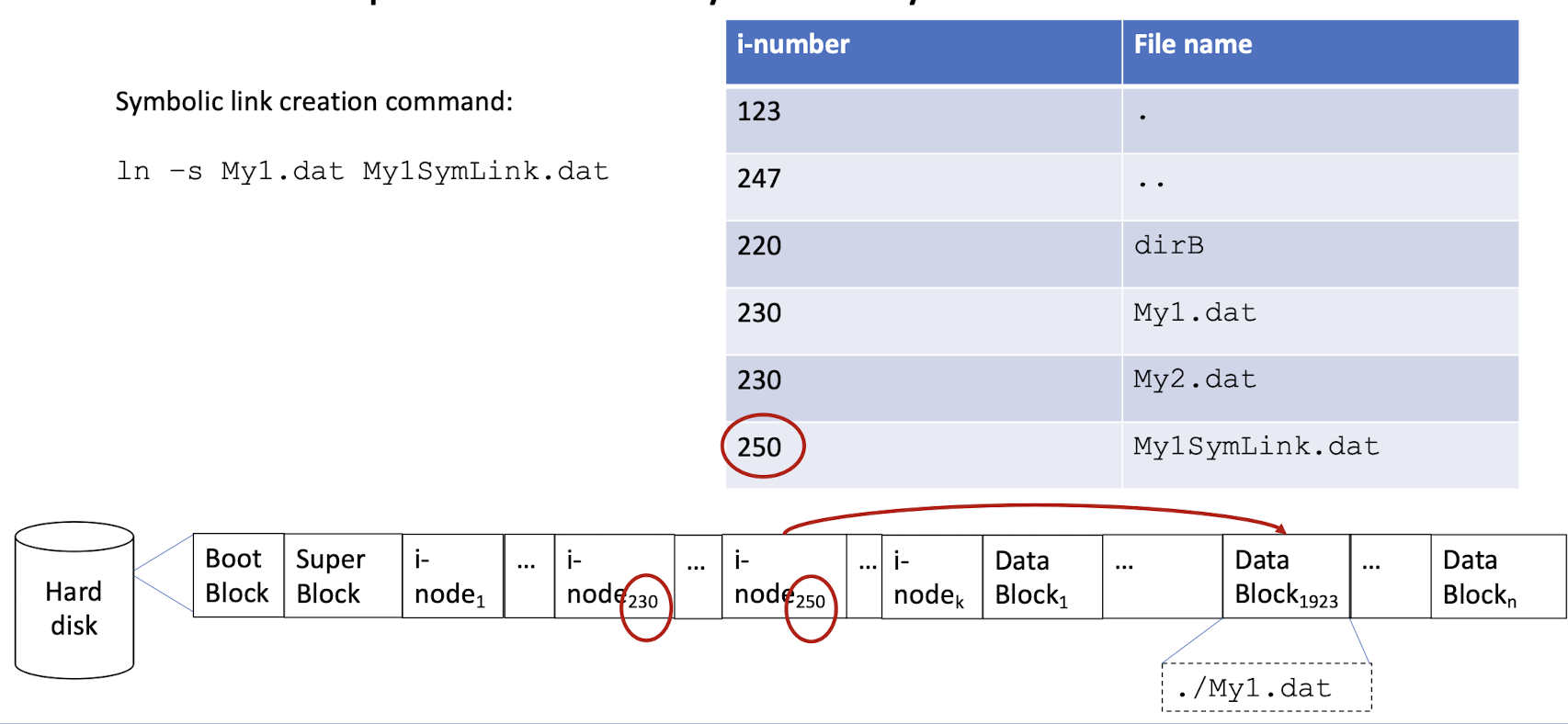
3.13 An example directory file: symbolic link
- Create a new i-node
- The i-note points to the data block (create a new file), and the content is the relative path of the target file.
- Unless we provide the absolute path in target, otherwise it is a relative path.
- In all, whether symbolic link is vaild depends on the target‘s path is valid or not (relative or abstract).
1 | |
linkName -> target
3.14 Hard Link vs Symbolic Link
1 | |
Hard links
- Two file with the same i-node, but different file name.
Hard links must be on the same file system,
Hard linked files stay linked even if either one is moved (unless the move crosses file system boundaries, triggering copy-and-delete).
- The performance is just like the
cp; - Even if the original file is moved (
rm), the hardlink can still find the original file, because there is a counter varibale stored in the i-node, if there is still some file linked, the data will not be deleted from the disk. (decide to showdow remove or deep remove)
- The performance is just like the
- Hard linked files are co-equal (data is deleted only when all hard links are deleted), while the original is special in symbolic links (deleting the original deletes the data, deleting the symbolic link does not delete the data).
Symbolic link
- Two file with the different i-node, different file name.
- symbolic links can cross file systems.
- Because the content of the symbolic link is the (relative) path of the target file.
- Symbolic linked files break if the original is moved.
- Or the symbolic link is moved to another file system, it also cannot find the original file, because it use the relative path.
- Symbolic link can point at any target, but most OS/filesystems disallow hardlinking directories to prevent cycles.
- Symbolic link can require special support from file system walking tools.
- Can also provide the absolute path in the target, then the moving of the file will not affect the link.
3.15 Where is i-node stored? And how can we find the i-node of a file?
Name resolution is a function to convert a pathname to an i-node number.
When a program references a file by pathname, OS traverses the file system tree to find the filename and the i-number in the appropriate directory.
Once it has the i-number, the OS can determine other information about the file by accessing the i-node.
Usually, the OS keeps copies of the i-nodes for active files in memory for efficiency.
Remark: directories are disk resident files that can be read by any program. In many aspects, they are treated the same way as regular files.
3.16 How large a file can be?*
12 direct pointer can point to 12 x 8KB = 96KB of file content.
A Single indirect pointer points to a block of direct pointers.
- A block can contain 8KB/4bytes = 2K pointers = 2048 pointers.
- 2048 direct pointers can point to 2048 x 8KB = 16MB of file content.
A Double indirect pointer points to 2048 single indirect pointers, that is 2048 x 16MB = 32GB of file content.
A Triple indirect pointer points to 64TB of file content.
So one I-node can at the most point to 64TB + 32GB + 16MB + 96KB of file content.
3.17 How are files accessed in user programs?
Within C programs, a file is accessed either by file descriptors or by file pointers, which provide logical names (handles) for performing device-independent I/O.
The Unix file system calls use file descriptors (via open,read, write,close, and ioctl).
The ANSI C I/O library uses file pointers (via fopen, fscanf, fprintf, fread, fwrite, fclose, etc.).
File descriptors (in unistd.h) for standard input, standard output, and standard error files are STDIN_FILENO, STDOUT_FILENO, and STDERR_FILENO
- while file pointers (in
stdio.h) arestdin,stdout, andstderr;
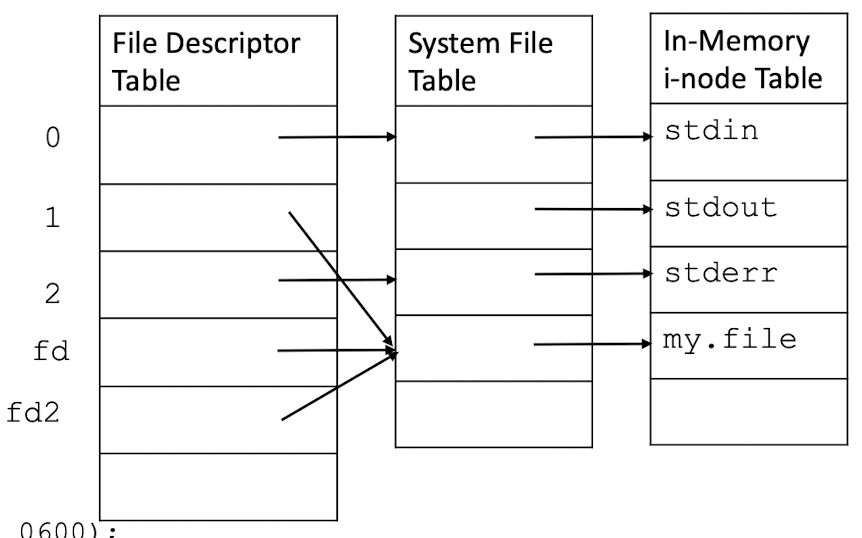
3.18 File descriptors
Each program has a File Descriptor Table (FDT) that contains pointers to the System File Table (SFT) entries.
SFT entry contains information about whether a file is opened for read/write, permission, lock, read/write offset etc.
Several entries in SFT may point to the same physical file.
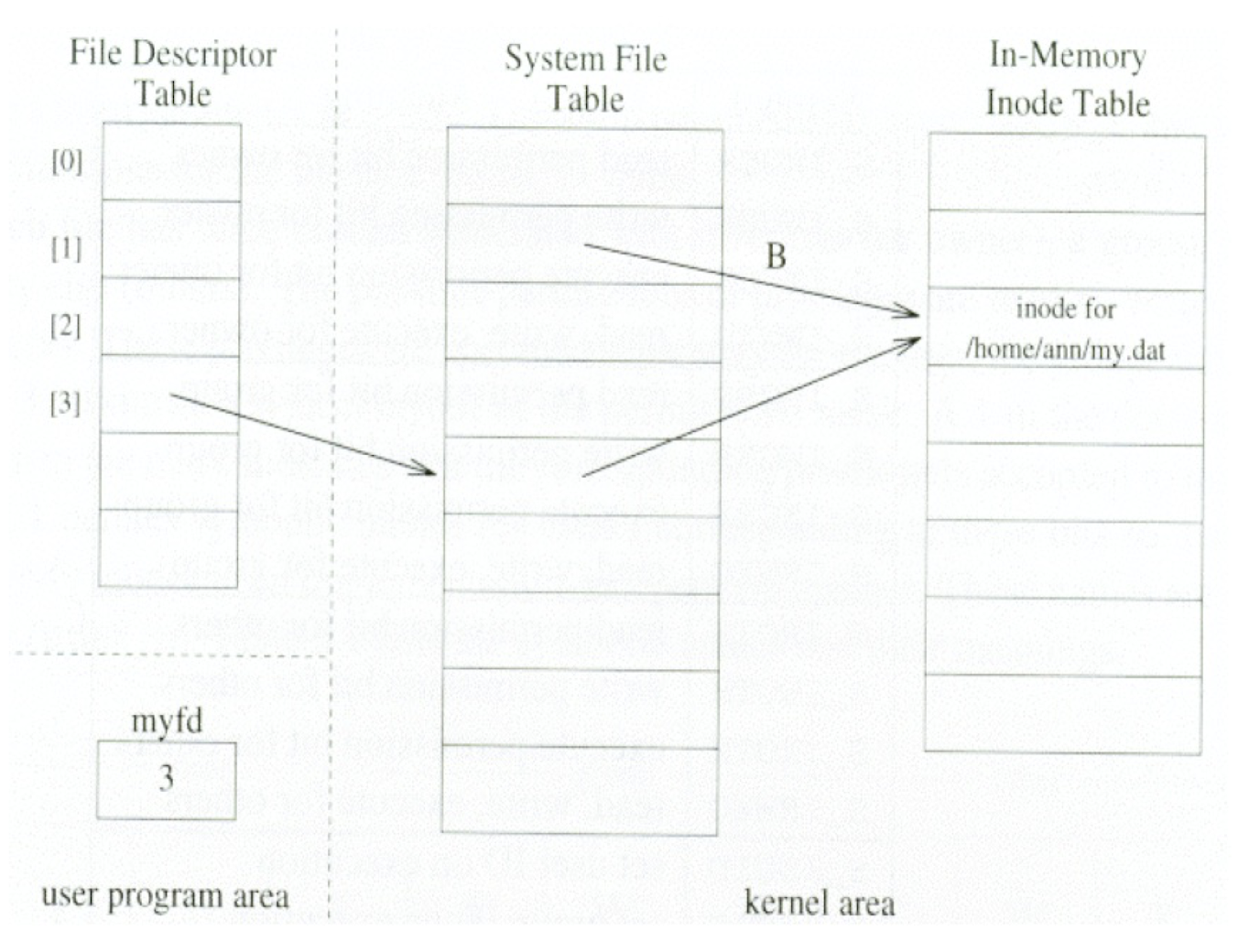
Three files are opened automatically:
STDIN_FILENO: standard inputSTDOUT_FILENO: standard outputSTDERR_FILENO: standard error- Corresponding to constants
0,1,2inunistd.h
When new files are opened, it is assigned the lowest (smallest index) available FD.
Accessing files for I/O is a three-step process, whether it is a regular file or a device:
- Open the file for I/O
- Read and write to the file
- Close the file when finished with I/O
3.19 File descriptor: open a file
1 | |
Open a file
pathname: absolute or relative path to the fileflags: must include one of the following access modes:O_RDONLY,O_WRONLY,O_RDWR, and bitwise-or’d(i.e. using the|operator) with zero or more of the following:O_CREAT: if the pathname does not exist, create the file as a regular file; must add the access permission mode parameter (e.g.0644).O_APPEND: the file is opened in append mode.- …
Returns the opened file’s file descriptor or –1 if an error occurred (the errno is set accordingly)
1 | |
3.20 File descriptor: read a file
1 | |
Read from file associated with fd; place countbytes into buffer
fd: file descriptor to read frombuffer: pointer to an arraycount: number of bytes to read
Returns number of bytes read or –1 if an error occurred
Demo Task 3
1 | |
3.21 File descriptor: write a file
1 | |
Write contents of buffer to the file associated with fd; write count bytes into the file (will NOT erase the original content)
- Or use
O_TRUNCto erase the original content. fd: file descriptor to write tobuffer: pointer to an arraycount: number of bytes to write
Returns number of bytes written or –1 if an error occurred
Demo Task 4
1 | |
1 | |
3.22 File descriptor: close a file
1 | |
Closes an open file descriptor fd
Returns 0 on success, -1 on error
3.23 File pointers
A file pointer points to a data structure FILE, called a file structure in the user area of the process.
A file structure contains a buffer and a file descriptor (so a file pointer is a handle to a handle)
The following code segment open the file /home/ann/my.dat for output and then writes a string to the file.
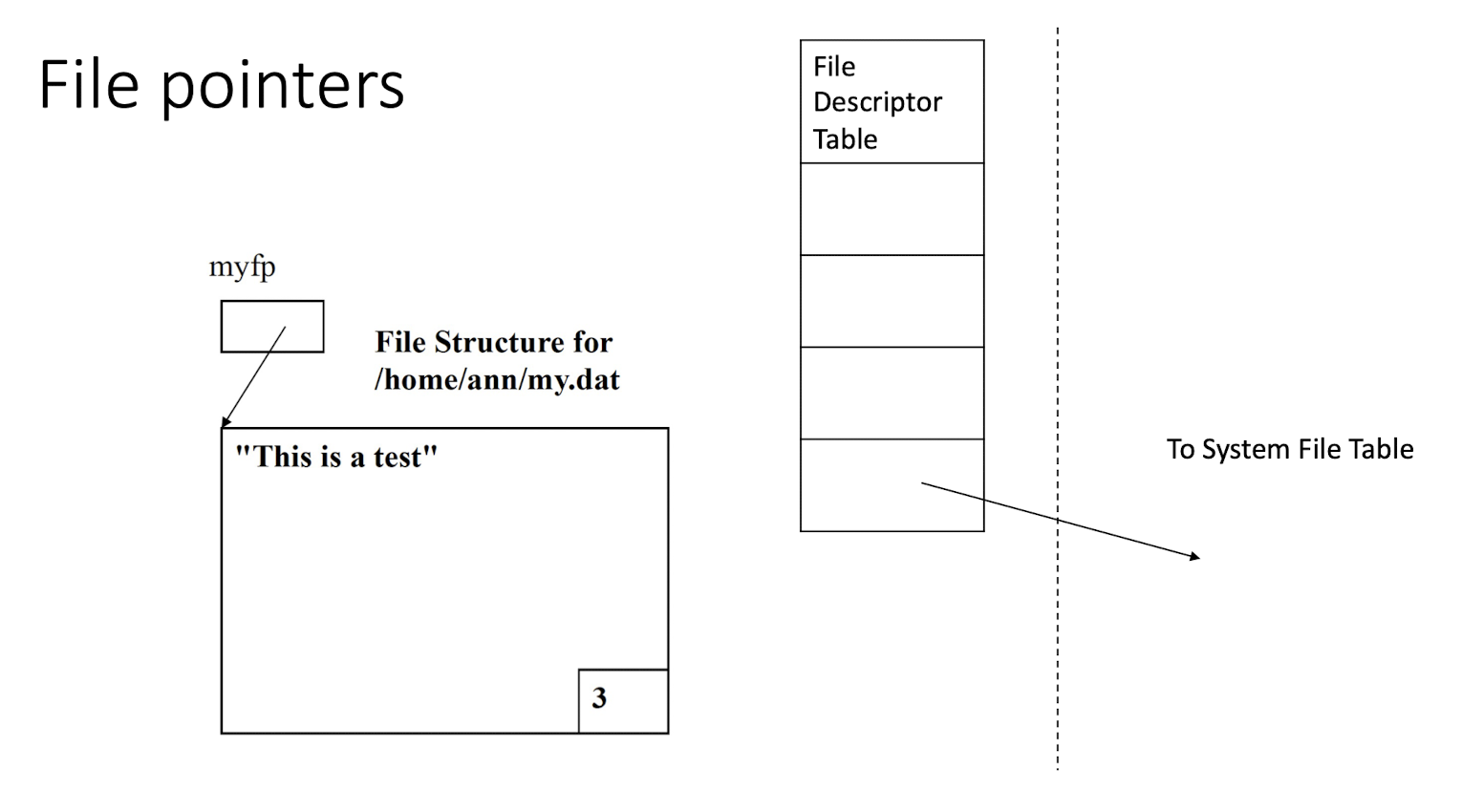
Demo Task 5
1 | |
1 | |
3.24 File pointer and FILE
File pointers are used (via the FILE data type) in the following higher-level I/O
functions in C libraries:
1 | |
3.24.1 fopen() and fclose()
1 | |
Path: char*, absolute or relative path
Mode:
r– open file for readingr+- open file for reading and writingw– overwrite file or create file for writingw+- open for reading and writing; overwrites filea– open file for appending (writing at end of file)a+- open file for appending and reading
1 | |
Closes the opened file represented by file_stream
3.24.2 printf()
1 | |
formatted_string: string that describes the output information, variable types are escaped with %
The formatted string is followed by as many expressions as are referenced in the formatted string.
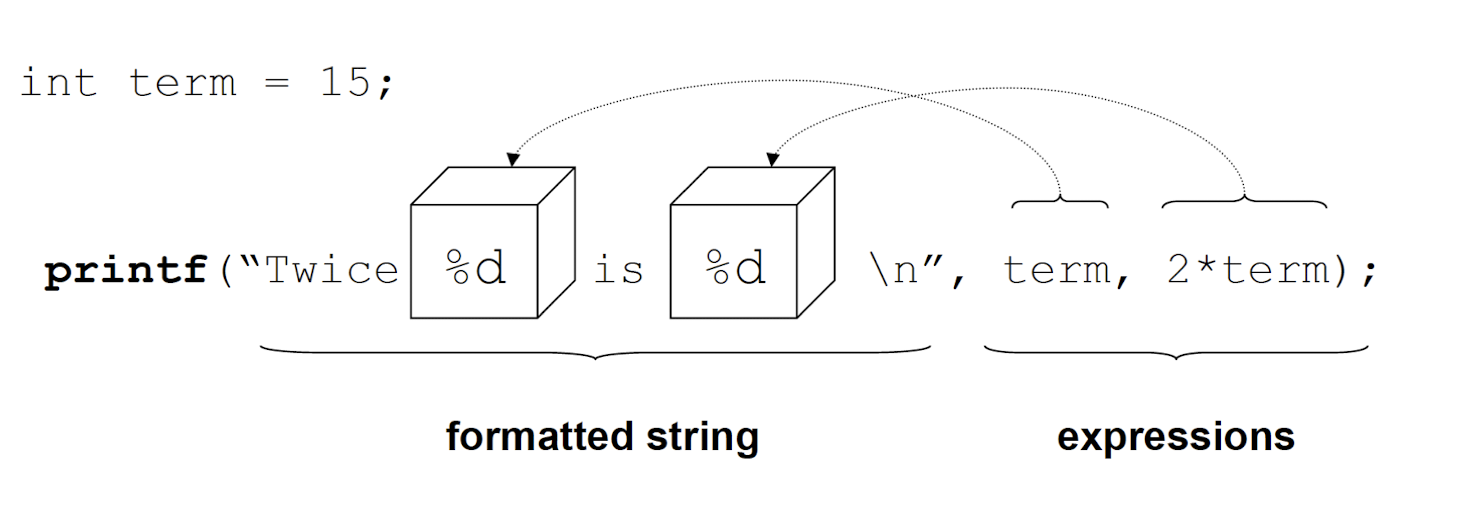
3.24.3 Escaping variable types
%d,%i– decimal integer%u– unsigned decimal integer%o– unsigned octal integer%x,%X– unsigned hexadecimal integer (a,b,c,d,e,f and A,B,C,D,E,F)%c– character%s– string or character array%f– float%e,%E– double (scientific notation)%g,%G– double or float%%– outputs a %character
3.24.3 printf() examples
Demo Task 6
1 | |
1 | |
printf("The sum of %d, %d, and %d is %d\n", 65, 87, 33, 65+87+33);
Output: The sum of 65, 87, and 33 is 185
printf("Error %s occurred at line %d \n", emsg, lno);
Output: Error invalid variable occurred at line 27
printf("Hexadecimal form of %d is %x \n", 59, 59);
Output: Hexadecimal form of 59 is 3B
3.24.4 scanf() examples
scanf(formatted_string, ...)
Similar syntax as printf, only the formatted string represents the data that you are reading in.
Must pass variables by reference
Demo Task 7
Example:scanf(” %d %c %s", &int_var, &char_var, string_var);
1 | |
1 | |
Using fgets
1 | |
fscanf:
1 | |
The leading white space is to ask scanf to ignore any white space (including newline) characters.
Other alternatives to flush the ‘
\n’in input buffer include usinggetchar()after ascanf()call, using ‘%*c’, but the best is to usefgets()to get a line stead of usingscanf
3.25 printf() and scanf() families
fprintf(file_stream, formatted_string, ...)
Prints to a file stream instead of stdout
sprintf(char_array, formatted_string, ...)
Prints to a character array instead of stdout
int fprintf(FILE *stream, const char *format[, argument ]...);int sprintf(char *buffer, const char *format[, argument]...);
fscanf(file_stream, formatted_string, ...)
Reads from a file stream instead of stdin
sscanf(char_array, formatted_string, ...)
Reads from a string instead of stdin
1 | |
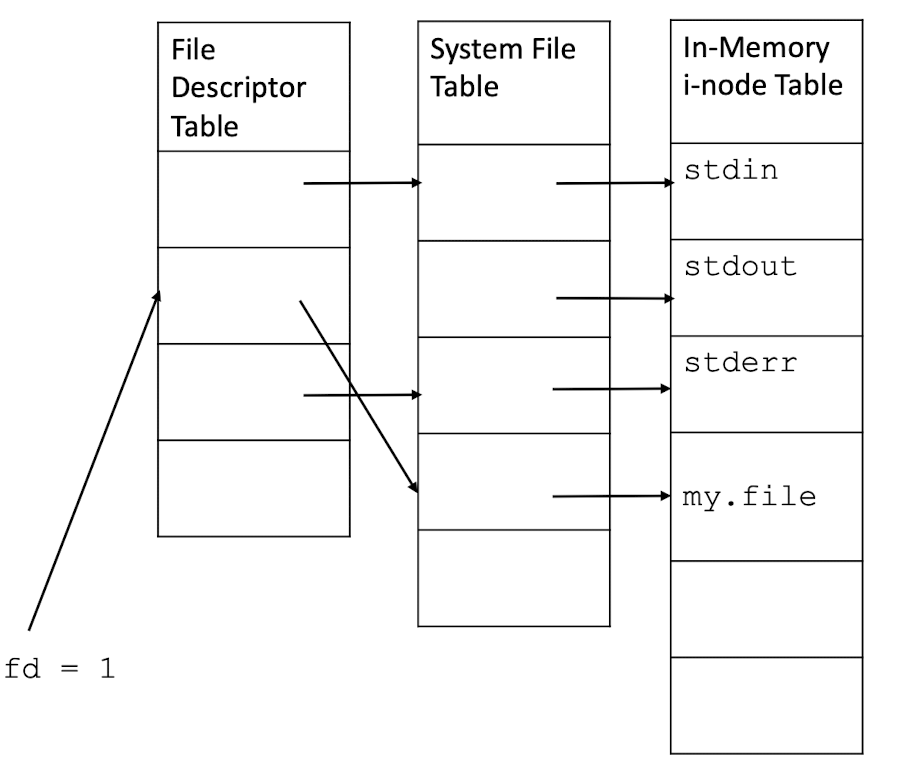
3.26 I/O redirection
Recall: to access a file, a process uses a file descriptor, which is an index into the process file descriptor table, which in turn points to an entry in the system file table.
Redirection means that the process modifies its file descriptor table entry so that it points to a different entry in the system file table.
Consider the command cat, which reads from a file and outputs to stdout.
The following command redirects stdout to my.file:
1 | |
3.27 I/O redirection realization using dup()
int dup(int oldfd) duplicates the given file descriptor to the lowest numbered unused file descriptor in the file descriptor table.
Demo Task 8
1 | |
./task8 task8.txt- Finally, the
lsoutput will be written to the fileargv[1](e.g. tesk8.txt) instead of the screen.
3.28 Communication between parent/child via pipe
System call pipe() returns two file descriptors by which we can access the input/output of a pipe (an I/O mechanism)
1 | |
- Return:
0success;-1error - fd[1] is for writing
- fd[0] is for reading
Demo Task 9
1 | |
strlen()
- The
strlen()function calculates the length of the string pointed to by s, excluding the terminating null byte (‘\0’).
write()
- The number of bytes written may be less than count if, for example, there is insufficient space on the underlying physical medium,
- The actual number of bytes written may be less than the
count.
3.29 More about Unix files
Details on C library functions/system calls for creating, opening, reading, writing, locating, renaming, deleting, and closing files and directories.
4. Introduction to Device Drivers
4.1 Outline
What is a device driver?
Related OS infrastructure
Devices and files
Major design issues
Types of device drivers
4.2 What is a device driver
Device driver is a special kind of library, which can be loaded into the OS kernel, and links application program with the I/O devices
4.3 Related OS infrastructure
In Unix, the following infrastructure is related to device drivers:
- Unix system architecture
- File subsystem and its relations with char/block device driver tables
- Char/block device driver tables
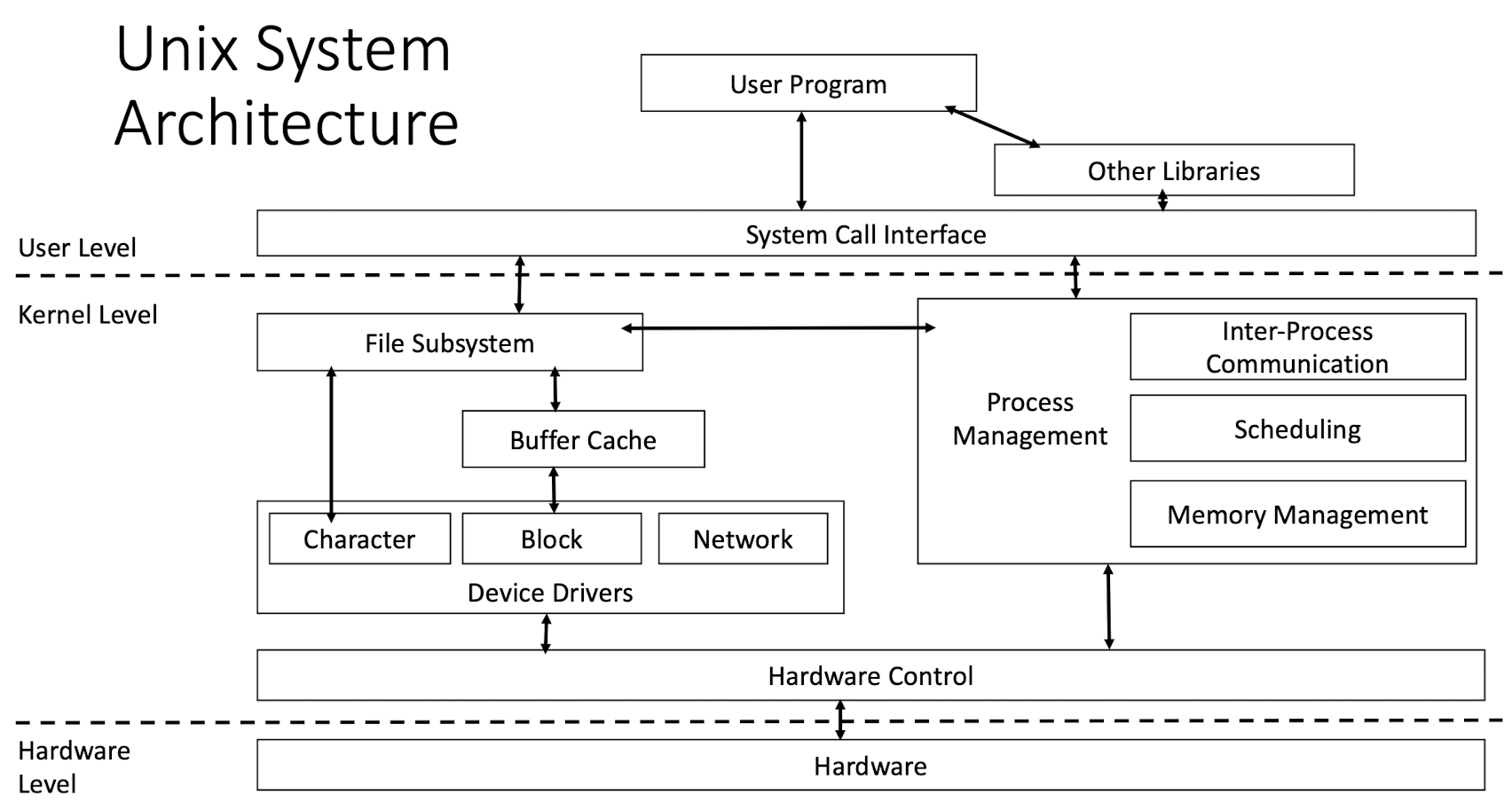
4.4 Unix System Architecture
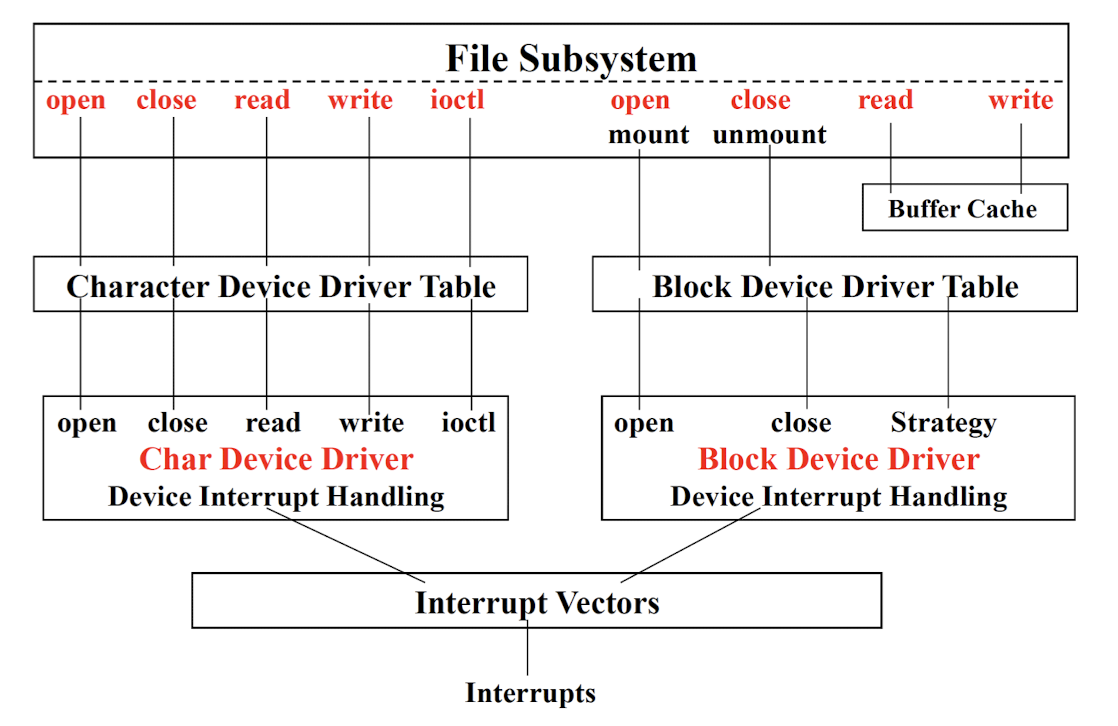
4.5 File subsystem & char/block device driver tables
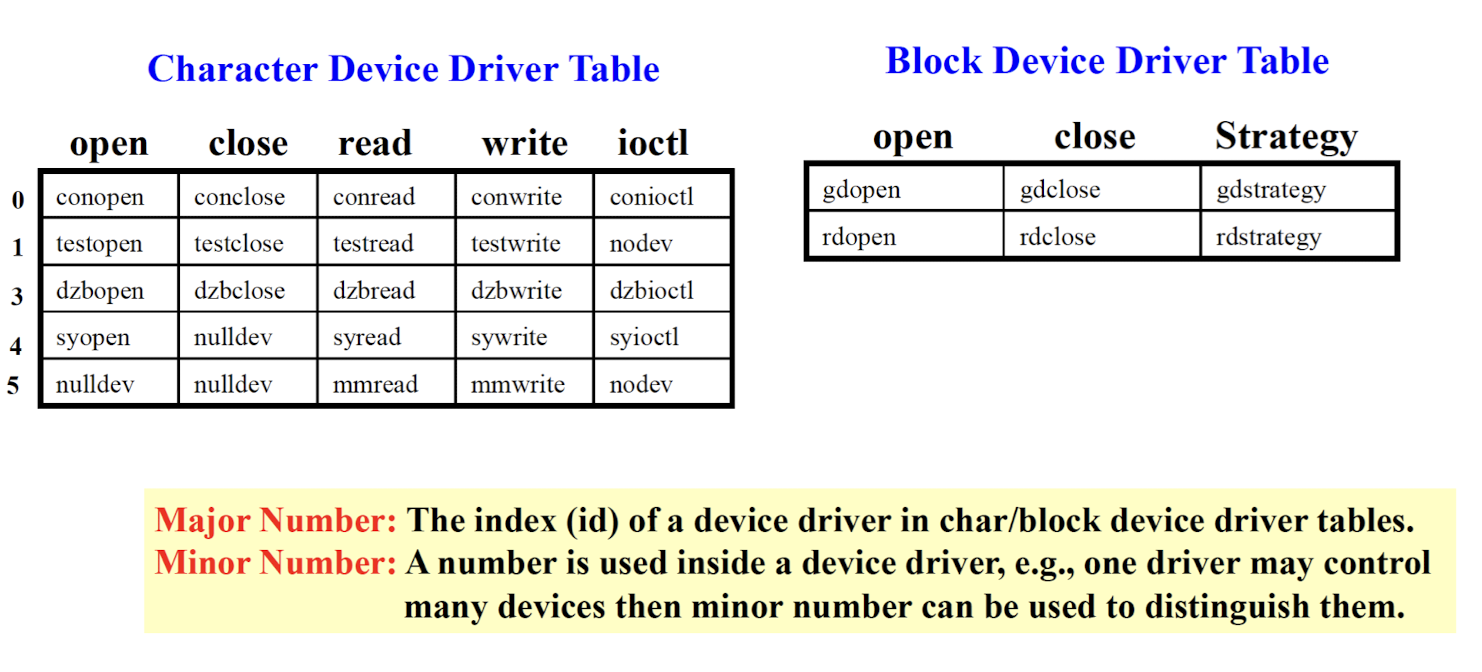
Major number:
- The index of the device driver in the char/block device driver tables.
Minor number:
- The index of the specific hardware using the same device driver.
- E.g. two printers using the same driver.
4.7 Advantages to separate device drivers from the OS
OS designers
- Devices may not be available when an OS is designed.
- Not a part of the kernel at the first, it is the module, when need it, you load it.
- Do not need to worry about how to operate devices (set up registers, check statuses, …).
- Focus on OS itself by providing a generic interface for device driver development.
Device driver designers
- Do not need to worry about how I/O is managed in OS (how to design kernel data structures to efficiently operate devices, …)
- Focus on implementing functions of devices with device-related commands following the generic I/O interface
Monolithic kernel vs. Microkernel
- Monolithic kernel: function call, complicted, but fast.
- Microkernel: like internet, send message to each other, slower, time-cost, but easy to maintain, easy to debug, easy to extend, better isolation, better security.
Linux is kind of Monolithic kernel, but it has the module, which is kind like Microkernel, you load it into the kernel when you need it.
4.8 Devices and Files
In Unix, devices are treated as special files.
A file is associated with an inode. We can use
1 | |
to create a special file for a device file.
When we create a special file (an inode) for a device file, we associate major/minor numbers with the file (the inode).
- Major number is mapped 1 to 1 to the device driver instance;
- Minor number is used to identify the specific hardware using the same device driver.
The major number associated with a special file is used to identify its corresponding device drivers in the kernel.
4.9 Character/Block Device Files
Basically, there are two types of device files: character device file and block device file.
[Example]

4.10 Major Design Issues
- OS / Device Driver Communication
- Device Driver / Hardware Communication
- Device Driver Operations
- Interpret commands received from OS
- Schedule multiple requests for services
- Manage data transfer across both interfaces
- Accept & process hardware interrupts
- Maintain the integrity of the device’s and kernel’s data structures
4.11 Types of Device Drivers
Based on the differences in the way that device drivers communicate with Linux
- Block
- Character
- Network
4.11.1 Block Device Drivers
Communicate with the OS through a collection of fixed size buffers
- Like the FedEx, user just frop the package, the FedEx will take care of the delivery.
OS manages a buffer cache; satisfy user requestsfor data by accessing buffers in the cache.
Driver is invoked when requested datais not in the cache; when buffers in the cache have been changed and must be written out (write backto the devices).
By using buffer cache, block drivers are insulated from the many details of user requests; only need to handle requests from the OS to fill or emptyfixed size buffers.
Mainly support devices that contain file systems.
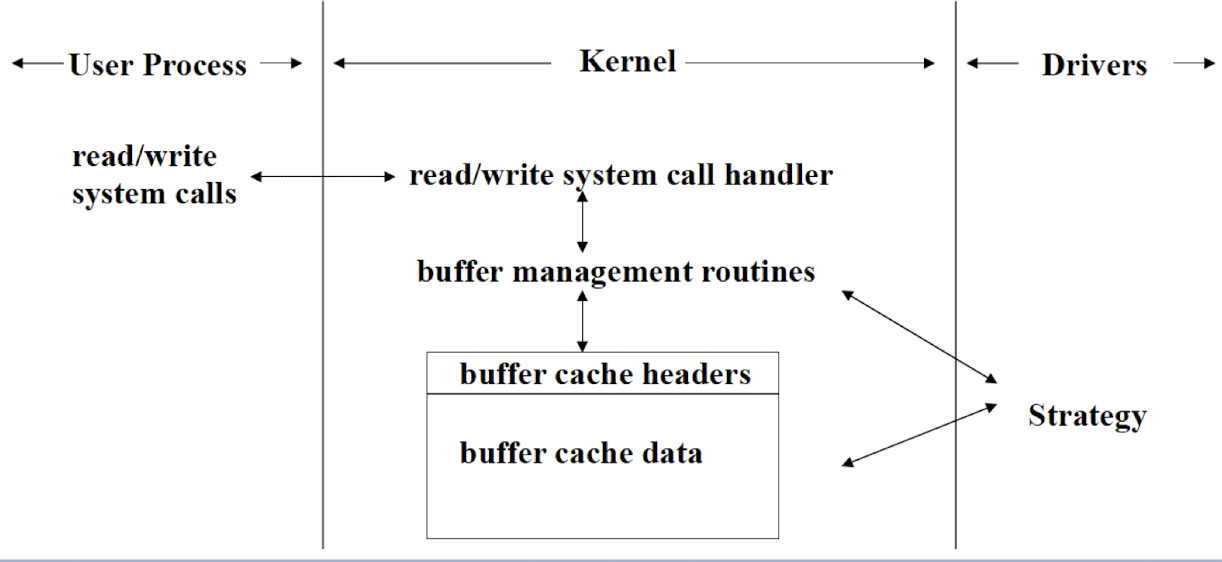
4.11.2 Character Device Drivers
Character devices can handle I/O requests of arbitrary size; support almost any type of devices.
- Handled individually by the device driver.
- More like a personal delivery, the driver will take care of the delivery, individually sevice.
Be used to handle data a byte at a time(e.g. keyboard); or work best with data in chunks smaller or larger than the standard fixed size buffer used by device driver (e.g. ADC)
The communication structure of character device driver:

4.12 Major differences between block/character drivers
Block driver
- only interacts with buffer cache
Character driver
- directly interacts with user requests from user processes
- I/O requests are directly passed (essentially unchanged) to the drivers from the user processes
- Character driver is responsible for transferring data directly to/from the kernel memory space and the user memory space.
4.13 General Programming Considerations
Device drivers are parts of the kernel and not normal user processes, which means we can only use the kernel routines in device driver programs, particularly C library functions or system calls for user level cannot be used.
Some kernel routines may have the same names as C library functions, but they are of totally different implementations.
Make frugal use of stack (local arrays & recursive function calls), as the stack space in the kernel is limited and not expandable.
- kernel stack is limited, not expandable, different from the user land stack
Be aware of floating-point arithmetic: may cause incorrect results
Be aware of busy wait: may lock up the whole system
- Infinite while loop
- In the user land, the while loop will not crash, since it has the time-slice,
- but in the kernel land, it will crash and block the whole system.
4.14 Summary
A device driver is a computer program that glues OS and its I/O devices together.
A device is treated as a special file in Unix.
There are three types of device drivers in Linux based on the different communication manner between device drivers and OS: block, character, and network.
5 Character Device Drivers I
5.1 Overview of Device Driver Development
In Unix, two generic interfaces are related to character device driver development
User programs: devices are treated as special files and users can only access devices through file operation system call (such as open, close, read, write, etc.), just like accessing regular files.
Kernel: provides a generic interface and kernel routines for all device drivers to implement functionalities and register functions into the kernel data structures (such as char/block device driver tables).
5.2 The Interface for User Programs
Device are treated as files: user programs access devices through file operation system calls.
Each file has an inode, and each device driver has a major number.
When using a device driver in user programs, we need to create a special file by associate its major number (driver) with an inode, e.g.
1 | |
5.3 The Device Driver Development (Kernel)
Two tasks
- Implement functionalities based on the generic interface
- Register the device driver into the kernel data structure (the char/block device driver table)
The major number is the ID of a device driver
5.4 The Generic Interface for Char Device Driver in Linux
A data structure called file_operations is defined in <linux/fs.h>. It is basically an array of function pointers (to locate the function in the memory).
1 | |
To develop a char driver, we need to implement the corresponding functions for a device based on the above generic interface.
Translate into the kernel memroy space.
5.5 “Hello World” Device Driver
Demo Task 1
Header files include the prototypes of kernel routines and data structures needed in the program1
2
3
4
5
6
7#include <linux/config.h>
#include <linux/module.h>
#include <linux/kernel.h>
#include <linux/init.h>
#include <linux/fs.h>
#include <linux/string.h>
#include <asm/uaccess.h>
Use “static“, the effective range of a variable is limited in the file containing it, so we can avoid name pollution.
- The static keyword restricts the visibility of variables to the file where they are declared, which is a good practice in kernel code to avoid namespace pollution and unintended side effects.
1 | |
1 | |
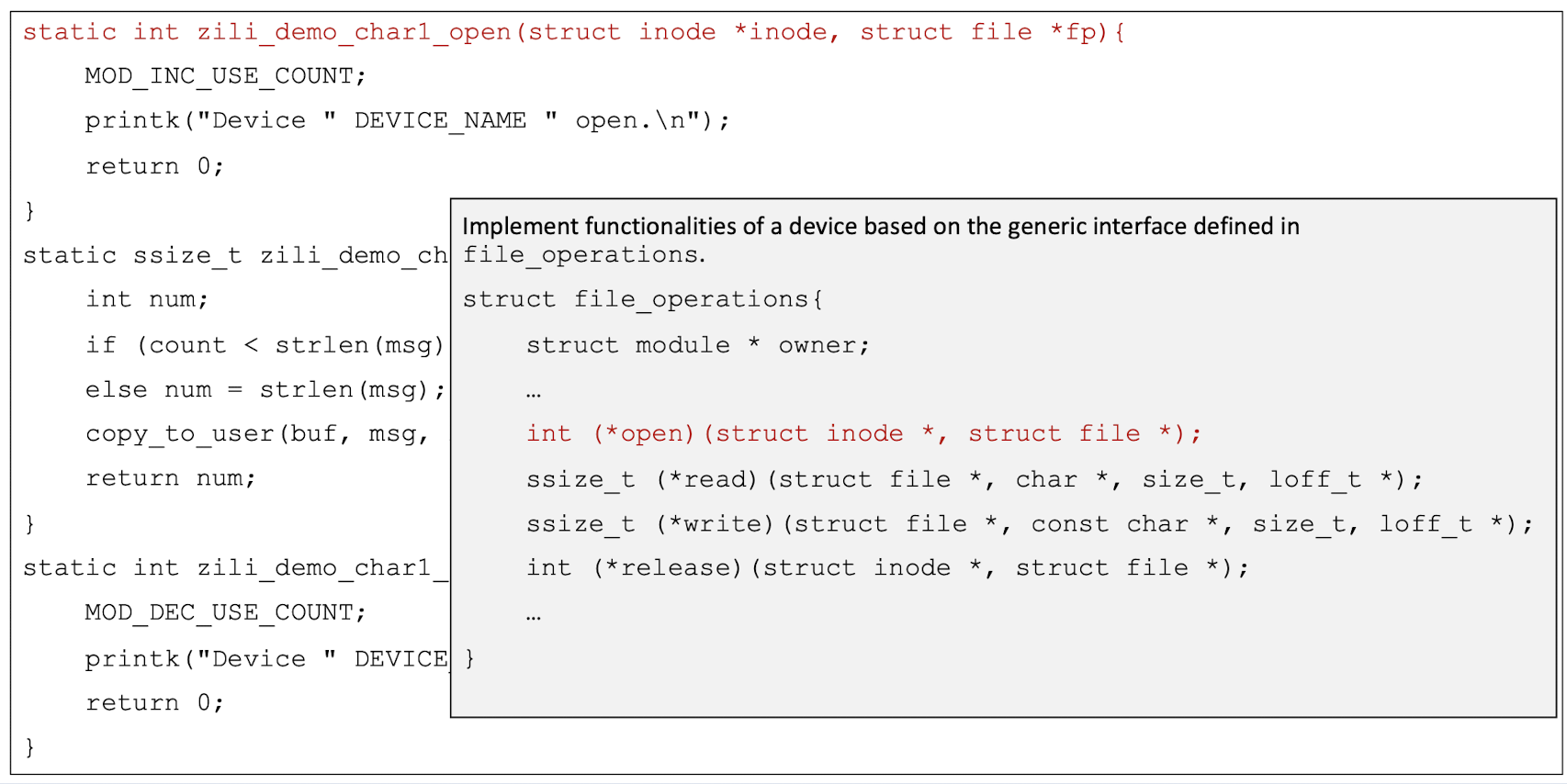
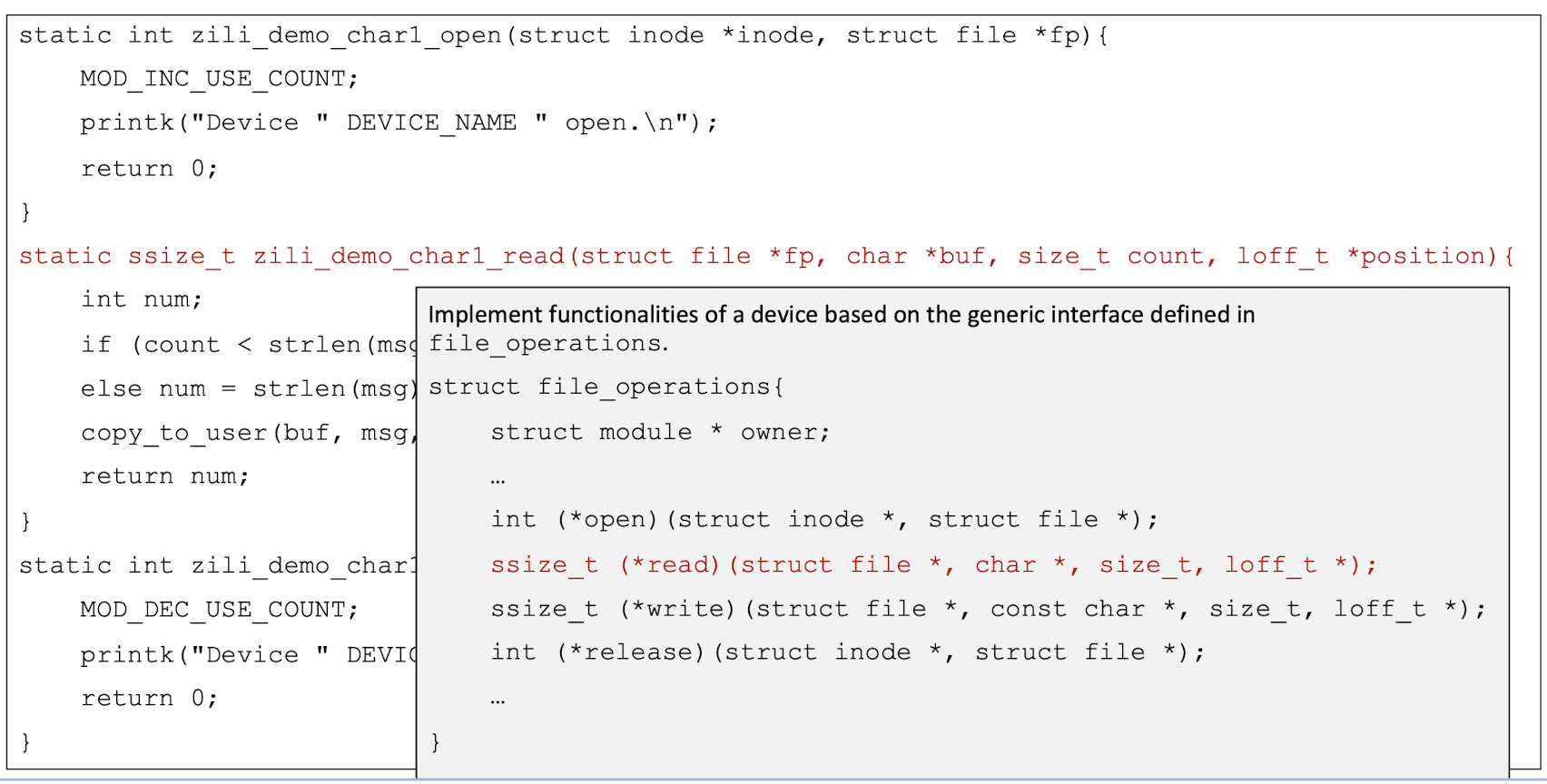
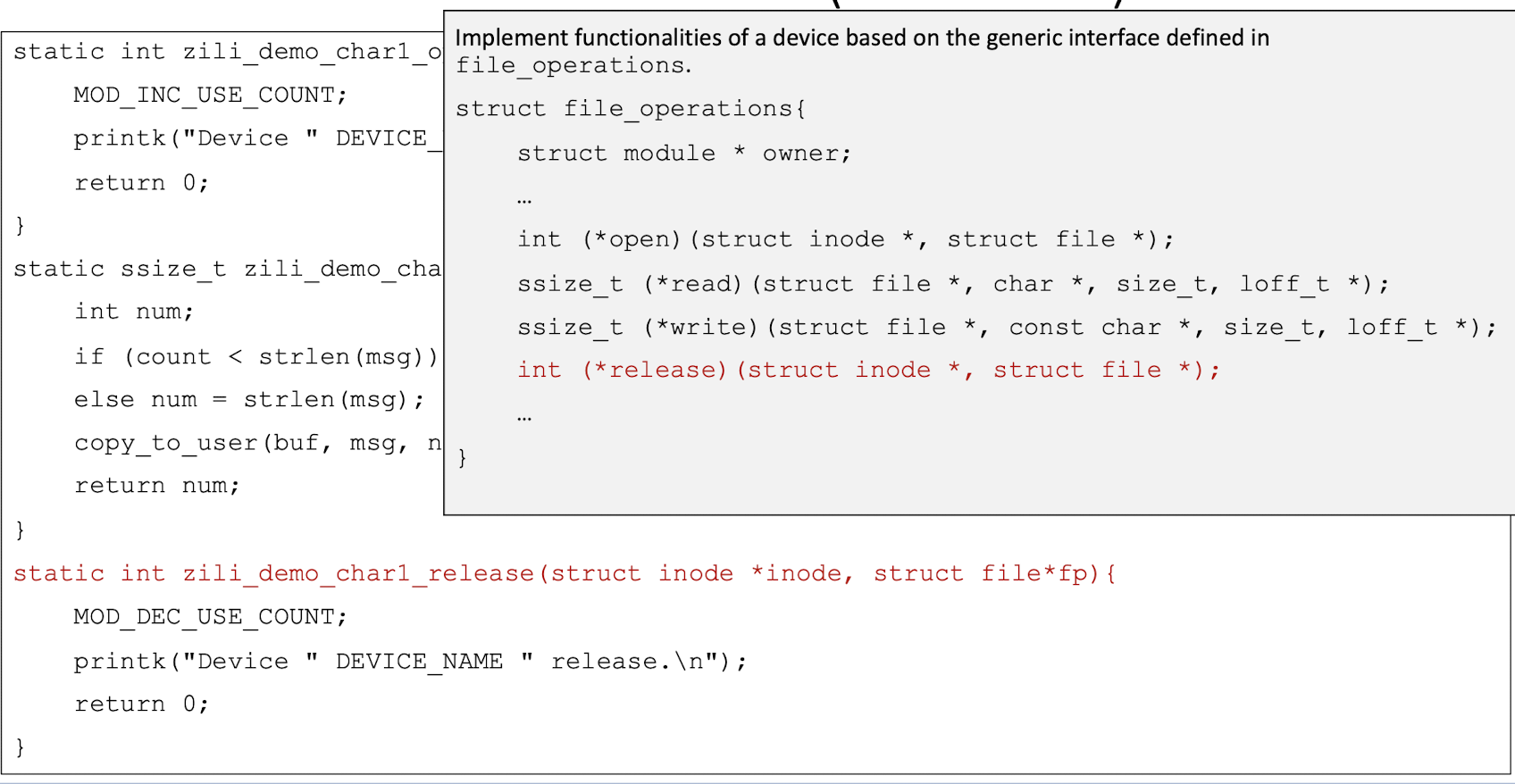
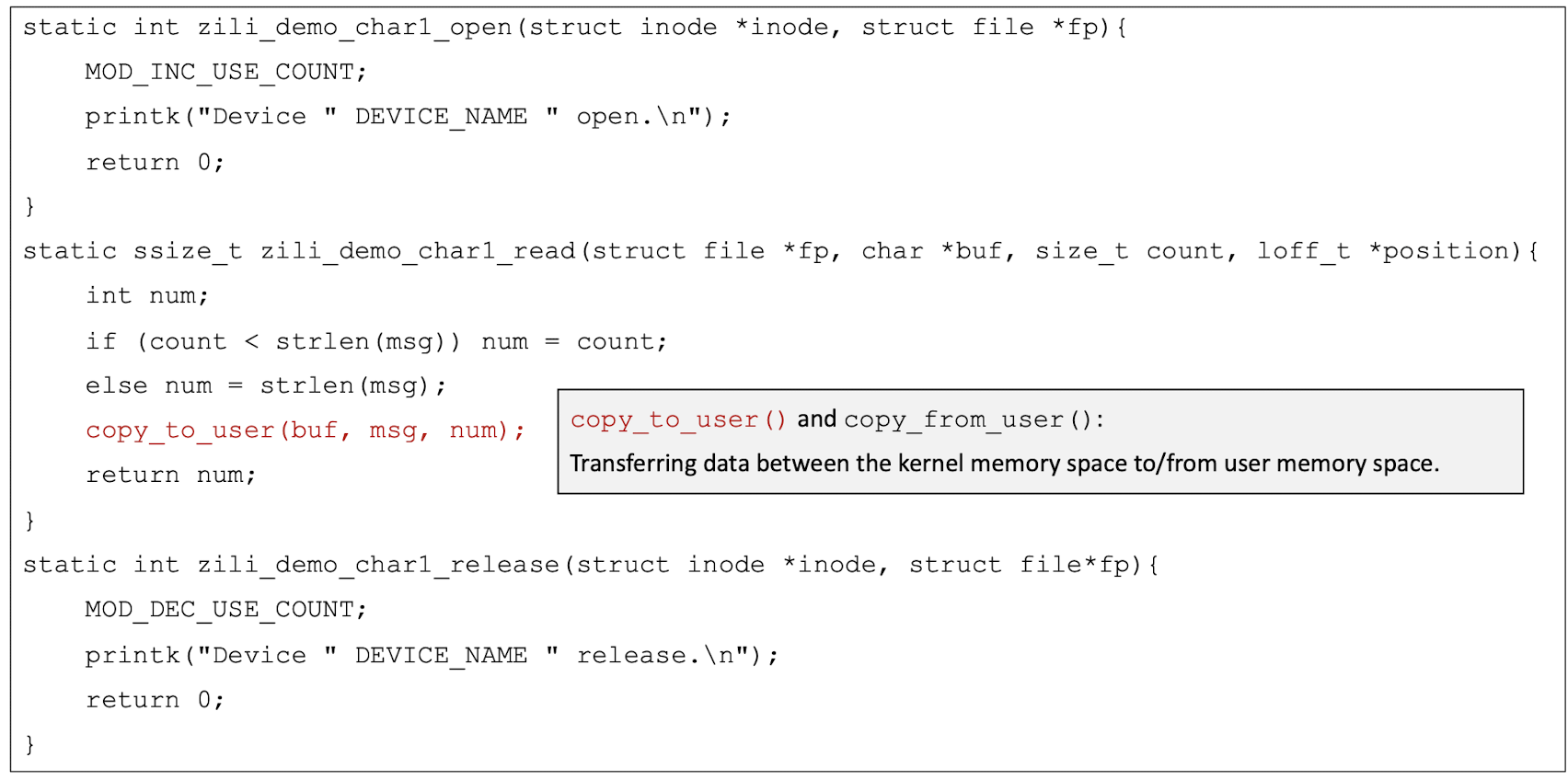
5.6 Kernel Memory Space and User Memory Space
The kernel virtual memory address space and user virtual memory address space are separate in Unix.
The resources that only kernel can access are also called the “kernel land“, while the resources that the user can access are also called the “user land“.
5.6 Register/Unregister a Character Device Driver
Register: inform the kernel that we have a set of generic interface functions implemented for a certain kind of device
1 | |
major: major number.
- If it is
0, the system will automatically assign an unused major number, and return it; - if it is
greater than 0, this function will attempt to reserve this number as the character device’s major number, andreturn 0 on success.
name: a charpointer to the name of this character device driver.
fops: a pointer to a file_operations structure, where pointers to the generic interface functions are stored.
Unregister: inform the kernel that the specified character device driver should be removed.
1 | |
major: major number of the character device.
name: a charpointer to the name of this character device driver.
“Hello World” Device Driver (Continued)
1 | |
1 | |
- The
file_operationsstructure is crucial as it tells the kernel which functions to call for different file operations (open, read, release, etc.). - The
__initand__exitmacros are used for constructor and destructor functions, respectively.- Functions marked with
__initare used only at initialization time and their memory is freed after the function finishes. - Functions with
__exitaren’t included in the kernel if the module isn’t compiled as a loadable module but built directly into the kernel.
- Functions marked with
5.7 Compile and Load/Unload
Linux provides a dynamic module load/unload method for device driver management.
Compile:
- Add module dependency relations into
MakefileandKConfig - Run command “
make menuconfig“ to set up the module as “dynamically load/unload“ - Run command “
make“
Load/Unload:
insmod xxx.kormmod xxx- where
xxxis the module name.
- where
how to compile a kernel module and insert or remove it from the kernel at runtime
5.8 Test
To the user land, devices are treated as files so we need to create a file for a device driver using command “mknod”, e.g.
1 | |
- The
mknodcommand is used to create the device file in the filesystem that user-space programs can open, leading to the invocation of the corresponding driver code in the kernel.
User programs access devices through file operation system calls, e.g.
1 | |
5.9 Application Program
1 | |
5.10 Summary
Two generic interfaces are provided for using devices in Unix:
- In the kernel, a generic interface is provided.
- For user programs, devices are treated as files.
To develop a device driver, basically we need to finish two tasks:
- Implement functionalities based on the generic interface
- Register the device driver into the kernel data structure (the char/block device driver table)
A simple device driver “Hello” has been provided as an example for understanding the internal of a character devciedriver.
6 Character Device Drivers II
6.1 Outline
Communication between device drivers and devices
Analysis for a simple character device driver – LED controller
comp_char_lab2_1.c- control one LED (GPIO_C5)comp_char_lab2_2.c- control three LEDs with minor numbers
Interrupts
Semaphores
6.2 Access/Control Devices through I/O Ports
Command/data registers of devices can be accessed through I/O ports from
- memory space (memory-mapped I/O)
- separate space (I/O space)
depending on the hardware,
e.g.
- ARM 32 – memory-mapped I/O
- Intel 32 – I/O space (independent and different from memory space)
6.3 Input/Output Ports of ARM 2410s
ARM 2410s has 117 multifunctional input/output port pins:
Part A (GPA) - 23 - pins output port
Part B (GPB) - 11 - pins input/output port
Part C (GPC) - 16 - pins input/output port
Part D (GPD) - 16 - pins input/output port
Part E (GPE) - 16 - pins input/output port
Part F (GPF) - 8 - pins input/output port
Part G (GPG) - 16 - pins input/output port
Part H (GPH) - 11 - pins input/output port
6.4 I/O Ports in ARM 2410s
I/O ports in ARM 2410s can be configured by software to meet various system configuration and design requirements.
For out LED drivers, we will use three I/O pins that are multifunctional:
| Pin | Functions | - |
|---|---|---|
| GPC 7 | Input/Output | LCDVF2 |
| GPC 6 | Input/Output | LCDVF1 |
| GPC 5 | Input/Output | LCDVF0 |
6.5 Multiplexed Ports
As most pins in ARM 2410s are multiplexed, we need to determine which function is selected before using it.
Usually there are three different registers for a port:
- Port Configuration Register – define which function
- Port Data Register
- If configured as output ports, data can be written to
- If configured as input ports, data can be read from
- Port Pull-up Register – enable/disable work without pin’s function setting (if we want to make pin’s setting function, this should be set up as disable, i.e. set the value to 1).
6.6 Registers for Port C (GPC) in ARM 2410s
For Port C, the three corresponding registers areGPCCON (configuration register), address: 0x56000020GPCDAT (data register), address: 0x56000024GPCUP (pull-up register), address: 0x56000028
6.7 I/O Setting by Macros in the System
Instead of accessing memory addresses for I/O setting, we can use a set of macros/functions provided by the ARM 2410s architecture dependent kernel source code for I/O setting. For example,
- We can configure Pin C5 as output with pull-up disabled by:
1 | |
- We can output one big “1” to Pin C5 by
1 | |
- These macros/functions are defined in the header file:
1
kernel-2410s/include/asm/arch/S3C2410s.h
6.8 Our LED Experiment
In our experiment, when we plug an LED board into the extension slot in a development set, the three pins, GPIO_C5, GPIO_C6, and GPIO_C7, are connected to three LEDs on the LED board.
Our LED driver is to control on/off of the LEDs by writing 0/1 to three pins (GPIO_C5/ 6 / 7).
6.9 Two Steps to Control Devices in Drivers
Step 1: In the initialization of a device driver, configure I/O ports based on functions needed.
Step 2: In the implementation for read/write/ioctl functions of a device driver, read/write from/to the corresponding ports.
For example, in our LED driver,
- in initialization, we configure the pin by
1 | |
- in write, we control LED by writing to GPIO_C5by
1 | |
6.9.1 Initialization in the LED Driver (comp_char_lab2_1.c)
1 | |
6.9.2 Control in the LED Driver (comp_char_lab2_1.c)
1 | |
6.10 Application Program
Suppose the major number is 251. Then create a file with the major number:
1 | |
1 | |
6.11 Minor Number
By assigning different minor numbers, we can use one device driver to control more than one devices.
An example can be found in the file comp_309_char_lab2_2.c
6.11.1 open() in comp_char_lab2_2.c
1 | |
6.11.2 write() in comp_char_lab2_2.c
1 | |
6.11.3 Initialization in comp_char_lab2_2.c
1 | |
6.12 Create Files with Different Minor Numbers
Suppose that the major number is 251 (after the driver is loaded into the kernel).
Create different files with different minor number but with the same major number:
1 | |
6.13 Application Program
1 | |
6.14 Interrupts
(Peripheral) devices usually have to deal with the external world and processing in devices may be very slow compared to the CPU.
To make devices and CPU work in parallel, we can use “interrupts”.
An interrupt is an asynchronous signal from hardware indicating the need for attention, or a synchronous event in software indicating the need for a change in execution.
In Linux, we need to register an interrupt and connect it with interrupt handler program.
1 | |
6.15 Race Conditions and Semaphores
Since an interrupt can happen at any time, it can cause the interrupt handler program to be executed in the middle of another program execution. The two programs may be accessing a piece of the same resource. Thus, race conditions must be handled.
The most common ways of protecting data from concurrent accesses are:
- Use spinlocks to enforce mutual exclusion
- Use a circular bufferand avoiding shared variables
- Use lock variables that are atomically incremented and decremented
- Note: use of semaphores should be avoided in driver code (in fact, avoided in any kernel code), why?
6.16 Summary
Devices can be controlled through I/O ports or mapped memory addresses (depending on the hardware)
Data and configuration manipulationson I/O ports or mapped memory addresses
- Configuration Register
- Data Register
- Pull-up Register
Two LED drivers are introduced to show how to write a simple char driver for LEDs
7 Block Device Drivers
Outline
- Introduction to Block Device Drivers
- A Simple Block Device Driver – Sbull (Simple Block Utility for Loading Localities, see “Block Device Driver Demo Source Code”).
7.1 Block Device Drivers
Provide accesses to devices that transfer data in fixed-size blocks.
Communicate with OS through a collection of fixed size buffers.
7.2 A Simple Block Device Driver –Sbull (Simple Block Utility for Loading Localities)
A device driver for RAM disk: a segment of RAM is treated as storage.
A simplified vesion from the book: Linux Device Driver (chapter 12 loading device driver), 2nd edition, Alessandro Rubini, Jonathan Corbet.
http://www.xml.com/ldd/chapter/book/ch12.html
7.3 Main functions of a block driver
Part I: Functions related to open, close, ioctl, check_media_change, and revalidate, defined in struct block_device_operations in <linux/blkdev.h>
Part II: Functions related to requests (strategy)
Part III: Functions related to module management (load or unload).
7.3.1 Functions in block_device_operations
1 | |
Note there are no “read”, ”write,” as they are handled by the kernel.
Boldface : will be reused.
Red: kernel function/structures
Red : important kernel functions/structures
7.3.2 Functions related to request (strategy)
1 | |


7.3.3 Important data structure
1 | |

7.3.4 Functions related to module management
1 | |

7.3.5 Functions related to module management
1 | |

Summary
Block device drivers provide accesses to devices that transfer data in fixed-size blocks.
Bascially, there are three parts in a block device driver:
- Part I: Functions related to
open,close,ioctl,check_media_change, andrevalidate, defined instruct block_device_operationsin<linux/blkdev.h> - Part II: Functions related to requests (strategy)
- Part III: Functions related to module management (load or unload).
A simple block device driver is introduced.
8. Overview of Compiler Design
Outline
Programming language: high-level vs. low level
What is a compiler?
Phases of a compiler
8.1 Programming Language: Machine Language
Everything is a binary number: operations, data, addresses, …
For example, in MIPS 2000:
0010 0100 1010 0110 0000 0000 0000 0100
which means:
$t5 + 4 - > $t
8.2 Programming Language: Assembly Language
Symbolic representations/mnemonics of machine language
For example, in MIPS 2000:
- 0010 0100 1010 0110 0000 0000 0000 0100
which means:
$t5 + 4 - > $t
In Assembly Code:
add $t6, $t5, 4
8.3 Programming Language: High-level Programming Language
High-level Programming Language: Benefits
- More human-readable.
- Hide unnecessary details, so have a higher level of abstraction, increased productivity.
- Make programs more robust, e.g., meaning of information is specified before its use, enabling substantial error checking at compile time.
- Make programs more portable.
High-level Programming Language: Translators
- Need a translator to translate high-level programming language into machine language.
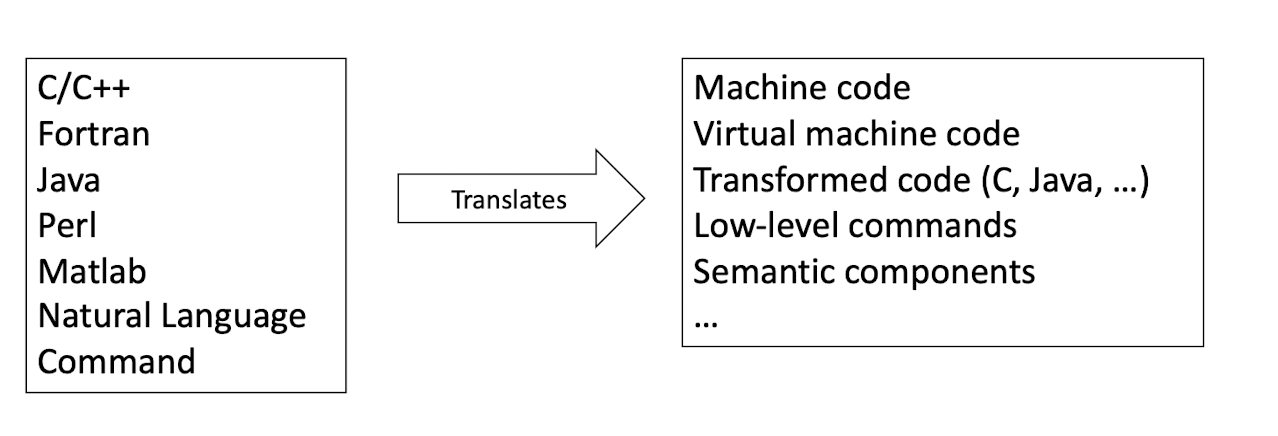
8.4 Translation Mechanisms
Different ways of translations
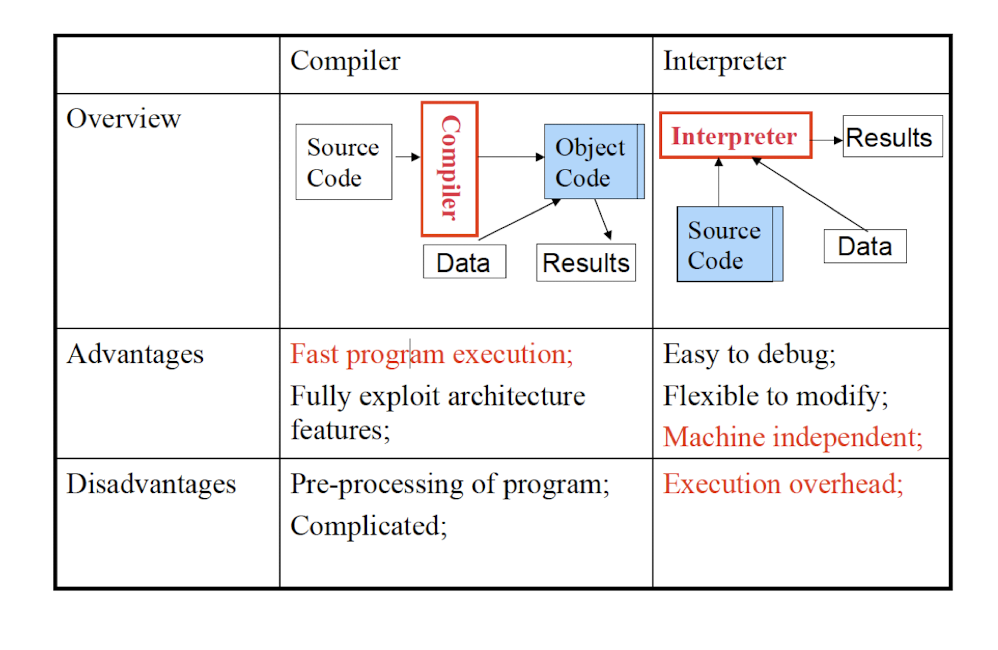
Development time translation: Compilation
- Translates source programs in one language into executable programs
- Examples: C, C++
- Listen the whole source program in once, all the way to the end, finaly to another language.
Runtime translation: Interpretation
- Read source programs, understand and produce execution results in the meantime.
- Examples: Perl, Shell commands
- Translate the source program line by line, and execute the line right away.
Hybrid: Compilation + Interpretation
- Example: Java, compiled into byte code, and then interpreted by JVM during runtime
8.5 Comparisons of Compiler/Interpreter
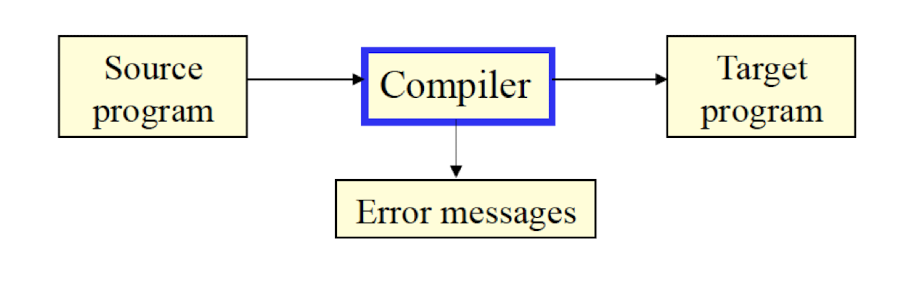
8.6 What is a compiler?
A compiler is a software that takes a program written in one language(called the source language) and translates it into another (usually equivalent) program in another language (called the target language).
It also reports errors (bugs) in the source program.
8.6.1 Phases of a Compilation
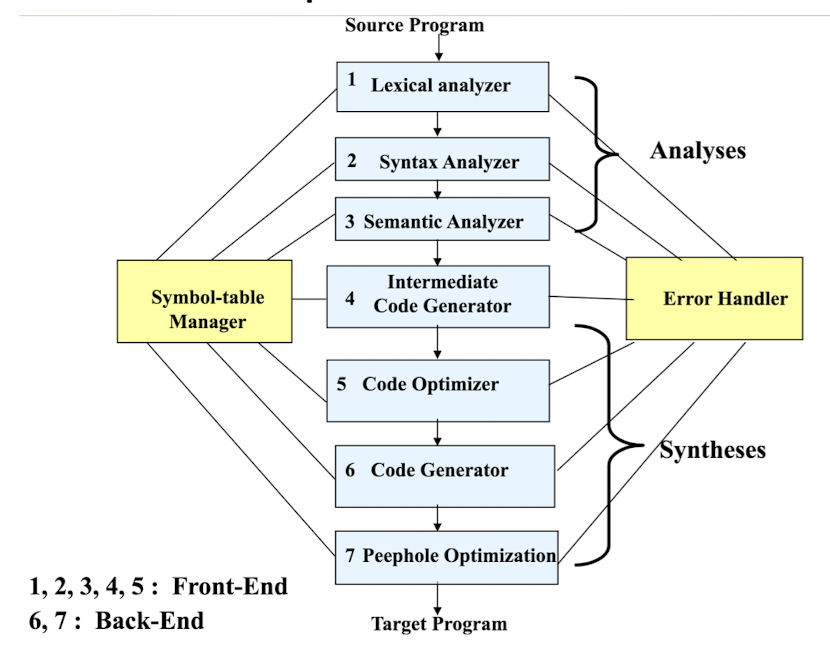
- The Symbol-Table manager and erroe handler are participated in all phases.
Lexical Analysis
Scan the source program and group sequences of characters into tokens.
A token is the smallest element of a language
- A group of characters (e.g., a series of alphabetic characters form a keyword; a series of digits form a number).
The sub-module of the compiler that performs lexical analysis is called a lexical analyzer.
- Example:
position := initial + rate * 60

Syntax Analysis
Once the tokens are identified, syntax analysis groups sequences of tokens into language constructs.
- e.g., identifiers, numbers, and operators can be grouped into expressions.
- e.g., keywords, identifiers, expressions, and operators can be combined to form statements.
The sub-module of the compiler that performs syntax analysis is called the parser/syntax analyzer.
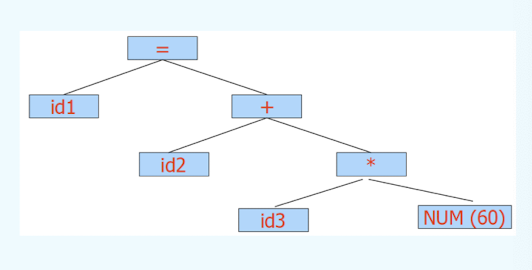
Syntax Analysis – Syntax (Parse) Tree
Result of syntax analysis is recorded in a hierarchical structure called a syntax tree.
- Each node represents an operation and its children represent the arguments of the operation.
- Evaluation begins from bottom and moves up.
- E.g., parse tree for position := initial + rate * 60
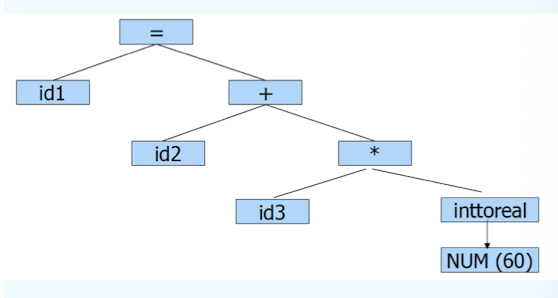
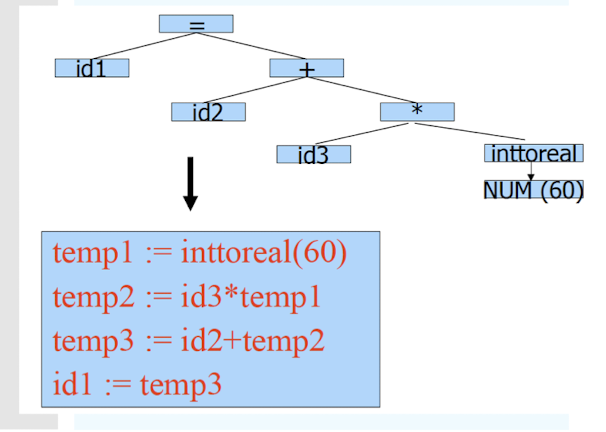
Intermediate Code Generation
Generate IR (Intermediate Representation) code:
- Easier to generate machine code from IR code.
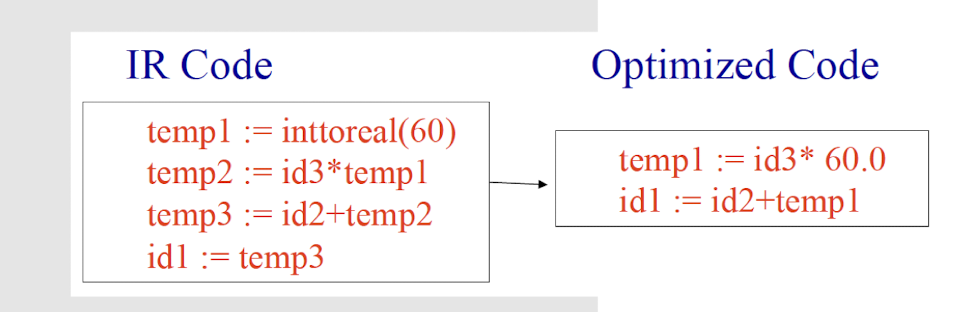
Code Optimization
Modify program representation so that program can run faster, use less memory, power, etc.
Code Generation
Generate the target program.

8.7 Symbol Table Management
Collect and maintain information about ID.
- Attributes:
- Storage: where to store (data, heap, stack, …)
- Type: char, int, pointer, …
- Scope: effective range
- Number: value
Information is added and used by all phases.
Debuggers use symbol table too.
8.7 Questions



NFA: Non-deterministic Finite Automaton, just like the human, unpredictable.
DFA: Deterministic Finite Automaton, like the Fan, to on and off
8.8 Distinction between Phases and Passes
Passes: the times going through a program representation. (2)
- 1-pass, 2-pass, multiple-pass compilation Language become more complex – more passes
Phases: conceptual stages, or modules of the compiler (7)
- Not completely separate: Semantic phase may do things that syntax should do
8.8 Compiler Tools
Phases
- Lexical Analysis
- Syntax Analysis
- Semantic Analysis
- Intermediate Code
- Code Optimization
- Code Generation
Tools:
- lex, flex
- yacc, bison
9. Lexical Analysis (I)
Outline
Part I: Introduction to Lexical Analysis
- Input (a source program) and output (tokens)
- How to specify tokens? Regular Expressions
- How to recognize tokens?
Regular Expression $\to$ Lex (software tool)
Regular Expression $\to$ Finite Automaton
Part II: Regular Expression
Part III: Finite Automata
9.1 Part I: Introduction to Lexical Analysis
Why we need lexical analysis? Its input and output.
How to specify tokens: Regular Expression
How to recognize tokens – two methods
Regular Expression $\to$ Lex (software tool)
Regular Expression $\to$ Finite Automata
9.1.1 Why we need lexical analysis?
Given a program, how to group the characters into meaningful “words”?
Example:
C program segment
1
2
3
4if (i == j)
z = 0;
else
z = 1;A string of characters stored in a file
if (i == j)\n\tz = 0;\nelse\n\tz = 1;
C program segment
9.1.2 Lexical Analysis (input and output)
In lexical analysis, a source program is read from left-to-right and grouped into tokens. A token is a sequence of characters with a collective meaning.
Input: source programif (i == j)\n\tz = 0;\nelse\n\tz = 1;
then
Lexical Analyzer:
Output: tokens
| Token | Lexeme (value) |
|---|---|
| keyword | if |
| ID | i |
| Operator | == |
| ID | j |
| … | … |
9.1.3 What is a token?
A syntactic category
- In English: a noun, a verb, an adjective, …
- In a programming language: an identifier, an integer value, a keyword, a white space, …
Tokens correspond to sets of strings with a collective meaning
- Identifier: strings of letters and digits, starting with a letter
- Integer value: a non-empty string of digits
- Keyword: else, if, where, …
Example: Expression (input and output)
((48*10) / 12)^
1 | |
Example: Mini Program (input and output)
1 | |
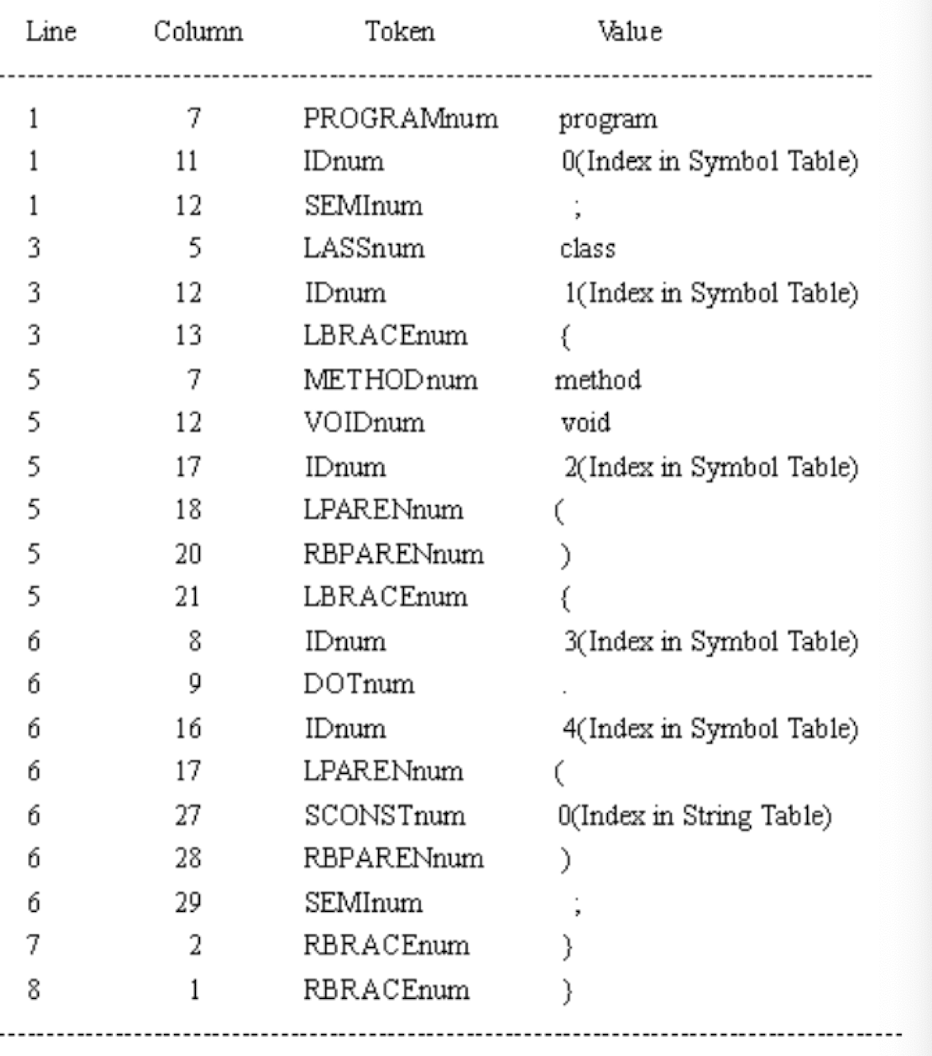
9.1.4 What are tokens for?
Classify program substrings according to their syntactic role.
As the output of lexical analysis, tokens are the input to the parser (syntax analysis)
- Parser relies on token distinctions
- e.g., a keyword is treated differently than an identifier.
9.1.5 How to recognize tokens (lexical analyzer)?
First, specify tokens using regular expressions (patterns)
Second, based on regular expression, there are two ways to implement a lexical analyzer:
- Method 1: use Lex, a software tool
- Method 2: use finite automata (write your own program)
10. Lexical Analysis (II)
Alphabet, Strings, Languages
Regular Expression
Regular Set (Regular Language)
10.1 Specifying tokens
A token is specified by a pattern: a set of rules that describe the formation of the token
The lexical analyzer uses the pattern to identify the lexeme: a sequence of characters in the input that matches the pattern. Once matched, the corresponding token is recognized.
Example:
- The rule (pattern) for identifier: letter followed by letters and digits
- abc1 and A1By match the rule (pattern), hence they are identifier tokens;
- 1A does not match the rule (pattern), hence it is not an identifier token.
Example: Rules, Tokens, Regular Expressions
The rules for specifying token patterns are called regular expression.
A regular set (regular language) is the set of strings generated by a regular expression over an alphabet.
What are alphabet, language, regular expression, regular set?
10.2 Alphabet and Strings
An alphabet (usually denoted as $\epsilon$) is a finite set of symbols.
- E.g. {0,1} is the binary digits alphabet;
- {a, b, … , z, A, B, … , Z} is the English letters alphabet.
A string s over an alphabet $\Sigma$ is a finite sequence of symbols drawn from that alphabet.
- E.g. 01001 is the string over $\sum_{\text{binDigits}}$ = { 0 , 1 };
- wxyzabc is the string over $\sum_{\text{lowerCaseLetters}}$ = {a, b, … , z};
- $\epsilon$ denotes the empty string (without any symbol).
The length of a string s is denoted as |s|. E.g. |$\epsilon$| = 0 ; | 101 | = 3 ; |abcdef| = 6.
10.3 Kleene Closure and Language
The Kleene closure of alphabet $\Sigma$, denoted as $\Sigma$∗, is the set of all strings, including the empty string $\epsilon$, over the alphabet $\Sigma$.
- E.g. given alphabet $\Sigma$ = { 0 , 1 }, then $\Sigma$∗ = {$\epsilon$, 0 , 1 , 00 , 01 , 10 , 11 , 000 , 001 , … }.
Any set of strings over an alphabet $\Sigma$, i.e. any subset of $\Sigma$∗ , is called a language.
- E.g. the empty set ∅, {$\epsilon$}, $\Sigma$, and $\Sigma$∗ are all languages;
- {abc, Def, D, z} is a language over $\sum_{\text{letters}}$ = {a, b, … , z, A, B, … , Z}.
10.4 Operations on languages
A language is a set, so all set operations can be applied to languages.
Particularly union, concatenation, Kleene closure, and positive closure.

10.5 Operations on languages: precedence
Kleene closure ≻ concatenation ≻ union
E.g. { 1 }|{ 2 }{ 3 }∗
Exponentiation (concatenating the same language) ≻ multiplication (concatenating different/same languages) ≻ addition (union)
E.g. 1 + 2 $\cdot{}$ { 3 }$^2$
Examples for operations on languages
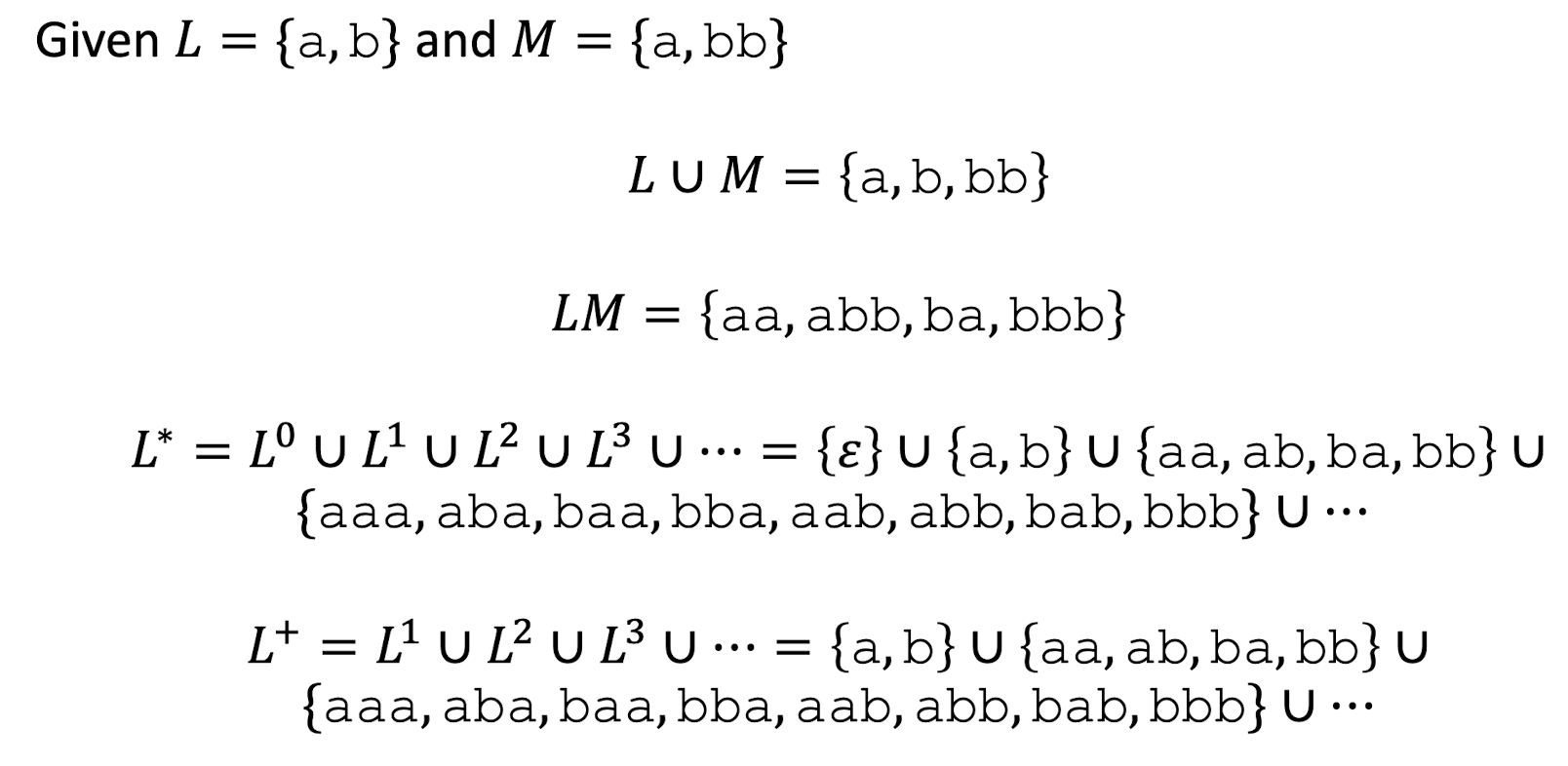

10.6 Defining regular expressions
The rules defining regular expressions over alphabet $\Sigma$:
- The empty string $\epsilon$ is a regular expression that denotes language {$\epsilon$}.
- A single symbol a $\in$ $\epsilon$ is a regular expression that denotes language {a}.
- Suppose 𝑟 and s are regular expressions denoting languages L(r) and L(s), then
- 3.1. (r)|(s)is a regular expression denoting $L(r) \cup L(s)$;
- 3.2. r(s) is a regular expression denoting $L(r)L(s)$;
- 3.3. r is a regular expression denoting $(L(r))^$;
- 3.4. (r) is a regular expression denoting $(L(r))$.
Examples of regular expressions

10.7 Regular Set, Regular Expression, and Regular Definition
Regular Set (Regular Language)
Each regular expression r denotes a language L(r) , which is called a regular set (aka regular language).
- E.g., given $\Sigma$ = {a, b}, then a|b denotes the regular set {a, b}.
Regular definition: give distinct names $d_1, d_2$, … for regular expressions $r_1, r_2$, …
- E.g., $d_1 \to r_1, d_2 \to r_2, …$
Example: Identifier in Pascal
Pascal identifier: a string of letters and digits beginning with a letter.
Regular definition:
LETTER $\to$ A | B |… | Z | a | b … |z
DIGIT $\to$ 0 | 1 … | 9
ID $\to$ LETTER (LETTER DIGIT)∗
Example: Unsigned Numbers in Pascal
Unsigned numbers in Pascal are strings such as 5230 , 39.37, 6.336E4, or 1.89E- 4.
Regular definition:
- DIGIT $\to$ 0 1 … | 9
- DIGITS $\to$ DIGIT DIGIT∗
- OPTIONAL_FRAC $\to$ .DIGITS|$\epsilon$
- OPTIONAL_EXP $\to$ (E(+|−|$\epsilon$)DIGITS)|$\epsilon$
- NUM $\to$ DIGITS OPTIONAL_FRAC OPTIONAL_EXP
10.8 Notation Shorthands
One or more instances: $r^+$ ≝ $rr^*$
Zero or one instance: $r?$ ≝ $r|\epsilon$
Character classes: $[a-z]$ ≝ a | b | c| … |z, $[0-9]$ ≝ 0 1 | … | 9
E.g., original regular expression for unsigned numbers:
DIGIT $\to$ 0 1 … | 9
DIGITS $\to$ DIGIT DIGIT∗
OPT_FRAC $\to$ .DIGITS|$\epsilon$
OPT_EXP $\to$ (E(+|−|$\epsilon$)DIGITS)|$\epsilon$
NUM $\to$ DIGITS OPT_FRAC OPT_EXP
Regular expression for unsigned numbers with notation shorthands:
DIGITS $\to$ [ 0 − 9 ]$^+$
OPT_FRAC $\to$ (.DIGITS)?
OPT_EXP $\to$ ((E|+|−)? DIGITS)?
NUM $\to$ DIGITS OPT_FRAC OPT_EXP
10.9 Recognize tokens
Given a string s and a regular expression r, is $s \in L(r)$?
E.g., suppose $\epsilon$ = {a, b}, then a|b is a regular expression.
- String $aa \notin L(a|b)$
- String $a \in L(a|b)$
10.10 Implementation of Lexical Analysis
After regular expressions are obtained, we have two methods to implement a lexical analyzer:
Use tools: lex (for C), flex (for C/C++), jlex (for Java)
- Specify tokens using regular expressions
- Tool generates source code for the lexical analysis
Use regular expressions and finite automata
- Write code to express the recognition of tokens
- Table drivern
10.11 Lex: a lexical analyzer generator
Lex is a Unix software tool (developed by M. E. Lesk and E. Schmidt from Bell Lab in 1972) that automatically constructs a lexical analyzer.
Input: a specification containing regular expressions written in the Lex language.
- Assumes that each token matches a regular expression.
- Need an action specification for each expression.
Output: Produces a C program that can recognize the matching tokens and trigger the specified actions.
Especially useful when coupled with a parser generator (e.g. Yacc).
How does Lex work
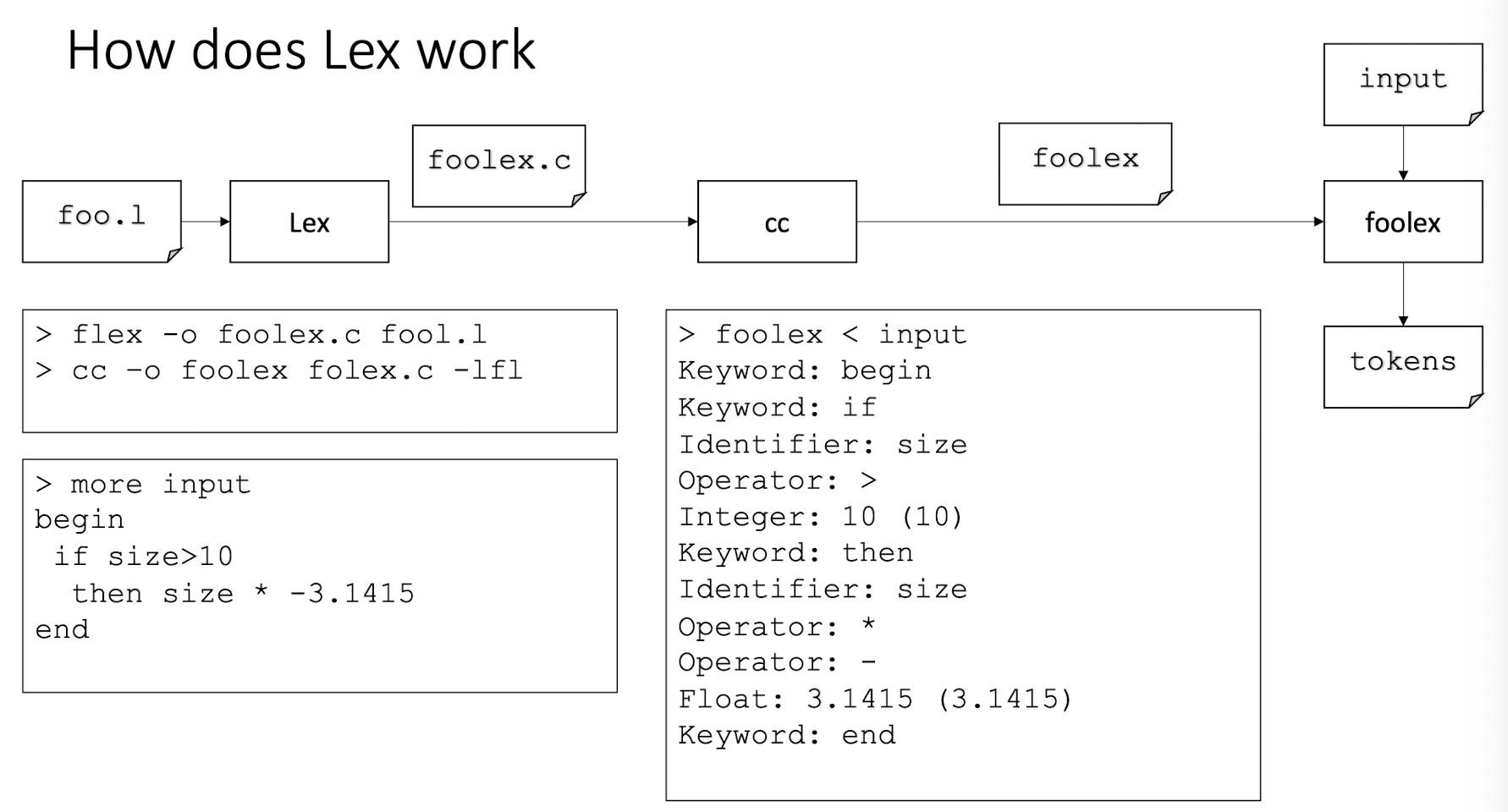
10.12 Exercise



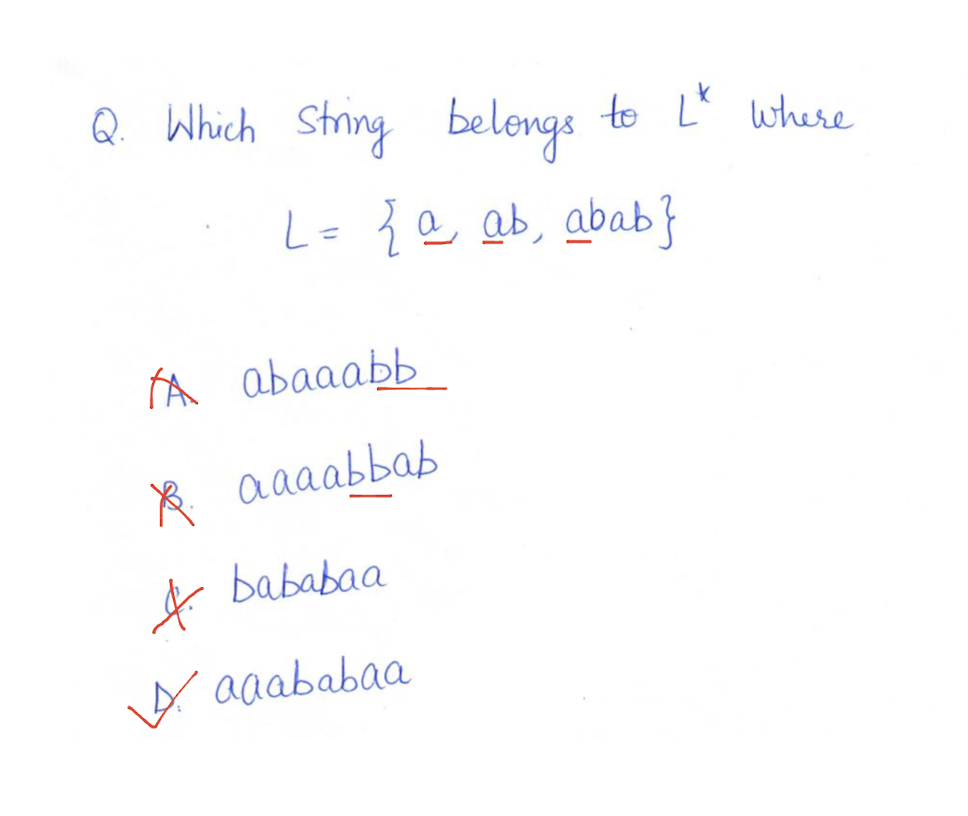
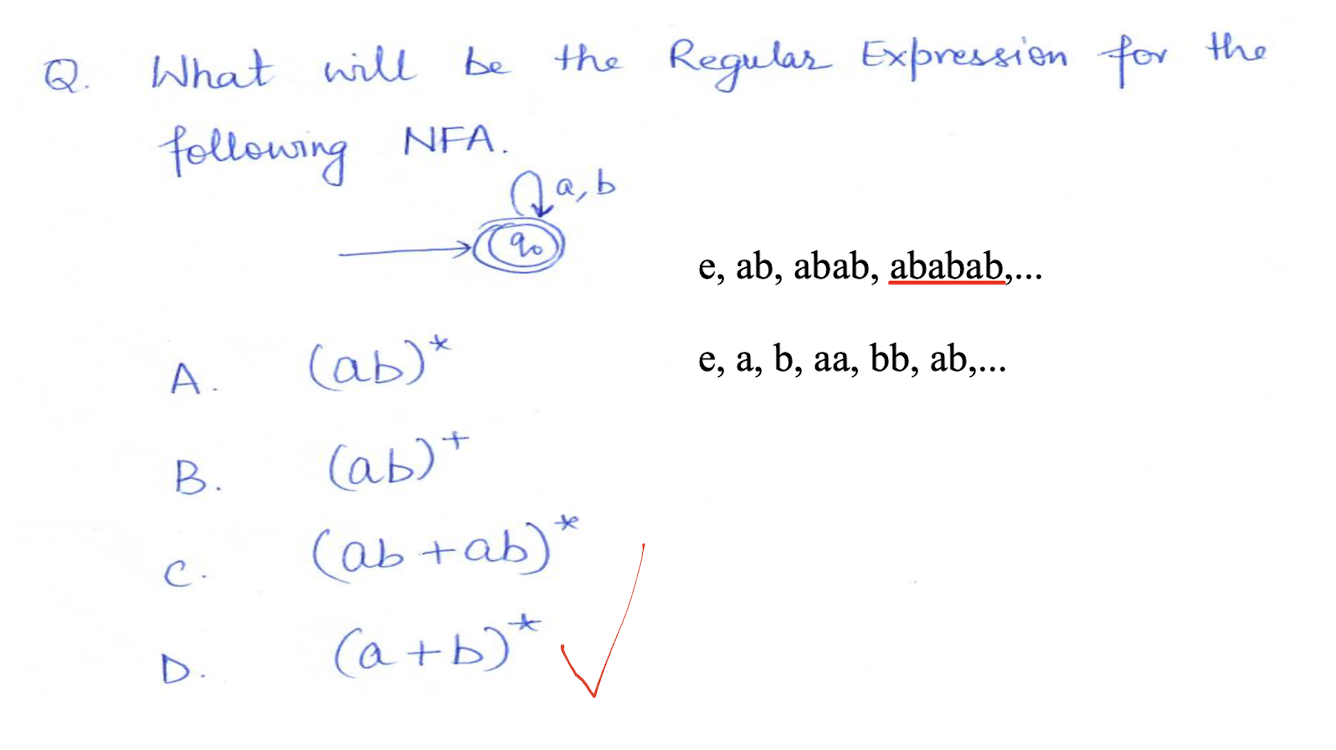
11. Lexical Analysis (III)
11.1 Review of the previous lectures
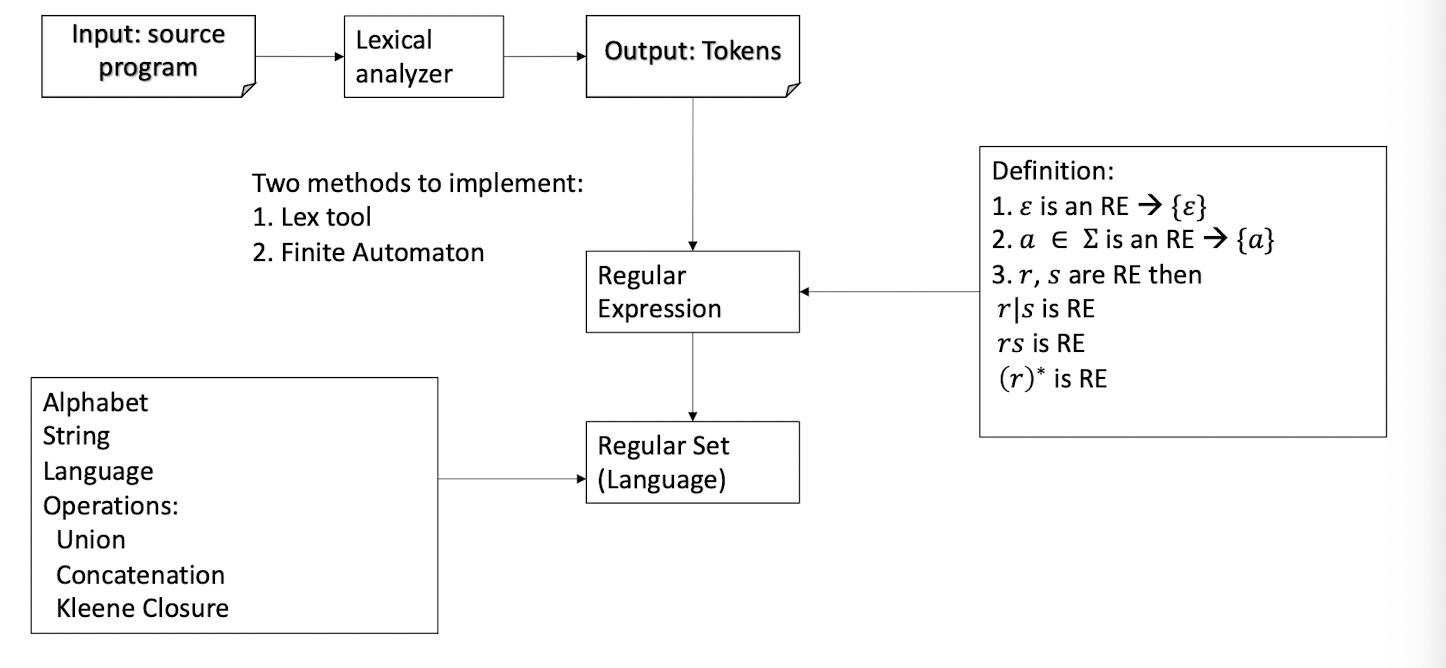
11.2 Outline
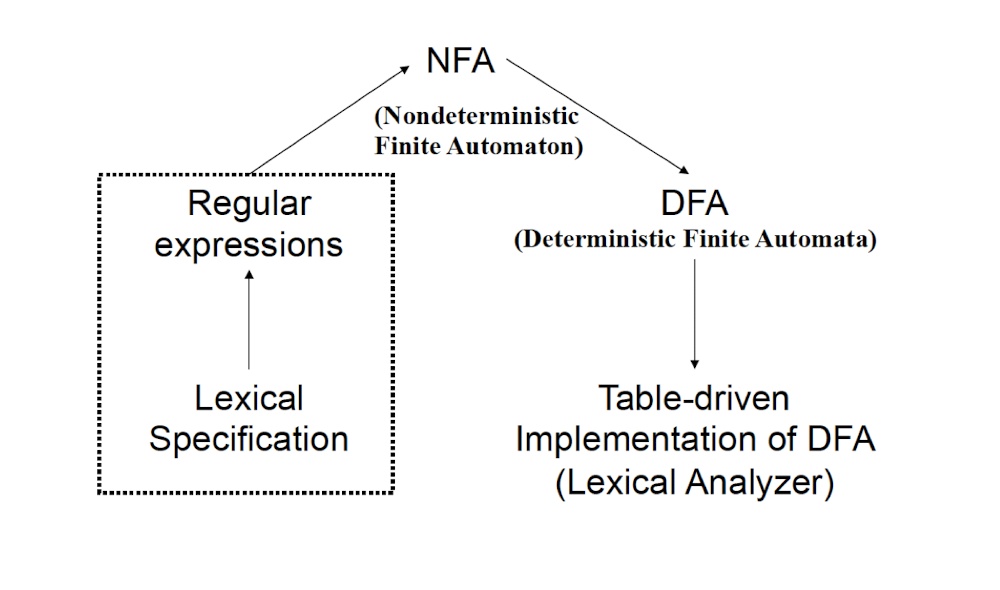
11.3 Part III-1: NFA, DFA, and NFA$\to$DFA Conversion
11.3.1 Recognizing Tokens
- Regular Expression $\to$ Specify tokens
Finite Automaton $\to$ Recognize tokens
A language recognizer:

- A recognizer for a language L is a program that takes a string x and answers “yes” if x is a string of L, and “no” otherwise.
11.3.2 Nondeterministic Finite Automata (NFA)
A Nondeterministic Finite Automaton (NFA) consists of 5 components ($\Sigma$, S, $s_0$ , F, move).
- $\Sigma$ is the input alphabet
- S is the set of states
- $s_0$ is the start state
- F $\subseteq$ S is the set of accepting states
- move is the transition function that maps state-symbol pairs to sets of states.
11.3.3 Transition Graphs (graphical representation of an NFA)

- A state
- The start state
- An accepting state
- A transition
- A simple example: a finite automaton that accepts only “ 1 ”
More Examples
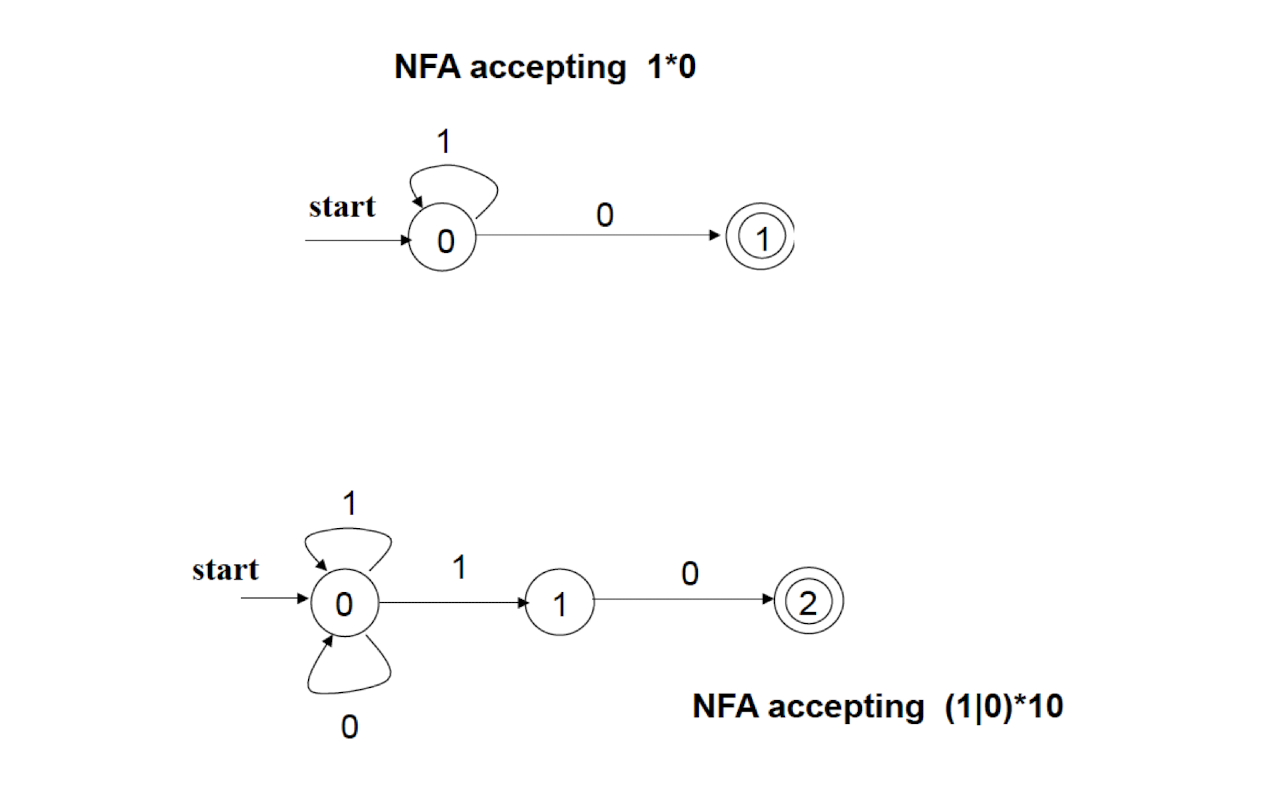
11.3.4 State Transition Table
The transition function of an NFA can also be implemented by a transition table, where the entries of rows are states and columns, respectively.
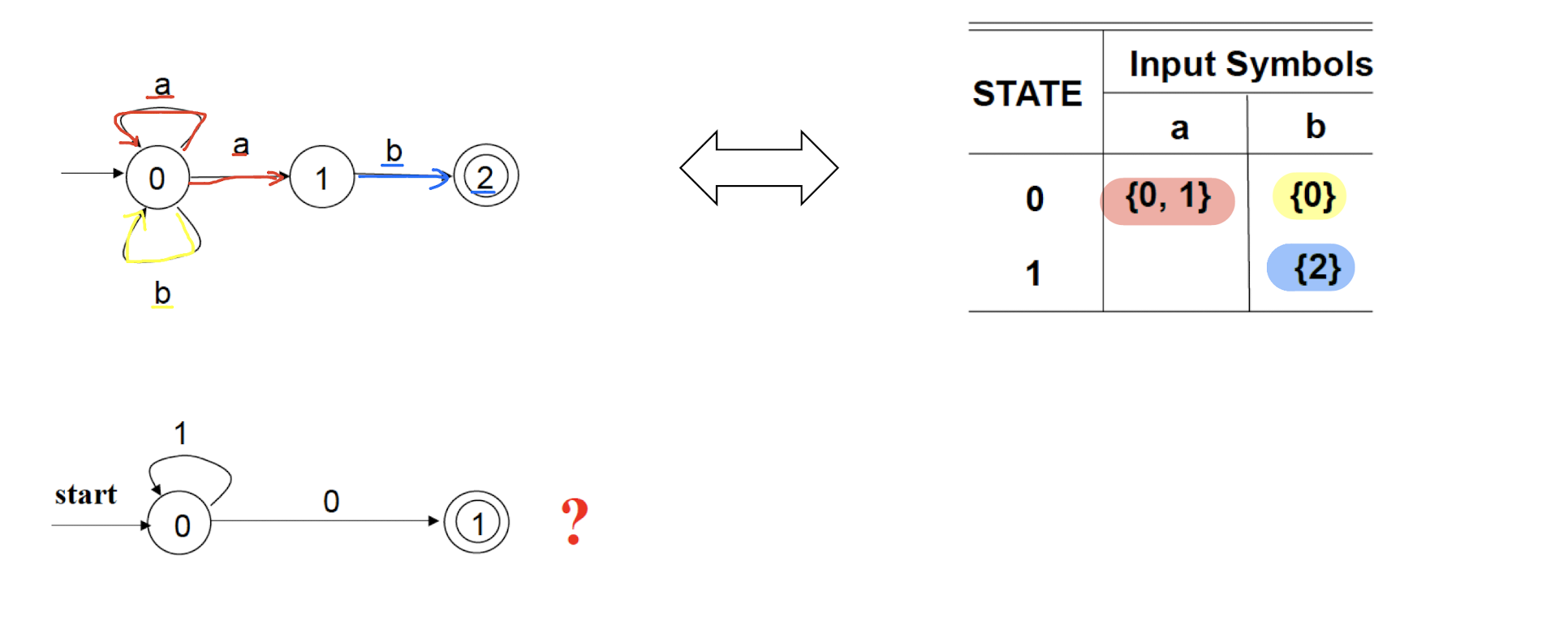
| STATE | 0 | 1 |
|---|---|---|
| 0 | {1} | {0} |
Input: 0 | 1
S0: {1} | {0}
11.3.5 $\epsilon$-Transition
Another kind of transition, where the automaton transits from one state to another state without reading any input.

Example: NFA accepting 00|11
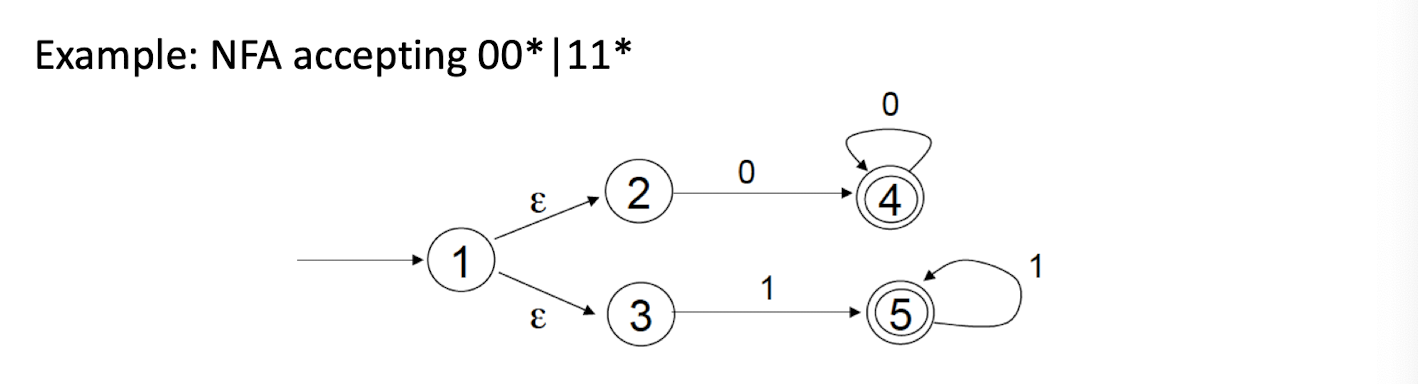
11.3.6 NFA based recognitions (decisions) are hard to implement
Can have multiple transitions from one input in a given state
Can have $\epsilon$-transitions
Easy to form from regular expressions
Hard to implement the recognition (decision) algorithm
Another kind of finite automata:
- Deterministic Finite Automata (DFA)
11.3.7 Deterministic Finite Automata
A DFA is a special case of NFA:
- One transition per input per state
- No $\epsilon$-transitions
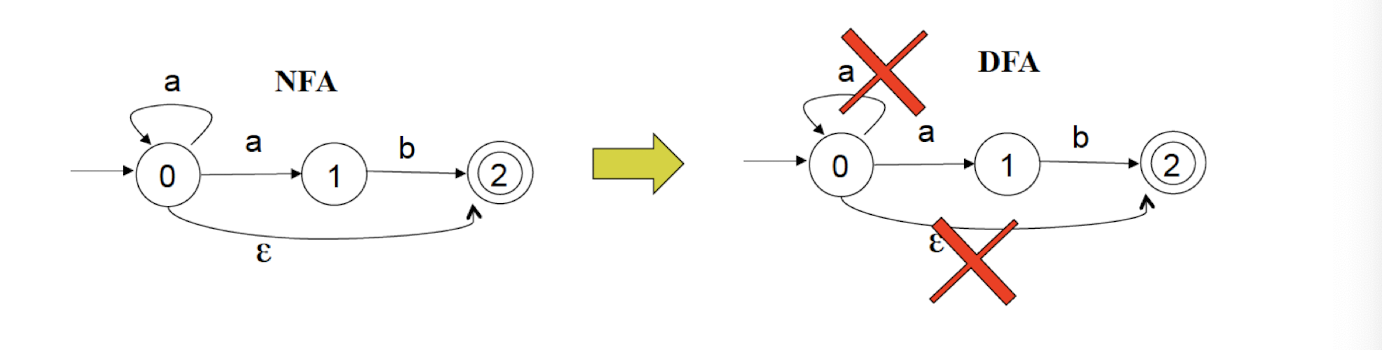
Examples of NFA and DFA
NFA: Easy to generate strings.
DFA: Easy to both generate and recognize strings.
NFA: May go to anyone of several states given an input symbol.
DFA: Goes to only one deterministic state given an input symbol.
NFA: May go to another state when there is no input, due to $\epsilon$-transition(s).
DFA: Does not go anywhere when there is no input; does not have any $\epsilon$-transition.
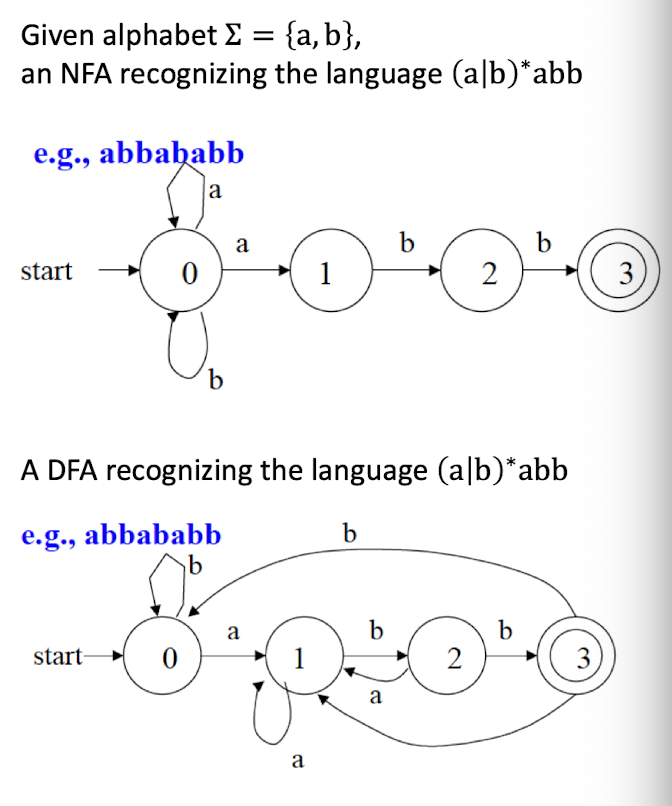
11.3.8 Table Implementation of DFA
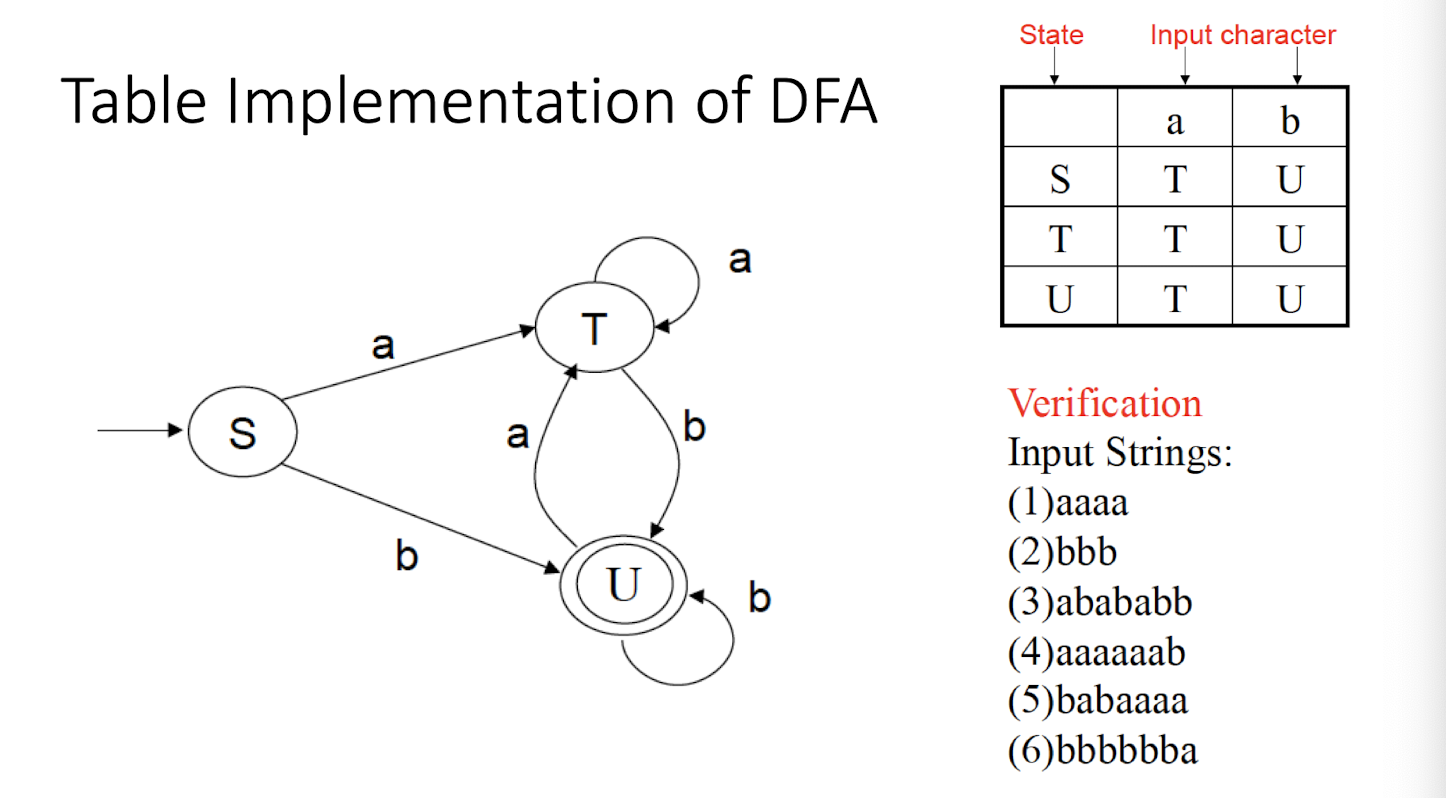
- only end with ‘b’
11.3.9 Algorithm: Simulating a DFA
Input: input string x terminated by an end-of-file character eof;
- DFA D with start state s” and set of accepting states F.
Output: The answer “yes” if D accepts x, “no” otherwise.
Method: Apply the following algorithm to the input string x.
- move(s, c) gives the state to which there is a transition from state s to input c.
- nextchar returns the next character of the input string x.

11.3.9 Regular Expression to NFA
Every Regular Expression can be converted to an NFA, following the elementary
rules:
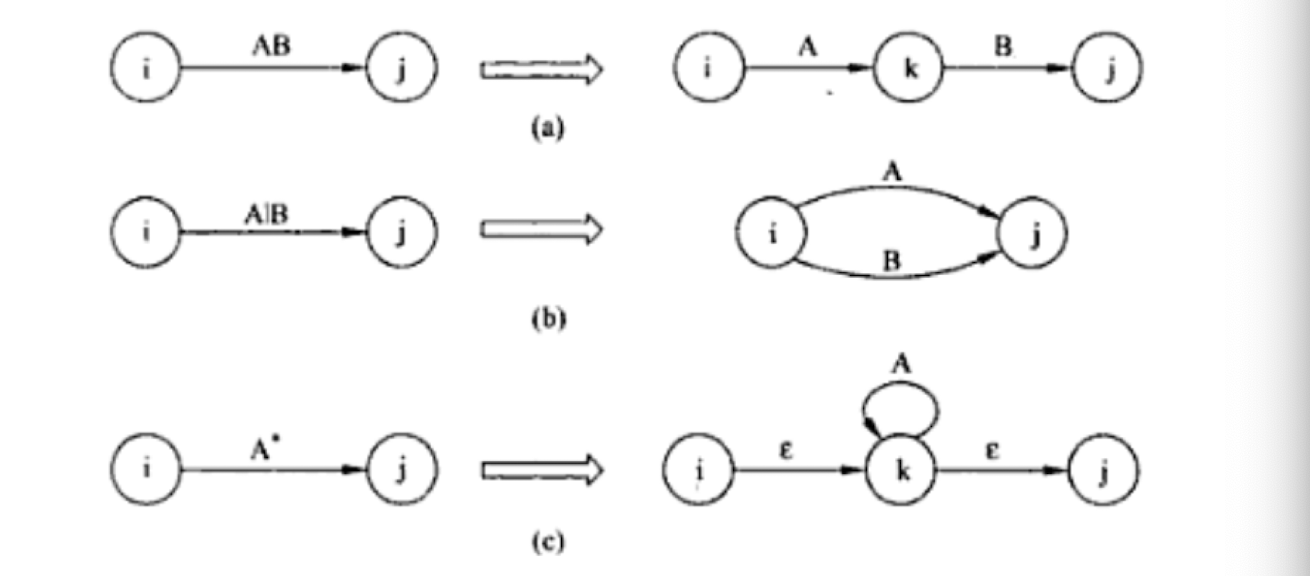
Example: regular expression to NFA
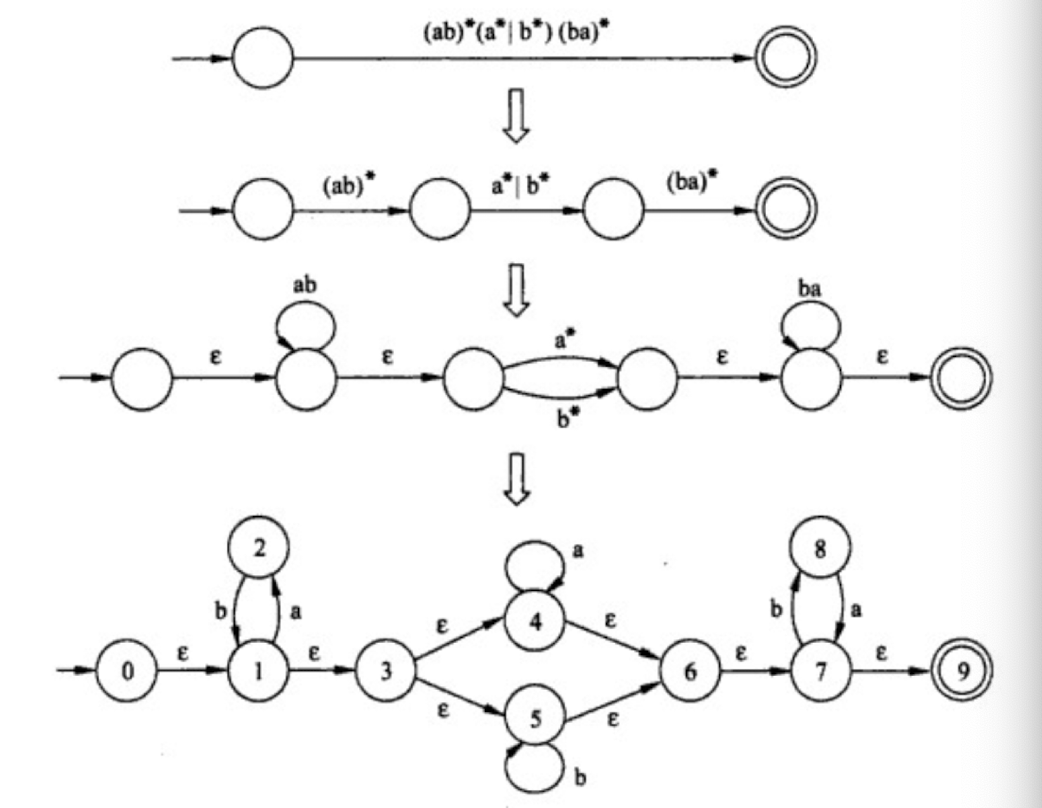
11.3.10 NFA to DFA
A DFA is a special case of NFA. The conversion of an NFA to a DFA needs to meet the two requirements on DFA:
- $\epsilon$-closure(s): the set of all states reachable from s on $\epsilon$-transition (to meet the no $\epsilon$-transition requirement of DFA).
- Regard all reachable states from one state on one input symbol as one state (to meet the one transition per input per state requirement of DFA).
NFA $\to$ DFA Conversion Algorithm

11.3.11 States of DFA obtained from NFA
An NFA may be in many states at any time.
If there are N states, the NFA must be in some subset of those N states.
How many subsets are there?
- Given a set of N elements, it has $2^N$ subsets. The DFA can have at the most $2^N$ states, where N is the number of states of the NFA.
11.4 Part III-2: Regular Expression to NFA
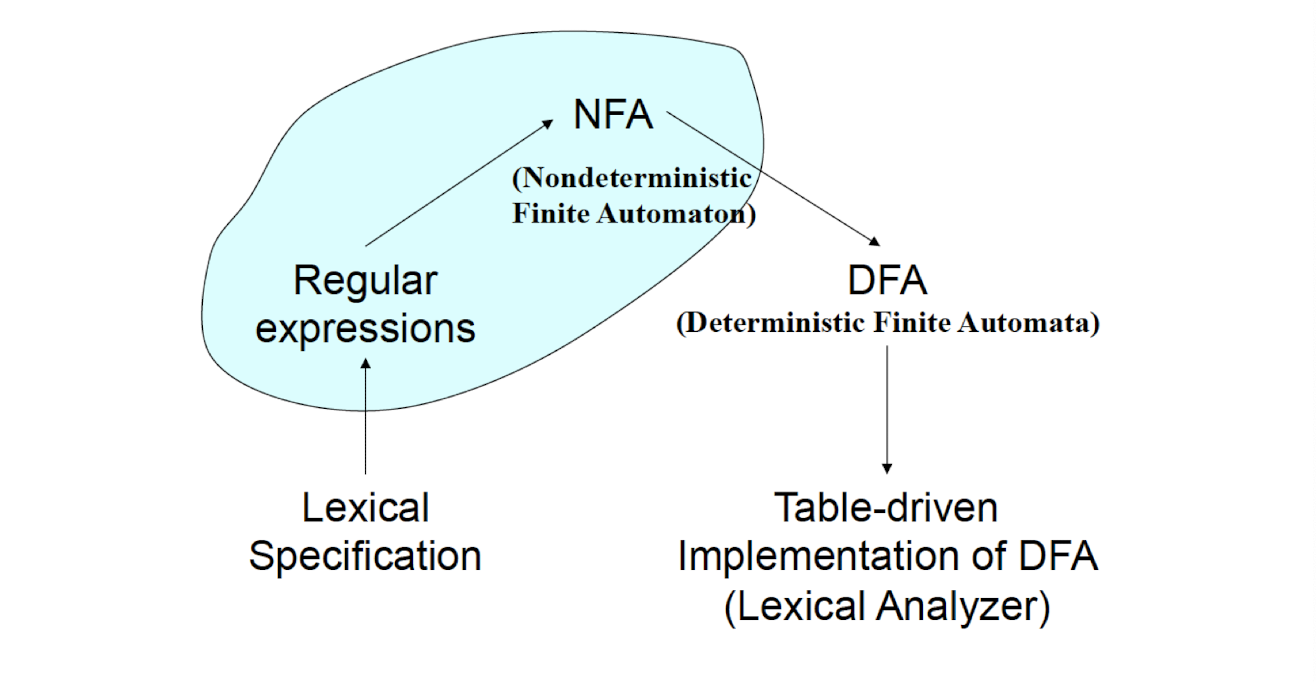
Algorithm to convert a regular expression to an NFA (Thompson’s construction)
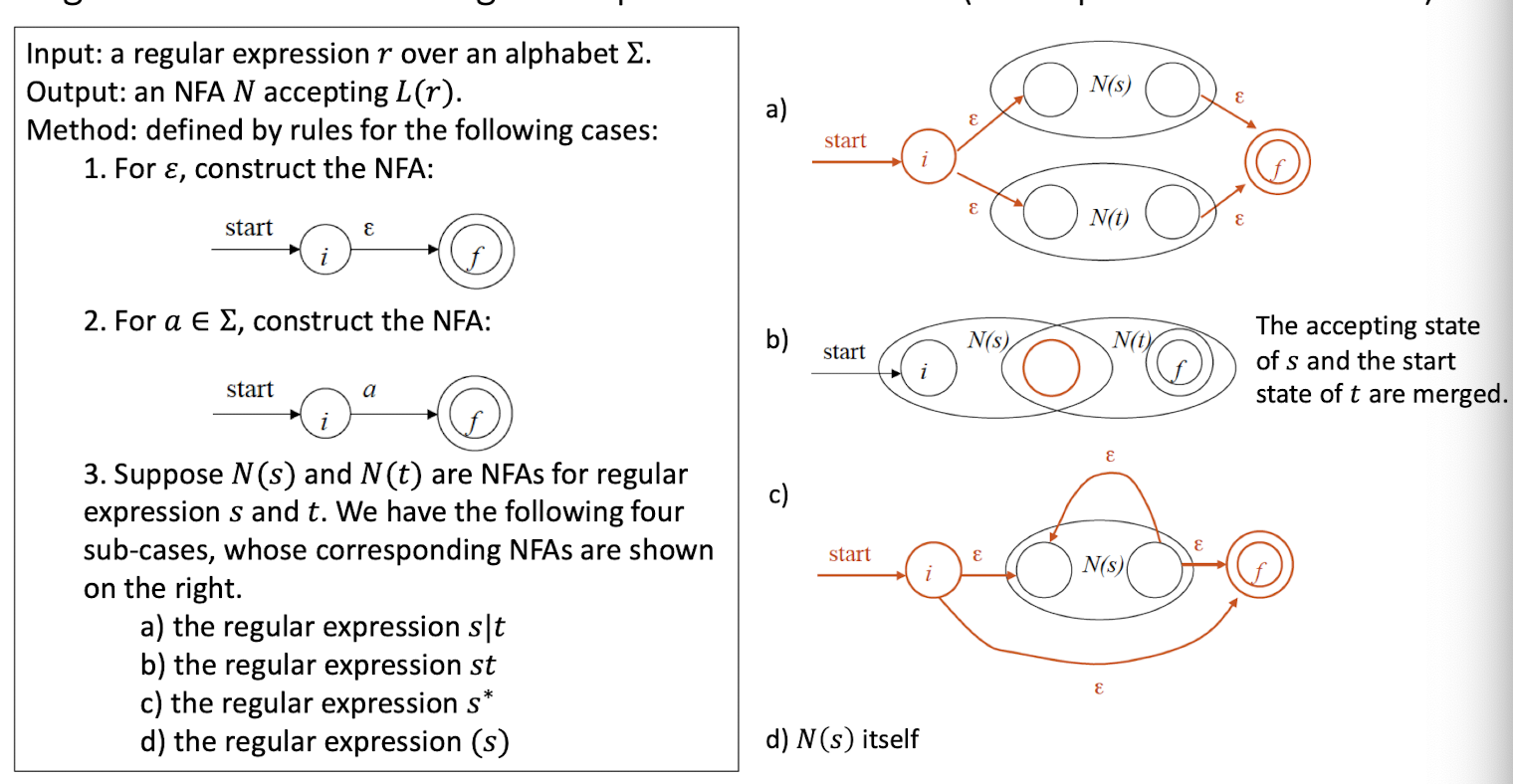
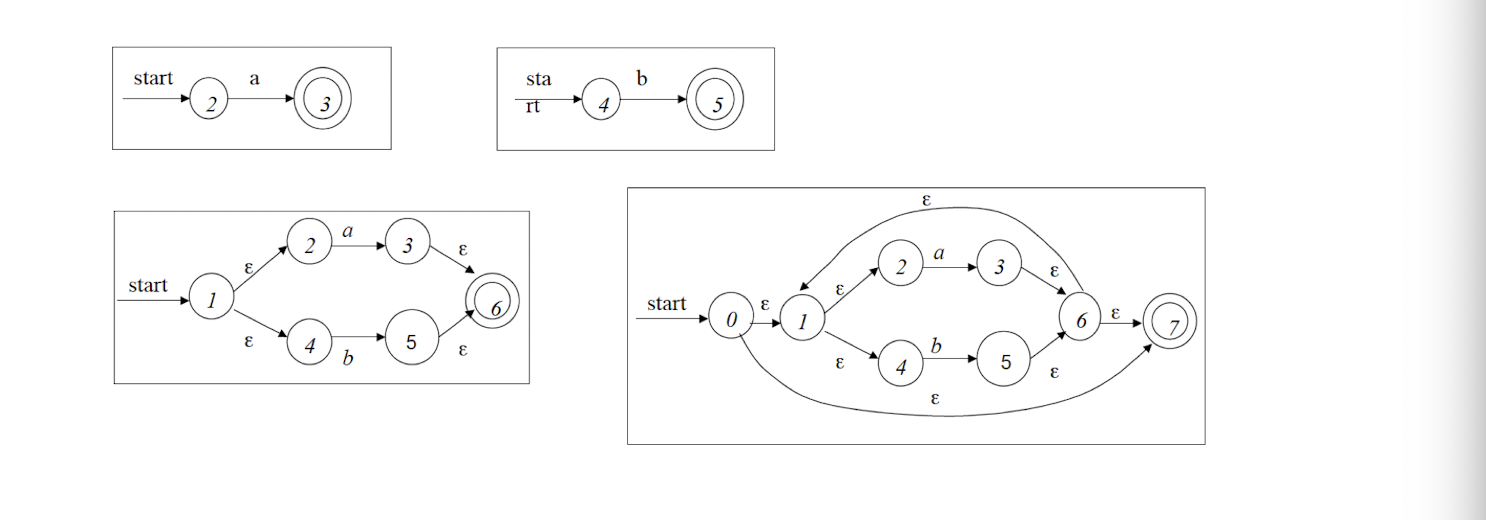
a
b
a|b
(a|b)*

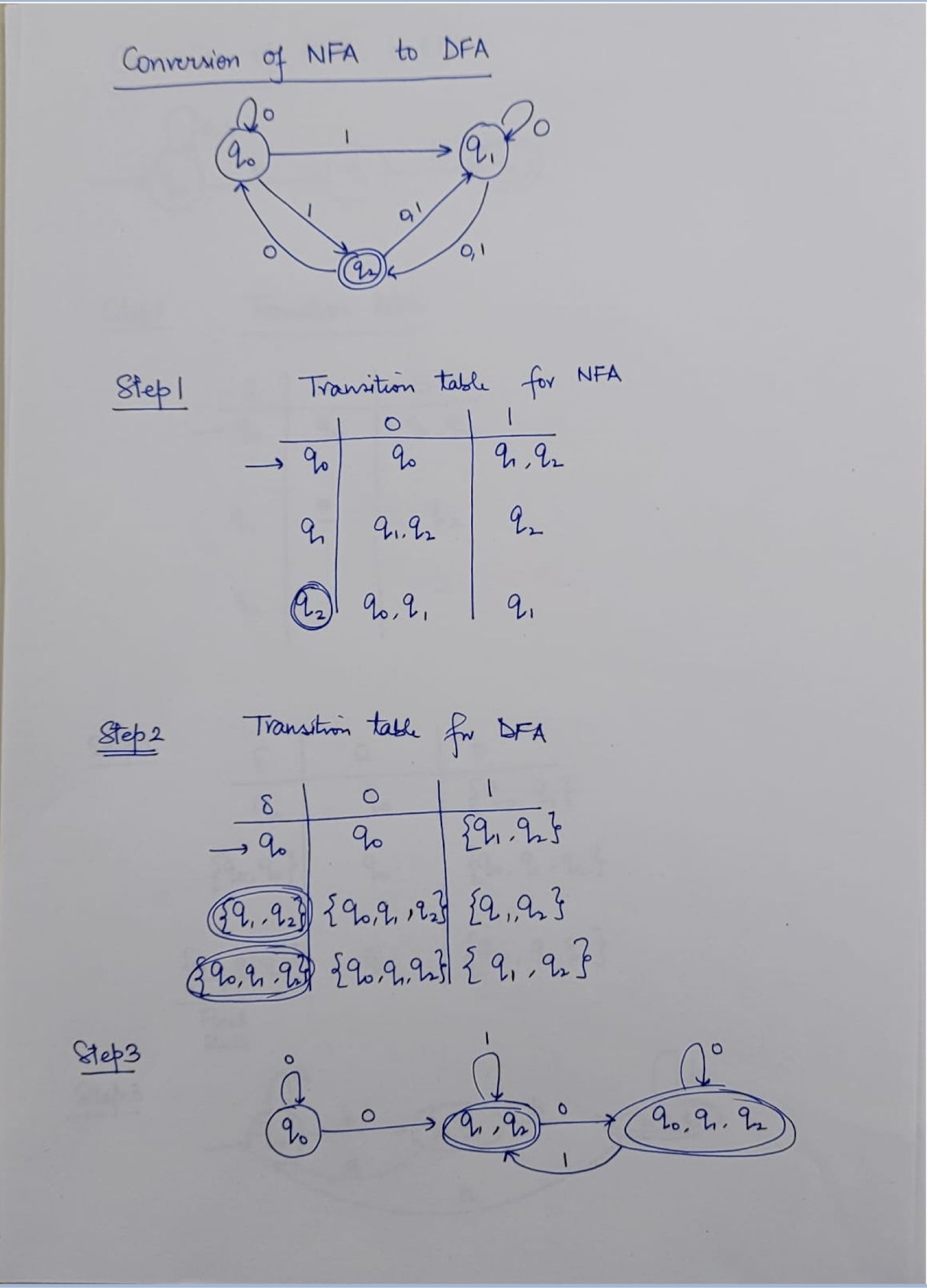
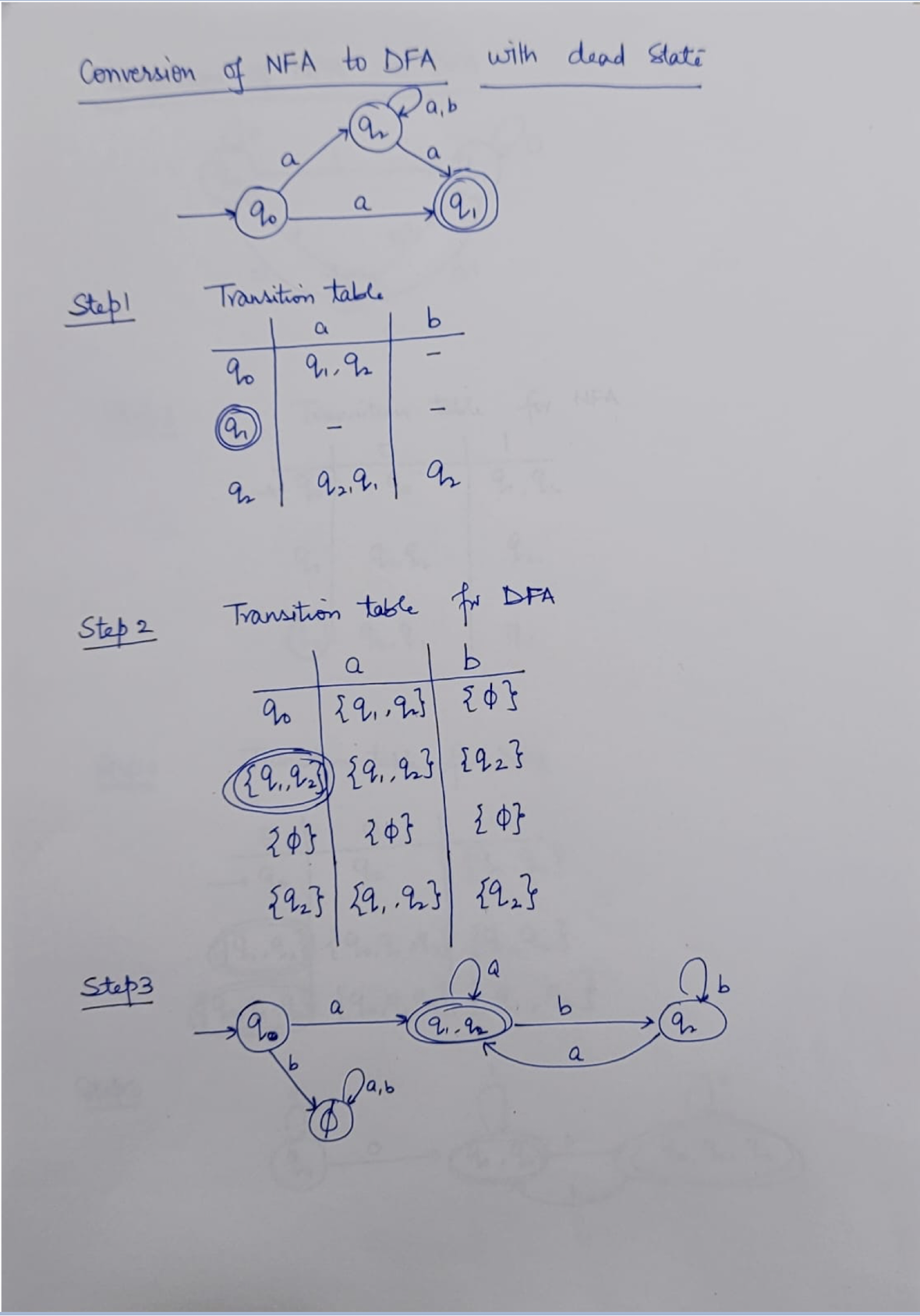
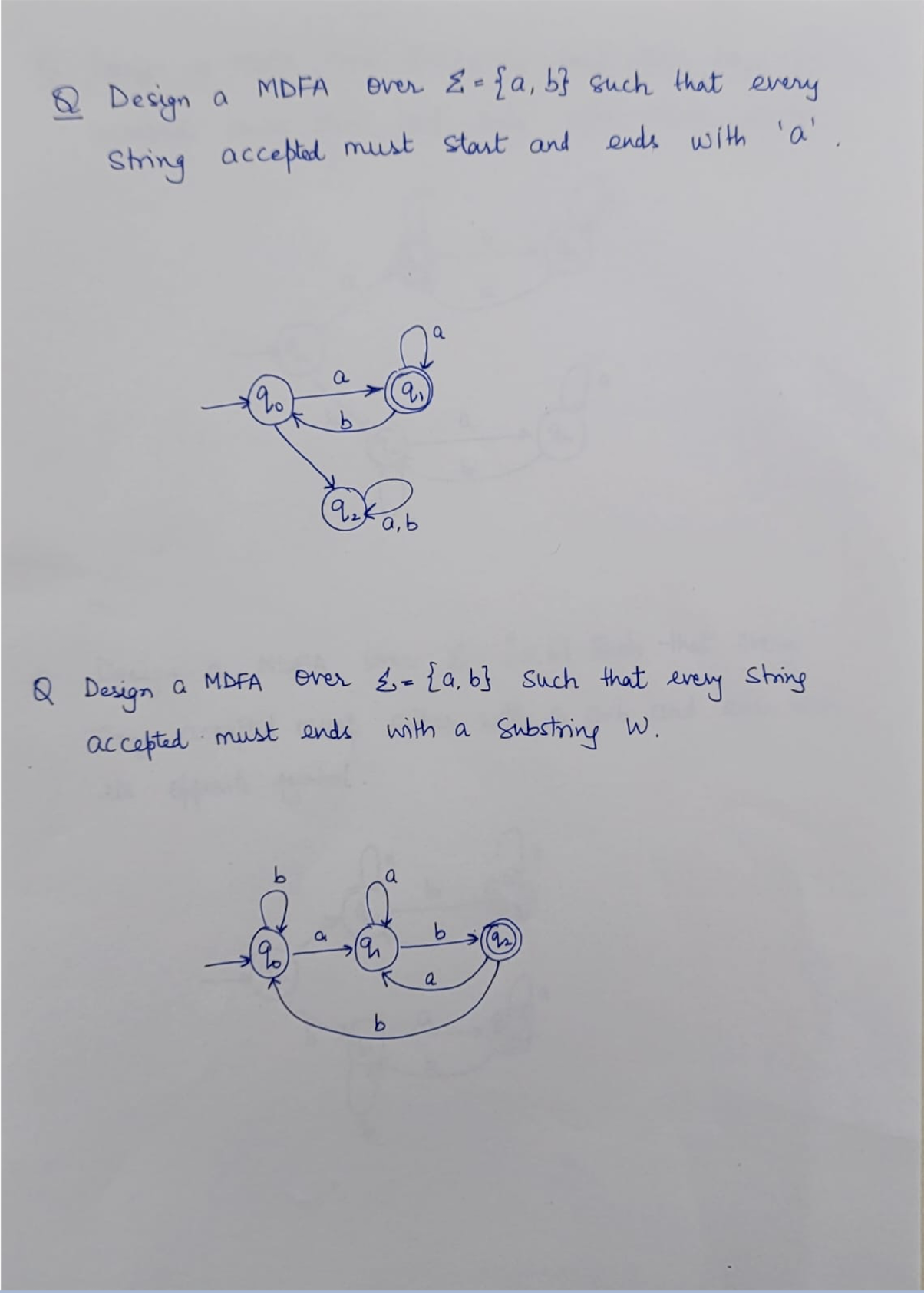
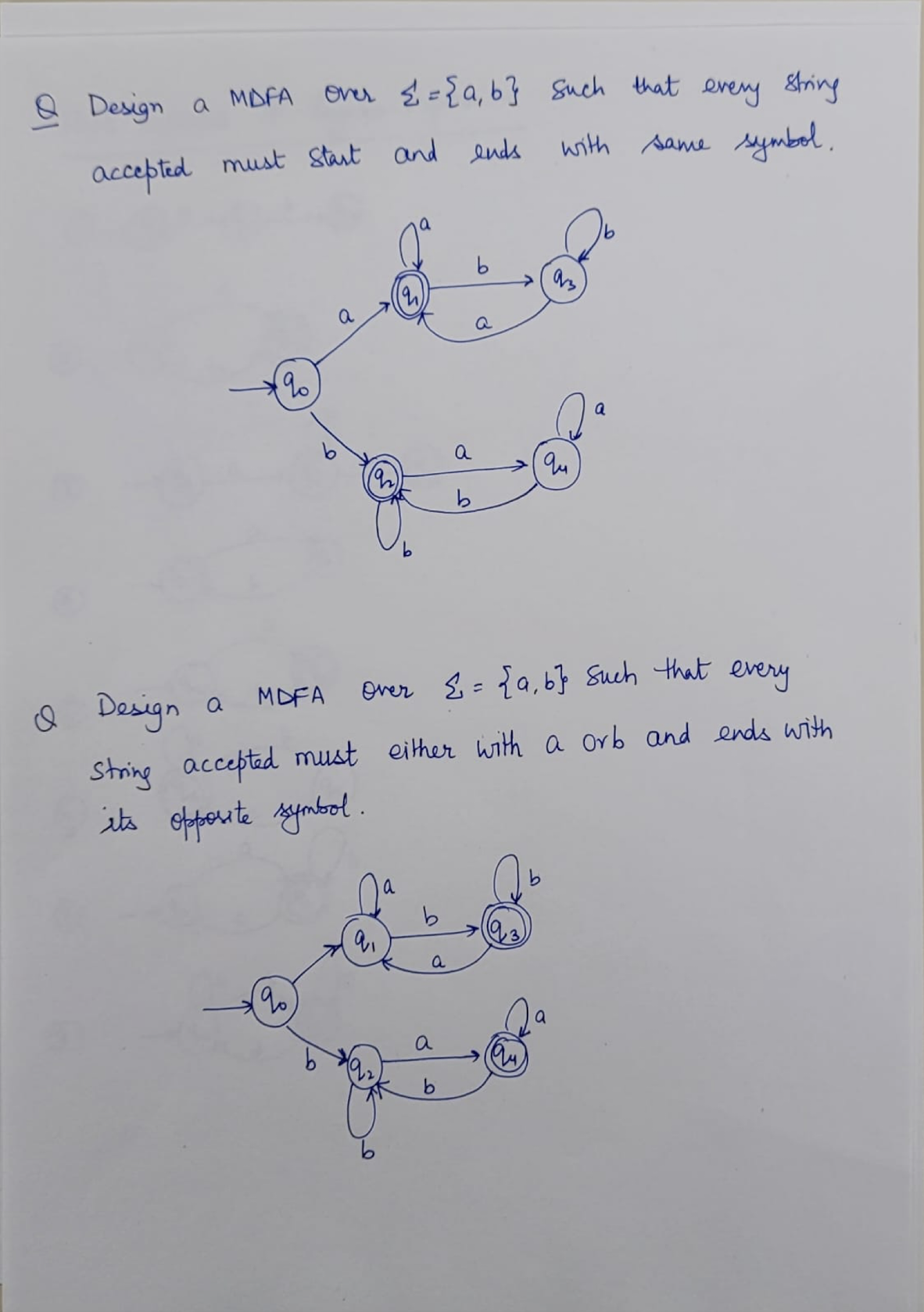
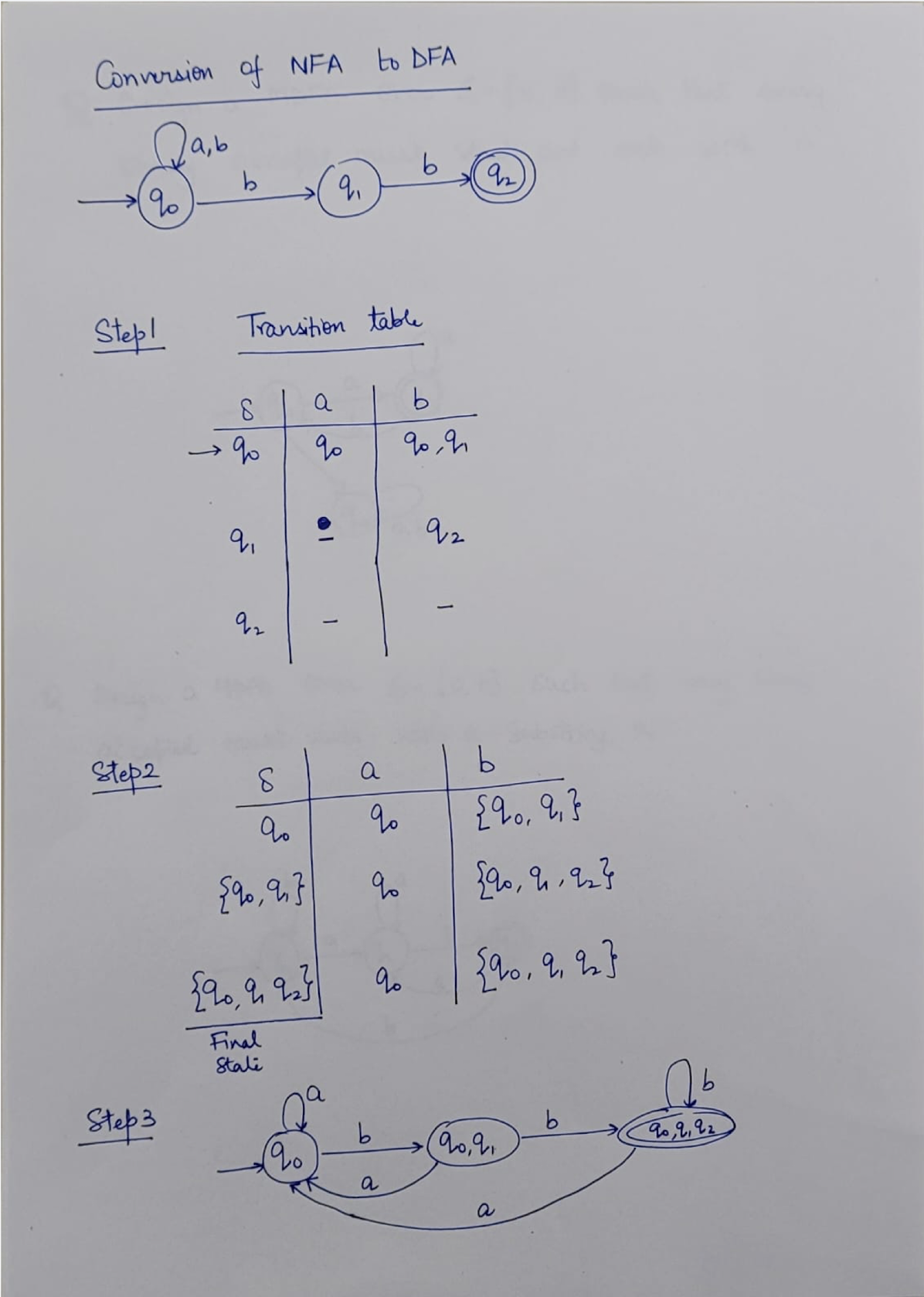
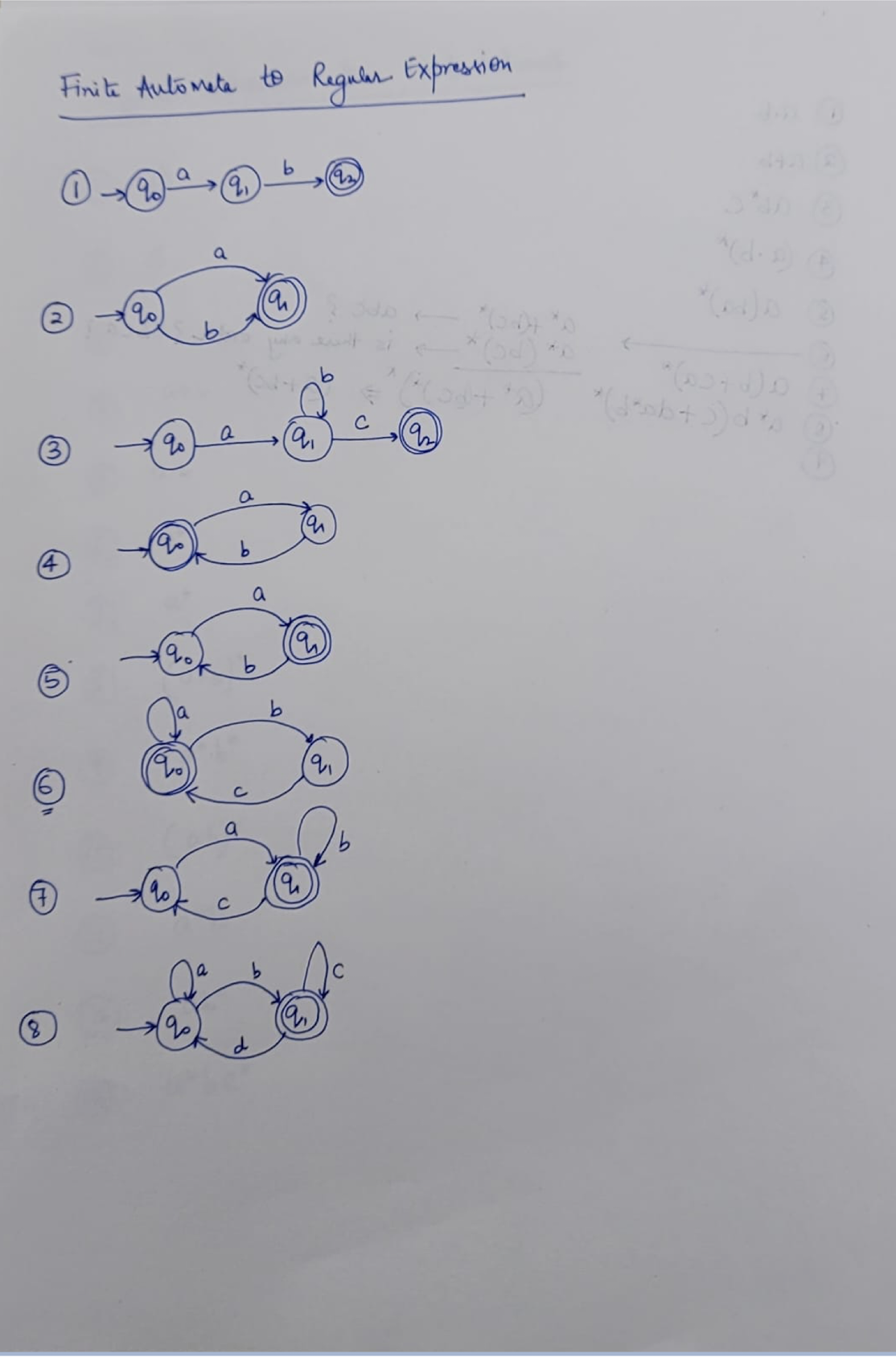
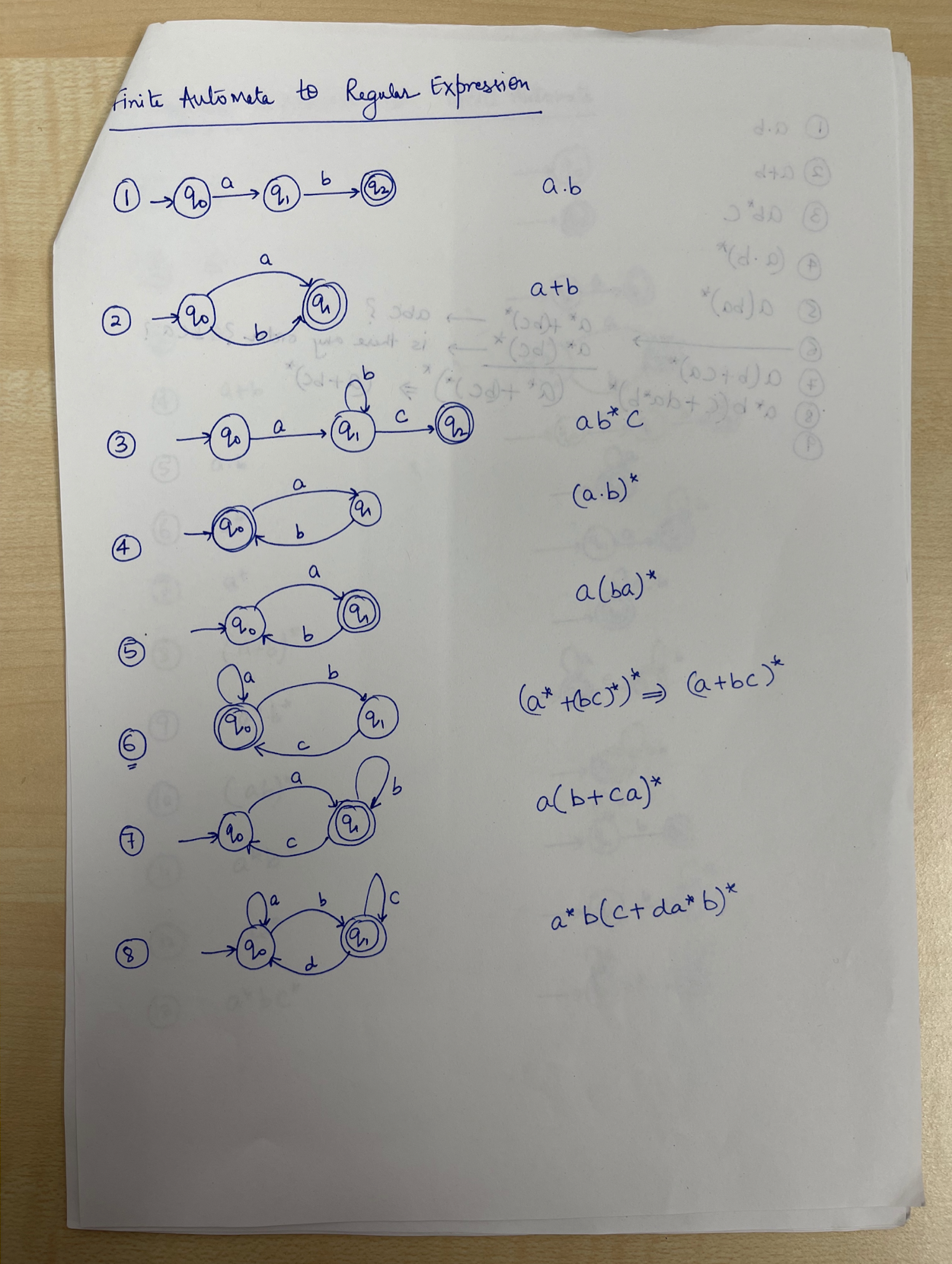


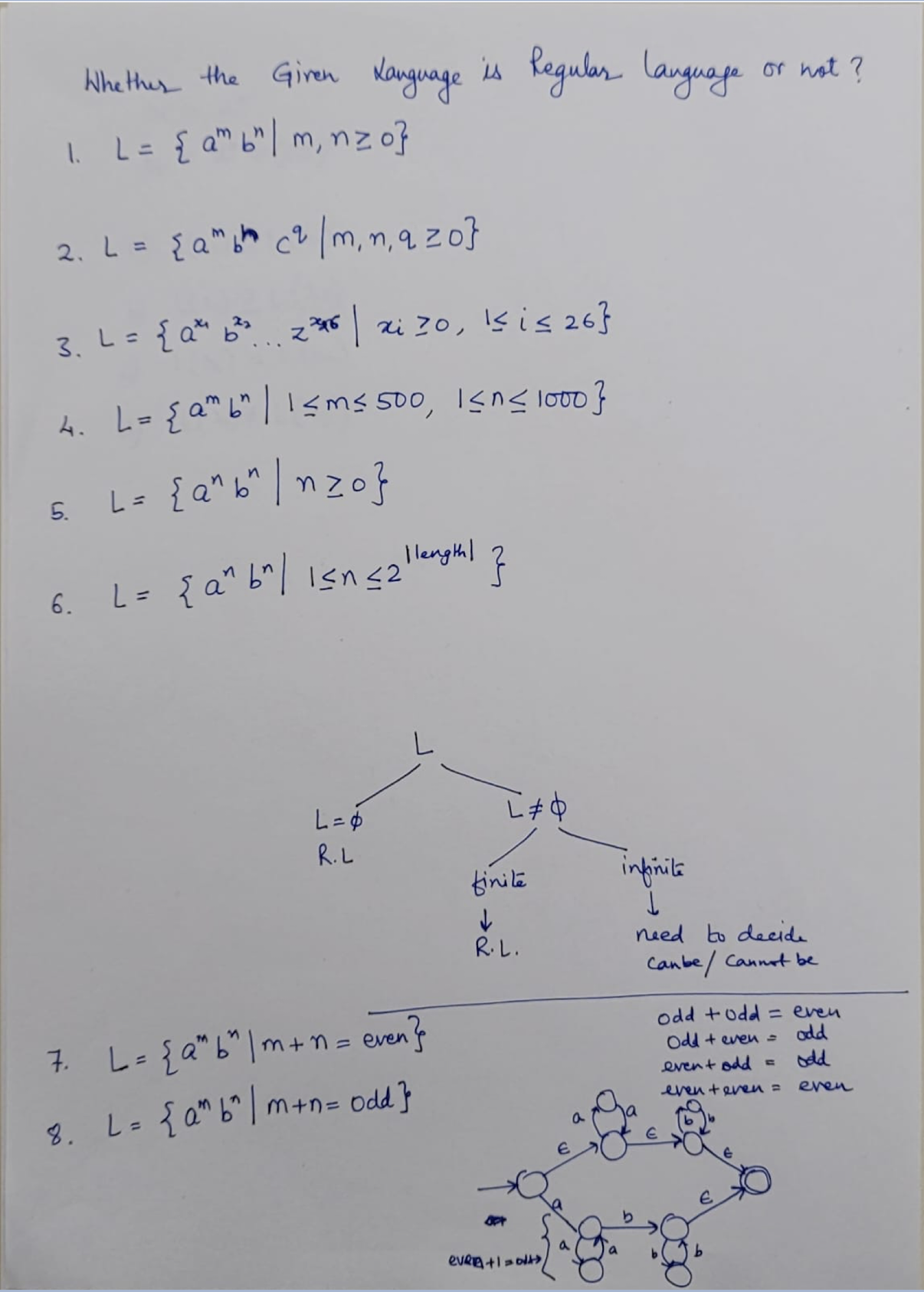

12.Syntax Analysis (I)
Review of the previous lectures
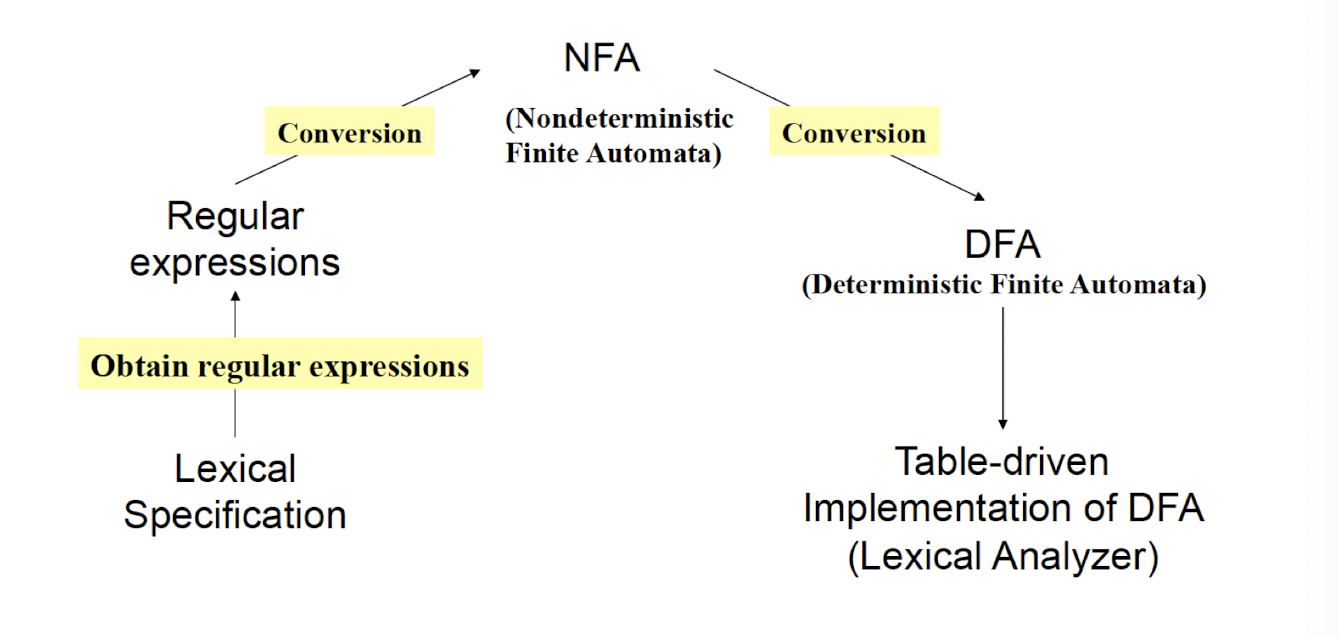
12.1 Part I: Introduction to Syntax Analysis
12.1.1 Syntax Analysis (Parsing) – 2nd Phase
Input: sequence of tokens from lexical analysis.
Output: a parse tree (syntax tree) based on the grammar of a programming language.
Comparison:
| Phase | Input | Output |
|---|---|---|
| Lexical analysis (scanner) | Source program (string of characters) | String of tokens |
| Syntax analysis (parser) | String of tokens | Parse/syntax tree |
Example
Code:
if x == y then 1 else 2 fi
Parser input is a string of tokens:
IF ID == ID THEN NUM ELSE NUM FI
Parser output:
graph TD
IF_THEN_ELSE ----> 'EQUAL'
IF_THEN_ELSE ----> NUM
IF_THEN_ELSE ----> NUM_
'EQUAL' ----> ID
'EQUAL' ----> ID_
12.1.2 Syntax and Grammar
Programming language has rules to prescribe the syntax of programs.
In Pascal, program $\to$ blocks; block $\to$ statements; …
1 | |
The syntax of programming language constructs can be described by context-free grammar (CFG).
12.1.3 Context-Free Grammar (CFG)
A context-free grammar G = (N, T, S, P) is:
(1) N is a finite set of nonterminal symbols (simplified as “nonterminals”), non-leaf nodes of the parse tree;
(2) T is a finite set of terminal symbols (simplified as “terminals”), leaf nodes of the parse tree;
(3) S is the unique start nonterminal (S $\in$ N);
(4) P is a finite set of productions. Every production in P is of the form A $\to$ $\beta$, where A $\in$ N, and $\beta$ is a string over (N $\cup$ T)∗
For example:
G = {N = {S},T = {a, b}, S, P = {S $\to$ aSb | ab} },
where S $\to$ aSb|ab denotes the language $L = {a^nb^n | n \gt 0}$.
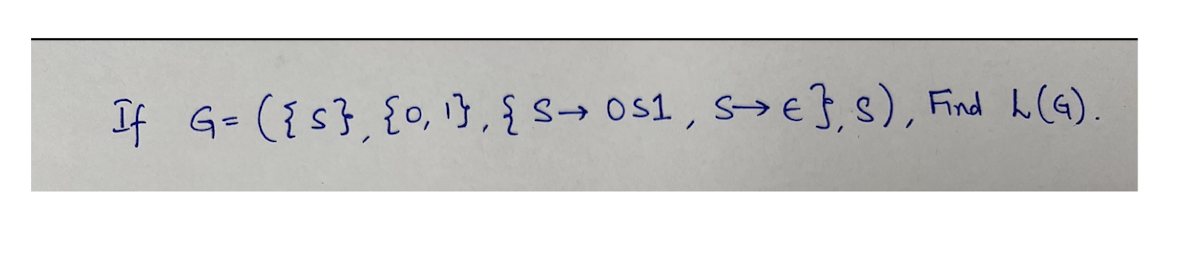
12.1.4 Why not Regular Expression?
An example:

12.1.5 Regular Expression, CFG, and Automata
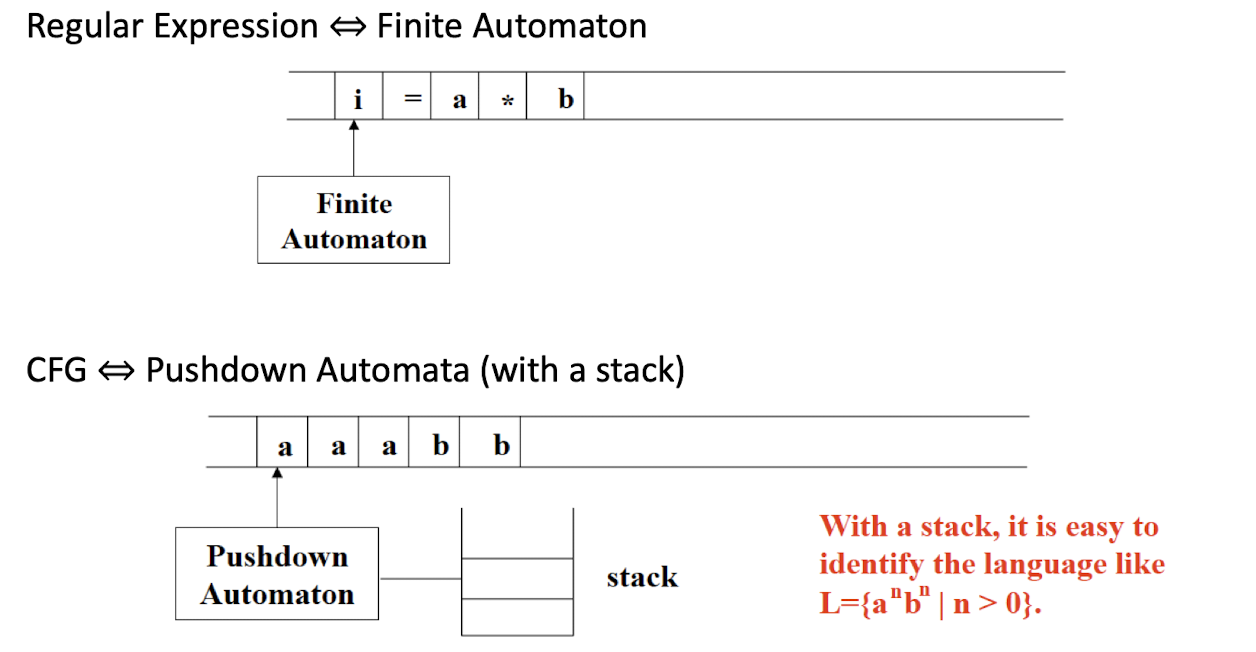
12.1.6 Language Classification
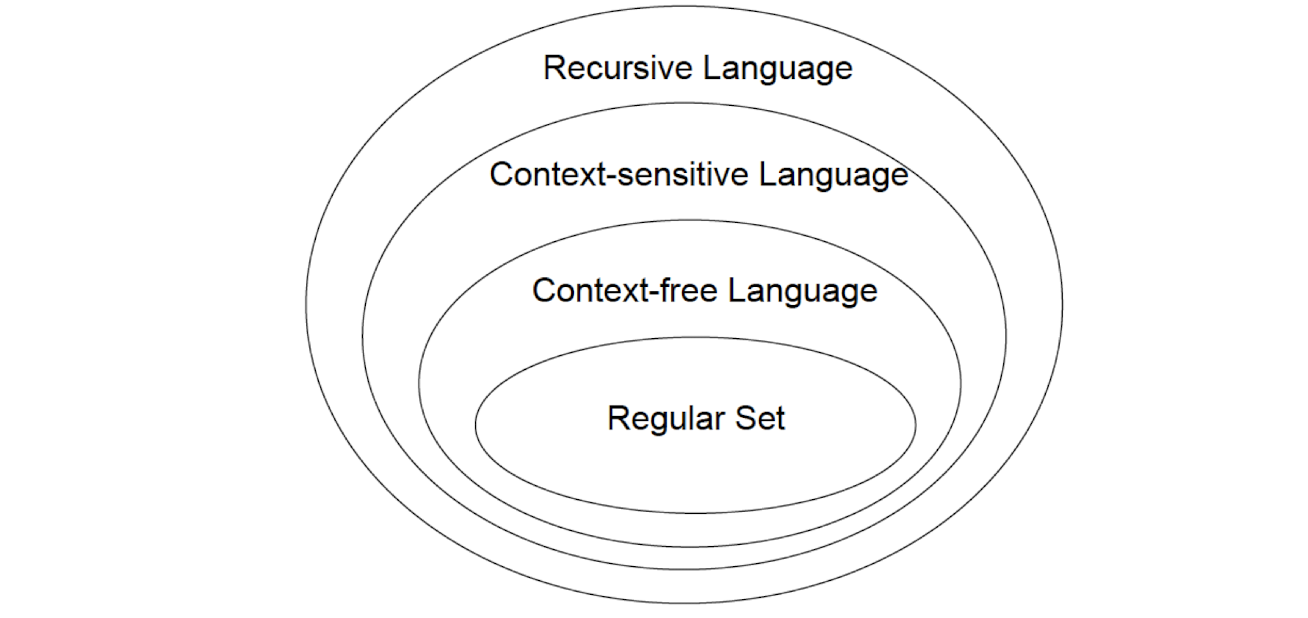
12.1.7 Regular Expression vs. CFG
Every language that can be described by a regular expression can also be described by a CFG, e.g.
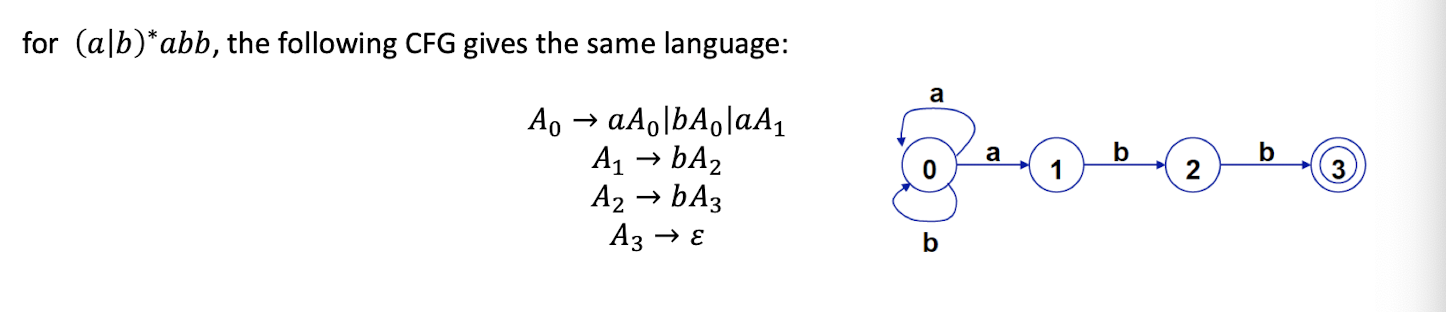
12.1.8 Derivations, Language of a CFG
Based on a grammar for a language, we can generate sentences (strings consisting only of terminals) of the language. This is done by derivations. For CFG, derivation means start from the start nonterminal, repeatedly use productions to replace nonterminals, until a sentence is produced (i.e. all nonterminals are replaced).
Grammar: S $\to$ aSb|ab
Derivation: S ⇒ aSb ⇒ aabb
where “⇒” means “derives in one step”.
A CFG language is the set of all the sentences that can be derived from the start symbol of the CFG grammar.
The reverse is syntax analysis (parsing): given an input string of terminals, is there a derivation for the string based on the grammar (is the string a sentence of the grammar)?
12.1.9 Parse Tree, Leftmost/Rightmost Derivation
For CFG, a parse tree is a tree with the following properties
- The root is labeled by the start nonterminal;
- Each leaf node is labeled by a terminal or by 𝜀;
- An interior node is labeled by a nonterminal;
If A is the nonterminal labeling some interior node, and X1 , X2 , … , Xn are the labels of the children of that node from left to right, then A $\to$ X1 X2 … Xn is a production.
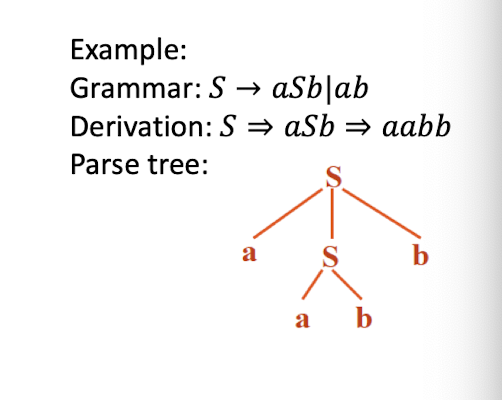
A string of terminals is a sentence of a CFG grammar iff there is a (can have more) parse tree for this string. The derivation of the sentence can be shown pictorially by this parse tree.
Suppose the parse tree of the sentence is found.
Leftmost derivation: only the leftmost nonterminal is replaced at each derivation step.
E.g., grammar: E $\to$ E + E | E ∗ E |( E )| − E|id
which is:
- E $\to$ E + E
- E $\to$ E * E
- E $\to$ (E)
- E $\to$ −E
- E $\to$ id
Leftmost derivation for the sentence −(id+id) is:
E ⇒ −E ⇒ − (E) ⇒ − (E + E) ⇒ − (id + E) ⇒ −(id + id)
Similarly, for rightmost derivation, the rightmost nonterminal is replaced at each step.
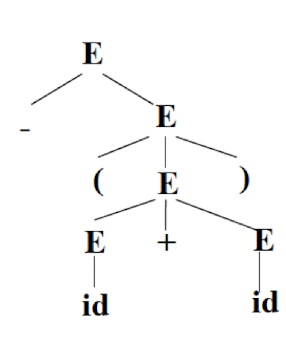
12.1.10 Parsing Methods
Bottom-Up Parsing
Start at the leaves and build the parse tree from bottom up.
Basic method: shift-reduce
- Shift symbols onto the stack;
- Reduce when handle is identified by left side.
Used to implement automatic parser generator such as Yacc.
Work for broader classes of grammars than top-down, but the grammars still must be Unambiguous
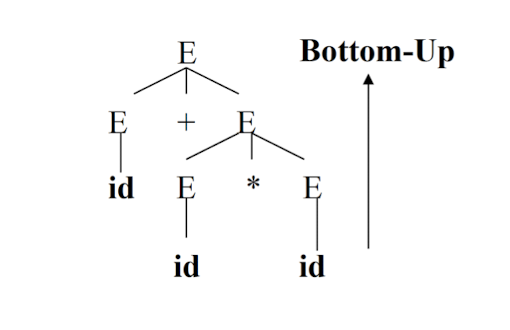
12.1.11 Shift-reduce Parser
Data Structures
- Two data structures are required to implement a shift-reduce parser-
- A Stack is required to hold the grammar symbols.
- An Input buffer is required to hold the string to be parsed.
- Stack contains only the $ symbol.
- Input buffer contains the input string with $ at its end.
Possible Actions
- A shift-reduce parser can possibly make the following four actions-
1. Shift
- In a shift action,
- The next symbol is shifted onto the top of the stack
2. Reduce
- In a reduce action, The handle appearing on the stack top is replaced with the appropriate non-terminal symbol
3. Accept
- In an accept action,
- The parser reports the successful completion of parsing.
4. Error
- In this state,
- The parser becomes confused and is not able to make any decision.
- It can neither perform shift action nor reduce action nor accept action.
12.1.12 Rules To Remember
It is important to remember the following rules while performing the shift-reduce action-
- If the priority of incoming operator is more than the priority of in stack operator, then shift action is performed.
- If the priority of in stack operator is same or less than the priority of in stack operator, then reduce action is performed.
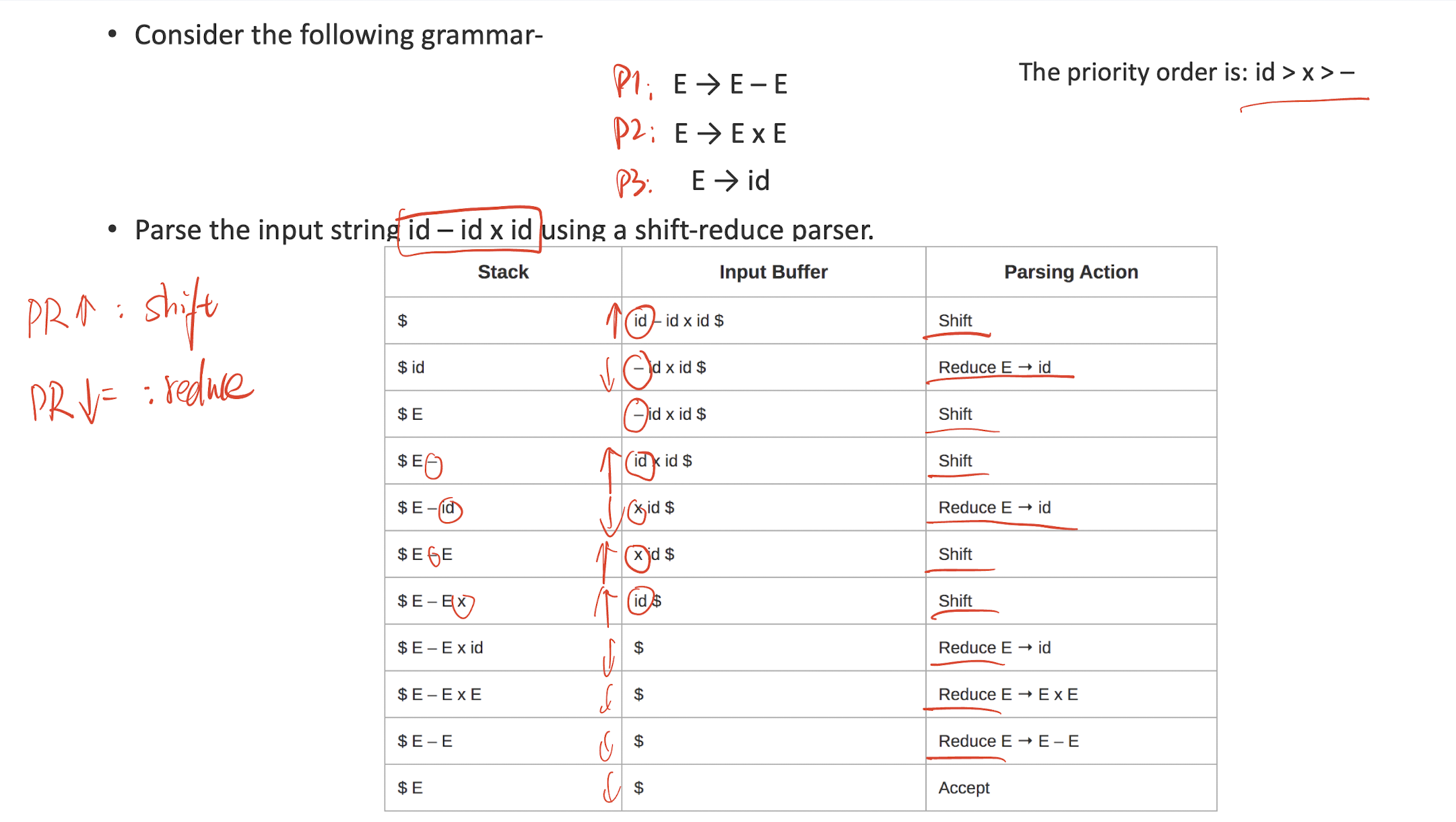
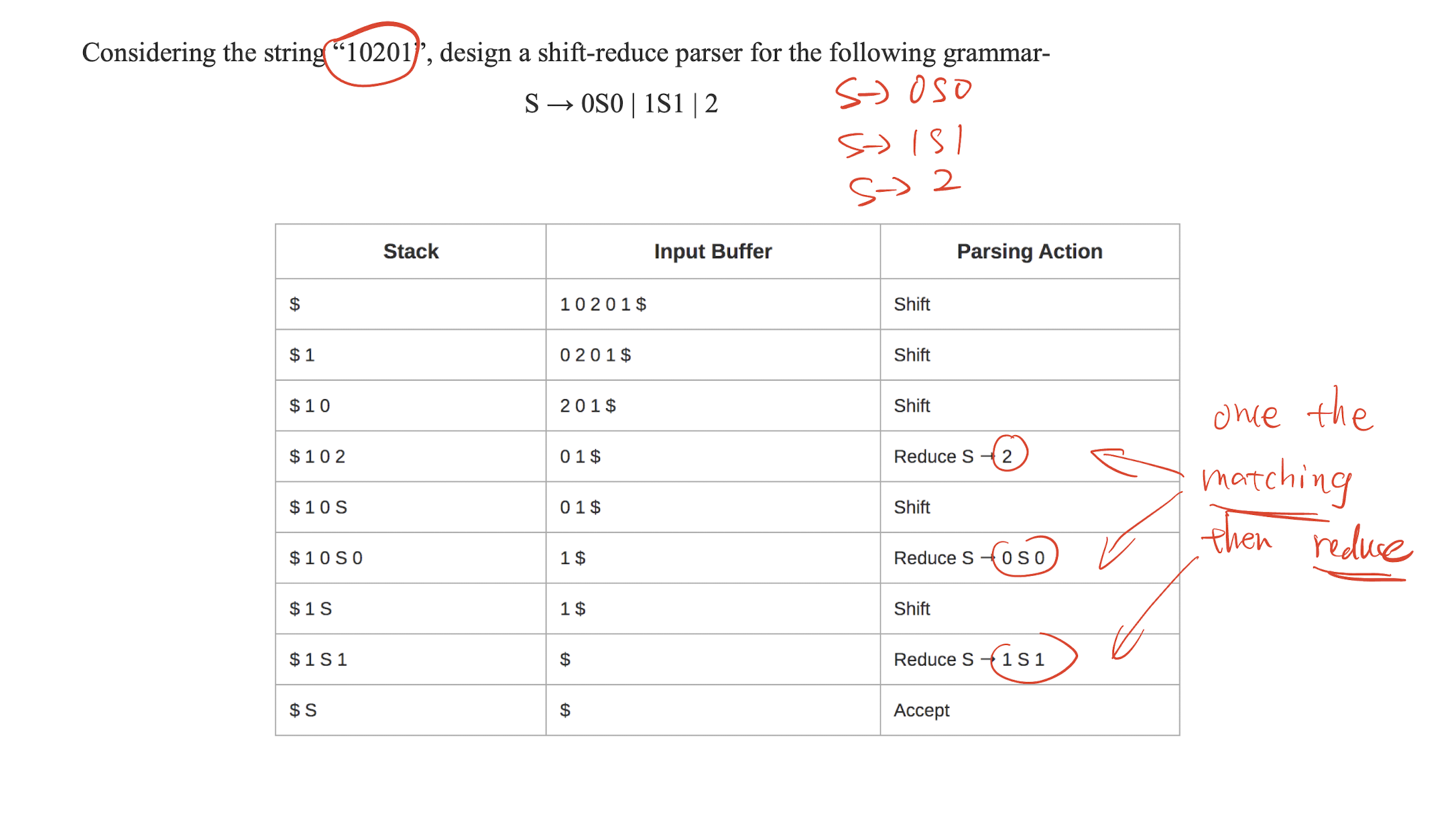
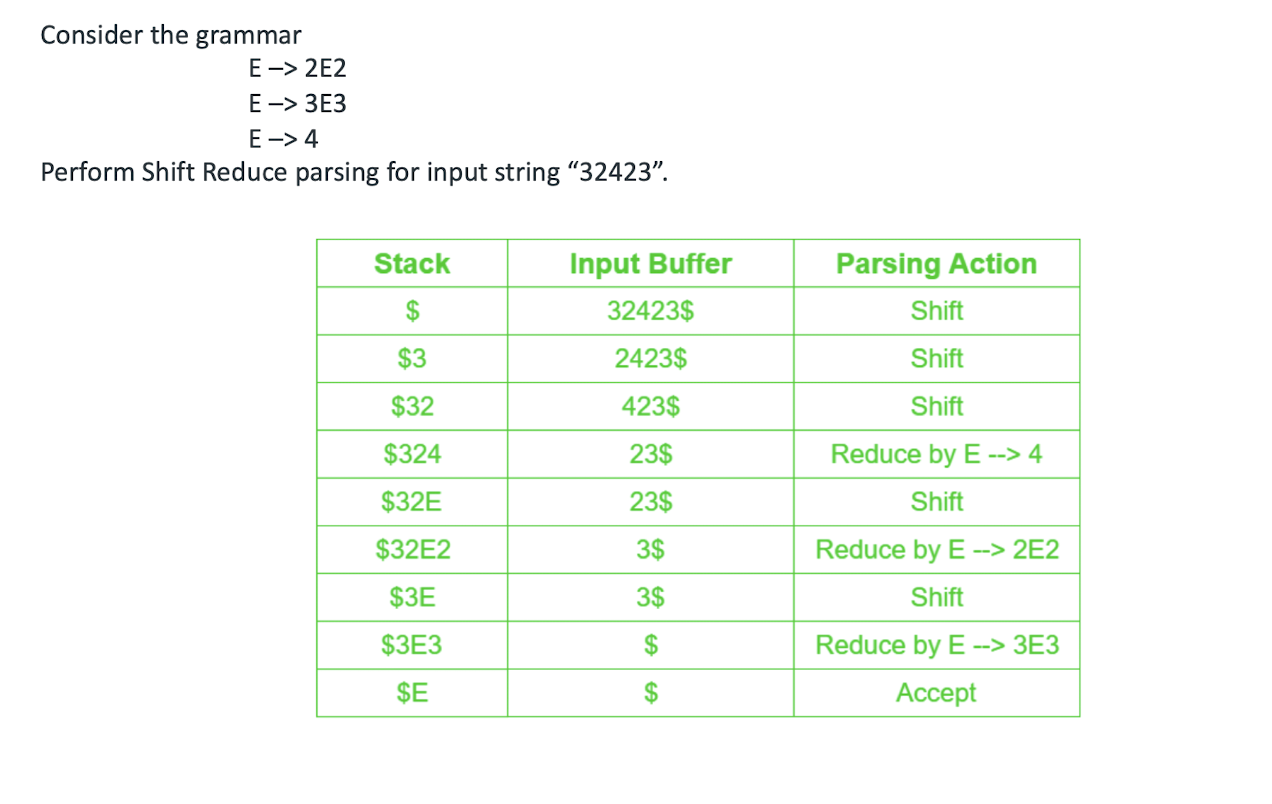
12.1.13 Top-Down Parsing
Start at the root of the parse tree and try to get to leaves. Can be efficiently written by hand.
Only work for certain class of grammars:
- Unambiguous
- No left recursion
- No left factoring
Left recursion: A grammar is left-recursive if and only if there exists a nonterminal symbol A that can derive
to a sentential form with itself as the leftmost symbol. That is, A ⇒ $^+$ 𝐴𝛼, where ⇒ $^+$ means the operation of making one or more substitutions, and 𝛼 is any sequence of terminal and nonterminal symbols.
Left factoring: A grammar is left factoring if and only if there exists a nonterminal symbol A that has A $\to$ 𝛼𝛽1 |𝛼𝛽2 , where 𝛼, 𝛽1 , 𝛽2 are any sequence of terminal and nonterminal symbols, with $\alpha \neq \epsilon$.
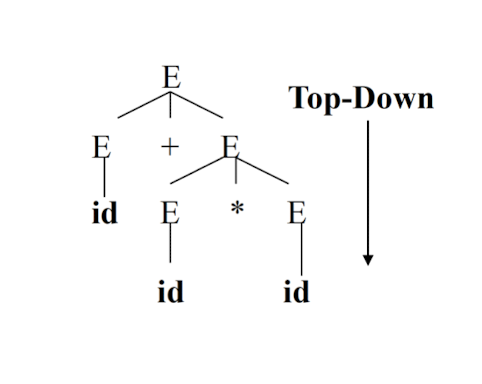
12.1.14 Recursive Production and Grammar
- Recursive Production: if the same non-terminal at both left and right hand side of production
$S\to aSb$
$S\to aS$
$S\to Sa$
- Recursive Grammar: if at least one recursive production is present
$S\to aS/a$
$S\to Sa/a$
$S\to aSb/ab$
12.1.15 Process of making a CFG, Compiler Friendly
If a CFG contains left recursion then the compiler may go to infinity loop, hence, to avoid the looping of the compiler, we need to convert the left recursive grammar into its equivalent right recursive production
- Convert Left recursion into Right recursion

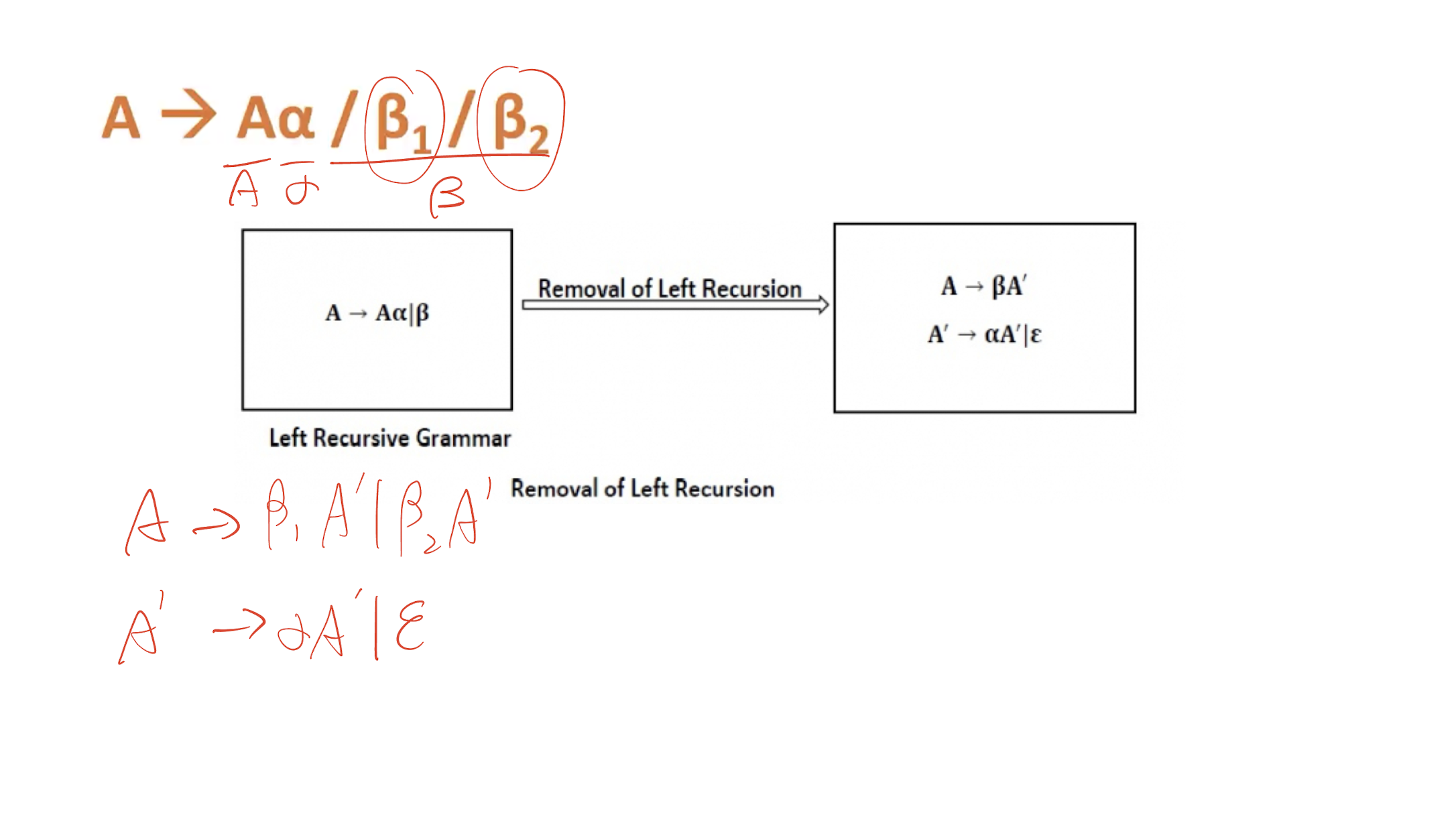
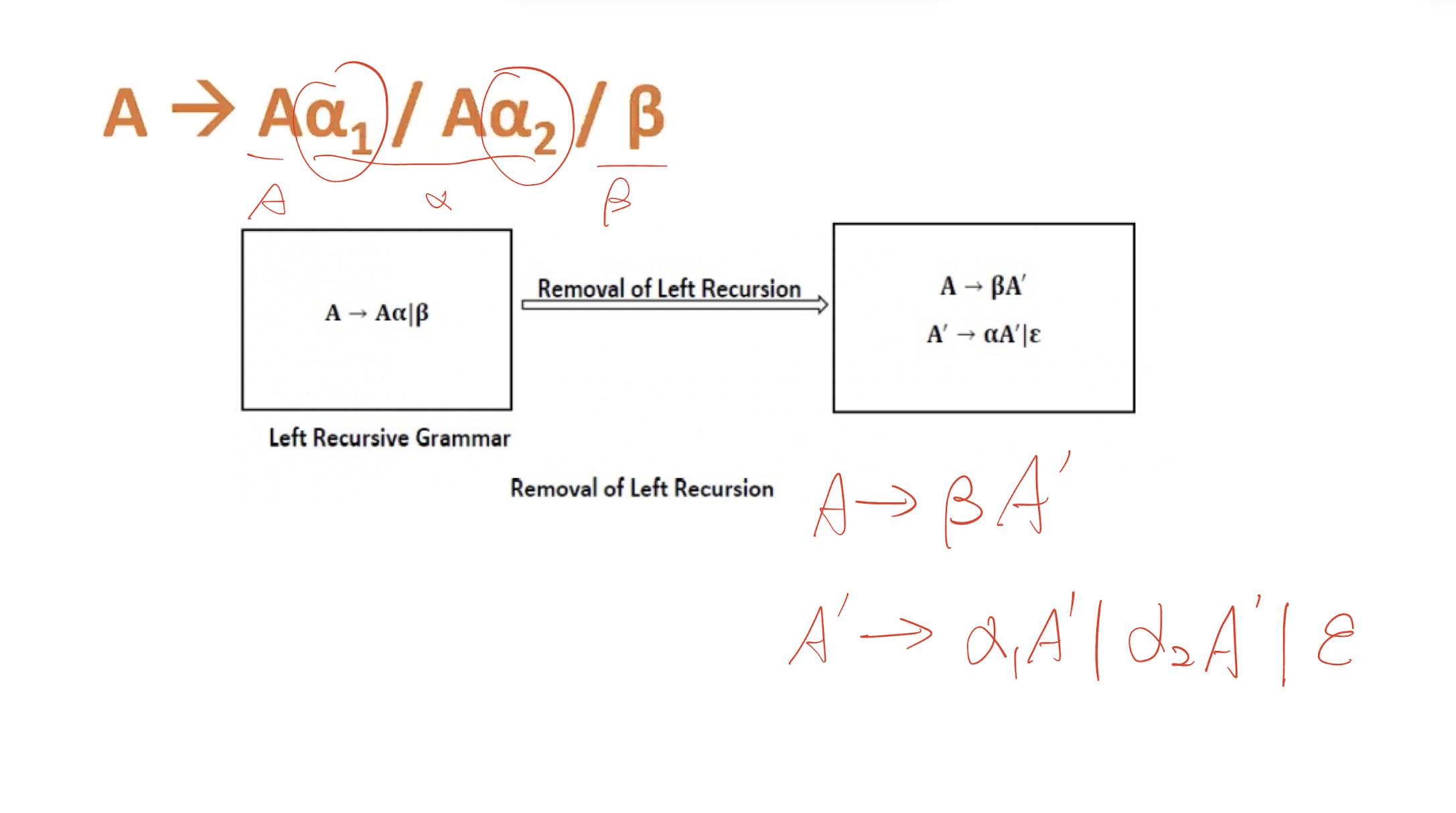
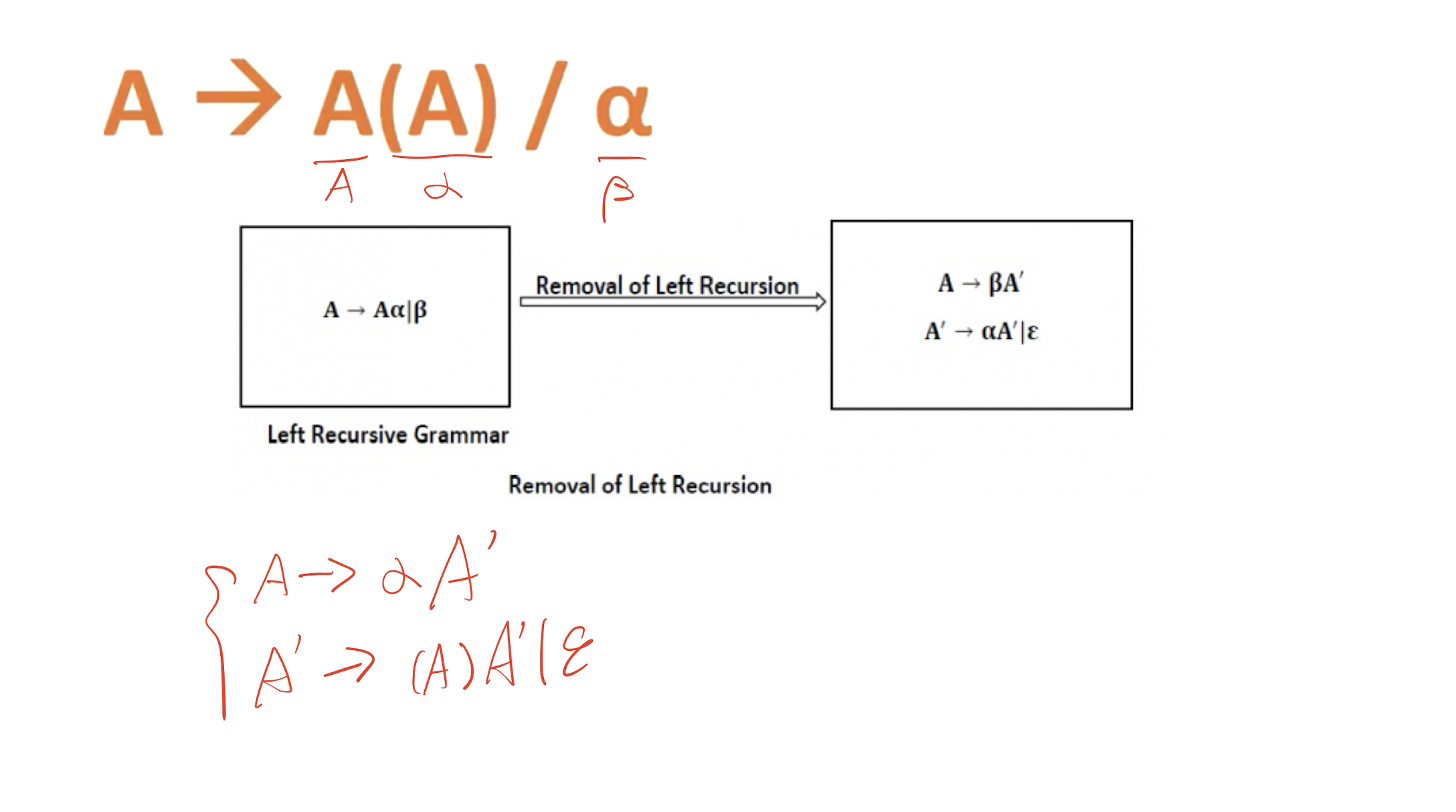
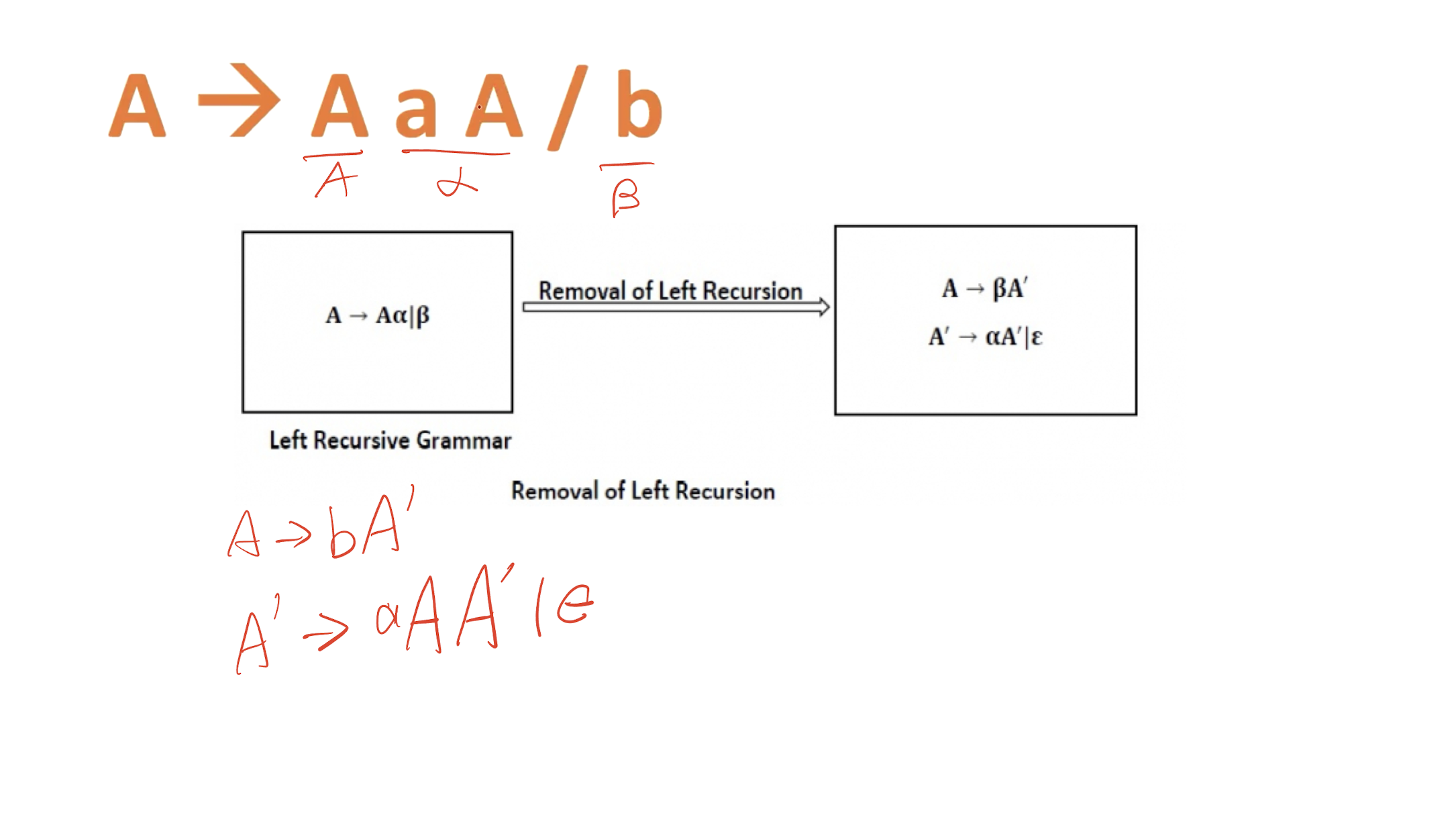
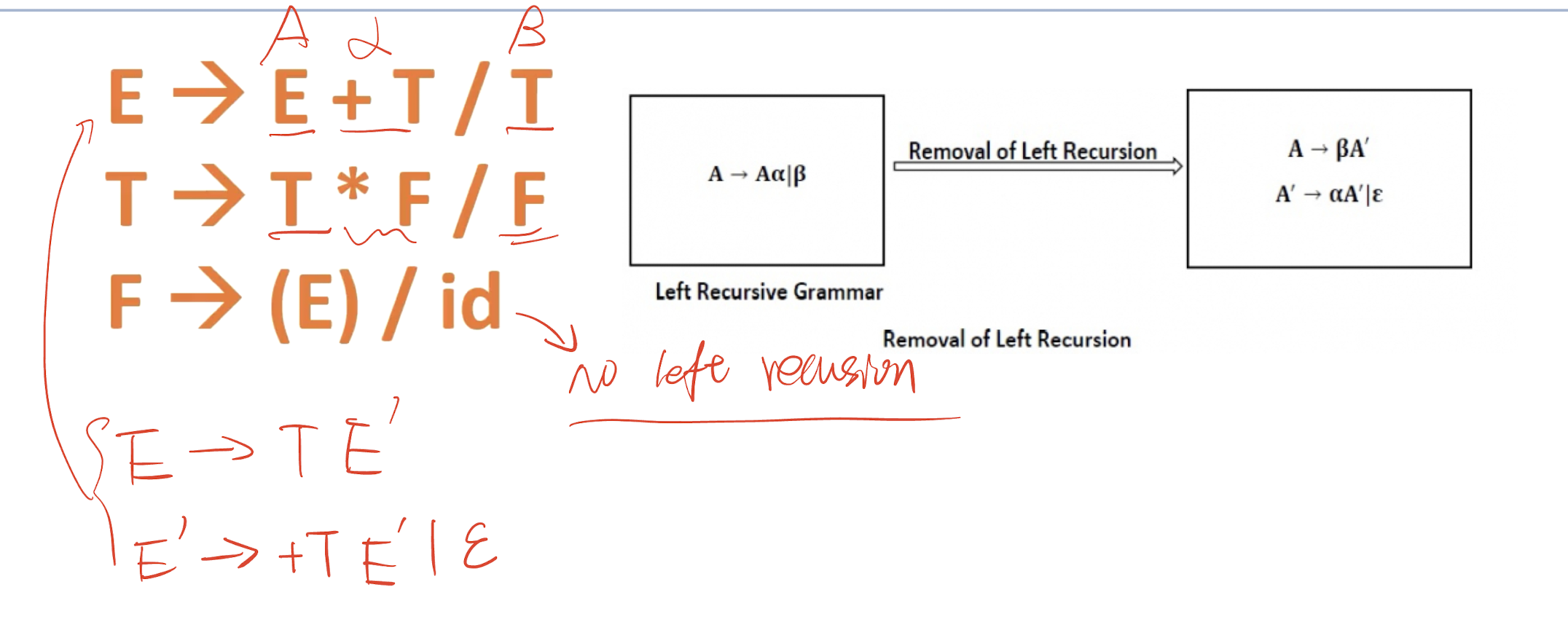
12.1.16 Ambiguous Grammars
Each parse tree has a unique leftmost/rightmost derivation.
Note sometimes a grammar may have (produce, imply) more than one parse tree for some of its sentences. Such a grammar is said to be ambiguous. For such a sentence (i.e., having more than one parse tree), its leftmost and rightmost derivations may be different.
E.g., grammar: E $\to$ E + E | E ∗ E | id
Sentence id+id∗id
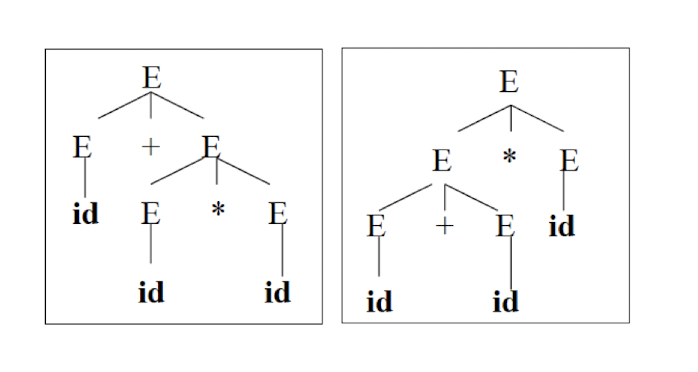
Grammar which is both left and right recursive is always ambiguous
- but ambiguous grammar need not be both left and right recursive
12.1.17 Non-deterministic Grammar


12.1.18 Normalization of CFG
The Grammar G is said to be in Chomsky Normal Form (CNF), if every production is in form
- A $\to$ BC/a
S$\to$ aSb/ab, CNF or not?
Step 1:
- S $\to$ ASB/AB
- A $\to$ a
- B $\to$ b
Step 2:
- S $\to$ S’B/AB
- S’ $\to$ AS
- A $\to$ a
- B $\to$ b
12.1.19 Parsing Methods
Parser (syntax analyzer): given a grammar and a string of terminals, judge if the string belongs to the grammar’s language. For CFG, this is usually done by trying to construct the parse tree (hence find the derivations) for the given string (success: yes, it belongs to the CFG language; fail: no, it does not belong to the CFG language).
Two parsing methods:
- Top-Down Parsing: construct starts at the root and proceeds towards the leaves.
- Bottom-Up Parsing: construct starts at the leaves and proceeds towards the root.
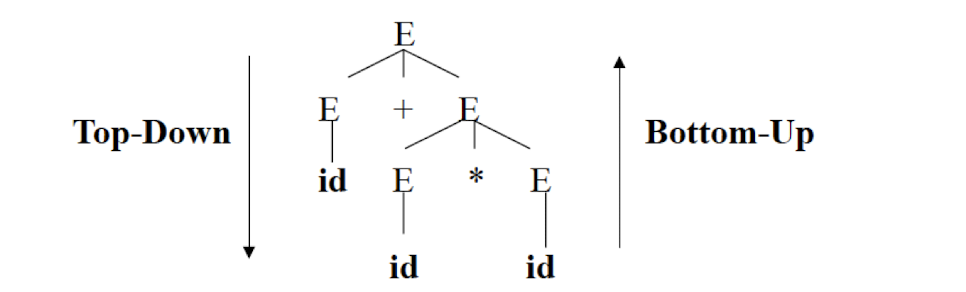
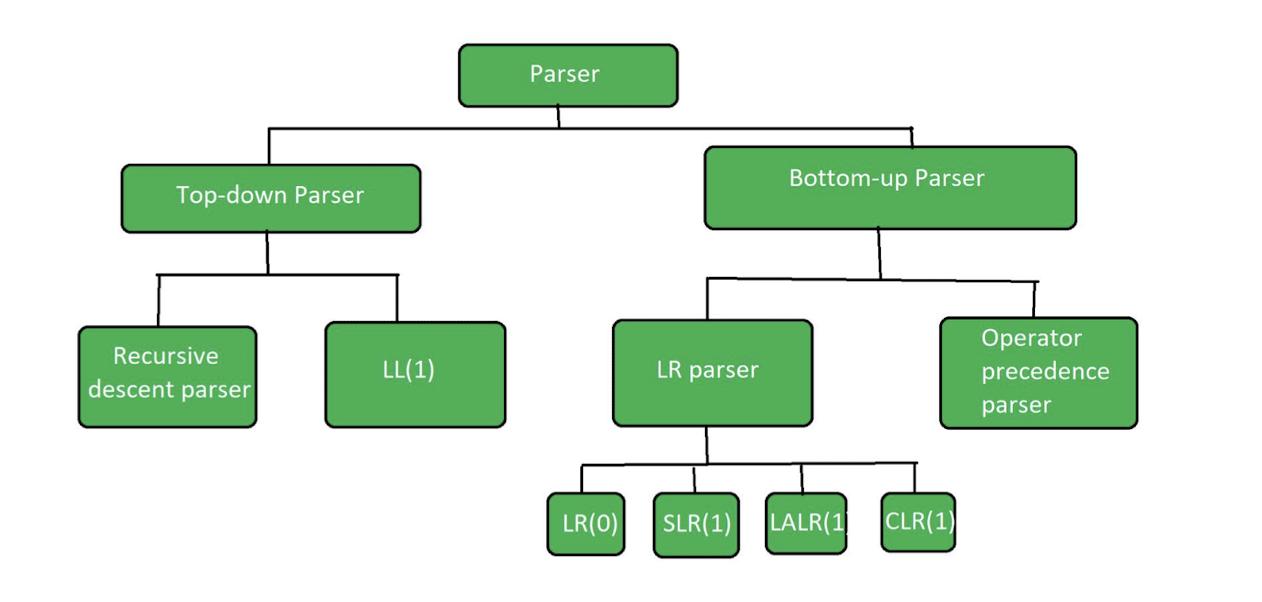
12.1.20 Brute Force Technique


12.1.21 Understanding First Function








12.1.22 Understanding Follow Function




12.1.23 Important Points
Note-01:
- $\epsilon$ may appear in the first function of a non-terminal.
- $\epsilon$ will never appear in the follow function of a non-terminal.
Note-02:
- Before calculating the first and follow functions, eliminate Left Recursion from the grammar, if present.
Note-03:
- We calculate the follow function of a non-terminal by looking where it is present on the RHS of a production rule.
12.1.24 First and Follow functions







12.1.25 Algorithm to construct LL(1) Parsing Table
Step 1: First check all the essential conditions and go to step 2.
Step 2: Calculate First() and Follow() for all non-terminals.
Step 3: For each production A –> α. (A tends to alpha)
1.Find First(α) and for each terminal in First(α), make entry A –> α in the table.
2.If First(α) contains $\epsilon$ (epsilon) as terminal, then find the Follow(A) and for each terminal in Follow(A), make entry A –> $\epsilon$ in the table.
3.If the First(α) contains $\epsilon$ and Follow(A) contains $ as terminal, then make entry A –> $\epsilon$ in the table for the $.
To construct the parsing table, we have two functions:


12.1.26 Intermediate code generation, code optimization, code generation
Three-Address Code:
Intuition: x = y + z
At most one operator on the right side of an instruction. No build-up arithmetic expressions.
x + y * z should be expressed as
t1 = y * zt2 = x + t1
Three-Address Code is built from two concepts: address and instruction.
An address can be
- A name, to be replaced by a pointer to its symbol-table entry, where all information about the name is kept.
- A constant
- A compiler-generated temporary, especially useful in optimization.
An instruction can be
- Assignment instruction of the form x = y op z, where op is a binary arithmetic or logical operation, and x, y, z are addresses.
- Assignment instruction of the form x = op y
- Copy instruction of the form
- Unconditional jump instruction
- Conditional jump of the form if x goto L and if False x goto L.
- Conditional jump in the form if x relop y goto L, where relop is a relational operator, such as >, <, >=, <=, ==, != etc.
- Procedure call and returns:
1 | |
- Indexed copy instructions of the form
x = y[i] and x[i] = y - Address and pointer assignments of the form
x = &y, x = *y, *x = y
So me common code optimization philosophies: Redundancy of the intermediate code creates the need to optimize code. Redundancy of the intermediate code is inevitable: for high level program clarity, and due to high level programming language construct constraints (e.g. A[i][j], x->y).
- Common subexpression elimination. E.g.
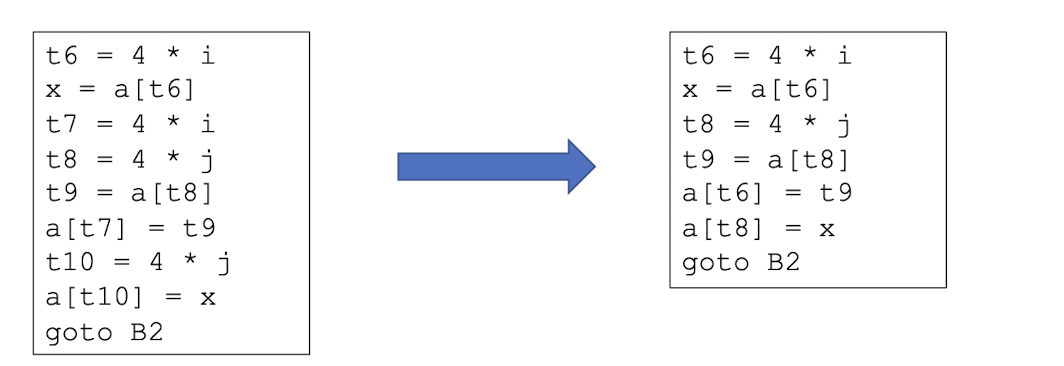
- Copy propagation. E.g.
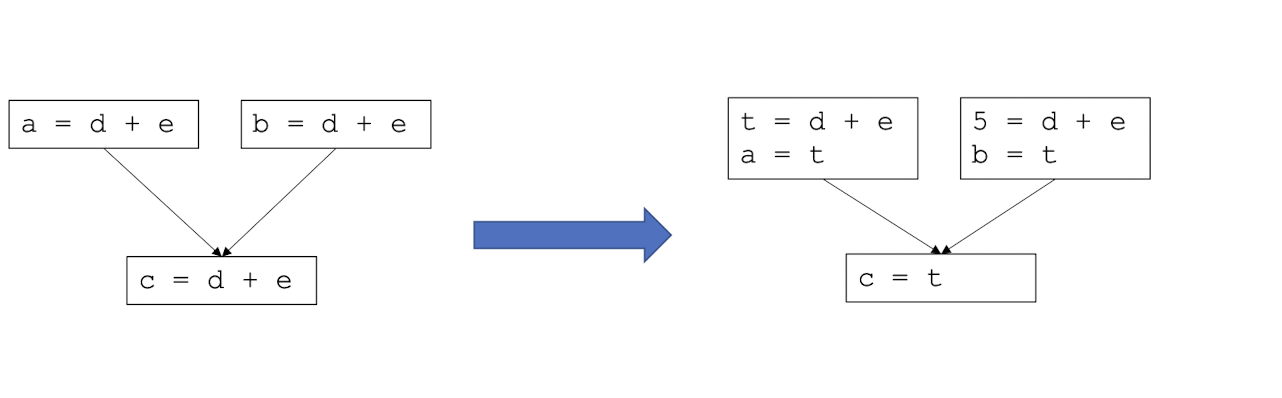
- Dead code elimination. E.g. if somewhere in the code there is
if (debug) print …
while somewhere before that, the compiler can derive
debug == FALSE
Constant folding. If the compiler deduce that an expression has a constant value, then all the appearance of that expression is replaced by that constant.
Code motion. Move unchanged part in a loop to before the loop. E.g.
1 | |
Change it to1
2t = limit * 2.5
while (i < t) /* statement does not change limit or t */
References
Slides of COMP3438 System Programming, The Hong Kong Polytechnic University.
个人笔记,仅供参考
PERSONAL COURSE NOTE, FOR REFERENCE ONLY
Made by Mike_Zhang