Operating Systems Course Note
Made by Mike_Zhang
Notice | 提示
个人笔记,仅供参考
PERSONAL COURSE NOTE, FOR REFERENCE ONLYPersonal course note of COMP2432 Operating Systems, The Hong Kong Polytechnic University, Sem2, 2022/23.
本文章为香港理工大学2022/23学年第二学期 操作系统(COMP2432 Operating Systems) 个人的课程笔记。Mainly focus on Interrupts and System Calls, Unix and Linux Programming, Process Management, Interprocess Communication and Programming, CPU Scheduling, Memory Management, Virtual Memory, Deadlock, Process Synchronization, File System, Secondary Storage, and Protection, and Security and Case Studies.
Unfold Study Note Topics | 展开学习笔记主题 >
Reference Book
[PDF] Operating System Concepts
0. Final Exam Revision
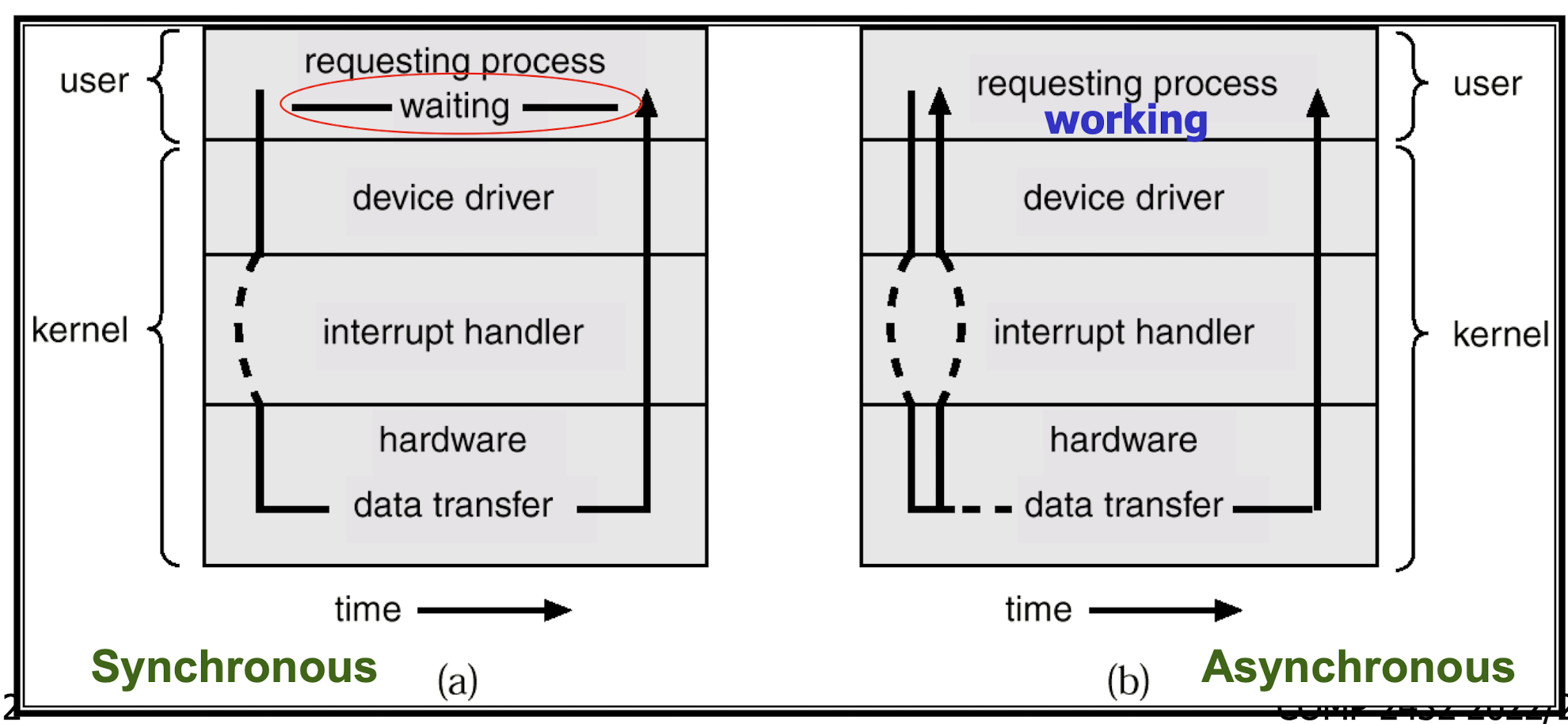
1.[2] Distinguish between synchronous and asynchronous I/O processing using a diagram.
- Synchronous I/O
- User program will wait until I/O completes.
- At most one I/O request is outstanding at a time
- Asynchronous
- User process is still running.
- User program do not wait until I/O completes.
- Several I/O requests working together.
2.[2] What is an interrupt? What are the two types of interrupts? Explain with a diagram how an interrupt could “interrupt” another interrupt. What are the purposes of a timer interrupt?
An interrupt
- is a signal to the CPU to tell it about the occurrence of a major event.
- is the mechanism the OS uses so that it could turn attention to other activities and to manage resources, because interrupt will seize the CPU.
- Get the CPU back to the OS.
Two type of interrupts:
- Maskable interrupt: interrupt that may be ignored or handled later. A lower priority interrupt is maskable.
- Non-maskable interrupt: interrupt that cannot be ignored. The CPU must handle this. A non-maskable interrupt may be “over”-interrupted by another non-maskable higher priority one.
Cause of interrupts, for 3 type:
- Program interrupt: Caused by conditions within CPU
- Caused by I/O interrupt: I/O related events
- Timer interrupt: Caused by the hardware timer
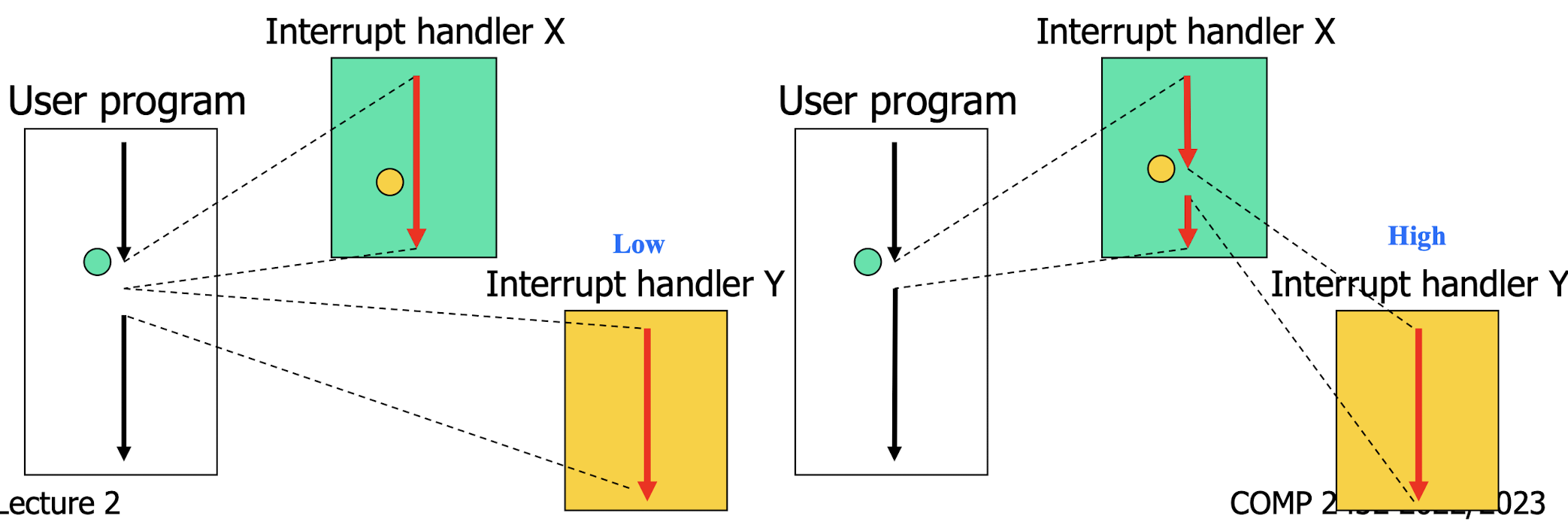
“interrupt” another interrupt
- If the incoming new interrupt Y has a lower priority, it will wait till the first one X completes.
- If the new interrupt Y has a higher priority, it will seize the CPU from the current interrupt handler X.
The timer mechanism
- Set up interrupt to occur after specific time period (alarm)
- Operating system decrements counter upon timer interrupt.
- watchdog timer.
- User is NOT allowed to disable the interrupt.
3.[2] What are the supervisor mode and user mode and what is the use of the mode bit? What types of instructions should be executed in supervisor mode? What is a system call? Draw a diagram to illustrate how a system call is implemented. What are the typical types of system calls? What are the common types of system programs?
User mode: Normal instructions, but not privileged instructions.
Kernel node
- execute all instructions. Only OS processes should be executing in kernel mode. It is also called system, privileged mode, supervisor mode
mode bit: Provide ability to distinguish when the system is running user program or system (OS) program.
- A process running with user mode bit ON is a user process.
- A process running with user mode bit OFF is a kernel or system process.
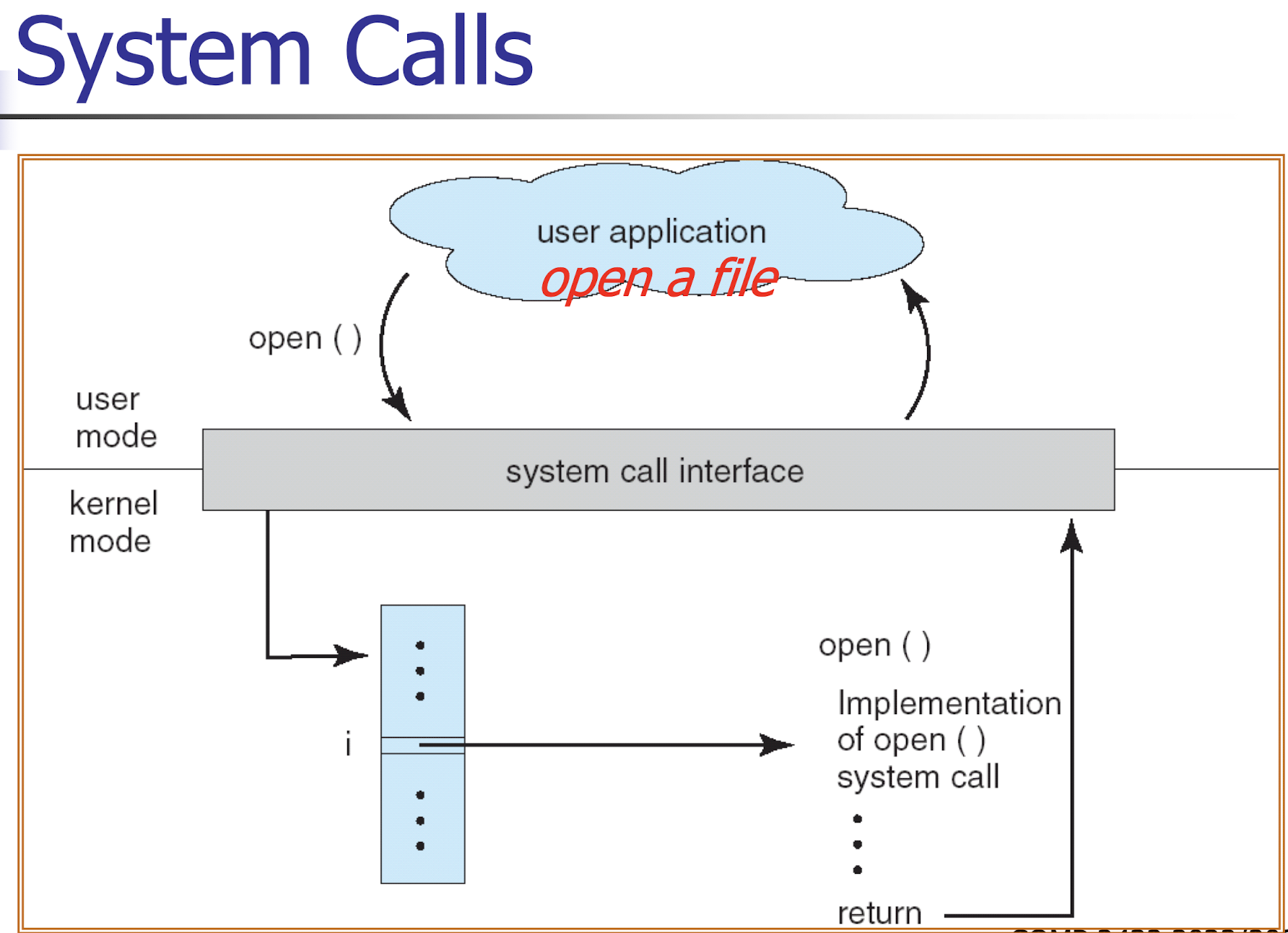
System call: is a programming interface to the services provided by the OS.
5 Types of System Calls:
- Process control
- File management
- Device management
- Information maintenance
- Communications
Types of system programs:
- File manipulation
- Status information
- File modification
- Programming language support
- Program loading and execution
- Communications
- Utilities
4.[2] What are the common types of OS? Draw diagrams to illustrate the difference between a simple OS and a layered OS. What are the advantages and disadvantages of micro-kernel systems? What are the advantages of Unix and Linux?
Types of Operating Systems
- Batch processing
- Multiprogramming
- Time-sharing
- Real-time
- Distributed
Microkernel System
Advantages:
- Easier to extend a microkernel.
- Easier to port OS to new architecture / hardware.
- More reliable (less code running in critical kernel mode).
- More secure.
- Bug in user part will not kill the system, in kernel part will.
Disadvantages:
- Performance overhead of user space to kernel space communication.
Advantages of Unix and Linux:
- Reliability: seldom crash, ported to many systems and tested by many people.
- Security: better security, with simpler kernel design.
- Speed: programs run faster with lower OS overhead.
- Cost: Linux is free and many Unix systems are free.
- Open source: source codes available; you could verify that they are correct; you could modify them to specific need.
5.[3] Distinguish between local and environment variables. What is the difference between quote and backquote in the bash shell? Write a bash script program to do abc. What would the following bash script program xyz produce?
Local variables are only valid within the shell when it is defined
Environment variables are valid across all shells created by the existing shell when it is defined.
- Can NOT be passed out from the subshell to the parent shell.
Single quote (’str’)
- The strong quote.
- Enclosed string looks like literal.
- No substitution and no execution is done.
Double quote (”str”)
- The weak quote.
- Enclosed string is almost like literal.
- Substitution is done for variable contents (prefixed with “$”).
- Execution is done for back-quoted commands.
- Watch out for “!!”, which is trying to match a past command.
- This is a bug in showing the current command.
Backquote enables a command to be executed (`str`)
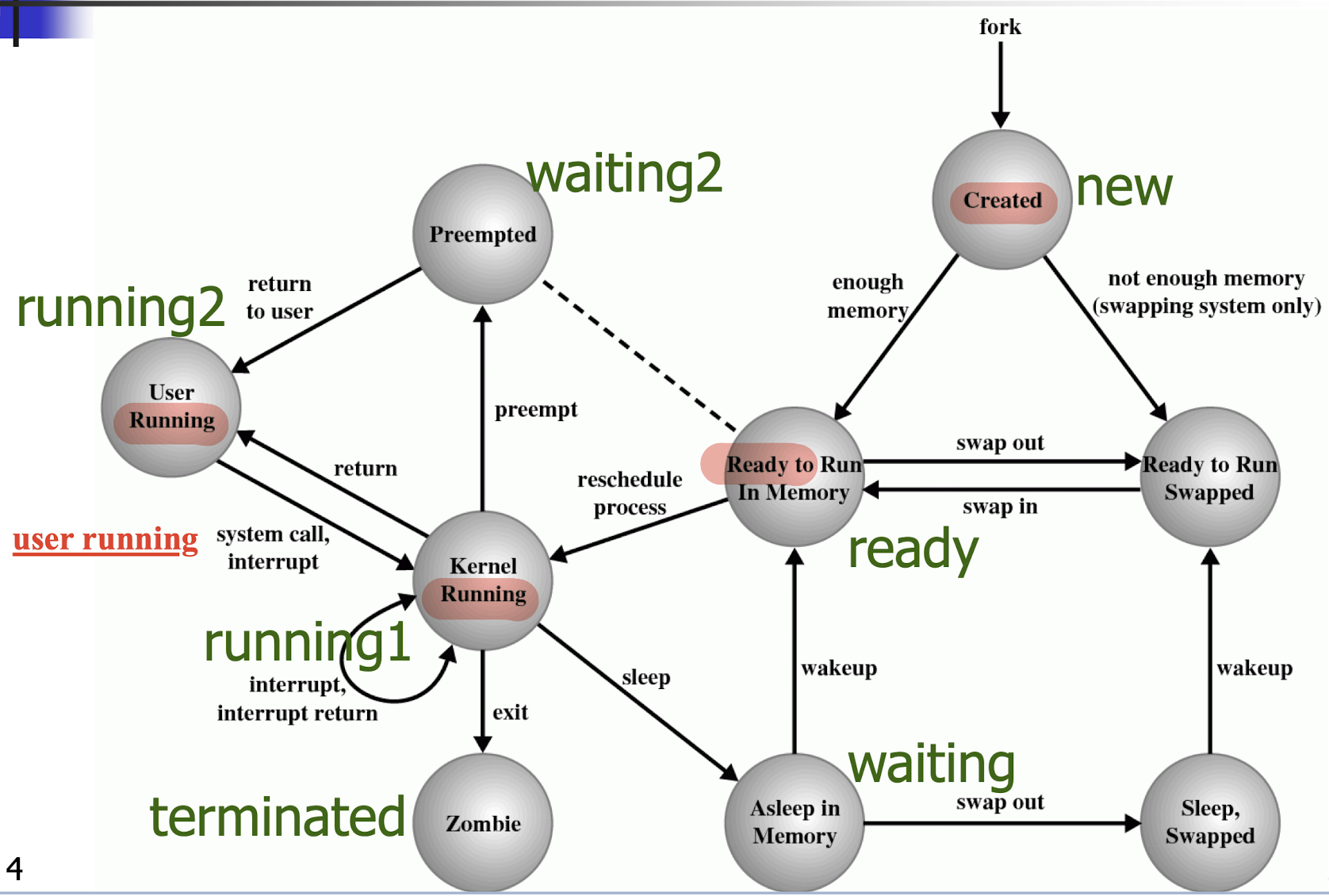
6.[4] What is a process? What is a PCB? What is a process state and what are the common process states? How could processes transit between states? What is the relationship between the life cycle of a process and the queues used in the OS?
A process is a program in execution
Process Control Block (PCB):
- Process state
- Program counter
- CPU registers
- CPU scheduling information
- Memory-management information
- Accounting information
- I/O status information
Process state: Process would alternate between “served by a CPU” and “waiting”.
- new, ready, running, terminated, waiting
Job queue: set of all processes in the system.
Ready queue: set of all processes residing in main memory, ready and waiting to be executed.
Device queues: set of processes waiting for an I/O device.
- process scheduler for each type of queues determines who will get service next.
7.[4] What are the three main types of schedulers in an OS? What are their functions? What is context switching?
1. Long-term scheduler makes decision to maintain a good mix of CPU-bound and I/O-bound processes.
- No long-term scheduler in Unix and Windows.
2. Short-term scheduler makes decision on which process to get CPU.
- Simple schedulers just submit the processes in a first-come-first-serve manner to the CPU.
- Better schedulers allocate the CPU to improve system performance.
- Waiting time for CPU.
- Completion time of processes.
- Responsiveness.
3. Medium-term scheduler
- always change CPU-bound and IO bound, then kick out;
- better mix of the two types of processes.
- Control multi-programming degree after process admission.
Context switching: Sequence of events to bring CPU from an executing process to another
8.[4] How can you create a child process? What is the possible relationship between a child and a parent? What is a process hierarchy? Distinguish between zombie and orphan processes.
zombie process:
- A child not collected bt its parent,
- child exit before parent
- until collect by parent.
orphan process:
- A child has no parent
- parent exit before child exit
9.[4] What are the advantages of using a pair of cooperating processes? Give a common application with cooperating processes.
Advantages of process cooperation:
- Information sharing: concurrent access to data.
- Computation speed-up: break into subtasks for processes.
- Modularity: better structuring of functionality.
- Convenience: model a user in concurrent working mode.
Application: Web server and web browser (client) pair
10.[5] Distinguish between direct and indirect communication in message passing. What are the common issues in message passing?
Direct communication
- Processes must name each other explicitly.
Indirect communication
- Messages are directed and received from mailboxes (also called ports).
common issues: Synchronization
11.[5] What are the key issues in buffering and synchronization between message sender and receiver?
Three different implementations for the message queue:
Zero capacity
- No message could be buffered.
- Sender must wait for receiver and vice versa.
Bounded capacity (most common)
- Queue can only store up to n messages.
- Sender must wait if the queue is full. (kinder of the blocking send)
Unbounded capacity
- Queue can hold infinite number of messages.
- Sender never needs to wait.
Four possible communication arrangements could be made:
Send \ Receive | Blocking | Non-blocking
—- | —- | —-
Blocking | Blocking send / blocking receive (for important msg; hand to hand “rendegvous”; in could computing (barrier) ) | Blocking send / non-blocking receive (least common)
Non-blocking | Non-blocking send / blocking receive (most common) | Non-blocking send / non-blocking receive
12.[6] Distinguish between non-preemptive and preemptive scheduling algorithms. What are the common performance criteria to be considered in scheduling?
Non-preemptive scheduling is easy to do.
- A process just uses the CPU until it wants to give it up
Preemptive scheduling is more complex.
- A process will be deprived of the CPU when its allocated time slice is used up or some other event happens.
performance criteria:
- CPU utilization
- Throughput
- Turnaround time
- Waiting time
- Response time
13.[6] Explain the operation of common scheduling algorithms. What are the relative performances of the algorithms? Explain the possible problems with a scheduling algorithm, e.g. convoy effect, starvation, excessive context switching.
Convoy effect happens when a single long process is blocking a number of processes.
starvation: The low priority process starves for the CPU that is repeatedly consumed by high priority processes.
14.[6] What are some common queues in a multi-level queue scheduling algorithm? What are the key parameters in the feedback mechanism of multi-level feedback queue algorithm?
System (Priority), interactive (RR), batch (FCFS/SRT) Queues
key parameters:
- Number of queues.
- Scheduling algorithms for each queue.
- Method used to determine when to upgrade a process to a higher priority queue.
- Method used to determine when to downgrade a process to a lower priority queue.
- Method used to determine which queue a process should enter when that process needs CPU.
15.[6] Draw Gantt charts for the following set of processes using different scheduling algorithms and compute the required performance metrics.
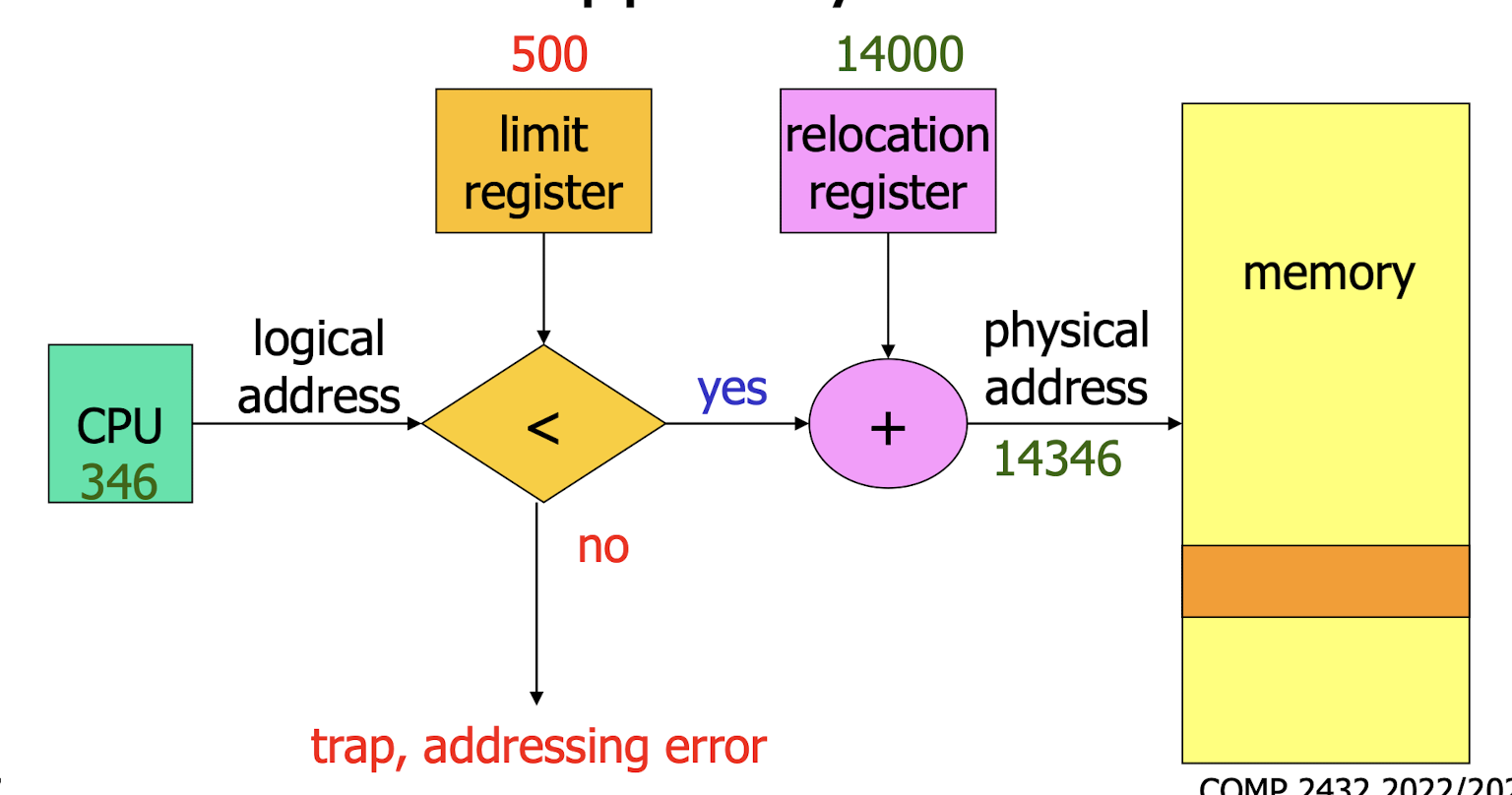
16.[7] What are the three types of address binding? Distinguish between logical and physical addresses. Use a diagram to explain how the MMU can translate the logical address and how the invalid address can be detected.
three types of address binding
- Compile time
- Load time
Execution or run time
Logical address is the address generated by the CPU, e.g. an instruction refers to an integer stored at a particular address(virtual address)
- Physical address is the address sent to the main memory.
17.[7] What are MFT and MVT in contiguous memory allocation? What are some common algorithms in contiguous allocation? How are the following requests served with MFT and with different algorithms in MVT? Explain the concepts of fragmentation and compaction.
MFT: Multiprogramming with a Fixed number of Tasks.
- Divide the memory into several partitions.
MVT: Multiprogramming with a Variable number of Tasks.
- A block of available memory is called a hole.
FF, BF, WF
Fragmentation: memory is available, but somehow could not be used.
- External Fragmentation
- Total memory space exists to satisfy a request but it is not contiguous that it could not be used.
- Internal Fragmentation
- with the wall;
- Memory internal to partition is not used (wastage inside partition).
compaction.
- Move memory content around to place all small free memory holes together to create one large block or hole.
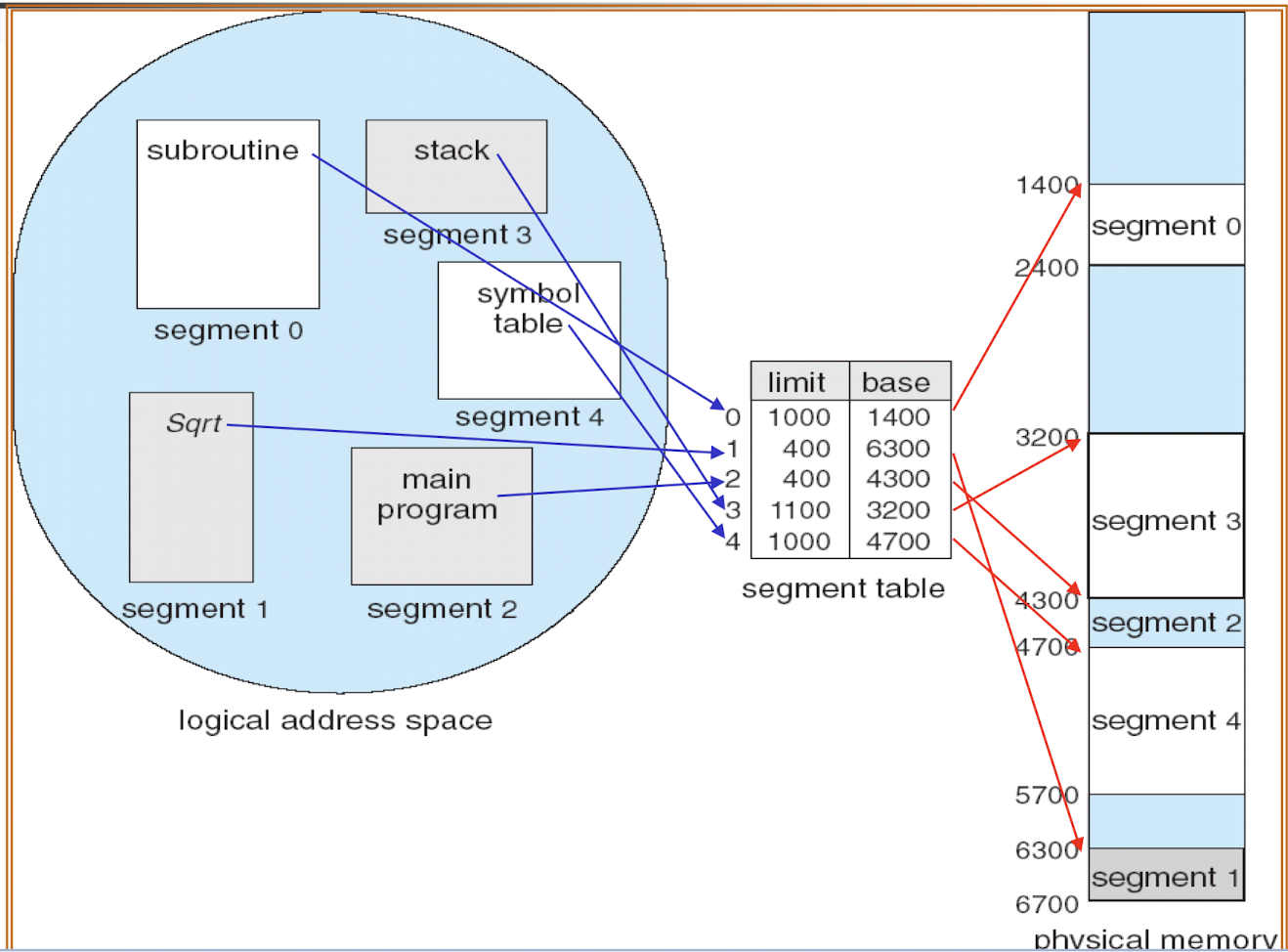
18.[7] Draw diagrams to show how memory allocation is done for paging and for segmentation. Draw diagrams to illustrate the hardware needed to support paging and segmentation.
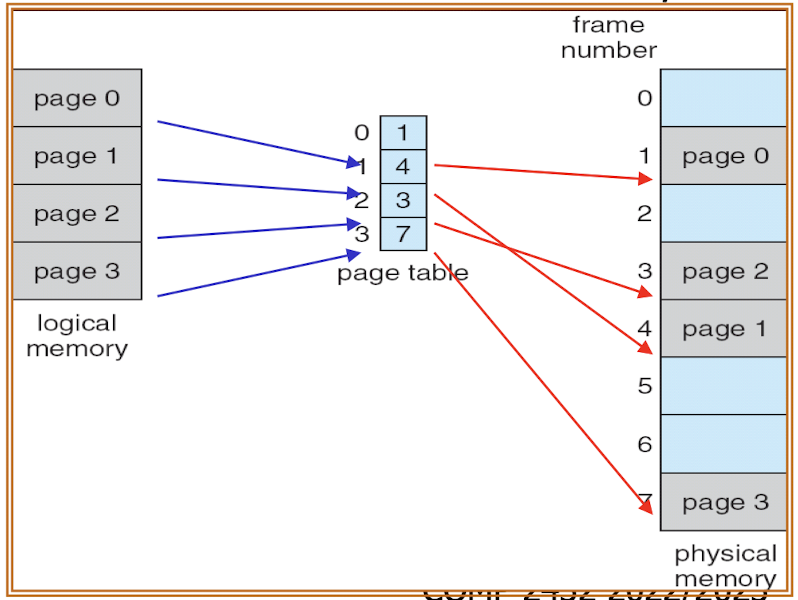
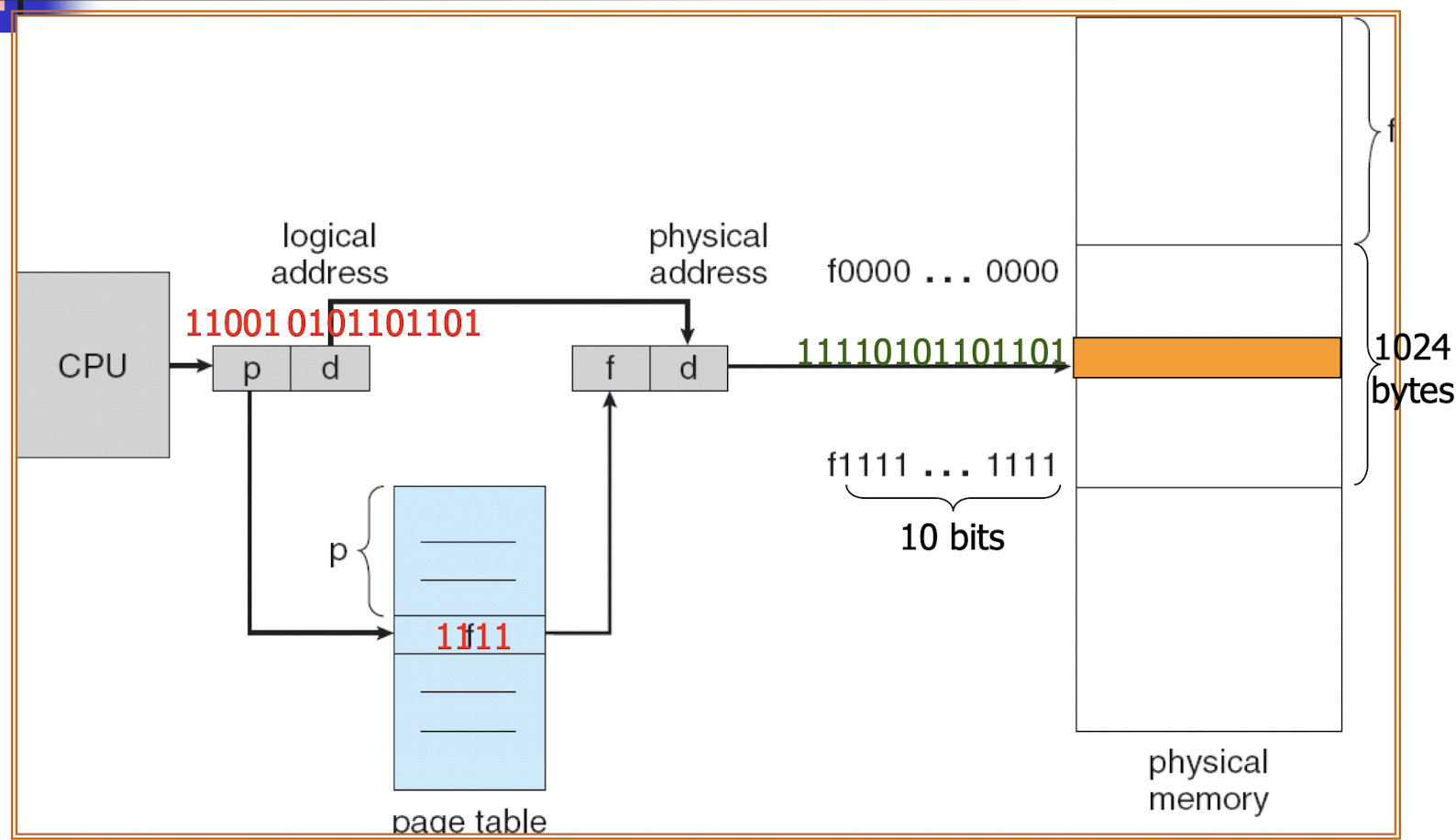
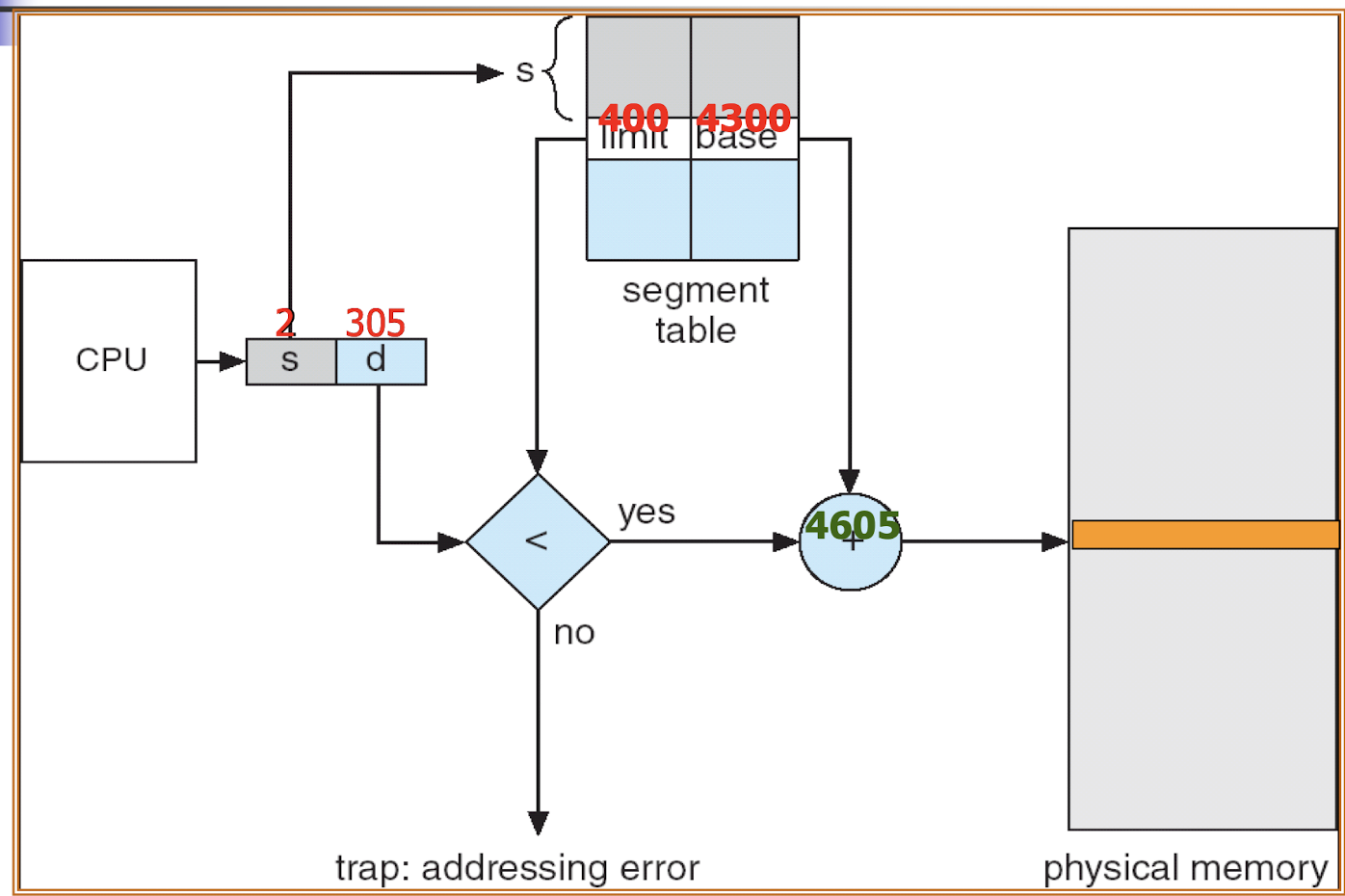
19.[7] Given a specific system configuration (e.g. size of physical and logical address space and paige size), determine the number of bits of addresses and the division of the addresses into different parts (page/segment number and offset). Show how a given list of logical addresses are translated into physical addresses.
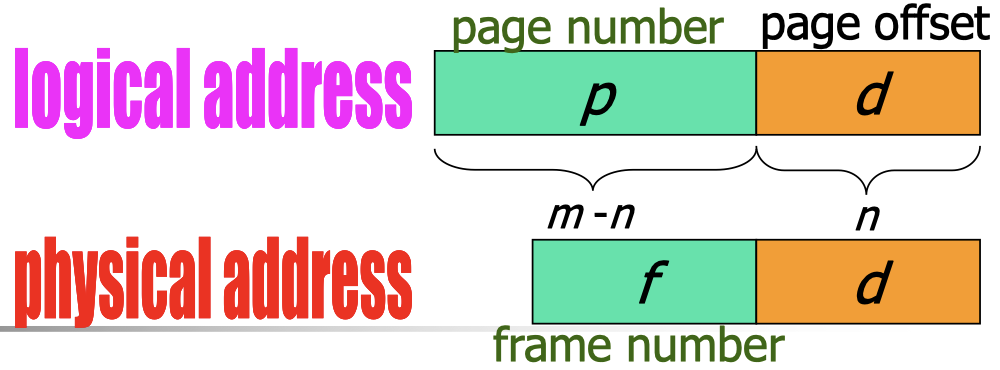
Assume that the logical address space is of size $2^m$ and each page (and frame) has a size of $2^n$.
- Logical address has a size of $m$ bits.
- Page number $p$ contains $m-n$ bits.
- Page offset $d$ contains $n$ bits.
20.[8] What is virtual memory? Given the size of physical and virtual address space and page size etc, determine the number of bits to the addresses and address component. Show how a virtual address is mapped to a physical address via the page table.
Virtual memory:
- separates user logical memory (not just logical address) from physical main memory.
- store the process on disk in a way similar to memory and load the needed part only when that part is executed.
21.[8] Distinguish between demand paging and anticipatory paging. Calculate the effective memory access time for a system.
Demand paging: bring a page into memory only when it is needed.
- Avoid loading pages that are not used (effective use of I/O resource).
- To load a needed page, process must wait for I/O to complete.
Anticipatory paging:
- predict what pages a process would need in near future and to bring them in before hand.
- No need to wait for a page to be loaded, faster response time.
- Prediction of future could be wrong and I/O would be wasted.
Effective Access Time (EAT) is the expected time to access to memory, in the presence of virtual memory.
- EAT $= (1 – f) \times$ memory access time $+ f \times$ page fault service time.
- Page fault service time = page fault overhead + time to swap the page in + restart overhead.

22.[8] Describe the procedures to serve a page fault. Draw a diagram to illustrate how virtual pages can be mapped to physical frames according to the page table.
Servicing a page fault:
- Get an empty frame from the free frame list.
- Schedule I/O to load the page on disk into the free frame.
- Update the page table to point to the loaded frame.
- Set the valid-invalid bit to be valid.
- Restart the instruction that caused the page fault.
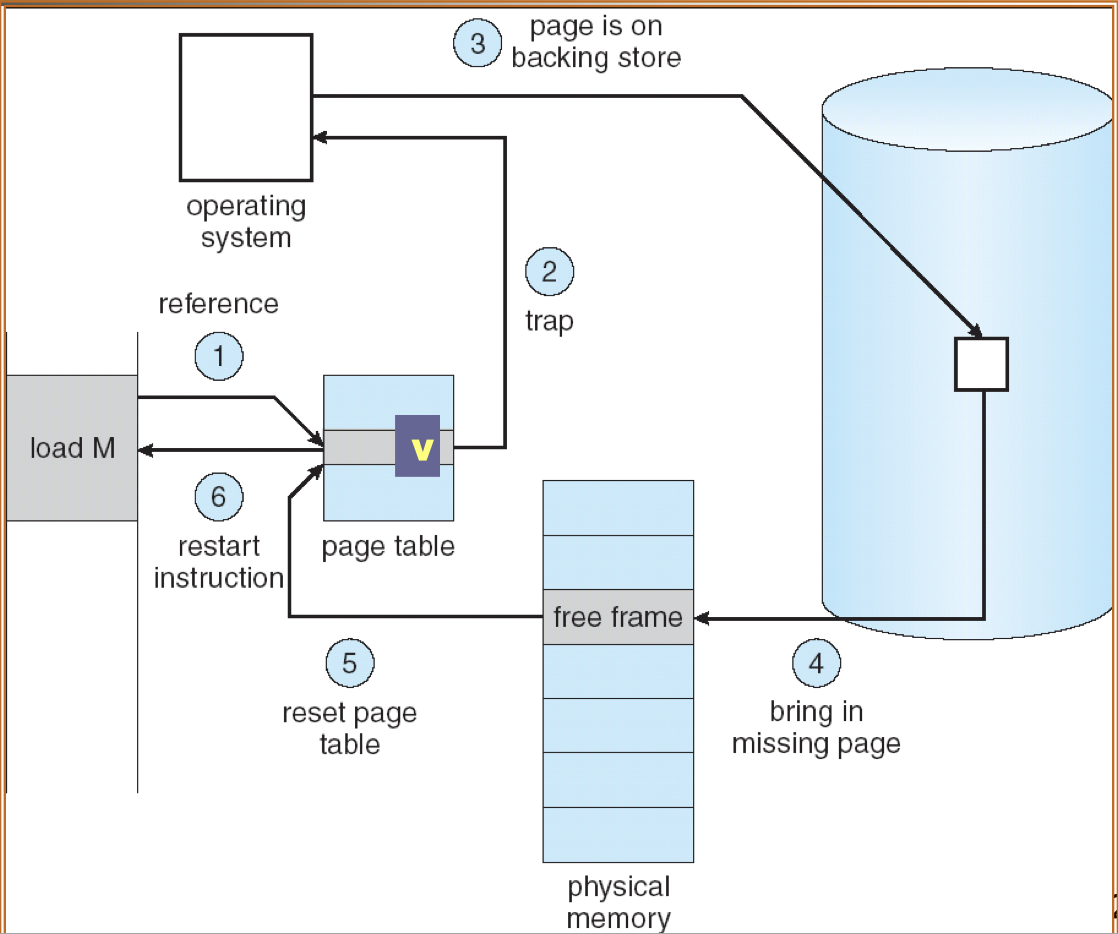
23.[8] Why is there a need for page replacement? Given a reference string, indicate the content of the frames after each page indicated by the reference string is accessed, when different page replacement algorithms are applied, showing also the page faults.
Page replacement:
- Action of finding a frame in memory to be removed to free up the space in order to admit a newly needed page.
24.[9] Distinguish between deadlock and livelock using an example. What are the four necessary conditions to deadlock? What are the four types of methods to handle deadlock?
deadlock:
- set of blocked processes, each holding a resource and waiting to acquire a resource held by another process in the set.
livelock:
- Each one tries to make a move to avoid forever waiting.
- No one can make any progress.
- It can be resolved if people are more lucky.
Four necessary conditions to deadlock:
- Mutual exclusion: Only one process at a time can use a resource.
- Hold and wait: A process holding at least one resource is waiting to acquire additional resources held by other processes.
- No preemption: A resource can be released only voluntarily by the process holding it, after that process completes its task.
- preemption: run until the completion;
- Circular wait: There is a chain of waiting processes
four types of methods to handle deadlock:
- Ostrich approach: Ignore the deadlock problem and pretend that deadlocks never occur in the system.
- Deadlock prevention: Ensure that the system will never enter a deadlock state.
- Deadlock avoidance: Allocate the resources very carefully so that system will not enter a deadlock state.
- Deadlock detection: Allow the system to enter a deadlock state, detect it and then recover from it.
25.[9] Are the following system states safe? Using Banker’s algorithm, determine whether a certain resource request by a process can be granted.
Safety algorithm
(Against Need with Available)
Define temporary arrays $Work[m]$ and $Finish[n]$ boolean array
$Work = Available$
$Finish = false$
while not done do
- Find an $i$ such that $Finish[i] = false$ and $Need_i[j] \leq Work[j]$;
- if no such $i$ exists, break;
- $Work[j] = Work[j] + Allocation_i[j]$
- $Finish[i] = true$
If for all $i$, $Finish[i] = true$, then declare the system is safe;
If some are false, declare the system is unsafe.

Request algorithm
Define $Request_i[m]$ to be requested by process $P_i$.
- If not ($Request_i \leq Need_i$), then raise error ($P_i$ has exceeded its maximum claim) and stop;
- If not ($Request_i \leq Available$), then $P_i$ must wait, since resources are not available;
- Else: pretend to allocate requested resources to
$P_i$ modifying the allocation state:- $Available = Available - Request_i$
- $Allocation_i = Allocation_i + Request_i$
- $Need_i = Need_i - Request_i$
Run safety algorithm on this pretended state.
- If safe, then resources are allocated to $P_i$.
- If unsafe, then $P_i$ must wait and the old resource allocation state is restored.


26.[9] Which of the following system states is/are suffering from deadlock? Explain how the deadlock, if any, could be handled or resolved.


27.[10] Explain what a critical section is. What are the three properties that a solution to a critical section problem should satisfy?
critical section:
This shared resource can only be shared in such a way that at any moment, only one can use it and it cannot be used by another one before its current usage is completed.
A solution should satisfy three properties.
- Mutual Exclusion (safety) (first fulfil)
- Progress (liveness) (second fulfil)
- Bounded Waiting (fairness) (third fulfil)
28.[10] Give a solution to the producer/consumer problem using (a) shared variables, (b) critical sections.
(a) A shared buffer can be viewed as a drawer to store money that a parent is passing to a child.
(b) Semaphores
29.[10] Determine whether the following program is correct in a solution to the critical section problem. Explain your answer via examples.
Peterson’s algorithm for ONLY two processes.
Two processes share two variables.
int turn = 1;// indicate whose turn it is to enter the critical section.boolean flag[2] = false;// indicate whether the process is ready to enter the critical section.
1 | |
Who goes first depends on the turn variable’s order
- Mutual Exclusion: achieved by critical section
- Progress: achieved by “turn” variable
- No fairness problem: achieved by “you go first” (turn=j)
- but not fair when “I go first” (turn=i)
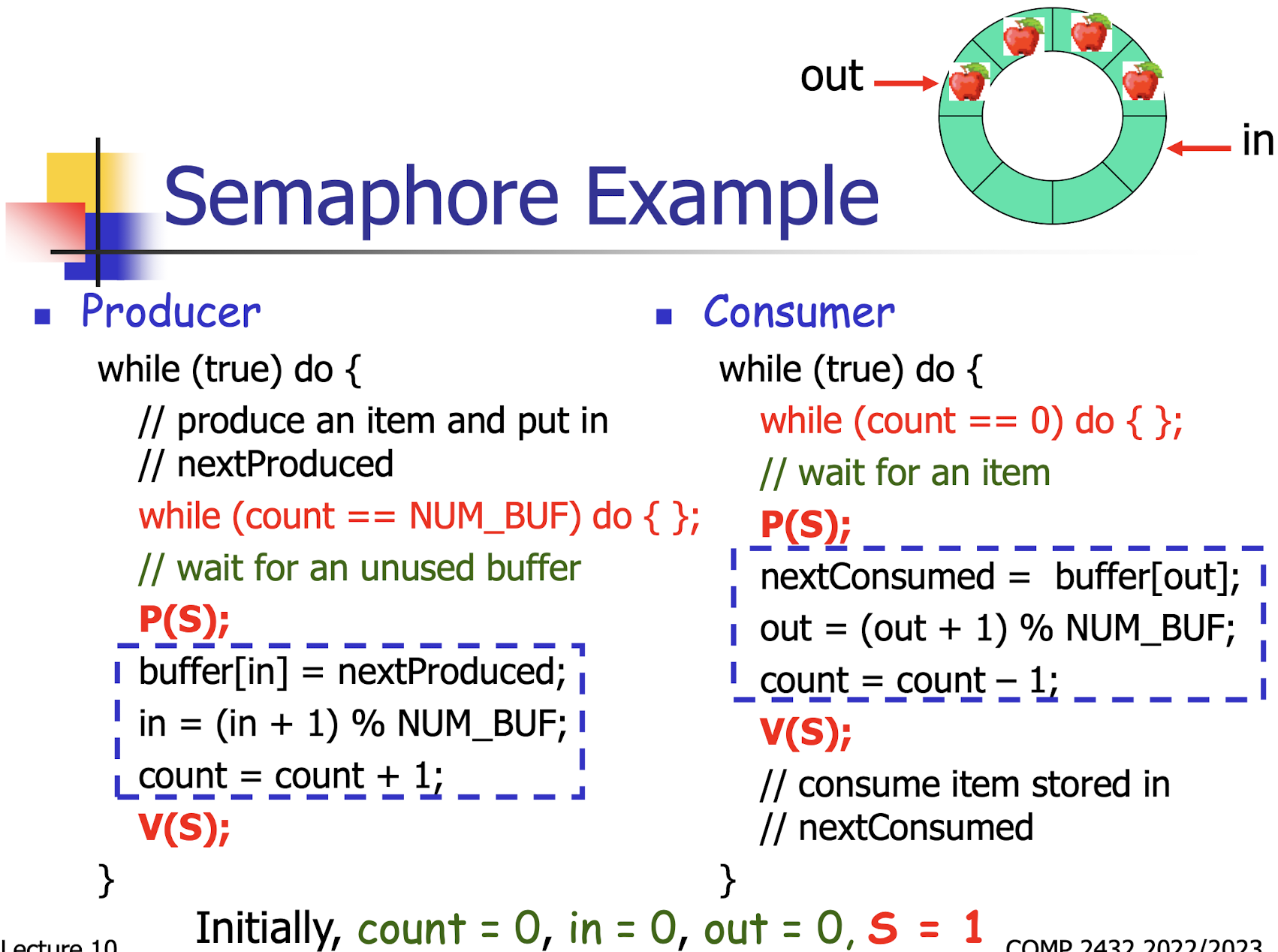
30.[10] Define the two operations on a semaphore. Explain how the semaphore operations could be implemented. Show how semaphores can be used to solve the critical section problem.
It provides two standard operations: P(S) and V(S).
P(S) means that the process will wait on S until S becomes positive.
- to wait for the resource to become available.
- then decrease S by one. to use it.
- (put following statement into the critical section, disablel the interrupt to ensure exe in ONE).
while (S<=0) do{};S = S - 1
V(S) means that S will be increased by one and the process waiting on S could proceed.
- S is released.
S = S + 1;
Binary semaphores are easy to implement.
- They are also called mutex locks (they look like locks and they help to ensure mutual exclusion or mutex).
- Providing critical section with semaphore S initialized to 1.
1 | |
S should be initialized to 1.0: no one go into;>1: all go into, crash;
31.[11] List the attributes for a file. Give the common operations on a file. Explain briefly the access modes to a file. Give the common operations on a directory. Differentiate between NFS, NAS and Cloud storage to support file systems.
attributes for a file:
- Name
- Identifier
- Type
- Location
- Size
- User or owner identification
- Protection
- Time and date information
operations on a file:
- Create
- Read
- Write
- Reposition within file
- Delete
- Truncate
- Open
- Close
access modes
- Sequential access
- Data are accessed in order
- Direct access
- Data can be accessed directly, based on record number.
- Indexed access
- A separate index file contains pointers to the data blocks of a data file (direct file or relative file).
32.[11] Differentiate between protection and security. How does policy differ from mechanism? What are domains and objects? How are they stored in the access matrix? Explain briefly the three implementations of the access matrix.
Protection
- Mechanisms and policy to keep programs and users from accessing or changing stuff they should not do.
Security
- Authentication of user, validation of messages, malicious or accidental introduction of flaws, etc.
Mechanism: OS provides access matrix and rules and ensures matrix is only manipulated by authorized agents and rules are strictly enforced.
Policy: user dictates policy on who can access what object and in what mode.
domain: specifies a set of objects and their operations.
objects: hardware or software resources
View protection need as a matrix.
- Rows represent domains.
- Columns represent objects.
Global table
Access control lists for objects
Capability lists for domains
1. Introduction to Operating Systems
1.1 OS and Computer System
1.1.1 OS
- The operating system (or OS) is the manager. It is the manager to the whole computer system.
- OS is the program that acts as an intermediary between a
user and the hardware.
OS goals:
- Execute user programs to solve user problems.
- Make the computer system convenient to use.
- Use the computer hardware in an efficient manner.
1.1.2 Computer System
A computer system contains four components.
- Hardware
- Provide basic computing resources.
- CPU, memory, I/O devices.
- Operating system
- Control and coordinate use of hardware among various applications and users. Windows 11, OS X, Unix, Linux.
- Application programs
- Define the ways that system resources are used to solve user computing problems.
- Word processors, compilers, web browsers, database systems, video games.
- Users
- People, devices, other computers.
1.2 The Operating System
A manager should
- Allocate and manage company resource effectively.
- Control working of subordinates so that they deliver performance.
An operating system is
- A resource manager
- Manage the allocation of computer resources.
- Decide between conflicting requests for efficient and fair use of resource.
- A control program
- Control execution of programs to prevent errors and improper use of computer.
1.3 Components of OS
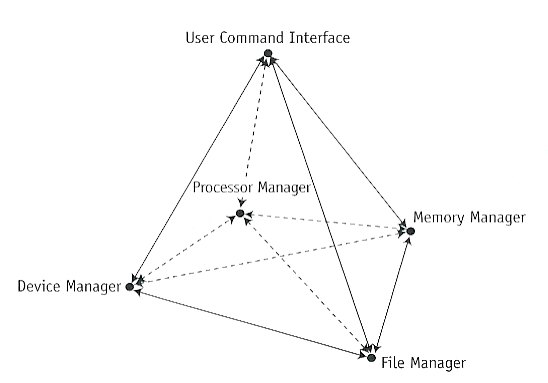
- Processor manager
- Handle jobs within system to be executed by CPU (processor)
- Memory manager
- Allocate the memory to be used by jobs.
- File manager
- Provide systematic storage for permanent data or programs.
- Device manager
- Control the different devices, mostly physical I/O devices.
- User command interface
1.3.1 Processor Manager
A process is a program in execution
- Program is a passive entity. You write a program to be executed
- Process is an active entity. You run a program to create a process.
- Create and terminate processes.
- Suspend and resume processes.
- Allow for process communication.
- Allow for process synchronization.
- Handle deadlocks.
The same program could create multiple processes.
- For example, you could invoke multiple copies of IE at the same time to browse different web pages.
1.3.2 Memory Manager
- Data should be in memory when a process is executing.
- Instructions of the program for a process should be in memory for execution.
- Memory management controls when and what data or program code should be in memory.
- Data and program are loaded into memory when necessary.
- OS must keep track of the usage of memory.
1.3.3 File Manager
- Storage (disk or tape) is controlled by its device(disk / tape drive).
- Devices have different device features
- Storage that a user could use is often generalized into a file
- A user of a file does not need to concern with the speed or storage method.
1.3.4 Device Manager
- OS should hide variations and details of hardware devices from the user.
1.3.5 User Command Interface
- OS accepts commands and performs tasks according to user need.
Two major types of interfaces:
- Batch interface: commands are stored in a file (script file or *.bat file) before hand.
- Interactive interface: commands are issued on the fly by users. There are two types of interactive interfaces:
- Command line interface (CLI)
- Graphical user interface (GUI)
1.4 Other aspects of OS
1.4.1 Protection and Security
Protection
- controlling access of processes or users to resources defined by the system
Security
- The defense of the computer system against internal and external attacks.
1.4.2
Network manager
- Provide a convenient way for users to share resources while controlling access to them.
1.5 OS Services
- User command interface
- Program execution
- I/O operations
- File-system manipulation
- Communications
- Error detection
2. Interrupts and System Calls
2.1 I/O Processing
Mostly use the interrupt.
- Synchronous I/O
- User program will wait until I/O completes.
- At most one I/O request is outstanding at a time
- Asynchronous
- User process is still running.
- Several I/O requests working together.
- An asynchronous call returns immediately, without waiting for the I/O to complete.
2.2 Interrupt Processing
An interrupt
- is a signal to the CPU to tell it about the occurrence of a major event.
- is the mechanism the OS uses so that it could turn attention to other activities and to manage resources, because interrupt will seize the CPU.
- Get the CPU back to the OS.
Two type of interrupts:
- Maskable interrupt: interrupt that may be ignored or handled later. A lower priority interrupt is maskable.
- Non-maskable interrupt: interrupt that cannot be ignored. The CPU must handle this. A non-maskable interrupt may be “over”-interrupted by another non-maskable higher priority one.
Cause of interrupts, for 3 type:
- Program interrupt:
- Caused by conditions within CPU
- Caused by I/O interrupt:
- I/O related events
- Timer interrupt:
- Caused by the hardware timer
2.3 Interrupt Handling
- After an (non-maskable) interrupt occurs, CPU Interrupt will put aside the process it is executing, by saving the program counter and register values on a stack.
- It looks up an interrupt table, using the interrupt number as an index, for a procedure for execution.
- interrupt handler, or interrupt service routine (ISR)
- executed in response to the interrupt to serve the interrupt.
- Jumps to;
- After the interrupt is serviced, the CPU resumes the suspended program and returns to the next instruction pointed to by the saved PC.
- New interrupt Y has a lower priority, it will wait till the first one X completes.
- New interrupt Y has a higher priority, it will seize the CPU from the current interrupt handler X.
2.4 Operating System Operation
Almost all OS are interrupt-driven .
- Interrupts allow the OS to gain control of the system when necessary (there is a special event).
The timer mechanism
- Set up interrupt to occur after specific time period (alarm)
- Operating system decrements counter upon timer interrupt.
- watchdog timer.
- In Unix:
- a special timer interrupt handler, called the clock routine, plays a central role in process scheduling and resource management.
- It is triggered by the hardware clock every 1/60 second in the original Unix design.
User is NOT allowed to disable the interrupt.
- It is triggered by the hardware clock every 1/60 second in the original Unix design.
- a special timer interrupt handler, called the clock routine, plays a central role in process scheduling and resource management.
2.5 User and Kernel Mode
Two mode:
- User mode
- Normal instructions, but not privileged instructions.
- Kernel node
- execute all instructions. Only OS processes should be executing in kernel mode. It is also called system, privileged mode;
- Provide ability to distinguish when the system is running user program or system (OS) program.
- A process running with user mode bit ON is a user process.
- A process running with user mode bit OFF is a kernel or system process.
Allow user go into the OS.
- entry port to the OS.
- Trap: changes from user mode to kernel mode, executes the privileged I/O command, returns from system call and reverts back to user mode to continue execution.
2.6 System Calls
A system call
- is a programming interface to the services provided by the OS.
- similar to a procedure call (a very special procedure call).
- When the user process executes the system call, the system call interface generates a software trap,
- Enter the kernel mode, save the user info, and the system call routine is executed (like interrupt).
5 Types of System Calls:
Process control
- Load, execute, create, terminate, abort, get/set attributes, memory allocation.
File management
- Create, delete, open, close, read, write, reposition, get/set attributes.
Device management
- Request, release, read, write, reposition, get/set attributes, attach/detach device.
Information maintenance
- Get/set time/date, get/set system data, get/set various attributes.
Communications
- Create connection, delete connection, send message, receive message, transfer status.
2.6.1 System Call Parameter Passing
Common procedure call parameter passing mechanisms.
- Pass-by-value (C, C++ and Pascal)
- Keep the copy the data, changes will not affect the original data.
scanf("xxx",$n);*n = 10;
- Pass-by-reference (Java objects, C++ & and Pascal var)
- NO copy, changes will affect the original data.
- Pass-by-value/result (Fortran)
Three general methods used to pass parameters to OS.
- Register
- Put parameters in registers and system call routine reads them from registers.
- Simple and fast, but it fails if the number of parameters is more than number of registers.
- Table
- Put parameters in a block or a table in memory.
- Pass the address of the block as a parameter in a register.
- Stack
- Push parameters onto the stack of the program.
- System call routine pops parameters off the stack for use.
2.7 System Programs
System programs
- provide a convenient environment for program development and execution.
- Some of them are just user interfaces to system calls.
- Some others are much more complex.
Unless we are programmers, we would not see system calls, but we see system programs.
Types
- File manipulation
- Status information
- File modification
- Programming language support
- Program loading and execution
- Communications
- Utilities
2.8 Types of Operating Systems
- Batch processing
- Multiprogramming
- Time-sharing
- Real-time
- Distributed
2.9 Operating System Structure
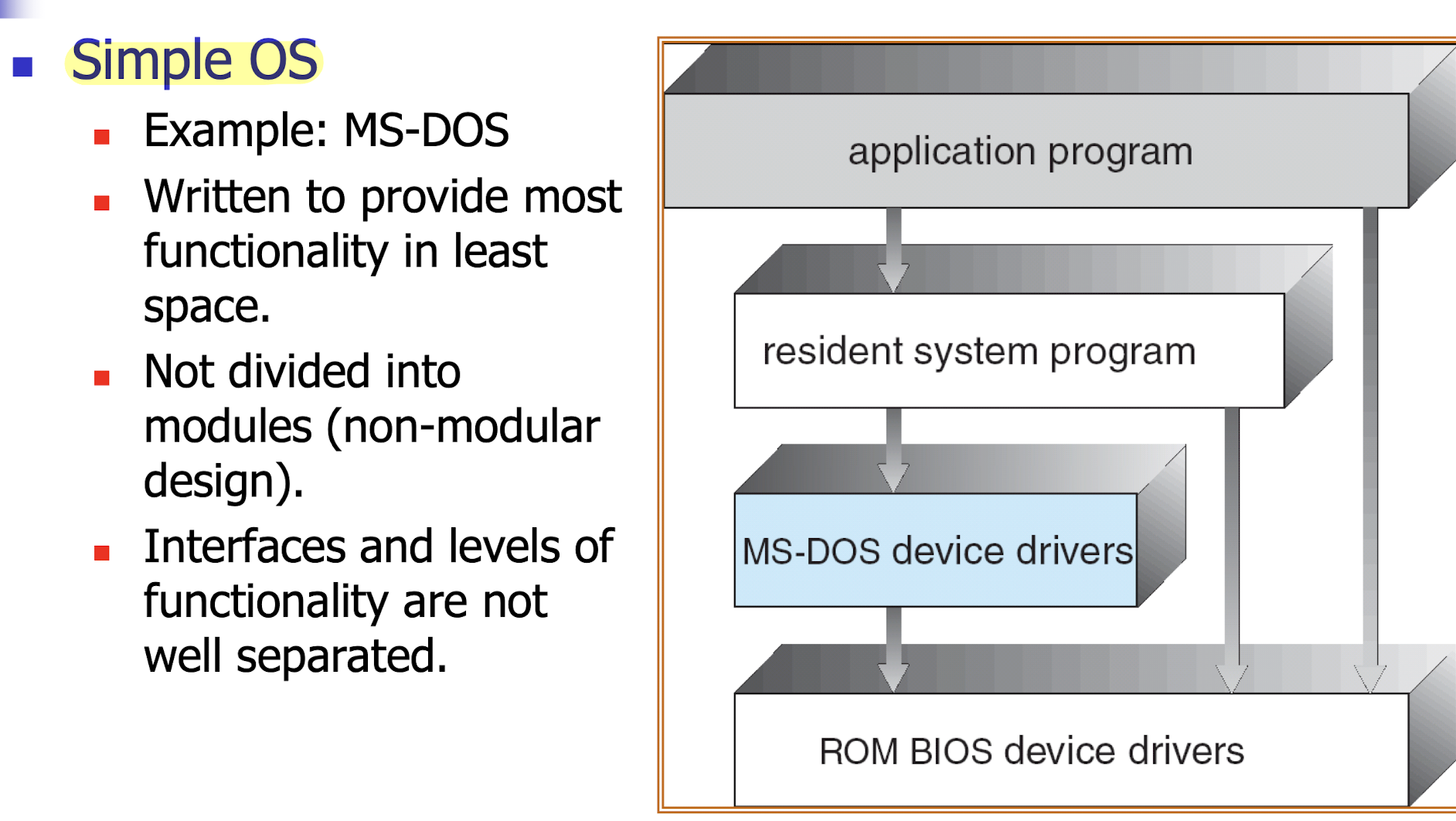
- Simple OS
- like: MS-DOS
- provide most functionality in least space.
- Not divided into modules (non-modular design).
- Interfaces and levels of functionality are not well separated.
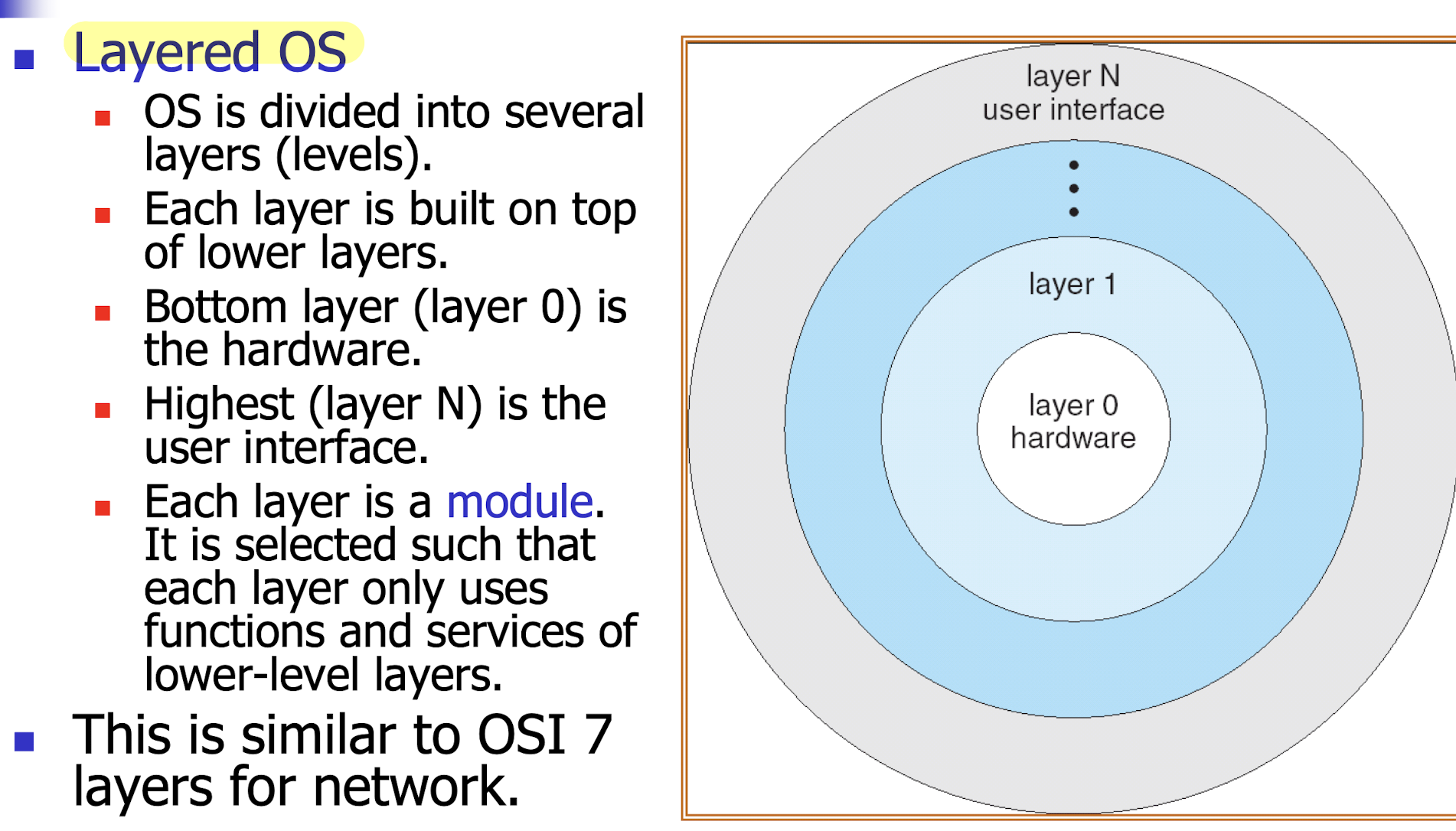
- Layered OS
- Each layer is a module. It is selected such that each layer only uses functions and services of lower-level layers.
2.9.1 *nix Operating Systems
Advantages of Unix and Linux:
- Reliability: seldom crash, ported to many systems and tested by many people.
- Security: better security, with simpler kernel design.
- Speed: programs run faster with lower OS overhead.
- Cost: Linux is free and many Unix systems are free.
- Open source: source codes available; you could verify that they are correct; you could modify them to specific need.
2.9.2 Unix Structure
Two layers:
- Kernel (key Unix core)
- System programs

2.9.3 Linux Structure
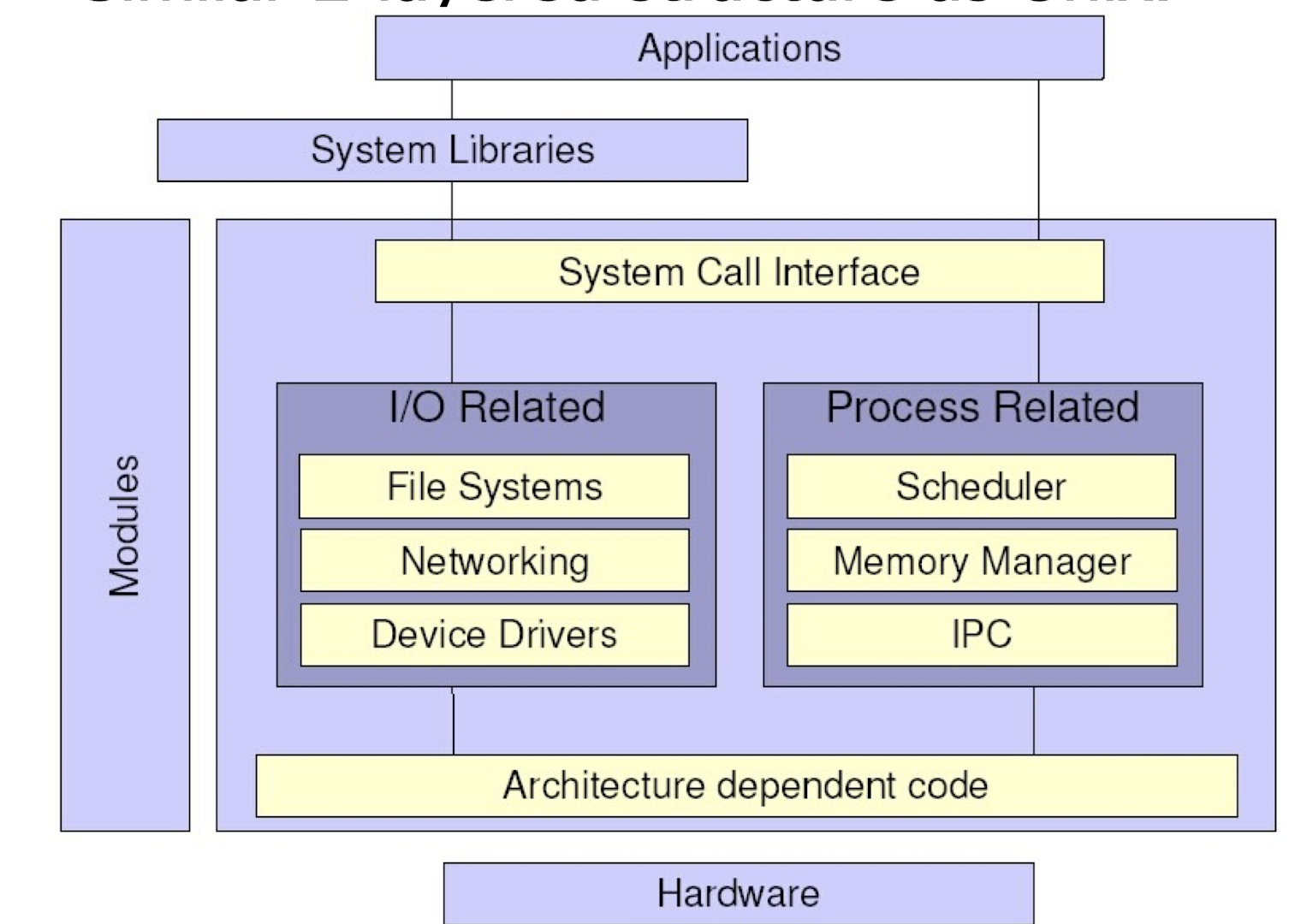
2.9.4 Mac OS X Structure
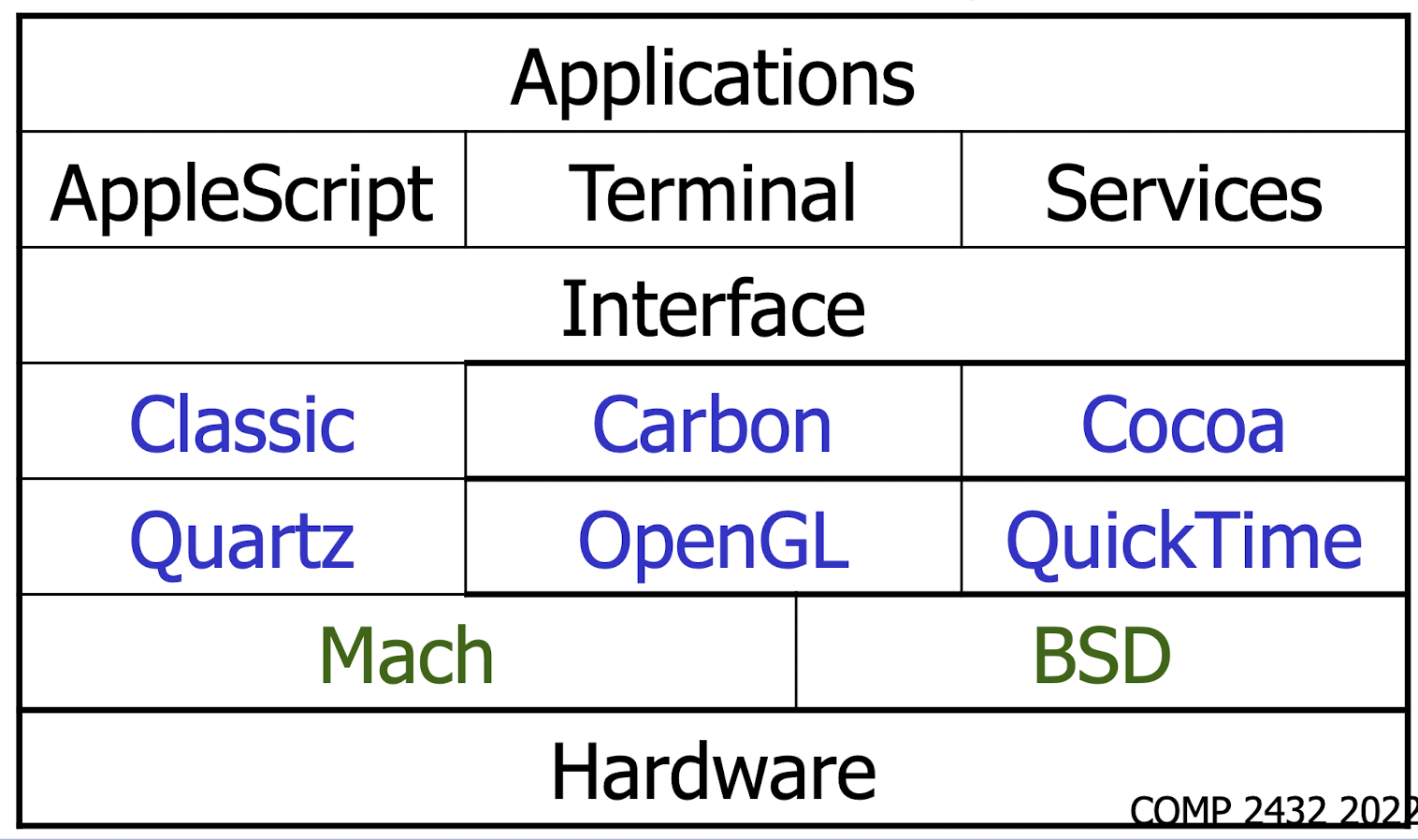
2.9.5 Microkernel System
- Move as many as possible of them from the “kernel” into “user” space to become user programs.
- microkernel approach (make the kernel small).
Advantages:
- Easier to extend a microkernel.
- Easier to port OS to new architecture / hardware.
- More reliable (less code running in critical kernel mode).
- More secure.
- Bug in user part will not kill the system, in kernel part will.
Disadvantages:
- Performance overhead of user space to kernel space communication.
2.9.6 Modular OS
- Object-oriented approach.
- Each core component is separated.
- Each talks to the others over known interfaces.
- Each is loadable as needed within the kernel.
Similar to layers but is more flexible.
3. Unix and Linux Programming
3.1 Basic Unix/Linux
shell: The commands are interpreted by the command line interpreter
Most commands used in Unix and Linux are actually system programs stored somewhere (often stored in /bin or /usr/bin).
- Files are collected into directories (folders).
- There are also symbolic links (similar to shortcuts). A symbolic link is itself a file, pointing to another file.
- Unlike symbolic links, a hard link is identical to the same physical file that it refers to.
- To create a directory, use
mkdir- For example,
mkdir comp2432
- For example,
- To delete an empty directory, use
rmdir- the directory must be empty
- To change to a directory, use
cd - To show your user directory, type
pwd(print working directory) - To tell who you are, type
whoami - To see the list of files, type
ls - Type
historyto see a list of recent commands. !n: to re-execute a previous command found in history, where n is the number of the command (n could be a large number).!ca: to re-execute the most recent command that starts with ca.PATH="$PATH:."to append the current directory “.”
to the path variable (PATH).file: let you know the type and other information of a file (or a sequence of files)
file is associated with an access privilege
-rwx r— r—
- The first group of four means privilege for “user” (you).
- The second group of three means those for “group” (your classmates).
- The third group of three means those for “others” (anyone else).
r means can read, w means can write, x means can execute.
chmod g+r f: add read permission to groupchmod o-r f: remove read permission from others
xxxx xxx xxx: #XXX can change into a hexodecimal number
wildcard
ls lab* will give you all files with a name beginning with lab.
ls lab? will give you all files with name labx (x is a character).
range specification ([] and {})
ls lab[1-5].cwill return all files labx.c where x is 1, 2, 3, 4, or 5ls lab[24].cwill only return lab2.c and lab4.c.ls lab{4,8,12}.c: only lab4.c, lab8.c and lab12.c
Patterns are regular expressions, built from some primitives:
^means beginning of line;$means end of line;.means any character;[abc]means any one of a, b, c;[^abc]means anything except a, b, c; use “\” for escape.
grep: look for a particular string within a collection of
files
$ grep malloc *.c
- Find C programs containing malloc and its usage.
$ grep -i polyu *.txt - Find text files and lines containing PolyU (ignore upper/lower case).
$ grep -l -i ’^polyu’ *.txt - Print only the names of files with lines beginning with “polyu”.
$ grep –h ’poly[^u]’ *.txt - Look for “poly*” except for “polyu” without filename.
to chain up commands:
- A chain contains a sequence of commands or even user programs.
prog1 | prog2 | prog3 | … | progn- The output of prog1 is the input to prog2 and so on.
ls | wc
- will count the number of lines, words and characters from a file containing all outputs from ls.
1 | |
1 | |
ls | wc | lpr
- will send the output above to a printer (lpr is the command to print with a printer)
3.2 Command Line Interface
The shell serves as a command interpreter.
- A shell will create a new child process (subshell) to execute the command passed to it.
- Features in shells make them being like programming languages(scripting languages).
3.3 Scripting Languages
A scripting language usually comes from a tool for quick handling of system operations.
- It is considered as a light-weighted programming language
- often used for automating repetitive tasks, e.g. backup.
- also used for prototyping and gluing together other programs.
- the basic data type, plus simple arithmetic.
- free of data types and data declaration.
- normally interpreted
Advantages
- Fast to write, ready to execute.
- A shell script is often smaller than a program.
- Allow partial execution before complete script is developed.
- Powerful to directly access OS services and execute commands.
- Allow string processing and output intermixed with those from running other programs.
Disadvantages
- Execute more slowly.
- Weaker data structure and computational support.
- Syntax often strange and program hard to understand.
- Protection against accidental mistakes is weak.
- Occasional bugs around.
3.4 Shell
- The first word specifies the command to be executed.
- All words following the command are its arguments.
- Several commands can be given at once by separating them with a semicolon
;.- Three processes will be created to execute the three commands sequentially
- Several commands can also be chained together via pipes
|(output being passed as input to the next).- Two processes will be created to execute the two commands (ps and more) in parallel (as concurrent processes).
$$ echo $$$: print out the pid of the current shell process
3.5 Variables
- the variables usually store strings.
- case-sensitive
- at most 20 characters long,
- with letters, digits and “_”.
Local (default) variable, global;
- Local variables are only valid within the shell when it is defined
- Environment variables are valid across all shells created by the existing shell when it is defined.
- To define, using
export:export varname=value
- Can NOT be passed out from the subshell to the parent shell.
- To define, using
- There must not be any space before and after “=”;
- print content of a variable, use echo
$varname;
To evaluate:$(( expr )) evaluates expr:
1 | |
let: evaluates expr and assigns the result to the variable varname:
1 | |
Built-in variables:
HOME
- Store the full pathname of the home directory: where you will go to (home) when you just type cd.
PATH
- Store a list of directories to be searched when running programs or shell scripts, separated by “:”.
PS1
- Store primary prompt string, with a default value of ‘\s-\v$ ‘, meaning system-version then $.
PS2
- Store secondary prompt string, with a default value of ‘> ‘. It is used for continuation of input lines.
PWD
- Store current working directory set by cd command.
- it is a variable, not like the
pwd, which is a program
HOSTNAME
- Store current machine name.
UID
- Store .
PPID
- Store process id of parent.
HISTSIZE
- Store number of lines of history to remember, default to the value of 500.
history
- Setting it will enable command history to be stored, useful for future, default to on.
noclobber
- Setting it will prevent overwriting of files when using I/O redirection, default to off.
ignoreeof
- Setting it will prevent accidental logging out with
(end of input), often used when entering data from keyboard, default to off.
allexport
- Setting it will automatically export all modified variables,
default to off.
To turn on use set –o variable
To turn off, use set +o variable
set –o noclobber# turn on noclobber featureset +o history# turn off history storage
3.6 Array
- The elements of the array (strings or integers)
- are numbered by subscripts starting from zero (like C).
1 | |
3.7 Quotation
Single quote (’str’)
- The strong quote.
- Enclosed string looks like literal.
- No substitution and no execution is done.
Double quote (”str”)
- The weak quote.
- Enclosed string is almost like literal.
- Substitution is done for variable contents (prefixed with “$”).
- Execution is done for back-quoted commands.
- Watch out for “!!”, which is trying to match a past command.
- This is a bug in showing the current command.
A special backquote enables a command to be executed (`str`)
- In bash, it is more common to put it as $(str) instead.
3.8 Shell Scripts
- create a shell file
first line contains “#!”, look at the path following the “#!” and start that program as the interpreter.
- use bash, so the first line is “
#!/bin/bash“.
- change the mode to be executable and run it.
chmod 700 fileorchmod u+x file
Most important
- A shell script should run without errors.
- A shell script should perform the task for which it is intended.
- Shell script program logic is clearly defined and apparent
- A shell script does not do unnecessary work.
- Shell scripts should be reusable.
Less important
3.9 Input/Output
output:
echo-n: stay on the same line to get the input
input:
read-p: prompt-t: timeout-s: silent-n: number of characters to read-a: input to an array
the standard input is the keyboard, and the standard output is the screen.
- input/output redirection: change the default input/output (e.g. to a file)
- You could store in a file (e.g. grade.txt) and redirects the input (<) from it.
$ GPA < grade.txt
You could also redirect outputs (>) away from the screen to a file (e.g. result.txt).
$ GPA > result.txt
$>,$>>: output and error;>>: append to the file;
Pipes:
- Processes are working concurrently using pipe but are working sequentially when using I/O redirection.
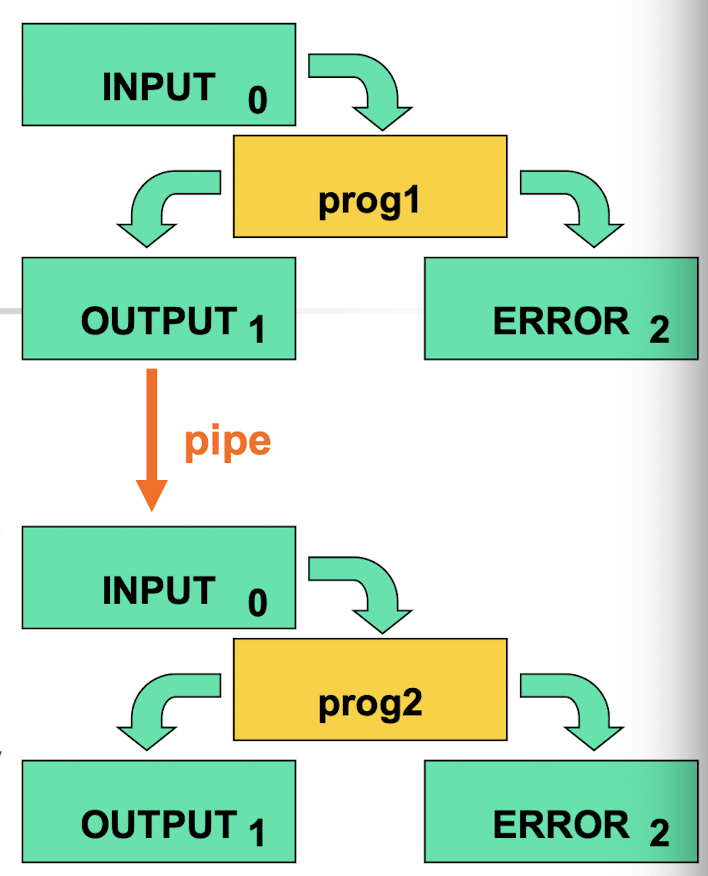
3.10 If-Statement
1 | |
-eq(==),-ne(!=),-gt(>),-ge(>=),-lt(<),-le(<=),-a(&&),-o(||), !- Note: you should use ==/!= instead of -eq/-ne to compare non-numeric.
3.11 Case-Statement
;;: match only the first pattern;;$: also match next pattern
1 | |
3.12 For-Loop
1 | |
1 | |
1 | |
- changes to the list inside the loop will NOT affect the number
3.13 While-Loop
1 | |
3.14 Until-Loop
pre-test loop: zero or more iterations
1 | |
3.15 File Testing
some built-in options for file inquiry.
-eFile exist-dFile is a directory-fFile is a plain file-rFile could be read (by owner)-wFile could be written-xFile could be executed
1 | |
3.16 Command Line Argument
$0: script name;$1-$x: All words following the script name
$$$$: Process ID of the shell.$?: Exit status of the most recently executed command;$#: Number of positional parameters (arguments).$*,$@: All positional parameters (arguments), starting from 1.
3.17 Exit Status
shell is the parent process of the script
- exit status is a number between 0 and 255.
- if the status returned is zero, the command was successful in its execution.
- the exit status is non-zero, the command has failed in some way.
- return value of -1 from a program is equivalent to 255, but 256 means 0
4. Process Management
4.1 Processes
- operating system executes a variety of programs for users.
- A process is a program in execution.
A process includes
- Value of program counter
- Value of registers and processor status word
- Stack for temporary variables
- Text for program code
- Data section for global variables
- Heap for dynamic storage of variables (those created using malloc)
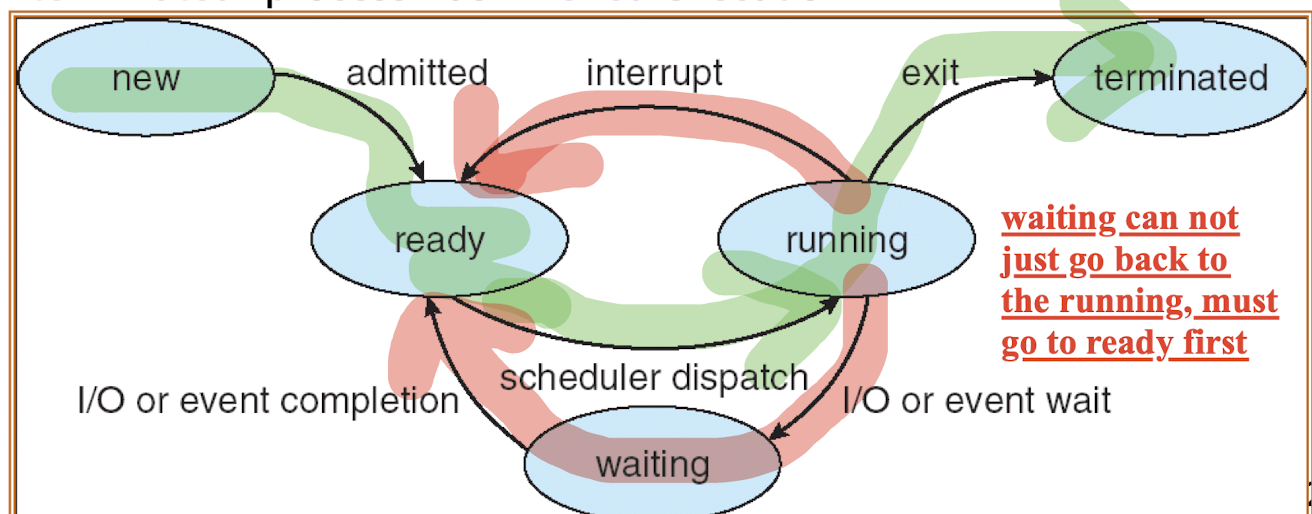
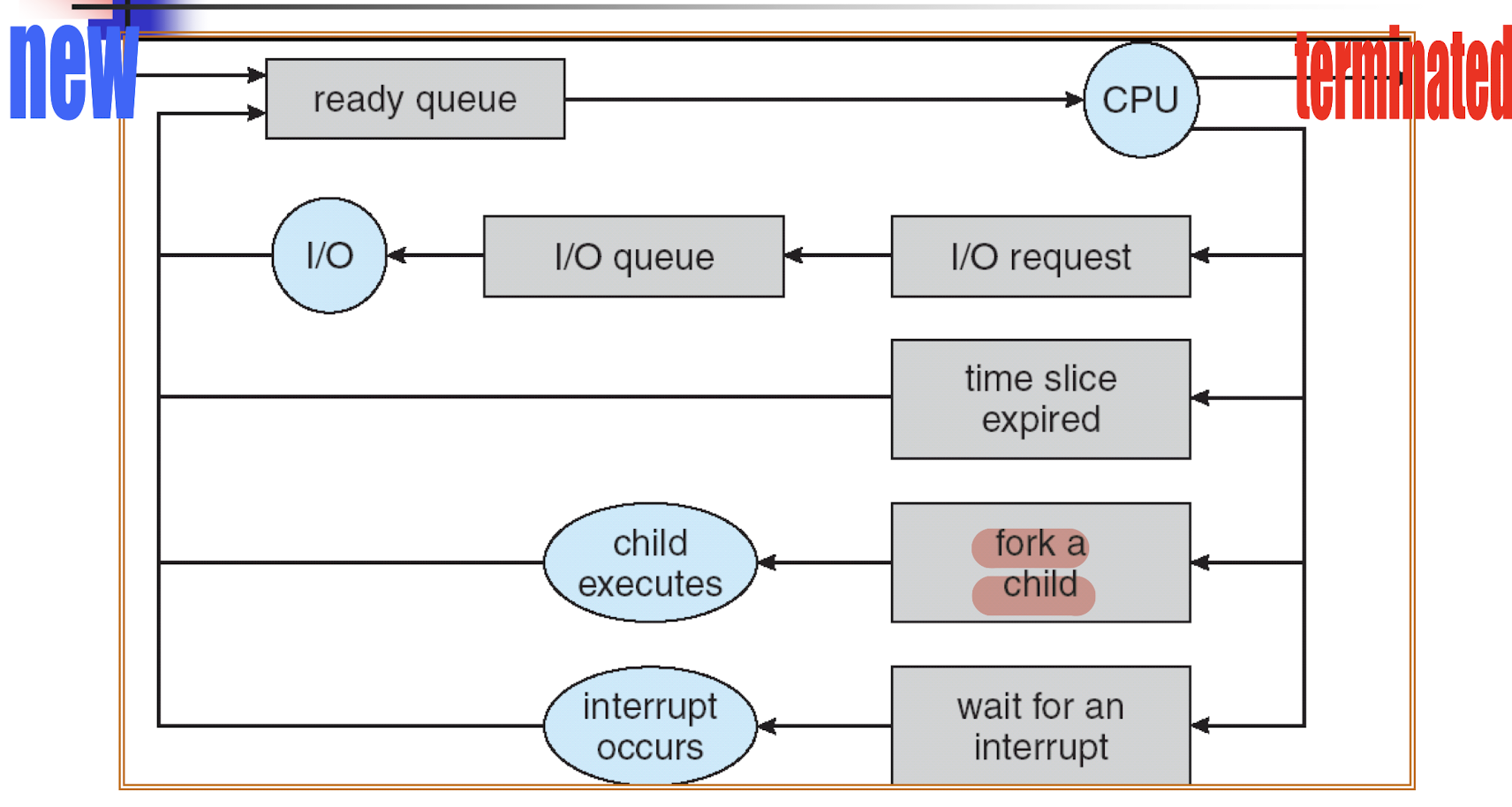
4.1.1 Process State
- new: process is being created.
- Not inside the OS
Admitted to the OS
- Not inside the OS
- ready: process is waiting to be assigned to a processor or CPU for execution.
- running: process is running (program instructions are being executed).
- terminated: process has finished execution.
waiting: process is waiting for some event to occur.
waiting can not just go back to the running, must go to ready first
4.1.2 Process Control Block
Process Control Block (PCB).
- Process state
- new, ready, waiting etc.
- Program counter
- CPU registers
- registers, stack pointer, PSW
- CPU scheduling information
- process priority, pointer to scheduling queue
- Memory-management information
- limit of memory boundary
- Accounting information
- process id, CPU time used
- I/O status information
- list of opened files
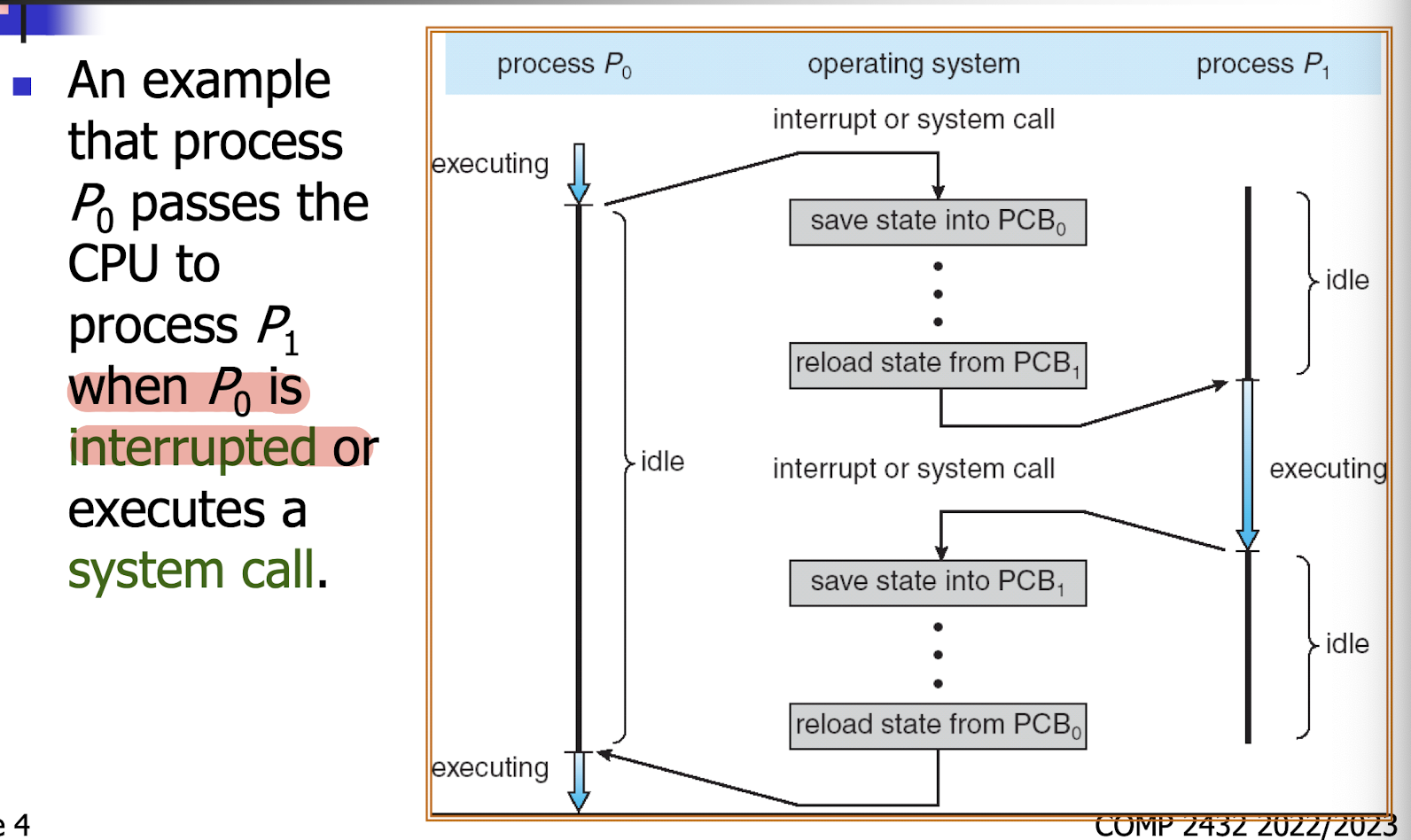
4.1.3 CPU Switching
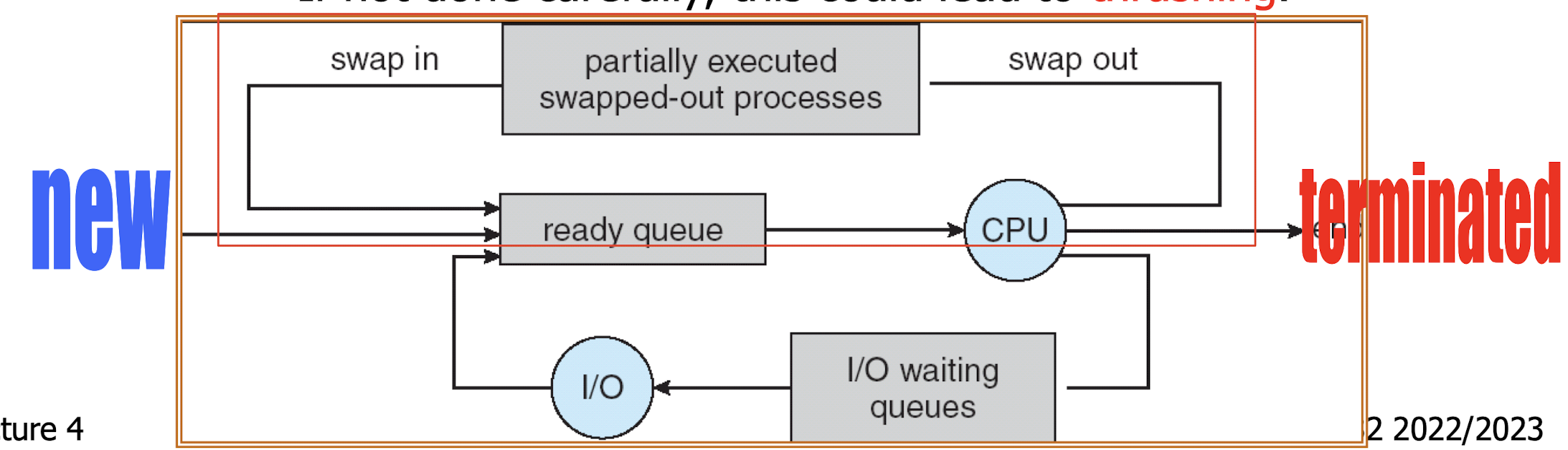
4.1.4 Process Scheduling Queues
Job queue: set of all processes in the system.
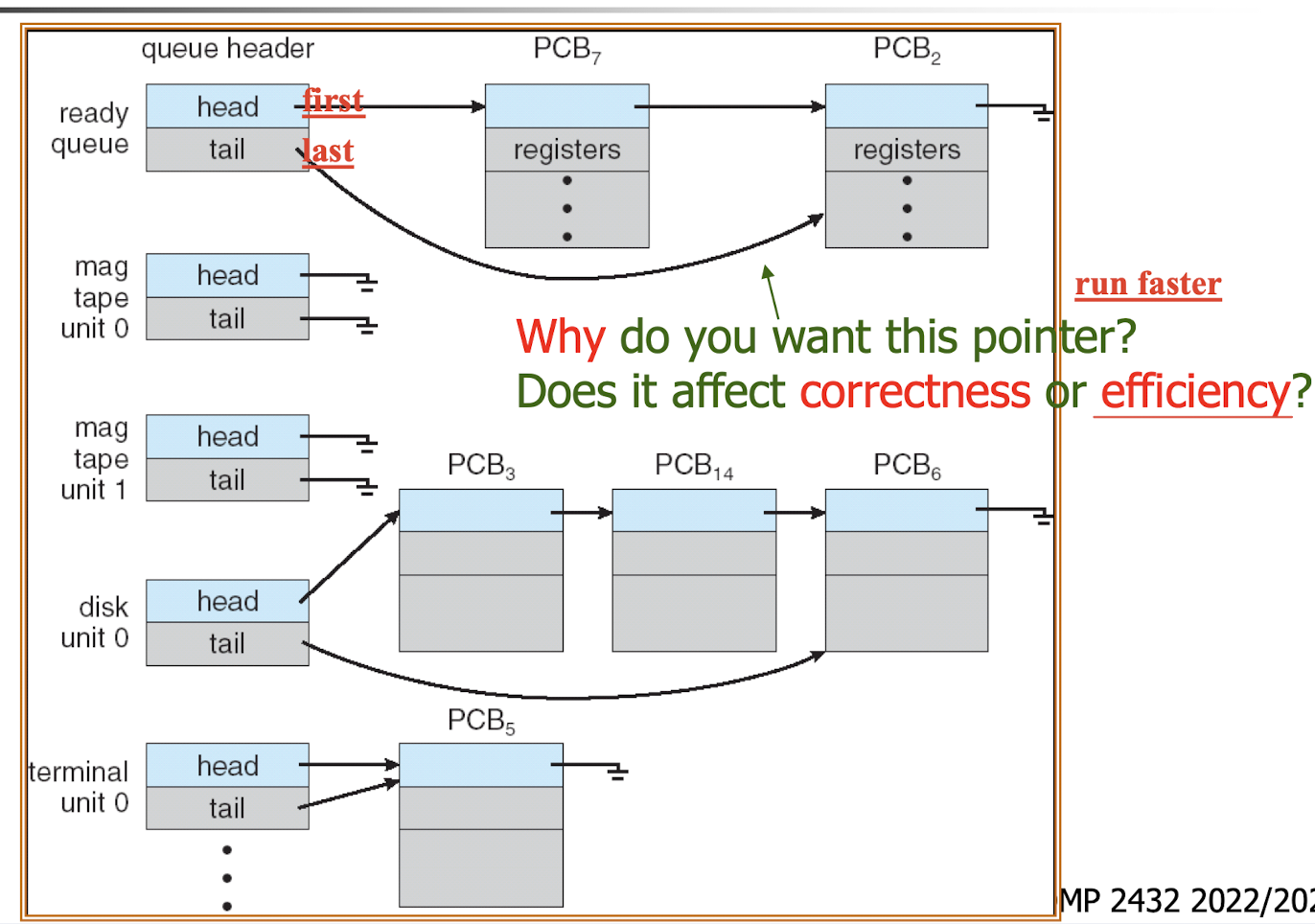
Ready queue: set of all processes residing in main memory, ready and waiting to be executed.
Device queues: set of processes waiting for an I/O device.
- process scheduler for each type of queues determines who will get service next.
4.1.5 Ready and I/O Device Queues
4.1.6 Process Life Cycle
4.2 Scheduler for Processes
A process will move through different queues as between its birth (creation) and its death (termination).
A scheduler selects the process to be served when it is waiting for different services.
Long-term scheduler
- Select which processes should be brought into the ready queue
- Who will be admitted to the OS
- should be a quite good one (it can afford a longer running time).
Short-term scheduler
- who will get the CPU next
- concerned with the allocation of CPU.
- step must be very fast (so it would be simple).
Two types of the process:
- I/O-bound process
- spends more time doing I/O than computations.
- many short periods of using CPU
- like an editor.
- CPU-bound process
- more time doing computations than I/O.
- computation programs, e.g. finding next move in chess playing.
may be I/O-bound initially and then become CPU-bound or vice versa.
Intermediate process between I/O and CPU-bound, with moderate I/O.
- computer system will not be effective if all processes are I/O-bound.
- Poor use of CPU
- will not perform well if all processes are CPU-bound.
- Poor device utilization.
1. Long-term scheduler makes decision to maintain a good mix of CPU-bound and I/O-bound processes.
- No long-term scheduler in Unix and Windows.
2. Short-term scheduler makes decision on which process to get CPU.
- Simple schedulers just submit the processes in a first-come-first-serve manner to the CPU.
- Better schedulers allocate the CPU to improve system performance.
- Waiting time for CPU.
- Completion time of processes.
- Responsiveness.
3. Medium-term scheduler
- Some systems provide medium-term scheduler
- always change CPU-bound and IO bound, then kick out;
- better mix of the two types of processes.
- Control multi-programming degree after process admission.
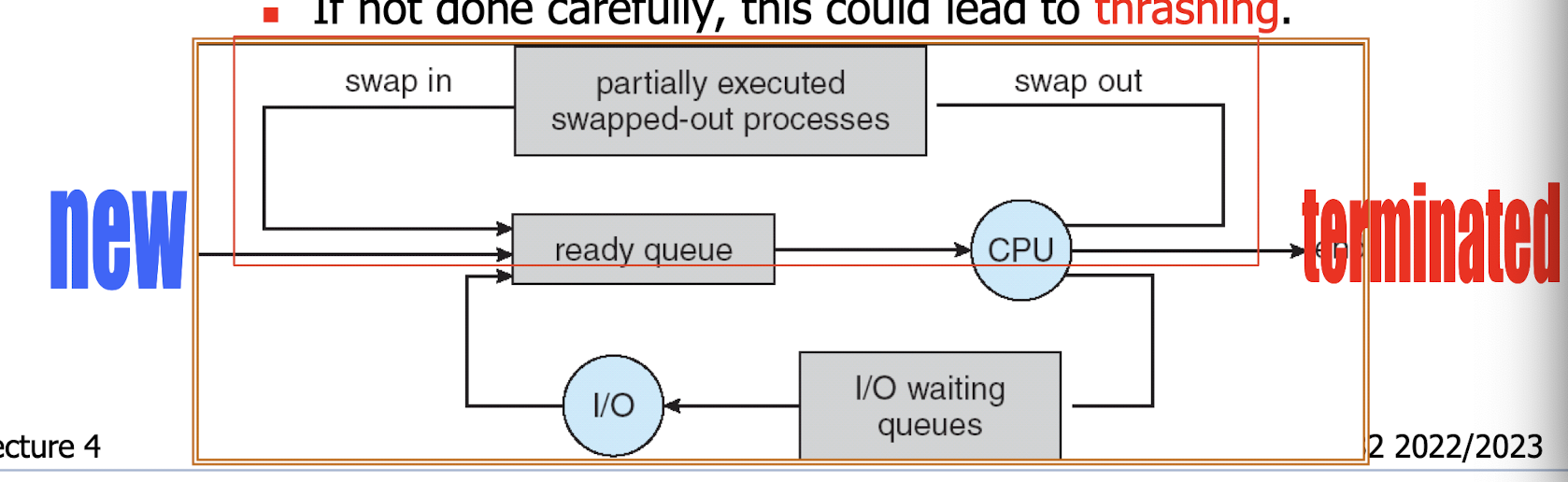
4.2.1 Context Switching
Sequence of events to bring CPU from an executing process to another
- the system must save the state of old process and load the previously saved state for new process.
- State of old process will be put on stack when the “time-up” clock interrupt occurs
- scheduler changes the PC and returns from interrupt/system call to the new process.
Context switching time is a kind of overhead.
- System does no useful work while switching from one process to another. only management work
- Time cost is dependent on hardware support.

4.3 Process Creation and Termination
4.3.1 Process Creation
type a.out in Linux, the Linux shell (CLI) creates a new process for a.out
- Processes are normally identified by an integer, called process identifier or pid.
- Since there is no long-term scheduler, the new process is automatically admitted and put in the ready queue.
- The creating process is called the parent process.
- The created process is called the child process.
Relationship between parent and its children:
- Resource sharing
- Parent and children share all resources.
- Children share subset of parent’s resources.
- Parent and children share no resources.
- Execution
- Parent and children execute concurrently. asynchrous
- Parent waits until all children terminate. synchronous
- Address space
- Each child duplicates that of parent.
- Each child has an independent program loaded into it.
To show the parent/children processes
ps -Hlforps -Helf
- daemon: listen to ssh connection
To create the new process: fork()
To replace process memory with a new program: exec()
collect child and then continues: wait()
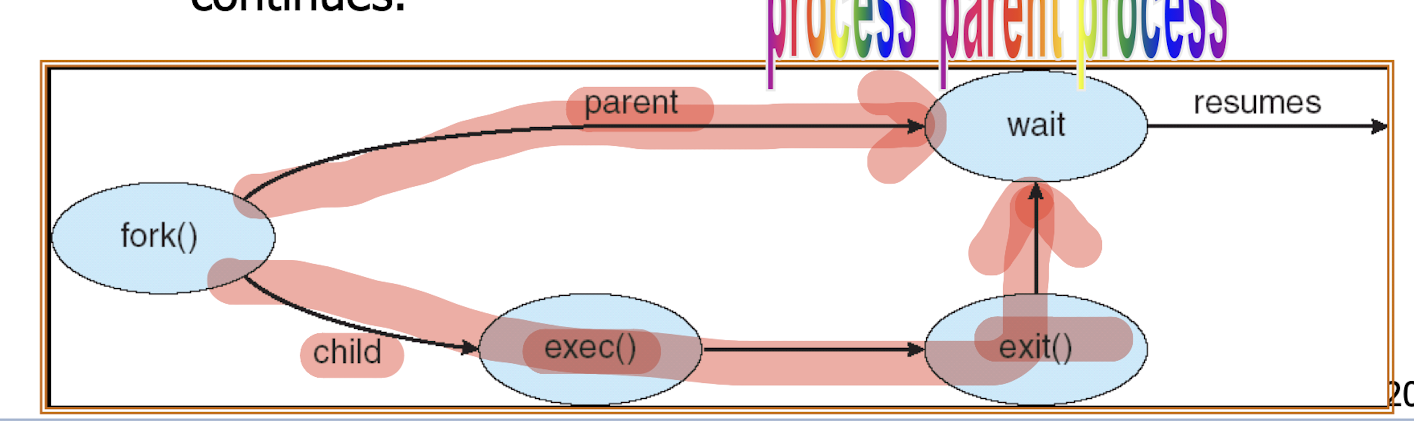
4.3.2 Process Termination
- asks the OS to terminate it by calling exit.
- Parent may terminate the execution of children processes by calling abort
- Child has exceeded usage of resources beyond its allocation.
- Task assigned to child is no longer required.
- Parent itself is exiting.
zombie process:
- A completed child process that is not collected or picked up by its parent is called a zombie process.
orphan process:
- A process without a parent is called an orphan process.
4.4 Unix/Linux Processes
4.4.1 Process Creation in Unix/Linux

In Unix/Linux:
- Resource sharing
- Parent and child share no resources.
- disjoint
- Execution
- Parent and child execute concurrently.
- Address space
- Child duplicates that of parent.
- Child may have an independent program loaded into it, with special exec system calls.
- Child duplicates that of parent.
Parent should wait for a child to collect it.
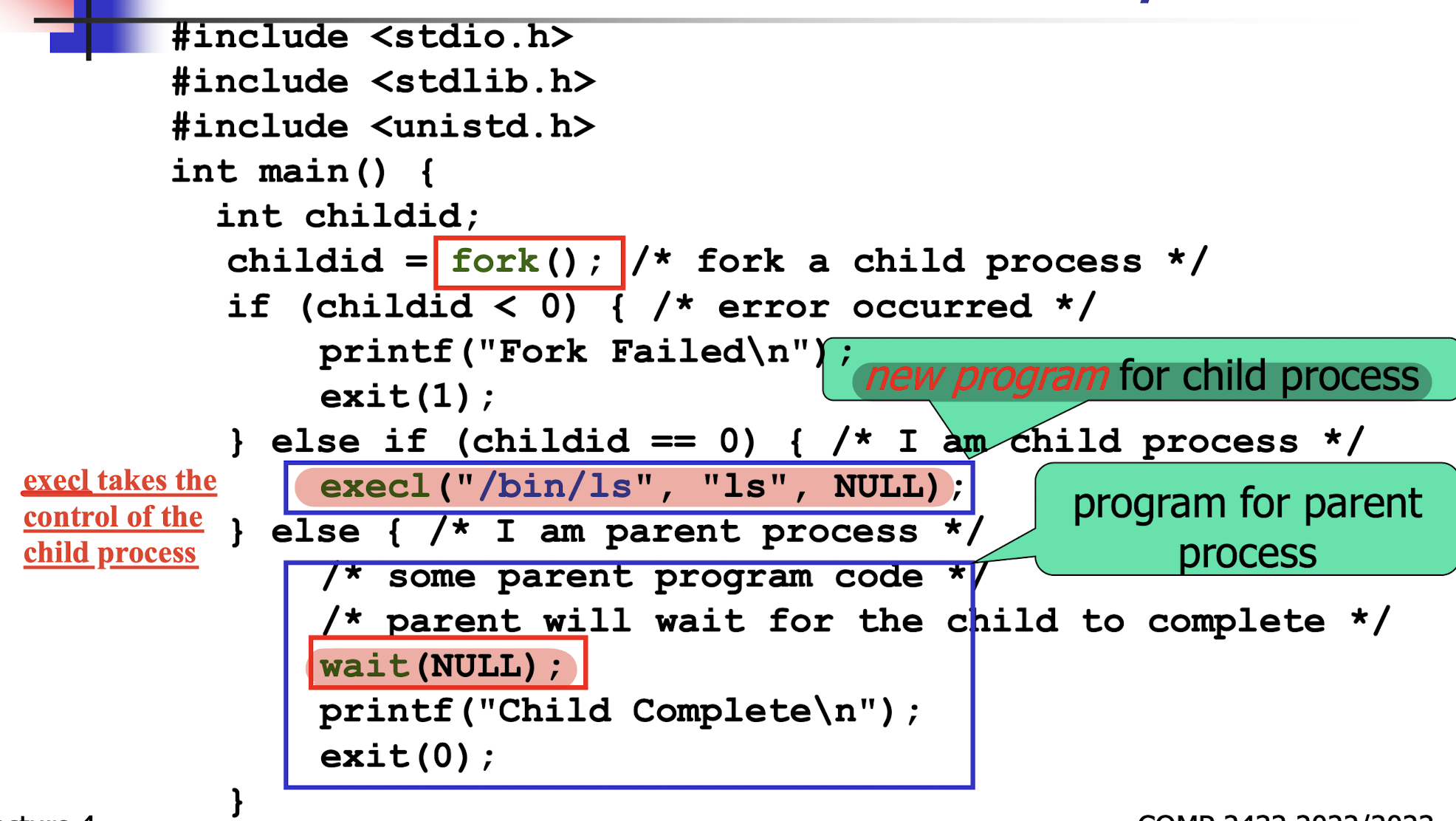
The exec family of system calls allow a Unix/Linux child process to execute another program (instead of the parent program).
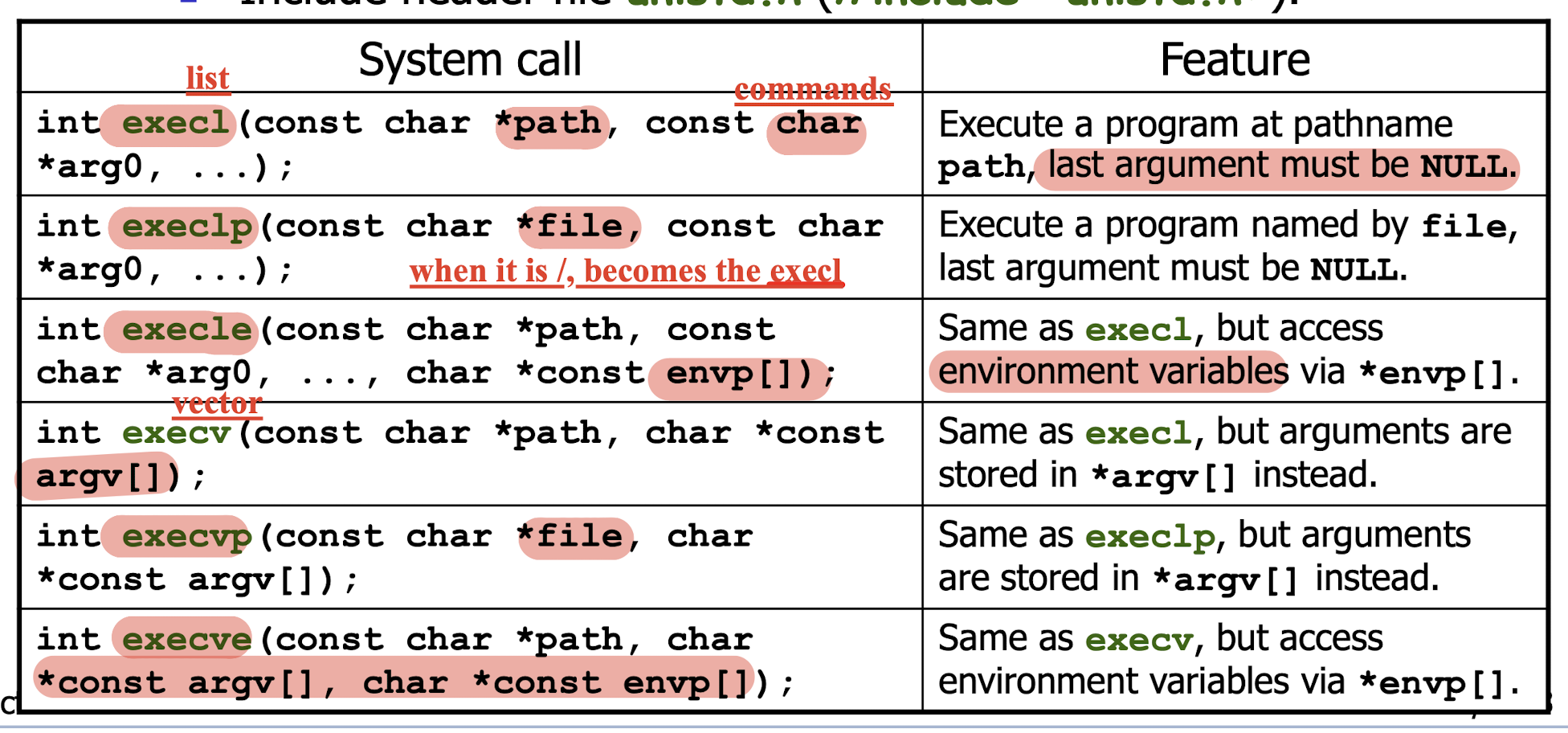
- A non-zero return value indicates an error from system call.
4.4.2 Process Termination in Unix/Linux
orphan:
- If parent does not wait for a child to complete, and if parent completes before child completes,
- Special arrangement in Unix and Linux for orphan.
- The special process willing to become new parent for all orphan processes has pid 1. It is the init process.
zombie:
- a completed child process that is not collected or picked up by its parent
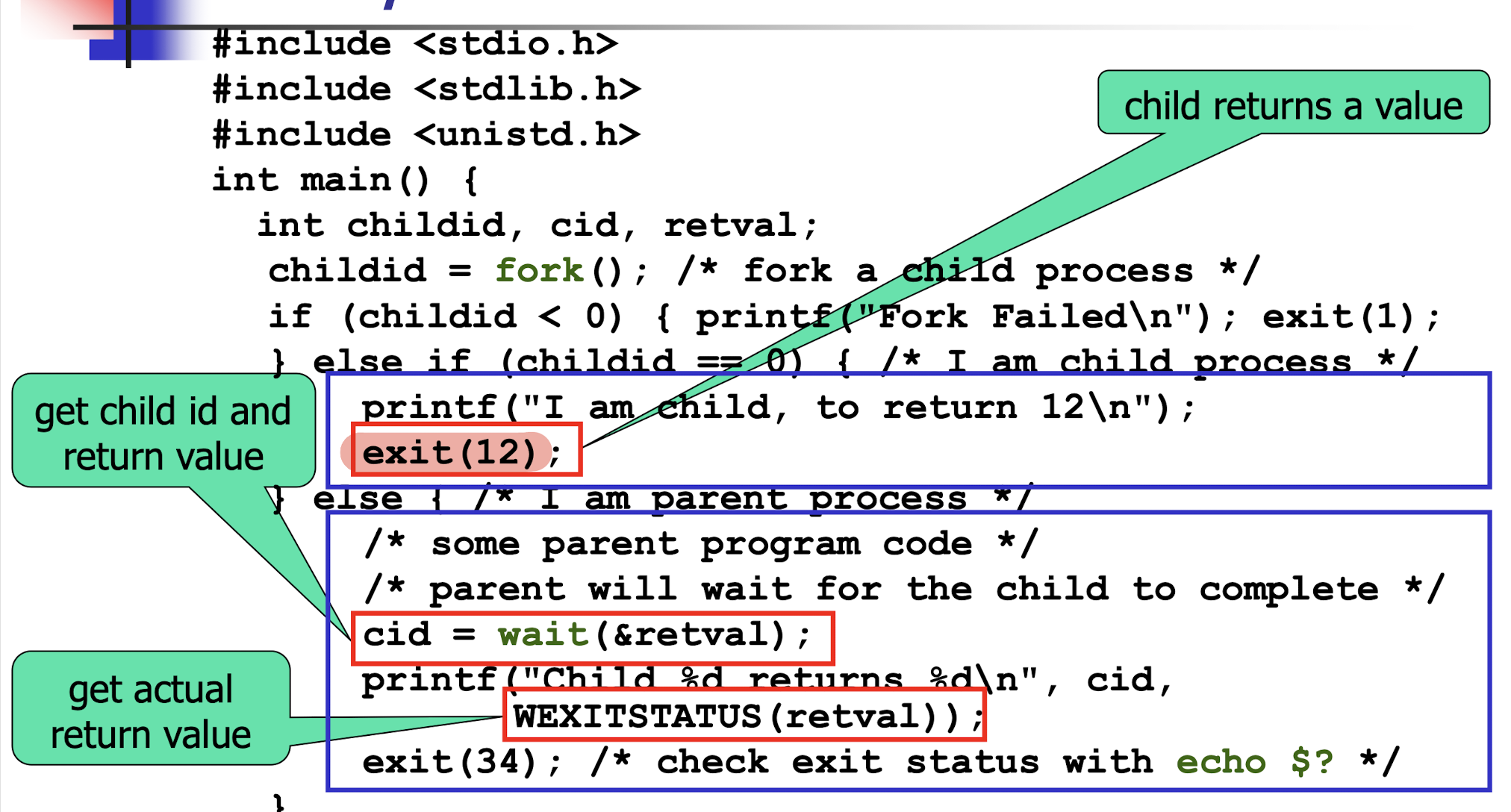
4.5 Process Communication and Synchronization
4.5.1 Cooperating Processes
- independent process cannot affect or be affected by the execution of another process.
- cooperating process can affect or be affected by the execution of another process.
- Web server and web browser (client) pair
Advantages of process cooperation:
- Information sharing: concurrent access to data.
- Computation speed-up: break into subtasks for processes.
- Modularity: better structuring of functionality.
- Convenience: model a user in concurrent working mode.
Model of a producer and a consumer:
- Producer process produces information (called item) that is
consumed by a consumer process. - Information (item) produced by producer must be stored up for consumer usage later (since consumer may not be running at the same speed as producer).
- Producer could store data into a shared array or shared queue and consumer takes it out there.
4.5.2 Communications Models
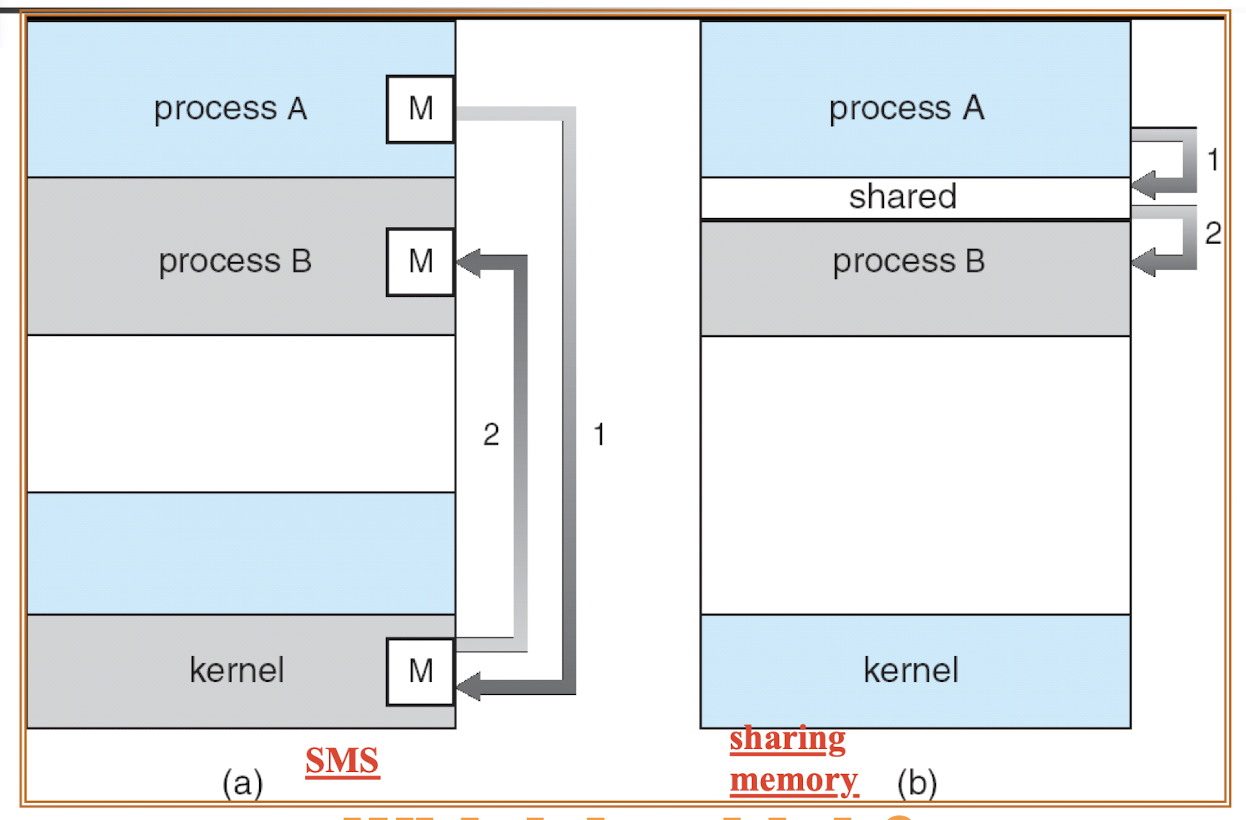
Shared memory system: processes communicate by reading/writing to shared variables.
Message passing system: processes communicate with each other by passing information without using shared variables.
4.5.3 Interprocess Communication
Interprocess communication (IPC) normally refers to message passing approach with two operations:
- send(message), receive(message).
4.5.4 Synchronization
problem:
- Concurrent access to shared data by cooperating processes (or threads) may make data inconsistent.
Synchronization
- ensures the orderly execution of cooperating processes that share a logical address space to guarantee data consistency.
5. Interprocess Communication and Programming
5.1 Interprocess Communication
IPC
Allow processes to communicate(link, locate) and to synchronize(coordination)
- Data transfer and sharing
- Event notification
- Resource sharing
- Synchronization
- Process control
Two major IPC mechanisms:
- Shared memory
- Message passing
Message passing is more common in practice.
- It is hard to share memory content across different computers over the network.
5.1.1 Direct/Indirect Communication
Direct communication
- Processes must name each other explicitly.
send(P, message): send a message to process P.receive(Q, message): receive a message from process Q.
- Properties of communication link:
- Links are established automatically.
- A link is associated with exactly one pair of communicating processes.
- Between each pair there exists exactly one link.
- The link may be unidirectional, but is usually bidirectional.
Indirect communication
- Messages are directed and received from mailboxes (also called ports).
- Each mailbox has a unique identifier;
- Processes can communicate only if they share a mailbox;
- Properties of communication link:
- Link is established only if processes share a common mailbox.
- A link may be associated with many processes.
- Each pair of processes may share several links.
- Link may be unidirectional or bi-directional.
- Operations:
- create a new mailbox.
- send and receive messages through mailbox.
- destroy a mailbox.
5.1.2 Synchronous/Asynchronous Synchronization
Synchronization between message sender and message receiver.
- Message passing may be either blocking or nonblocking.
1. Blocking: synchronous (need to wait, may be blocked).
- Blocking send ensures that the sender is blocked until the message is received by the receiver.
- Blocking receive ensures that the receiver is blocked until a message is available from the sender.
2. Non-blocking: asynchronous (no need to wait, will not be blocked).
- Non-blocking send allows the sender to send a message and can always continue.
- Non-blocking receive allows the receiver to receive a valid message or receive null if message is not available.
- Nothing sending to, will receive the null; always receiving.
Four possible communication arrangements could be made:
| Send \ Receive | Blocking | Non-blocking |
|---|---|---|
| Blocking | Blocking send / blocking receive (for important msg; hand to hand “rendegvous”; in could computing (barrier) ) | Blocking send / non-blocking receive (least common) |
| Non-blocking | Non-blocking send / blocking receive (most common) | Non-blocking send / non-blocking receive |
Buffering
- Sender may have sent several messages and receiver has not read them.
- A queue of messages is attached to the link to store (buffer) those outstanding messages.
- Three different implementations for the message queue:
- Zero capacity
- No message could be buffered.
- Sender must wait for receiver and vice versa.
- Bounded capacity (most common)
- Queue can only store up to n messages.
- Sender must wait if the queue is full. (kinder of the blocking send)
- Unbounded capacity
- Queue can hold infinite number of messages.
- Sender never needs to wait.
- Zero capacity
5.2 Unix/Linux IPC
IPC package is used to establish interprocess communication.
- The package sets up a data structure in kernel space.
- The data structure is usually persistent, i.e., it will normally continue to exist until being deleted.
- Appropriate system calls are provided for a programmer to develop a program using IPC mechanisms.
- Creation
- Writing
- Reading
- Deletion
Why should the IPC data structure be in kernel space?
Protection, in the user space is not safe, user may access other’s user space, kernel space is common for all users.With protection, a process cannot (and should not) access the memory space of other processes, nor the system (kernel) memory space.
5.2.1 Shared Memory Mechanism
Special system calls are provided to create shared memory segments within kernel memory space.
- User processes make system calls to create / remove / write to / read from the shared kernel memory space. (it is random)
- This is not flexible and is seldom used.
Unix Pthreads library provides more well-defined and more comprehensive mechanisms to support shared memory, since threads within the same process naturally share the memory space.
Linux also has Pthreads library available.
5.2.2 Message Passing Mechanism
Achieved via pipes(local machine) and sockets(over network).
Two major types of pipes:
- Unnamed pipes
- Named pipes: socket looks like a named pipe.
A Unix/Linux pipe is a unidirectional(one-way), FIFO(same order), unstructured(not separated) data stream:
- A buffer allocated within the kernel.
- Operates in one direction only.
- Some plumbing is required to use a pipe. (opening and closing)
- Fixed maximum size.
- No data type being transferred.
- Very simple flow control.
- Cannot support broadcast.
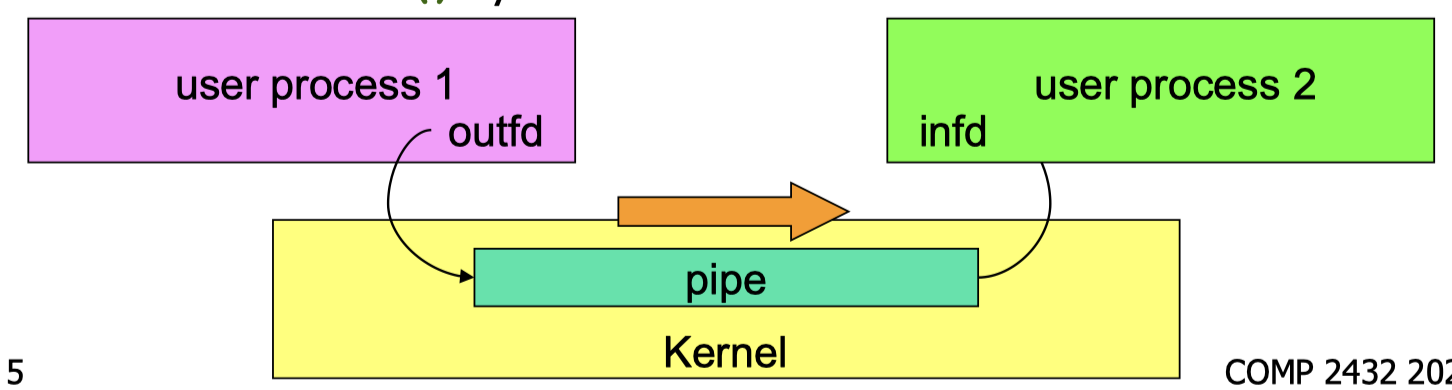
5.3 Unix/Linux Unnamed Pipe Programming
Created via system call pipe();
- A kernel buffer is allocated.
- Two file descriptors (fd) forming a 2-element array
- identify the read-end (keyboard) and write-end (screen) of the pipe.
fd[0]is for reading andfd[1]is for writing.- call
read(): read data from the pipe viafd[0]; - call
write(): write data to the pipe viafd[1].
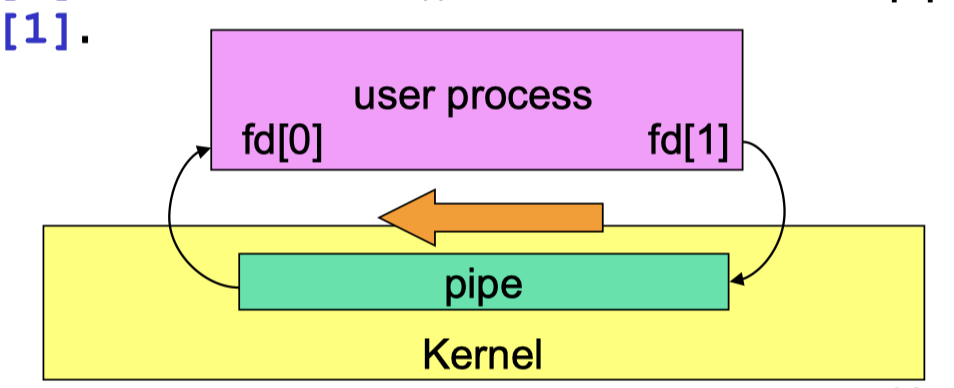
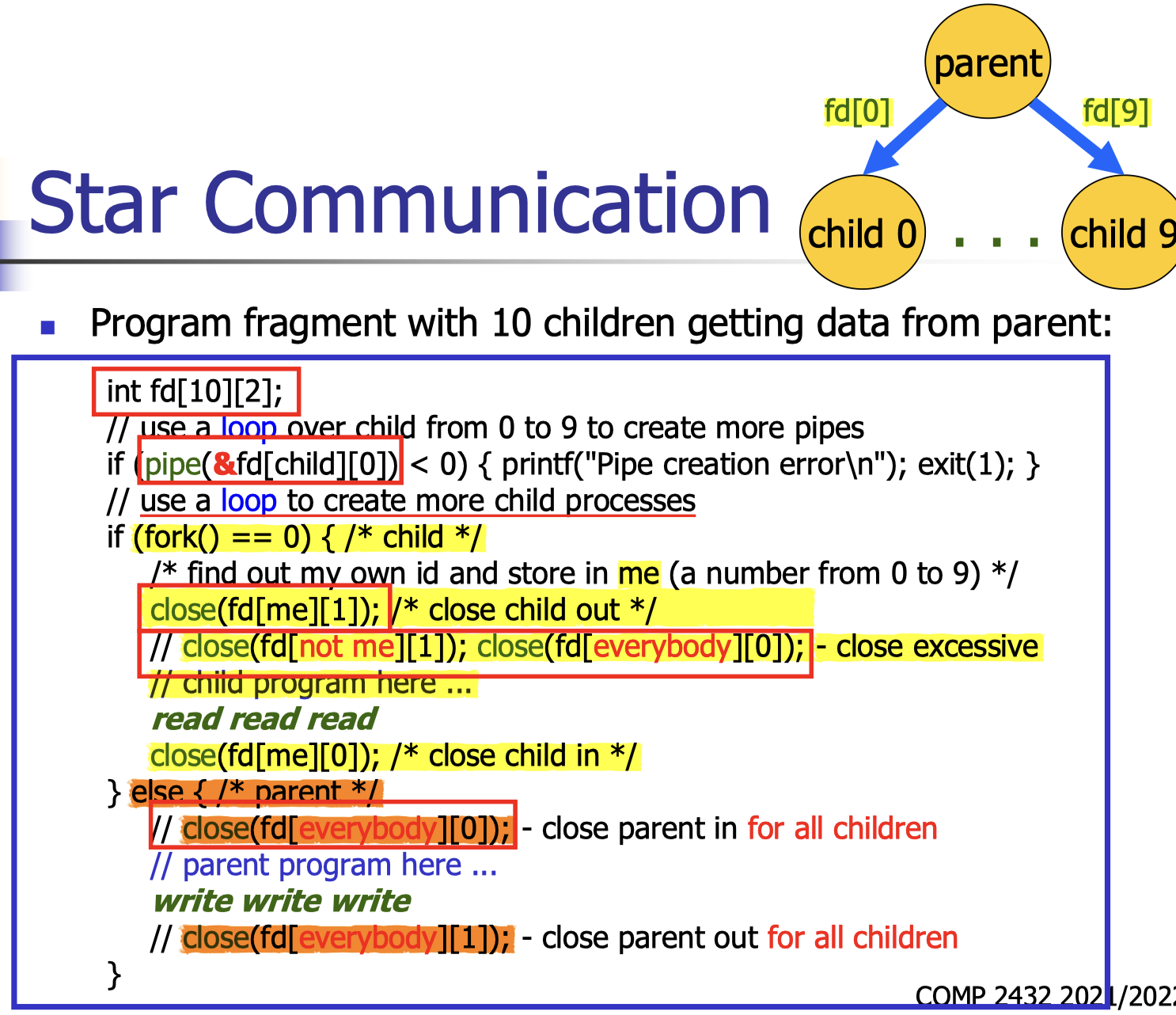
Program fragment:
- It sends data over the pipe to itself !!!
1 | |
A pipe should connect two processes
Child processes need to be created via system call fork() after the pipe is created.
fork()will make the child an exact copy of the parent.- pipe() first, then fork();
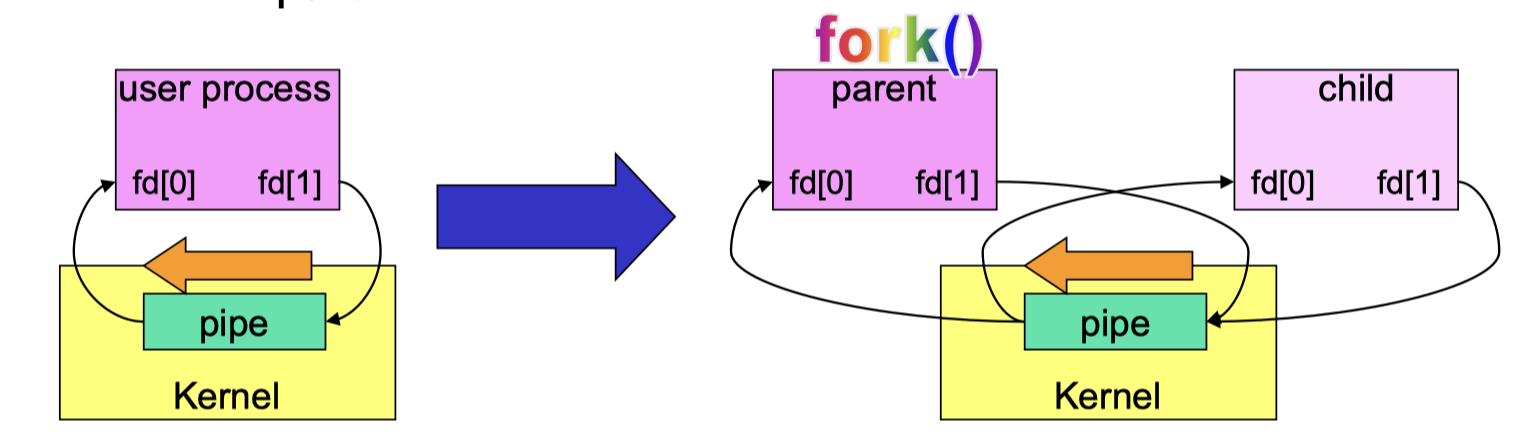
Now both child and parent can write to fd[1] and read from fd[0].
- There is just only ONE pipe, read from and write to the same pipe;
To avoid confusion, the unused ends of the fd[] must be closed.
- Closing the read end of parent and write end of child via system call close(), parent can write to child and child can read from parent, and not the other way round.
Program fragment with child getting data from parent:
Parent(write) -> Child(read)
1 | |
- Create array variable(s) to store fd[] for all the pipes.
1 | |
Program fragment with child sending data to parent:
Parent(read) <- Child(write)
1 | |
How can a parent talk to child and get data back from child (two-way)?
- Keep both pairs of pipes, one for parent to write to child as before, and one for child to write to parent as here.
- Communication can thus go in both direction, i.e. bi-directional communication.
Programming guidelines to reduce bugs:
- Draw a diagram for all the pipes between parent and children.
- Indicate the direction of data flow on each pipe.
- Create array variable(s) to store fd[] for all the pipes.
- Since parent will see all pipes, and children can see part or all of them, each process needs to close all unused ends in the diagram based on the fd[] variables.
In Unix/Linux:
- Shell programs implement the command level pipe (e.g. ls | wc) via a combination of fork() / pipe() / exec*().
fork()is used to create child processes to hold and execute the relevant commands, e.g. ls and wc.pipe()is used to create the pipe(s) to be shared between the processes, e.g. ls and wc.exec*()is used to replace the child processes with the programs, e.g. ls and wc.- Note that three child processes and two pipes will be created to execute a chained command like
prog1 | prog2 | prog3.
5.4 Communication Topology
Star topology
- Parent or coordinator talks to each individual child process.
- Simple to do, but bottleneck at parent.
- Very few pipes.
- At most 2 rounds of messages.
- For $n$ processes, need $2(n-1)$ pipes for both directions
- Bottleneck/single-point-of-failure at parent with $2(n-1)$ pipes
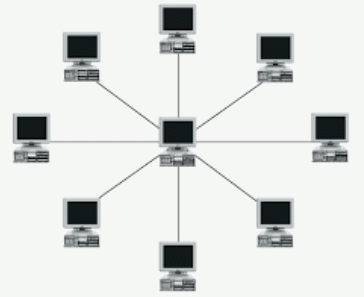
Program fragment with 10 children getting data from parent:
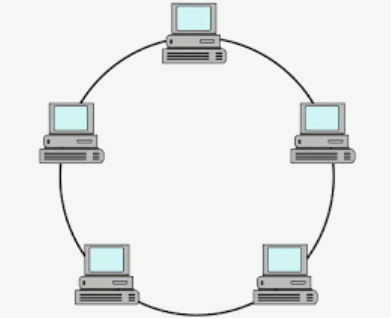
Ring topology
- Processes connected in a ring.
- Very few pipes.
- Quite many rounds of messages.
- One broken, still working;
- For $n$ processes, need $2n$ pipes
- No particular bottleneck
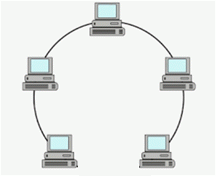
Linear topology
- Processes connected in a single line or chain.
- Very few pipes.
- Many rounds of messages.
- For $n$ processes, need $2(n-1)$ pipes
- Node failure will separate the communication.
Program fragment with parent/child/grand child getting data from parent:
Parent -> Child -> Grandchild

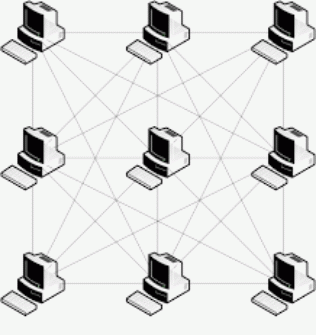
Fully connected
- Parent or child processes directly talk to one another.
- Need many pipes.
- Fast communication.
- For $n$ processes, need $n(n-1)$ pipes
- No bottleneck: everybody with $2(n-1)$
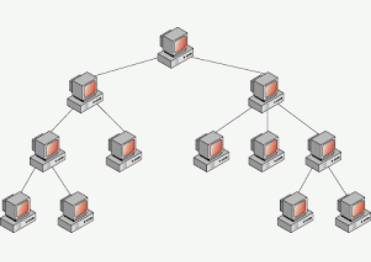
Tree topology
- Parent at each level of tree talks to its child process.
- Very few pipes.
- More rounds of messages.
- For $n$ processes, need $2(n-1)$ pipes
- Bottleneck spread around
Common version of the star and linear topology.
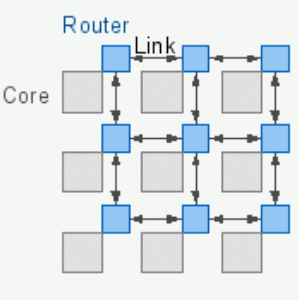
Mesh topology
- Links follow some structure, often grid-like.
- Fewer pipes than fully connected.
- Could be harder to program and maintain.
- Need routing for non-neighboring processes.
- Flexible.
- For $n$ processes, need between $2(n-1)$ and $n(n-1)$ pipes
- Each node is connected to around 4 neighbors
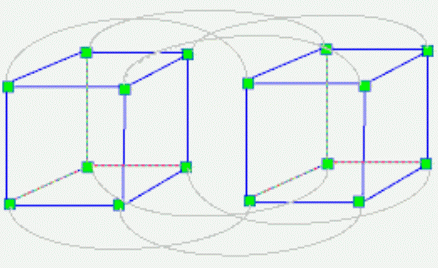
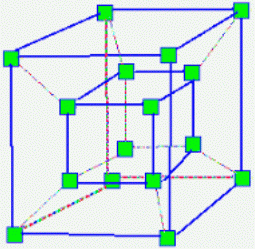
Hypercube topology
- Links follow a cube-structure.
- Fewer pipes than fully connected.
- Well-established routing mechanism for non-neighboring processes.
- Flexible.
- For $n$ processes, need between $2(n-1)$ and $n(n-1)$ pipes
- Each node is connected to $log_2n$ neighbors
Bus topology
- is not considered with pipes.
- Like Ethernet.
5.5 Unix/Linux Named Pipe Programming
Two different user processes in it.
- A named pipe is actually a file.
- created by creating a special file, via the system call
mkfifo();
- created by creating a special file, via the system call
- After a named pipe is created, any two processes knowing the name of the file will first
open()the pipe like a file.
- After a named pipe is created, any two processes knowing the name of the file will first
- They can then communicate by writing to and reading from it, using
write()andread()accordingly like a file.
- They can then communicate by writing to and reading from it, using
- The pipe remains even after both processes have completed.
- It is a good programming practice to create the named pipe and then delete the named pipe inside the program at the end, via
unlink()system call.
- It is a good programming practice to create the named pipe and then delete the named pipe inside the program at the end, via
Option1: Program fragments with P2 getting data from P1:
1 | |
P1:
1 | |
P2:
1 | |
- Option 1 is like socket programming in a network.
- The special file is replaced by an IP address (or a domain name) and a port number.
- Allows more than one user to run the program.
- Sometimes it is clumsy to develop two separate programs for communication.
- Note that there is no distinction between parent and child.
- could make use of the
fork()mechanism for the parent to create the child and run the two programs in one single shot.- We could also combine the two programs into one.
- Advantage: pipe is always created before use
Option2: Program fragments with P2 automatically executed:
1 | |
P1:
1 | |
P2:
1 | |
Option3: Program fragment with one single copy of code:
1 | |
P1:
1 | |
Named pipes could also be structured with topology.
- Given the potential larger naming space (on the names of pipes), it is less common to involve many processes.
- Managing named pipes with many processes is also tedious and error-prone, especially explicit creation and deletion are required.
Named pipes are not used often in Unix/Linux programming.
- Sockets are more common and more flexible.
Advantage of named pipe is often related to the support of heterogeneous programs, perhaps from different users.
Unnamed pipe is more secure than named pipe.
- every one can access the named pipe via file name;
- But the named pipe is easy for maintenance.
6. CPU Scheduling
- When the number of processes is more than number of CPUs, each CPU can only be allocated to a process for execution at each moment.
6.1 Scheduling
CPU scheduling:
- We are concerned about the decision of which process should get the CPU when the CPU is not in used.
CPU scheduler
- needs to maximize CPU utilization in the presence of multi-programming.
CPU burst
- is the consecutive amount of CPU time used by a process.
- time from need to leave the CPU
CPU scheduling decisions may take place when a process:
- Needs to wait for I/O or special events.
- Finishes execution.
- Gives up the CPU willingly or non-willingly.
- Completes its I/O or its special events happen.
The first two situations
- imply that current process can continue to hold CPU if it needs to (nonpreemptive, i.e. no forced taken of CPU).
The last two situations
- imply that there is a choice of taking CPU to give to a chosen process (preemptive, i.e. possibly forced taken of CPU).
1. Non-preemptive scheduling is easy to do.
- A process just uses the CPU until it wants to give it up when
- Terminated
- Waiting for I/O
- Execute a yield statement (in Java)
- No special hardware for timer interrupt is needed.
- Used in Windows 3.1 and old systems.
2. Preemptive scheduling is more complex.
- A process will be deprived of the CPU when its allocated time slice is used up or some other event happens.
- A form of timer interrupt must be used so that OS can take control when it is time.
- Used in most OS.
A scheduling algorithm
- is used by scheduler to determine which eligible process will be the next to get the CPU.
OS needs to:
- Perform context switching. store in the stack, go into the kernel mode.
- Switch to user mode.
- Jump to the proper location in the user program to resume that program.
dispatch latency:
- time taken by the OS to stop the current process and start another process for running
- a form of overhead, since CPU time is spent without doing real work.
6.1.1 Scheduling Consideration
CPU utilization
- Percentage of CPU time used for real work (non-idle).
- Want high CPU utilization.
- Smaller overhead
- For everyone, global view.
Throughput
- Number of processes completing execution per time unit.
- Want high throughput.
- For everyone, global view.
Turnaround time
- Amount of time to complete process execution since arrival.
- Want short turnaround time.
- For single, local view.
Waiting time
- Amount of time a process spends waiting in ready queue.
- Want short waiting time.
Response time
- Amount of time from the moment a request was submitted until the first response is produced (may not be output).
- Want short response time.
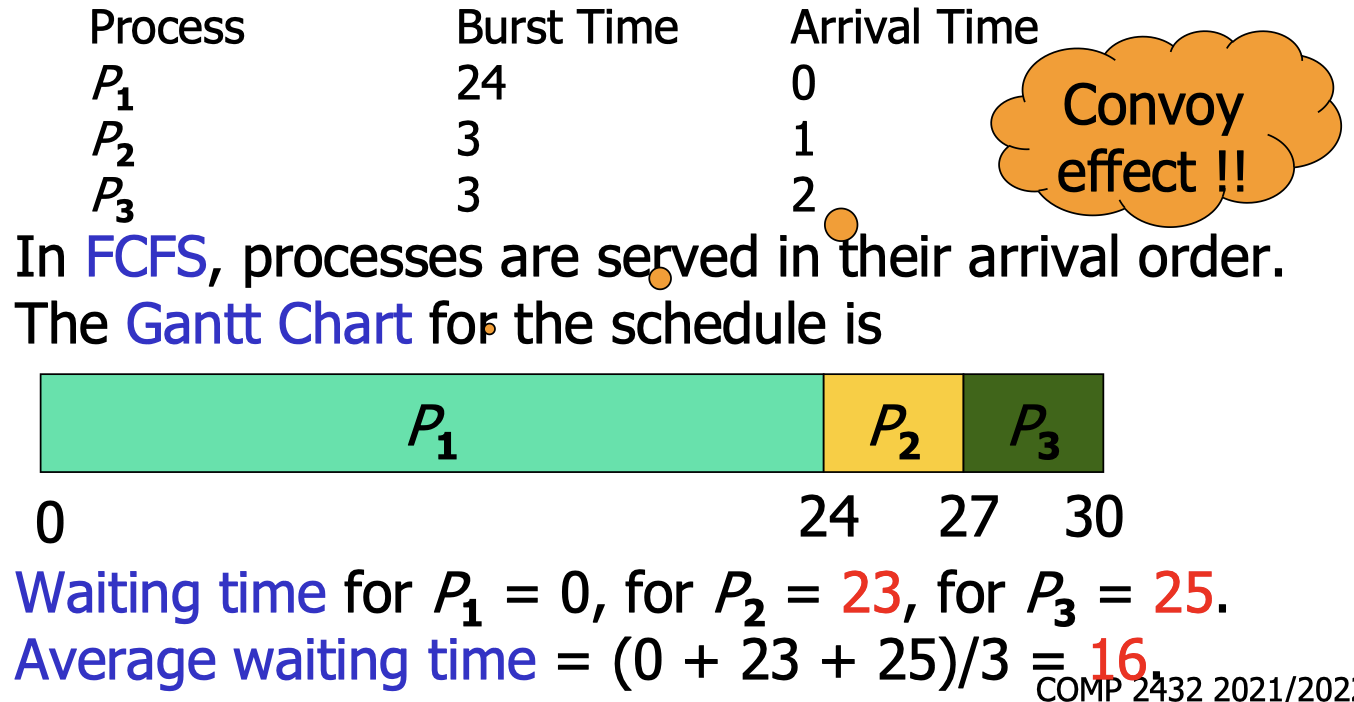
6.2 FCFS scheduling
To dry-run scheduling algorithms, we need information about the burst time (execution time) and the arrival time of processes.
- In FCFS, processes are served in their arrival order.
- Convoy effect happens when a single long process is blocking a number of processes.
Processes may arrive in around the same time.
- Often the process pid could reflect the real arrival order, since earlier process would normally receive a smaller pid.
- This is the case in Unix and Linux, but not for Windows.
6.3 SJF Scheduling
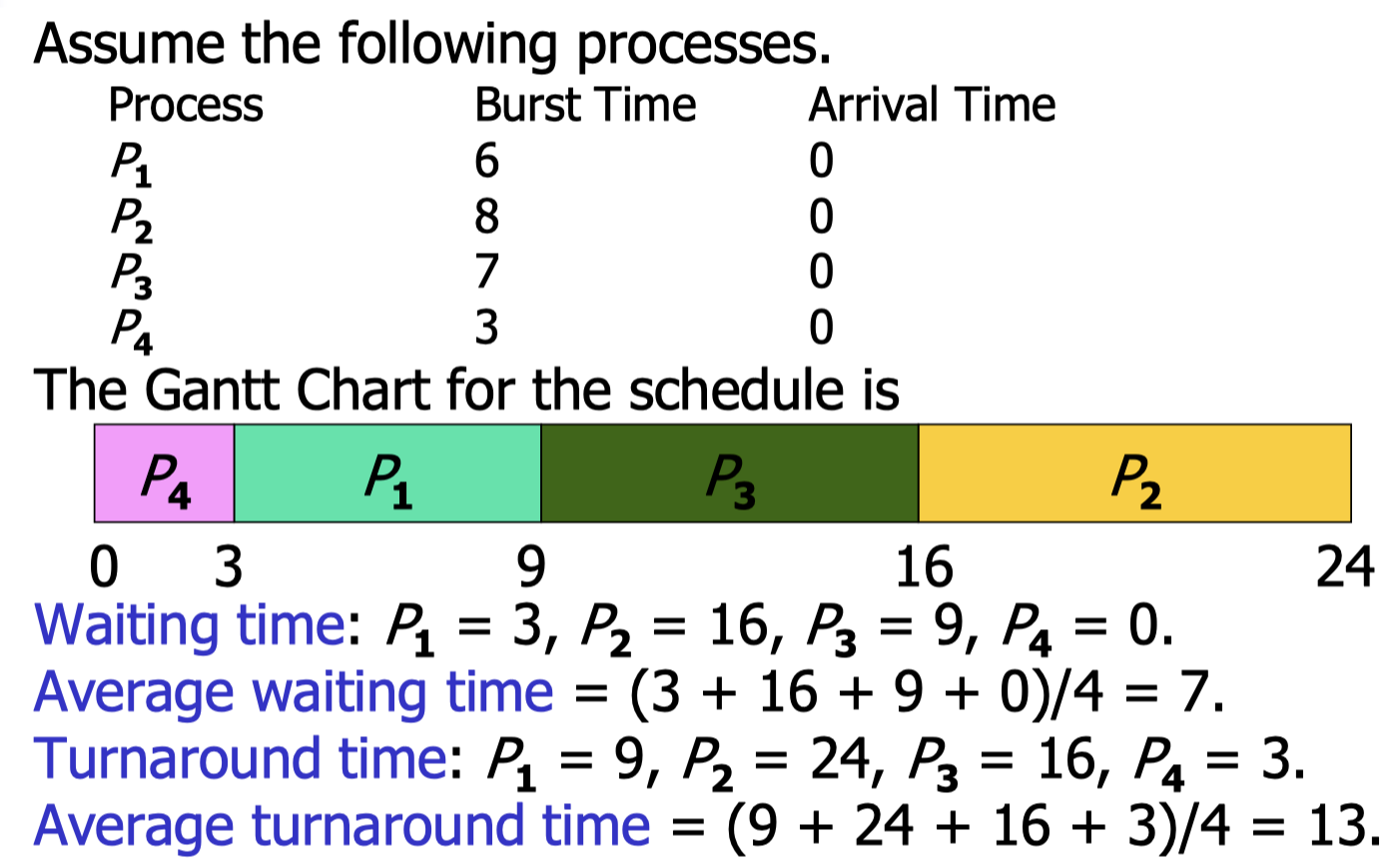
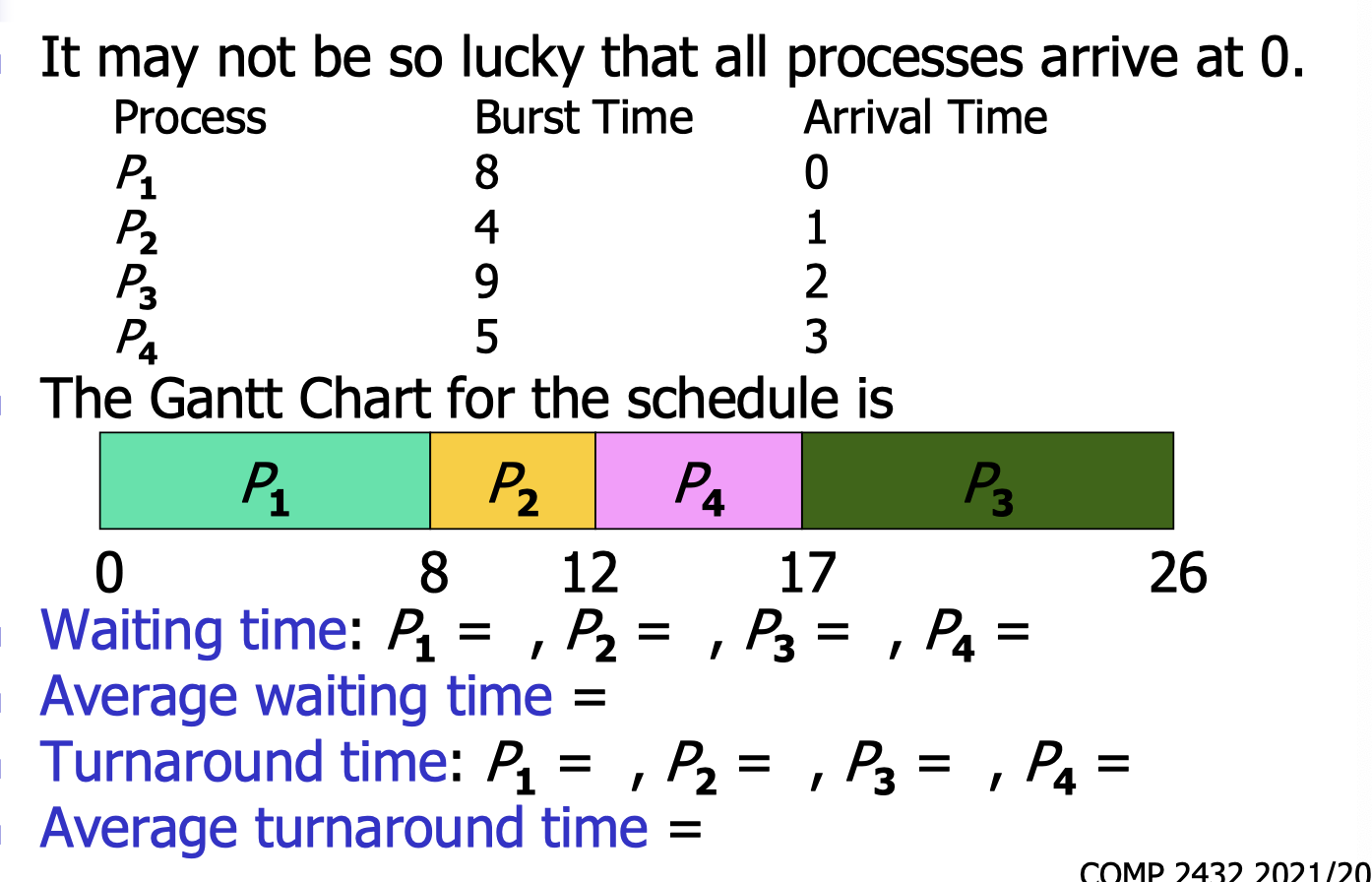
Shortest Job First (SJF) scheduling algorithm.
- To reduce the convoy effect, it is a good idea to let smaller jobs execute first.
- Smallest jobs will always be executed first.
- SJF produces the smallest average waiting time and smallest average turnaround time for a given set of processes.
6.4 SRT Scheduling
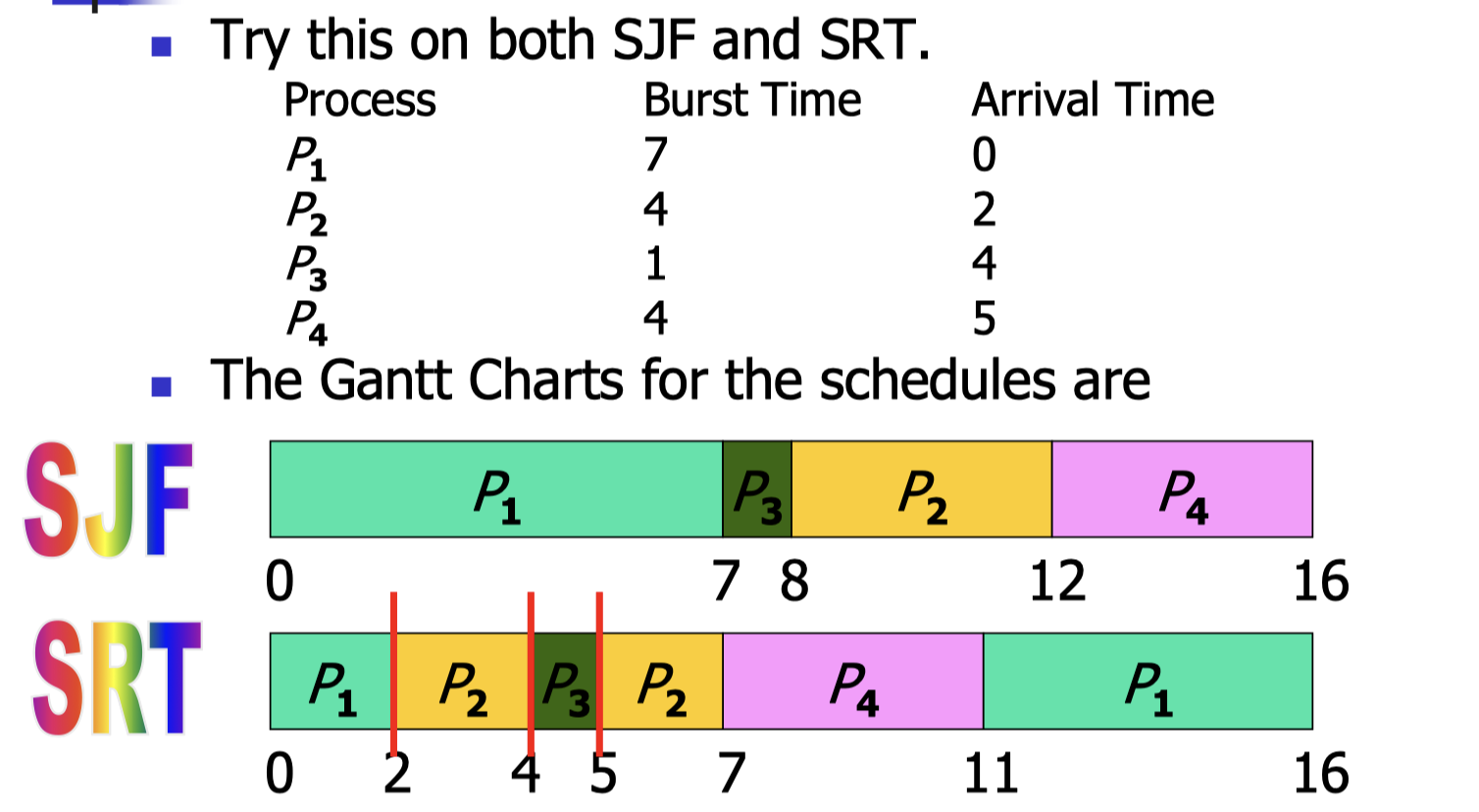
preemptive version of SJF is called Shortest Remaining Time (SRT).
- the remaining executing time of all existing processes are considered, and the one with the smallest remaining time (including the newly arriving one) will be executed.
- SRT always produces the smallest average waiting time and smallest average turnaround time for a given set of processes.
- We say that SRT is optimal (for preemptive scheduling).
- SJF is optimal for non-preemptive scheduling.

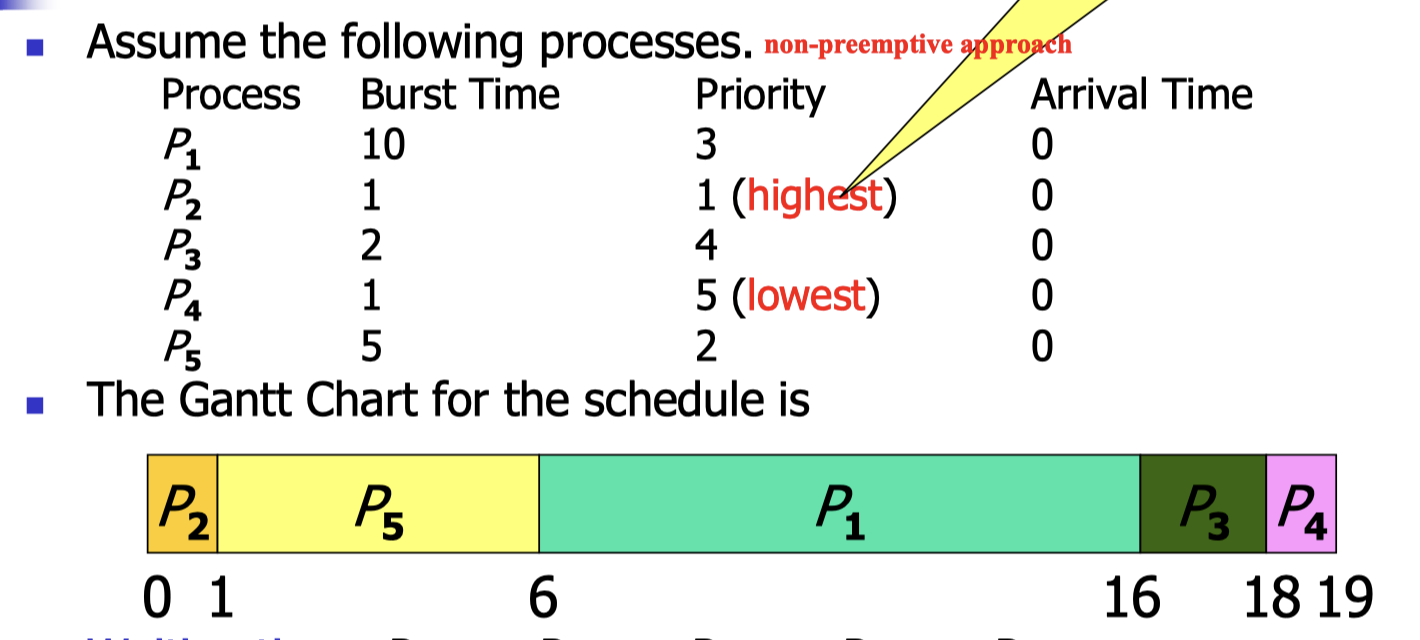
6.5 Priority Scheduling
A priority number is associated with each process.
CPU is allocated to the process with highest priority.
- In some systems, largest value in priority means highest priority (Windows), and in some others, smallest value means highest priority (Unix and Linux).
- Again, priority scheduling could be either non-preemptive or preemptive, but the preemptive version is more commonly in use.

SJF is a form of priority scheduling where the priority is CPU burst time (with smaller value meaning higher priority).
FCFS is a form of priority scheduling where the priority is process arrival time (with smaller value meaning higher priority).
- FCFS will not have the starvation problem, for later coming one always has lower priority.
Problem:
- low priority process may get no chance of execution, if there are higher priority processes that keep coming.
- starvation:
- The low priority process starves for the CPU that is repeatedly consumed by high priority processes.
SJF and SRT are special cases of priority scheduling, so they also suffer from the same starvation problem.
- The low priority process starves for the CPU that is repeatedly consumed by high priority processes.
- A long process would not get a chance of execution under SJF and SRT.
Solutions:
- Upgrade the priority of processes that wait for too long.
- Make a fairer usage of the CPU.
6.6 Round Robin Scheduling
We want a fair share of the CPU to everyone.
Round Robin (RR) scheduling:
- Each process gets a small unit of CPU time in turn.
- After this time has elapsed, the process is preempted and put back to the end of the ready queue.
- small unit of CPU time is called a time quantum, typically 10-100 milliseconds.
If there are n processes in the ready queue and the time quantum is q, then each process gets 1/n of the CPU time in blocks of at most q time units at once.
No process has to wait for more than the time it takes for each other process to use the CPU once, no more than q*(n-1) time units.
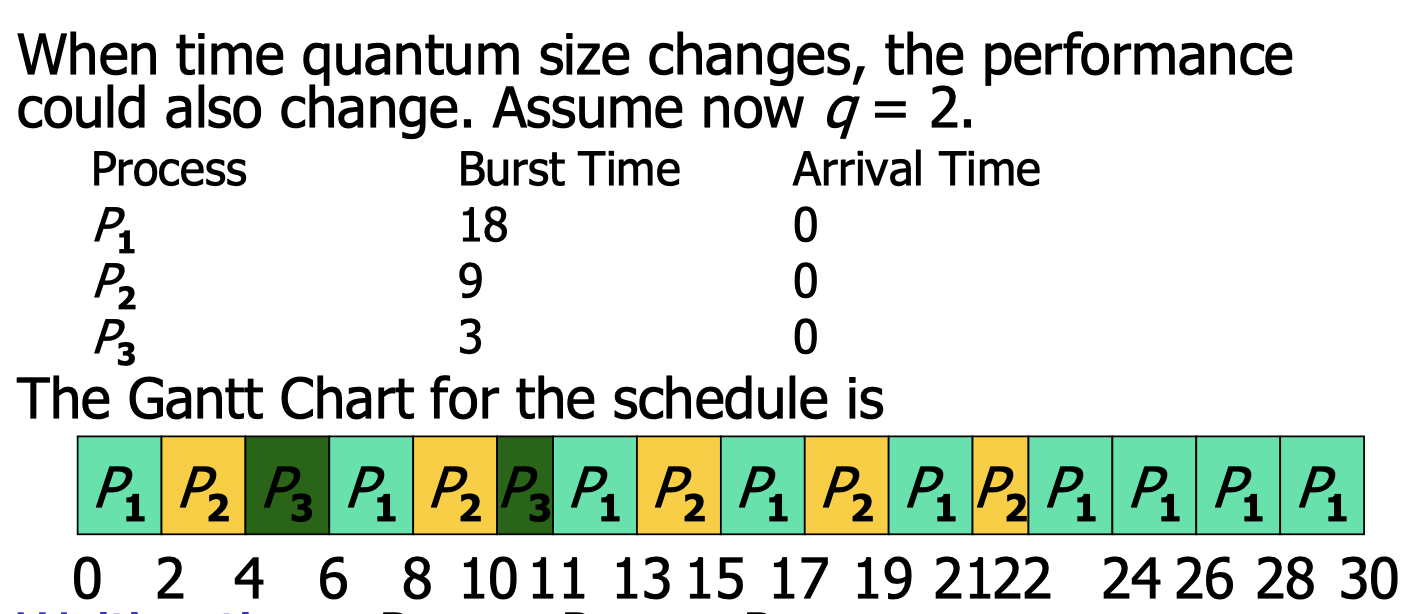
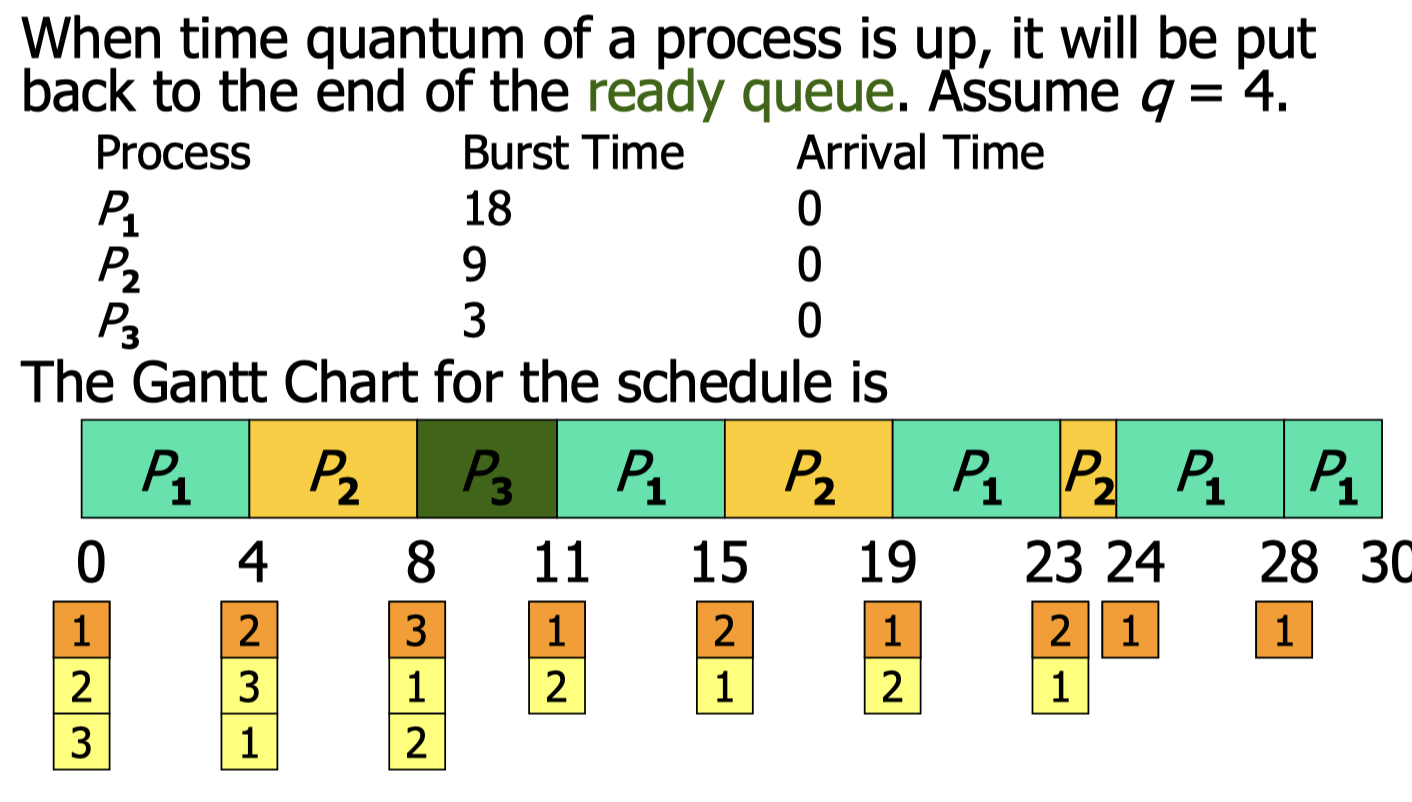
Performance
- Higher turnaround time, but better response time.
- q large then becomes close to FCFS.
- q small then context switching overhead will be very high.
6.7 Multi-Level Queue Scheduling
In Multi-Level Queue scheduling, the ready queue is partitioned into separate queues.
- In Multi-Level Queue scheduling, the ready queue is partitioned into separate queues.
- Each queue has its own scheduling algorithm.
- System (Priority), interactive (RR), batch (FCFS/SRT).
Fixed priority scheduling
- Each queue has a priority and high priority queues will be served before low priority queue.
- Possibility of starvation.
To solve it:
Time slicing
- Each queue gets a certain amount of CPU time for scheduling its own processes
- Example:
- Allocate 50% to system jobs
- Allocate 25% to interactive jobs
- Allocate 25% to batch/other jobs.
6.8 Multi-Level Feedback Queue
A process is allowed to move between the queues when there is a need.
A typical multi-level feedback queue scheduler is defined by the following parameters:
- Number of queues.
- Scheduling algorithms for each queue.
- Method used to determine when to upgrade a process to a higher priority queue.
- Method used to determine when to downgrade a process to a lower priority queue.
- Method used to determine which queue a process should enter when that process needs CPU.
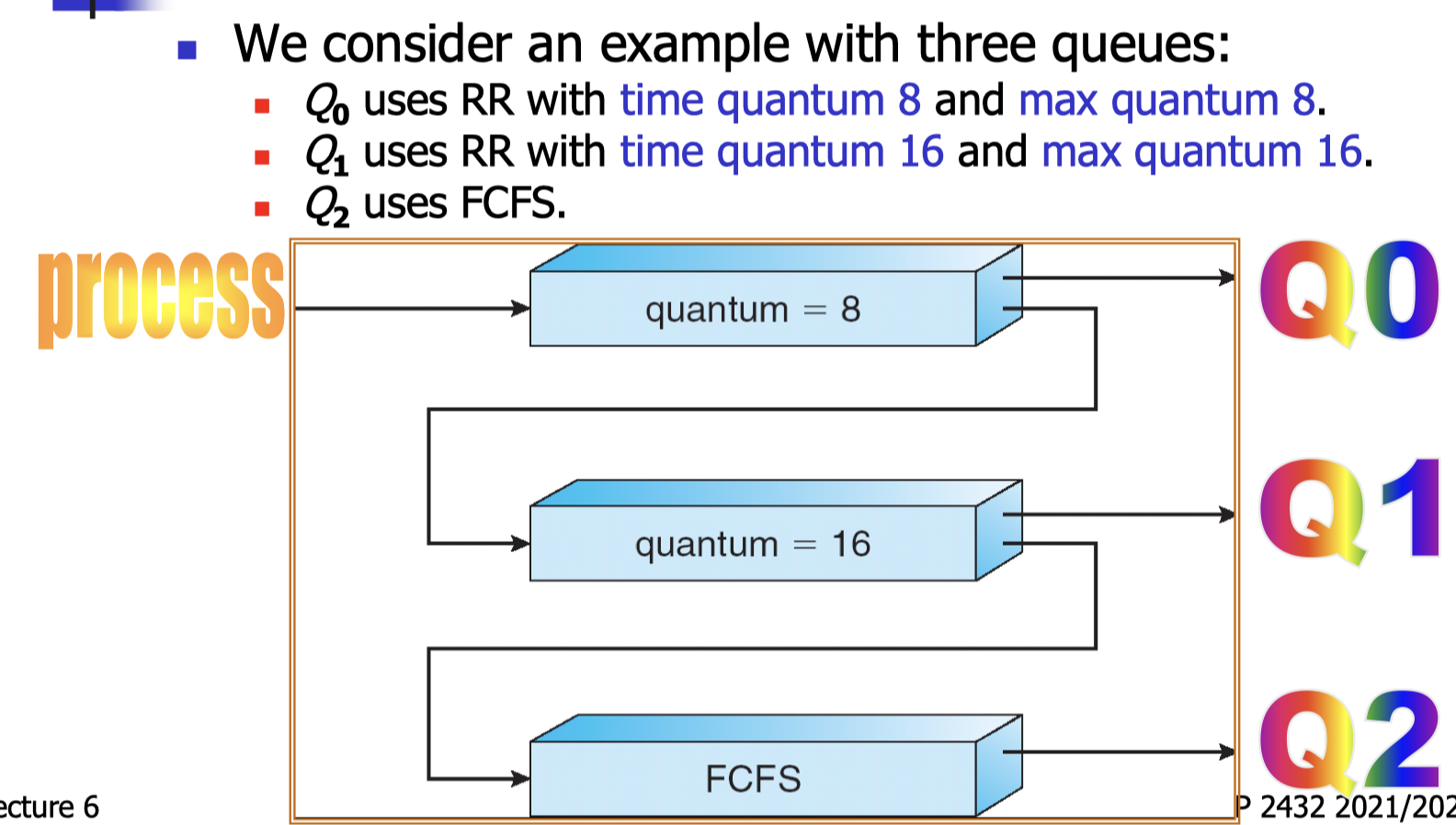
- Possibility of starvation.
- Solution: Time slicing
Scheduling for the example:
- A new job enters queue Q0 .
- When it is scheduled, it receives 8 ms of CPU time.
- If it does not finish in 8 ms, it is moved to queue Q1 .
- At Q1 , when it is scheduled, it receives 16 ms of CPU time.
- If it still does not complete, it is moved to queue Q2 .
- At Q2 , those “longer” jobs are served in FCFS order.
- At both Q 0 and Q1 , if a job waits for I/O before its time quantum expires, it will remain on the same queue.
- Q0 has the highest priority and Q 2 has the lowest priority.
- Fixed priority scheduling is used.
So I/O bound jobs remain in Q 0 and long batch jobs are downgraded to Q2 .
Short jobs get fast execution and good response.
7. Memory Management
7.1 Memory Management
A program must be brought from disk into main memory and loaded within a process for it to be run.
- Executable code (compiled) or source code (interpreted).
- Process is a program in execution.
Main memory/registers are storage that CPU can directly access.
- A register can be accessed in one CPU clock cycle.
- A main memory access can take many cycles.
- Cache sits between main memory and CPU registers to improve memory access time.
7.1.1 Address Binding to Memory
- Binding of address refers to the procedure of translating an address in the compiled program code to a memory address when the program is run.
- can happen at three different stages:
- Compile time
- If memory location is known ahead, absolute code can be generated.
- Code must be recompiled if starting location changes.
- cmd .com;
- efficient, but not flexible;
- Load time
- If memory location is not known at compile time, relocatable code must be generated.
- Addresses are defined after program is loaded.
- .exe;
- Execution or run time
- If a process can be moved during execution from one memory segment to another, binding must be delayed until run time.
- Hardware support for dynamic address mapping (e.g., base and limit registers) is required.
- flexible, but slow, not efficient.
- Compile time
- For each process, there is a pair of
baseandlimitregisters that define the address space of the process.- An address generated should stay between
baseandbase+limit. - Access to an address beyond the allocated address space is invalid.
- This protects a process from accessing the content of another process.
- An address generated should stay between
7.1.2 Logical and Physical Address
- Memory management technique is required to support run-time address-binding. This is because a program may move around during execution.
The key idea behind memory management is the separation of logical address and physical address.
- Logical address is the address generated by the CPU, e.g. an instruction refers to an integer stored at a particular address. This is also called a virtual address when it is different from the physical address.
- Physical address is the address sent to the main memory.
The logical and physical addresses are the same in both compile-time and load-time address-binding schemes, but differ in run-time address-binding scheme.
7.1.3 Memory Management Unit
The hardware device that maps virtual to physical address is called the memory management unit or MMU.
- In the simplest MMU solution, the value in a special relocation register is added to every logical address generated by a user process to form the physical address when it is sent to memory.
User process only deals with logical addresses. It never sees the real physical addresses.
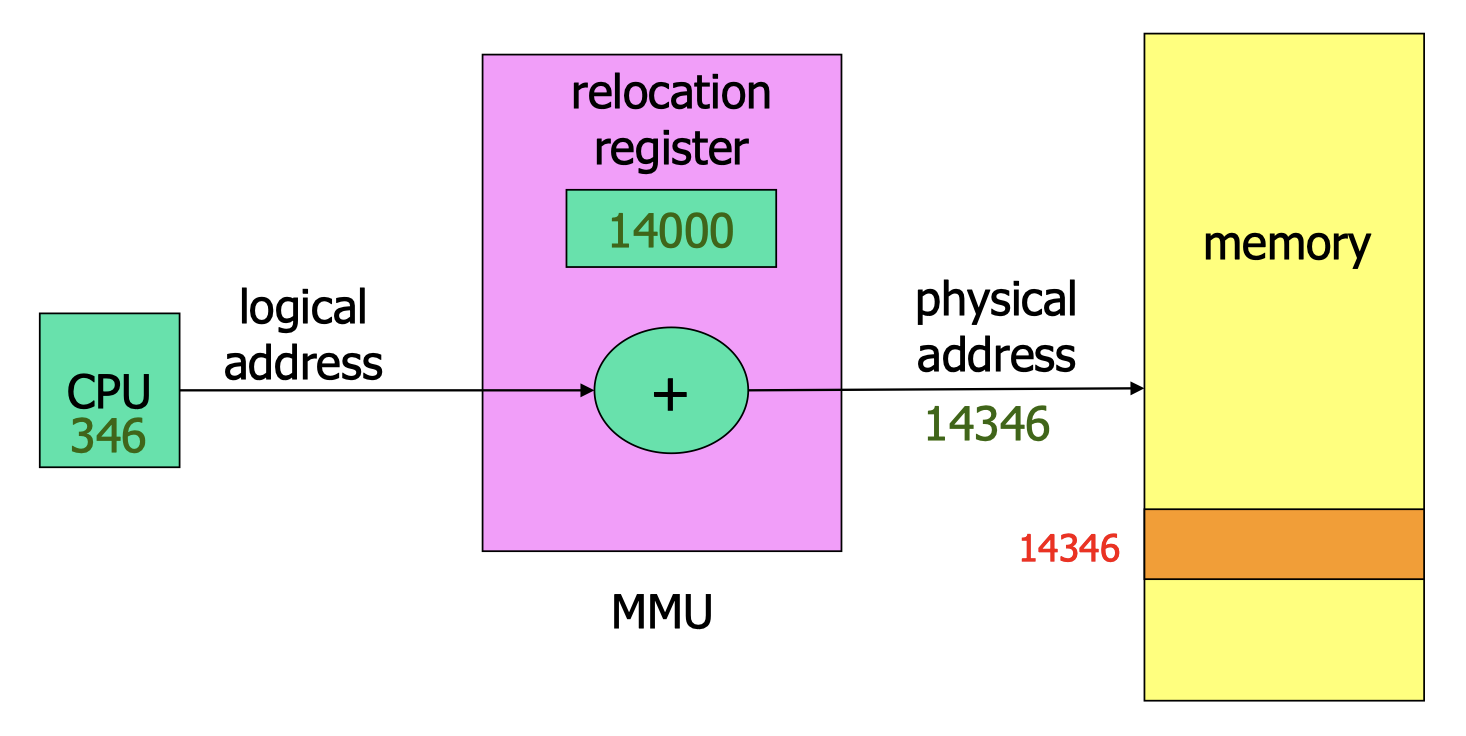
7.1.4 Memory Allocation
Main memory is usually divided into two partitions.
- Resident OS is usually stored in low memory, together with interrupt vector and interrupt handlers.
- User processes are stored in high memory.
Memory allocation is concerned with where a user process is actually placed when it is swapped/moved into main memory.
Two types:
- Contiguous allocation: allocate a single block of memory of size sufficient to hold the process.
- Non-contiguous allocation: chop up the process and allocate multiple blocks of memory to hold the process.
- The two major schemes are paging and segmentation.
7.2 Contiguous Memory Allocation
The most straightforward solution is to allocate a single block of memory to hold a process.
- One single block to hold one process (single partition).
- Multiple blocks to hold multiple processes (multiple partition).
A pair of registers are used to protect user processes from accidentally stepping into each other and changing operating system code and data.
- The relocation register(base resister) contains the value of smallest physical address for the process.
- The limit register contains the range (size) of logical address space.
- Each logical address must be less than(can NOT be equal) the limit register.
- MMU maps logical address dynamically into physical address by adding it to the relocation register.
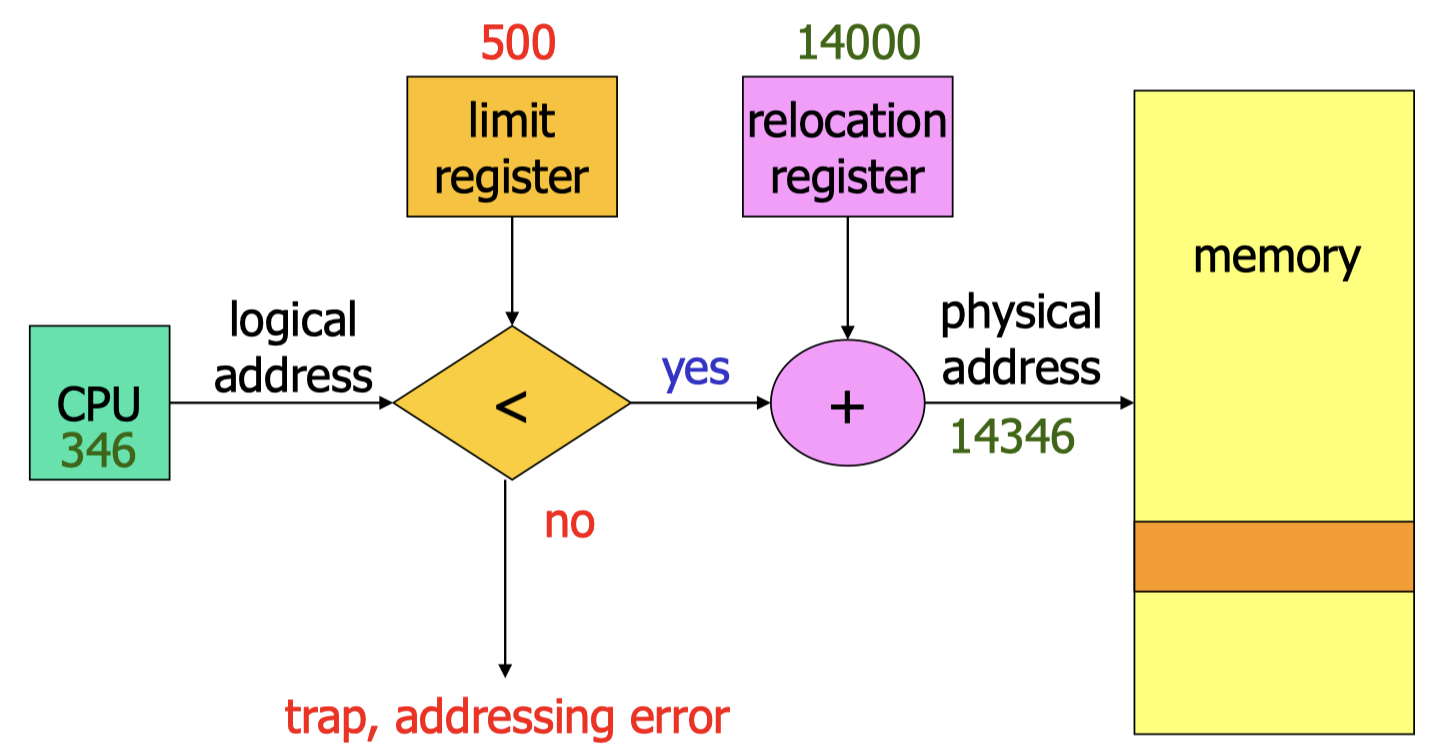
7.2.1 Multiple Fixed Partition
Called MFT: Multiprogramming with a Fixed number of Tasks.
- Divide the memory into several partitions.
- When a partition is free, a job is selected to be loaded into the partition.
- Only at most n jobs can be executed if there are n partitions.
- Very simple to manage.
- Not effective if there are many small jobs since many partitions are only used to very small degree and total free memory is still quite large.
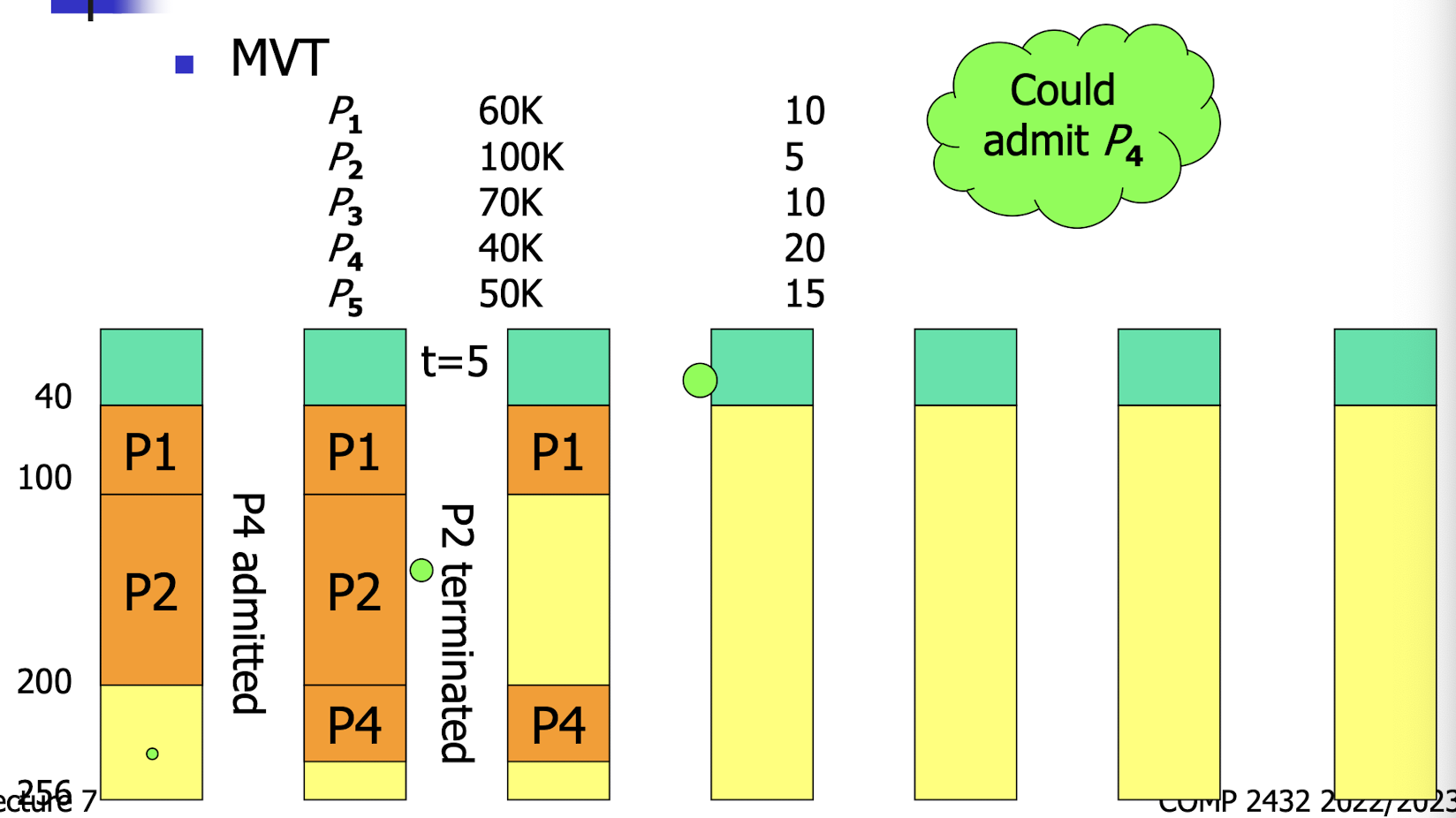
7.2.2 Multiple Variable Partition
Called MVT: Multiprogramming with a Variable number of Tasks.
- A block of available memory is called a hole.
- Holes of various size are scattered throughout the memory.
- When a process arrives, it is allocated memory from a hole large enough to accommodate it.
- OS maintains information about allocated partitions and free partitions (i.e. holes), often in the form of linked lists.
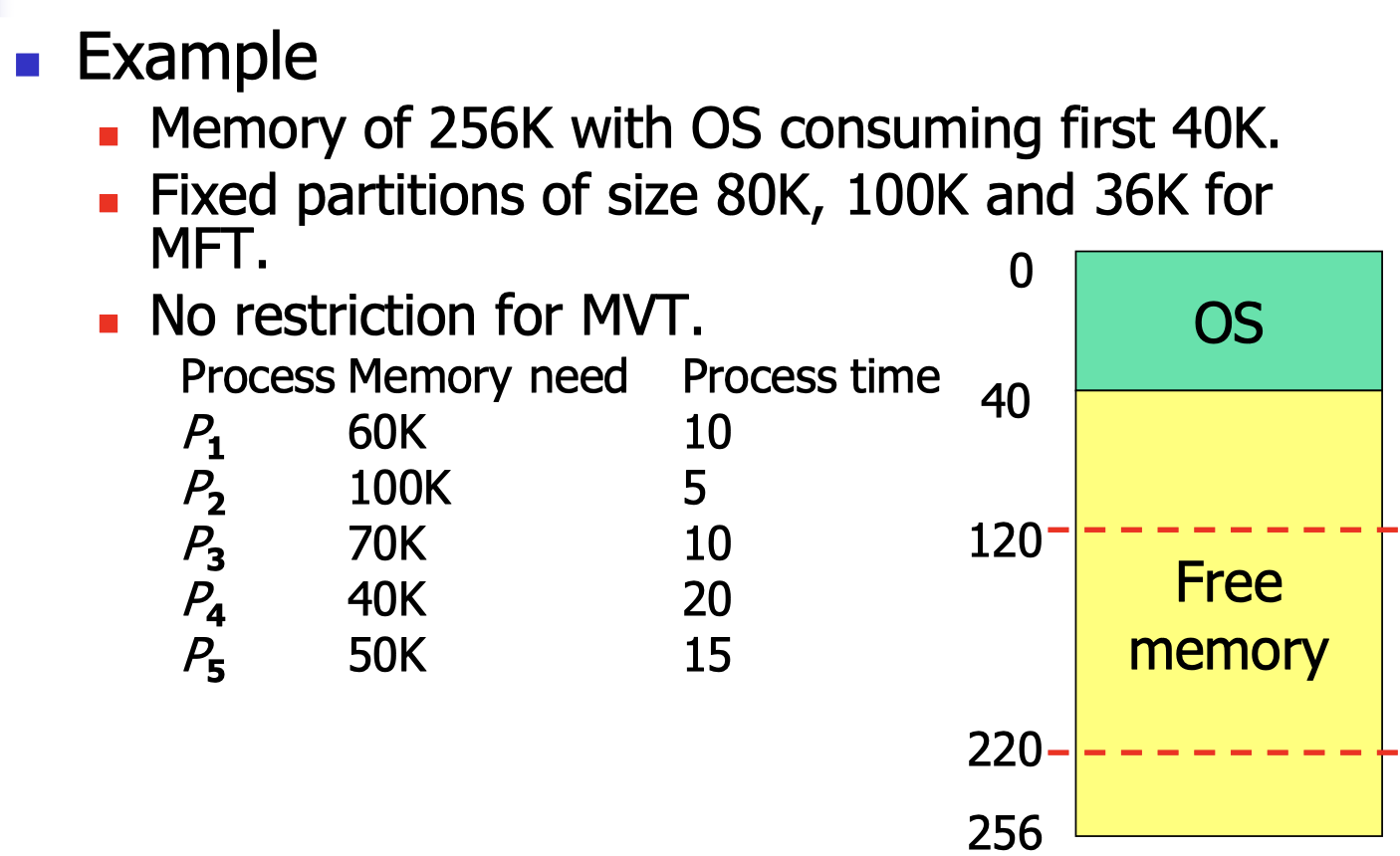
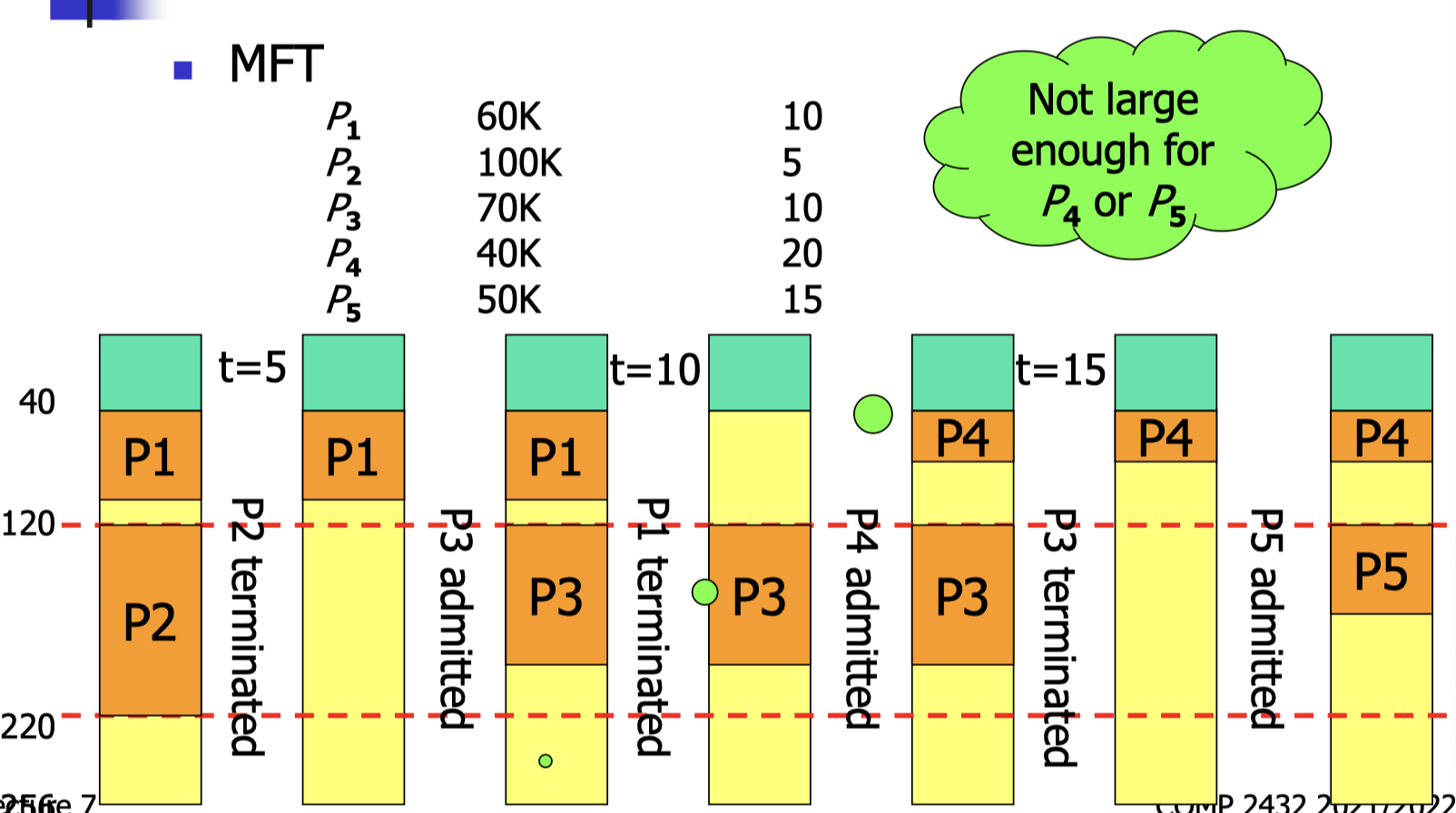
7.2.3 Allocation Algorithms
- First-fit: allocate the first hole that is big enough.
- Best-fit: allocate the smallest hole that is big enough.
- Produce the smallest leftover hole.
- Do not waste large holes for future large job.
- Worst-fit: allocate the largest hole.
- Produce the largest leftover hole.
- Ensure that leftover holes are large enough to be useful.
Best- and worst-fit need to maintain a sorted list for sizes of holes or a search is needed.
First- and best-fit are normally performing better than worst-fit.

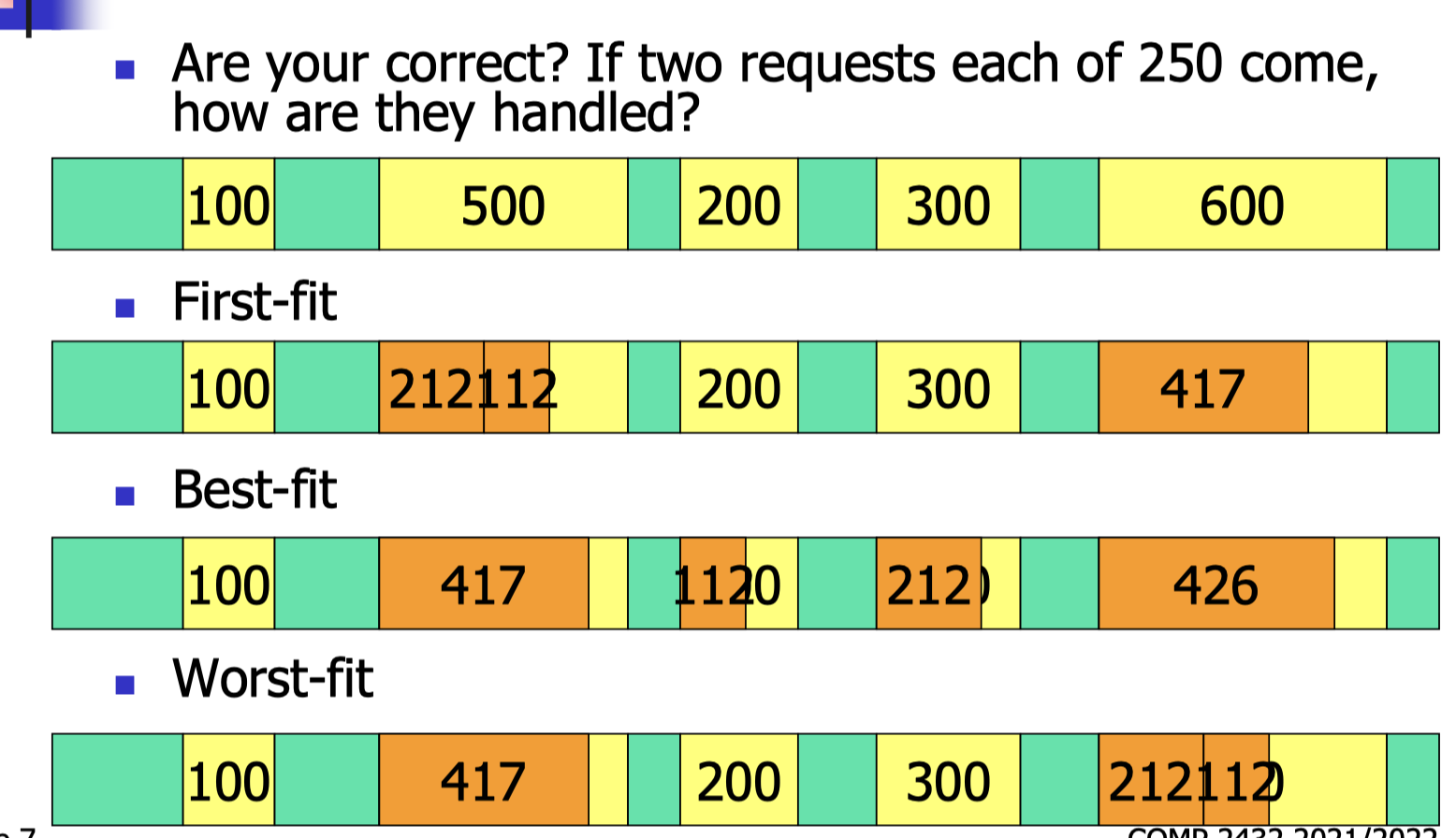
7.2.4 Fragmentation Problem
Fragmentation means that memory is available, but somehow could not be used.
External Fragmentation
- Total memory space exists to satisfy a request but it is not contiguous that it could not be used.
- It is a wastage outside partition.
Internal Fragmentation
- with the wall;
- Memory internal to partition is not used (wastage inside partition).
- This happens when a hole is slightly larger than requested size that the overhead to manage the small hole is not justified.
Reduce external fragmentation by compaction.
- Move memory content around to place all small free memory holes together to create one large block or hole.
- Compaction is possible only if relocation is dynamic.
7.3 Paging Non-contiguous Allocation
In memory allocation, the best candidate to serve as a container is the page.
- A page is a size of physical memory manipulated as a unit.
- It often corresponds to a block in the hard disk.
Non-contiguous allocation:
- When memory is divided up into pages, it is no longer necessary that consecutive pages be allocated for a process.
7.3.1 Paging
frames: In paging mechanism, physical memory is divided into fixed sized blocks called frames.
- The size of a frame is always power of 2 (normally between 512 bytes and 8,192 bytes).
pages: Logical memory is divided into blocks of same size as frames, called pages.
- To run a program of size of n pages, allocate n free frames in memory and load the program into those frames.
- Since the frames are scattered around, a page table is used to translate logical address to physical address.
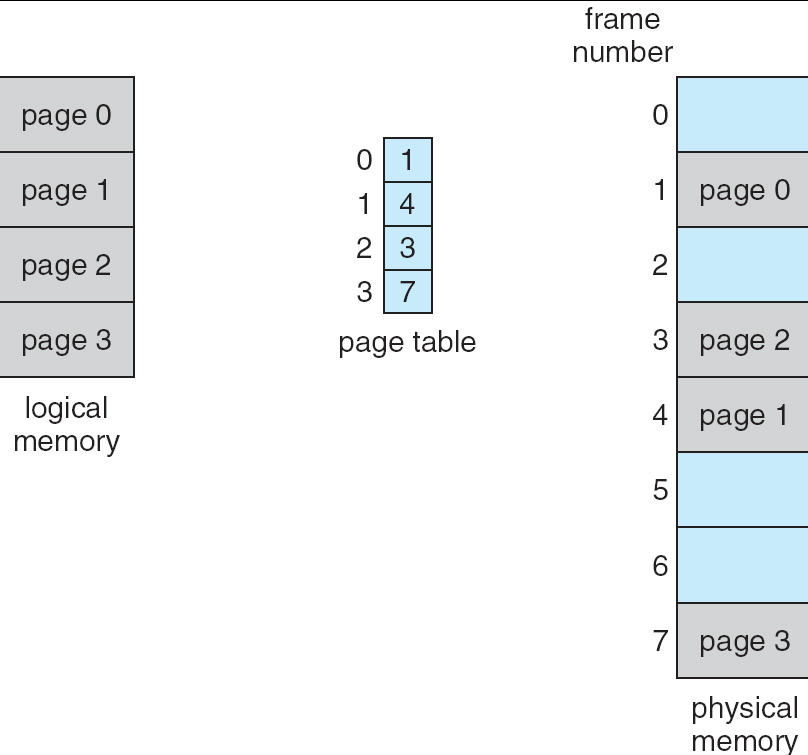
The logical address is divided into two parts.
- Page number (p): it is used as an index into a page table to look up for base address of each frame in physical memory.
- Page offset (d): it is added (or appended) to the base address to form the physical memory address.
Assume that the logical address space is of size $2^m$ and each page (and frame) has a size of $2^n$.
- Logical address has a size of $m$ bits.
- Page number $p$ contains $m-n$ bits.
- Page offset $d$ contains $n$ bits.
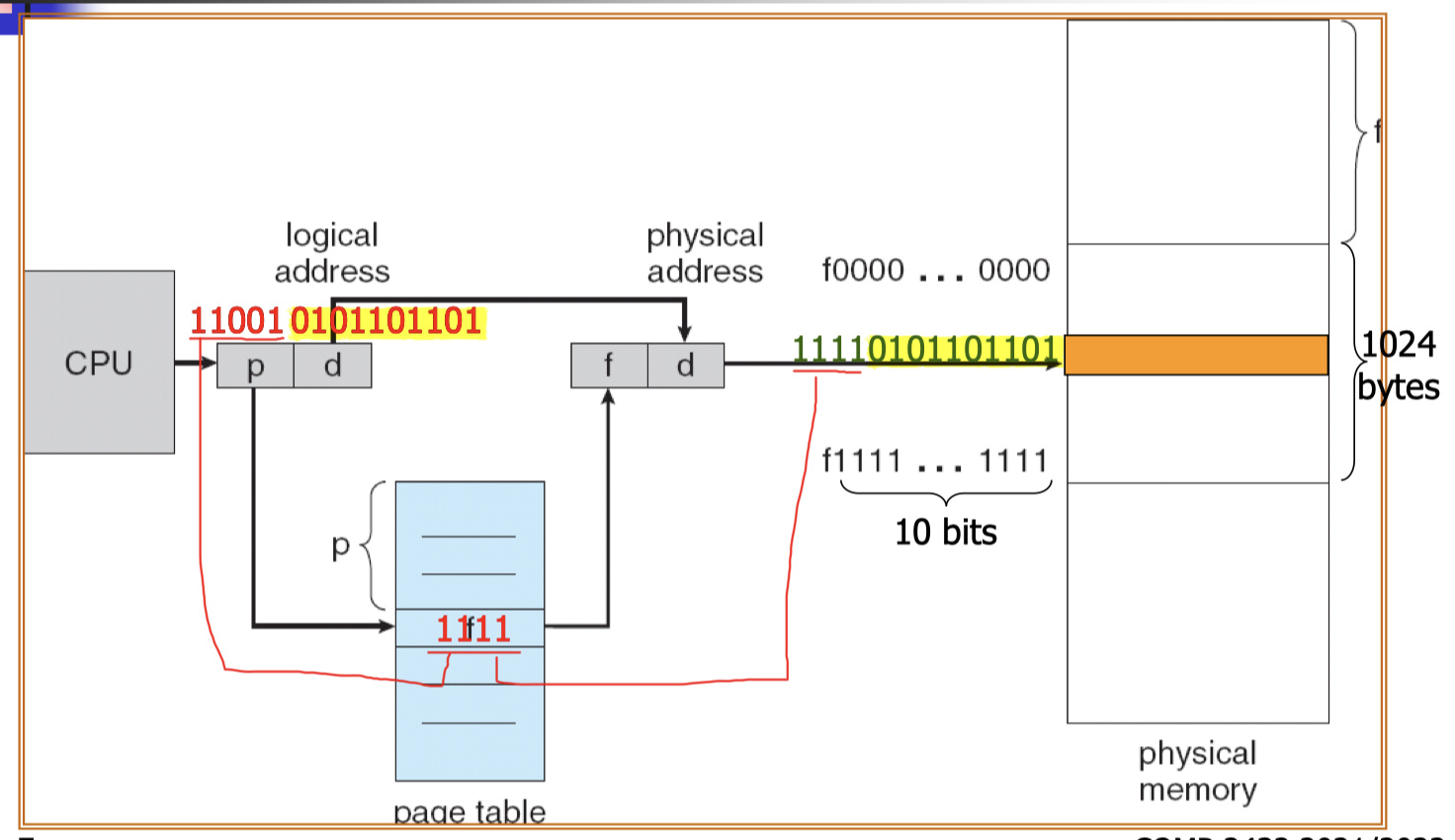
7.3.2 Page Table Implementation
The page table is the key for translation from logical to physical address for a process.
- There is one page table for each process and it is kept in the main memory.
- A hardware register, called page-table base register (PTBR), points to the page table for a process.
- Every data/instruction access requires two memory accesses: one for page table and one for data / instruction.
- This extra memory access to page table is expensive.
- This is solved by a hardware cache called Translation Lookaside Buffer (TLB) to store recently translated logical page numbers.
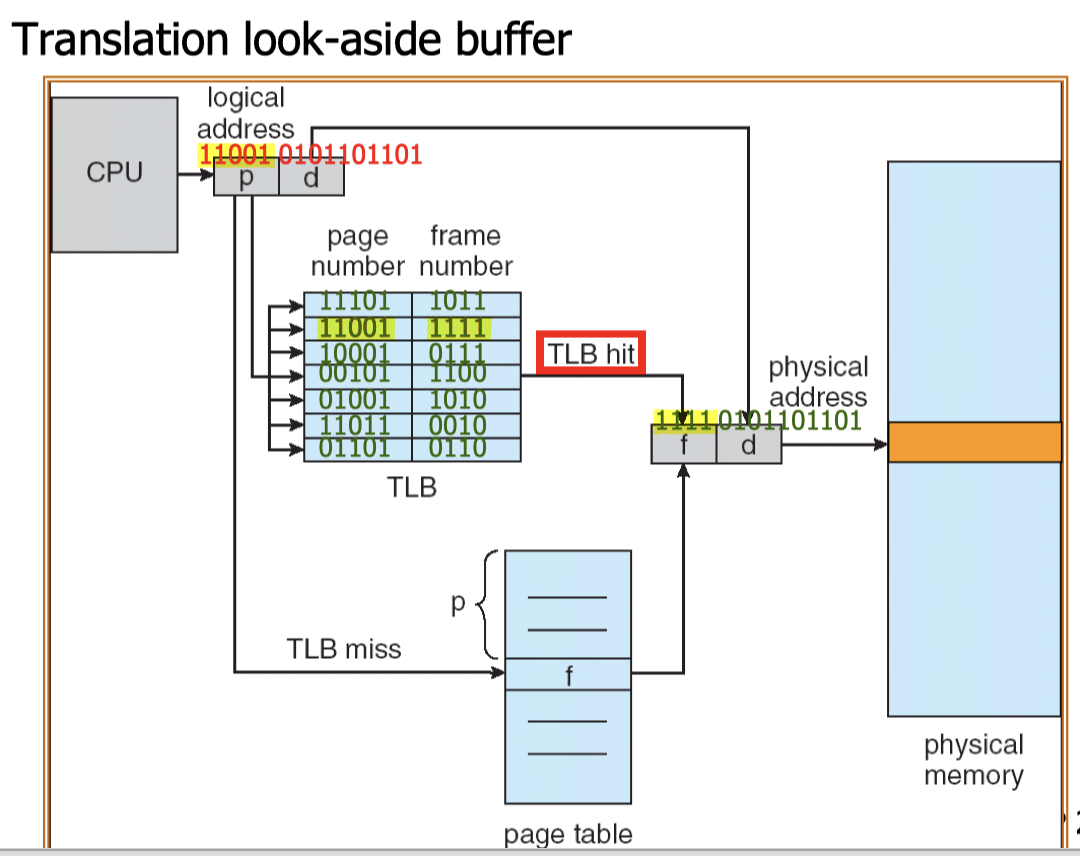
Translation Look-aside Buffer (TLB) is made up of high-speed associative memory (a form of cache) that allows concurrent search for a tag.
- The drawback is that the hardware cost is high.
TLB is inserted between the translation path from a page number to a frame number. The tag is the page number p, and the value is the frame number f.
- We first look up the TLB to for the existence of p and return the value of f. If that is successful, we call it a TLB hit.
- Otherwise, that is a TLB miss. We will look up the page table indexed by p to get f.
Example:
- For a TLB hit, the data access cost is only $1+c$, where c is the cost of cache access and $c<<1$.
- For a TLB miss, the data access cost is $2+c$. After the miss, the new pair (p,f) will be inserted into TLB for future use.
- Without TLB, data access cost is 2.

Example:


7.3.3 Hierarchical Paging
We could not store this large page table in consecutive block of memory, so we need to find a way to handle this table.
Three possible solutions:
- Hierarchical paging
- Hashed page table
- Inverted page table
Break up page table to be stored into multiple pages.
- In other words, break up logical address space into multiple page tables.
A logical address (on 32-bit machine with 4KB page size) is divided into:
- a page number consisting of 20 bits.
- a page offset consisting of 12 bits.
Page table is itself paged, page number is further divided into:
- a 10-bit second level page number.
- a 10-bit second level page offset.
We call the second level page table the outer page table.
- You could have a second outer page table if needed.
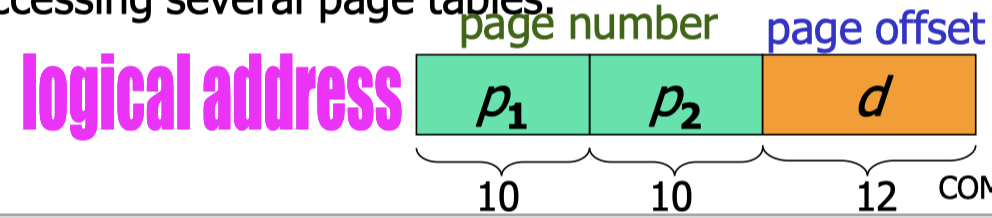
- Here $p_1$ is an index into the outer page table and $p_2$ is the displacement within the page of the outer page table.
7.3.4 Memory Protection
A program may not use up all pages in page table. Some pages in may be read-only (e.g. program text).
Memory protection is implemented by associating one or more protection bits with each page, e.g., we may attach a valid-invalid bit to each page table entry:
- “valid” indicates that the associated page is in process’ logical address space and is a legal page.
- “invalid” indicates that the page is not in logical address space. Accessing it will generate a trap to OS.
A hardware page-table length register (PTLR) is often used to check for validity of a logical address.
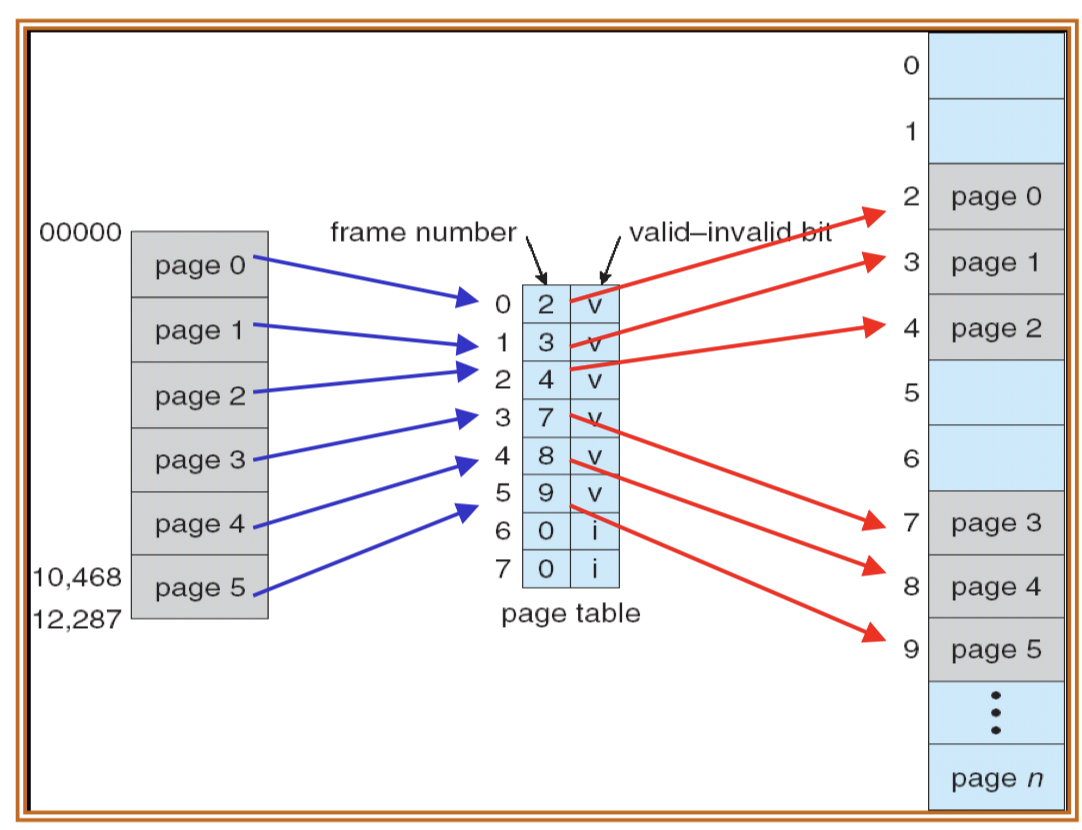
7.3.5 Shared Pages
Use of paging allows easy sharing of program code with private data.
- One copy of read-only code is shared among processes (e.g. editor).
- Each process keeps a separate copy of its private data.
- Private data can appear anywhere in the logical address space of a process.
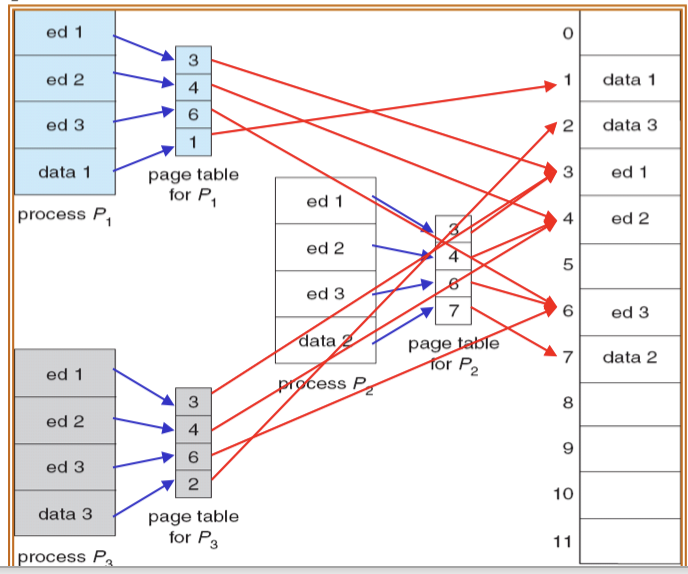
- Only 6 pages are needed instead of 12 pages.
7.4 Paging Implementation Segmentation
Users do not see pages, but they see segments for their programs.
A program consists of a collection of segments.
- A segment is a logical unit
- such as main program, procedures, functions, methods, objects, local variables, global variables, common block, stack, library, symbol table.
- Segmentation is the memory management scheme that supports user view of memory with segments.
- Segments are given segment numbers.
- Each segment is mapped to specific part of physical memory via segment table.
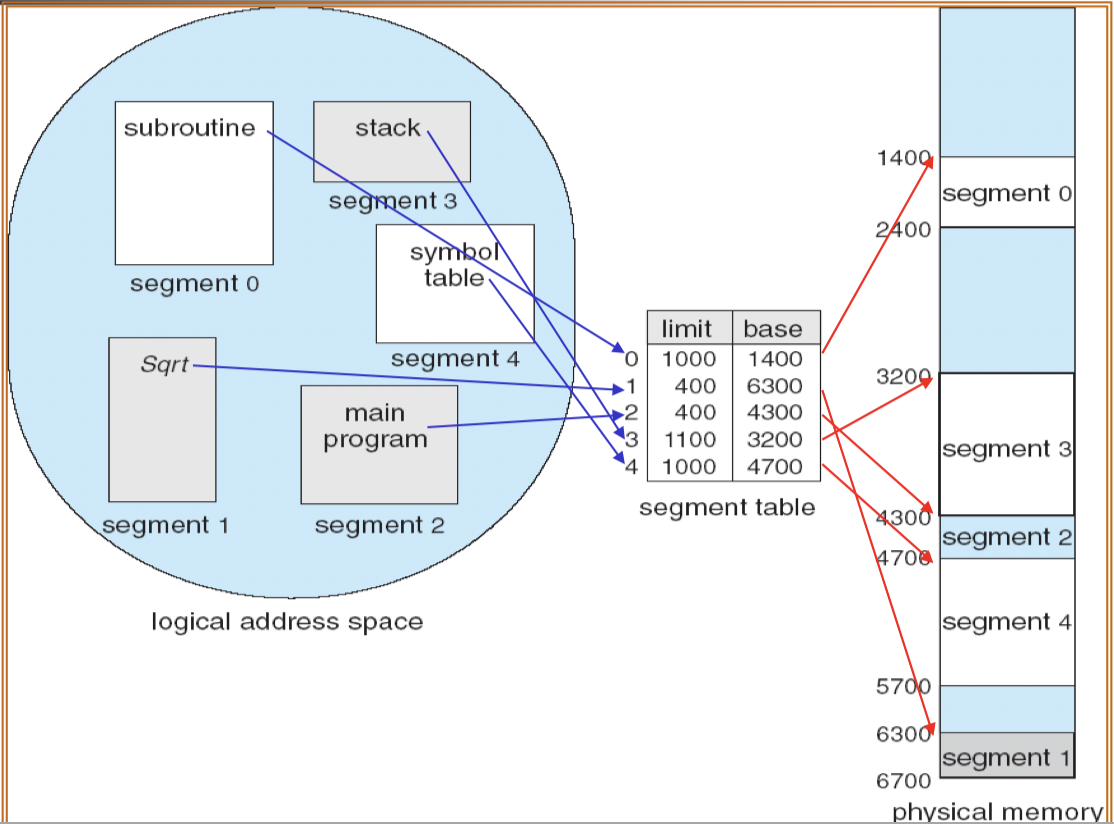
- Logical address has two parts:
- [segment-number, offset]
- Segment table maps logical into physical addresses.
- Each segment table entry has
- Base: contains segment starting physical address in memory.
- Limit: specifies length of the segment.
- Each segment table entry has also valid bit and access privilege bits for protection.
- Since segments vary in length, memory allocation is similar to contiguous dynamic storage-allocation problem. Segmentation suffers from external fragmentation.
- Segment-table base register (STBR) points to the segment table’s location in memory.
- Segment-table length register (STLR) indicates the number of segments used by a program.
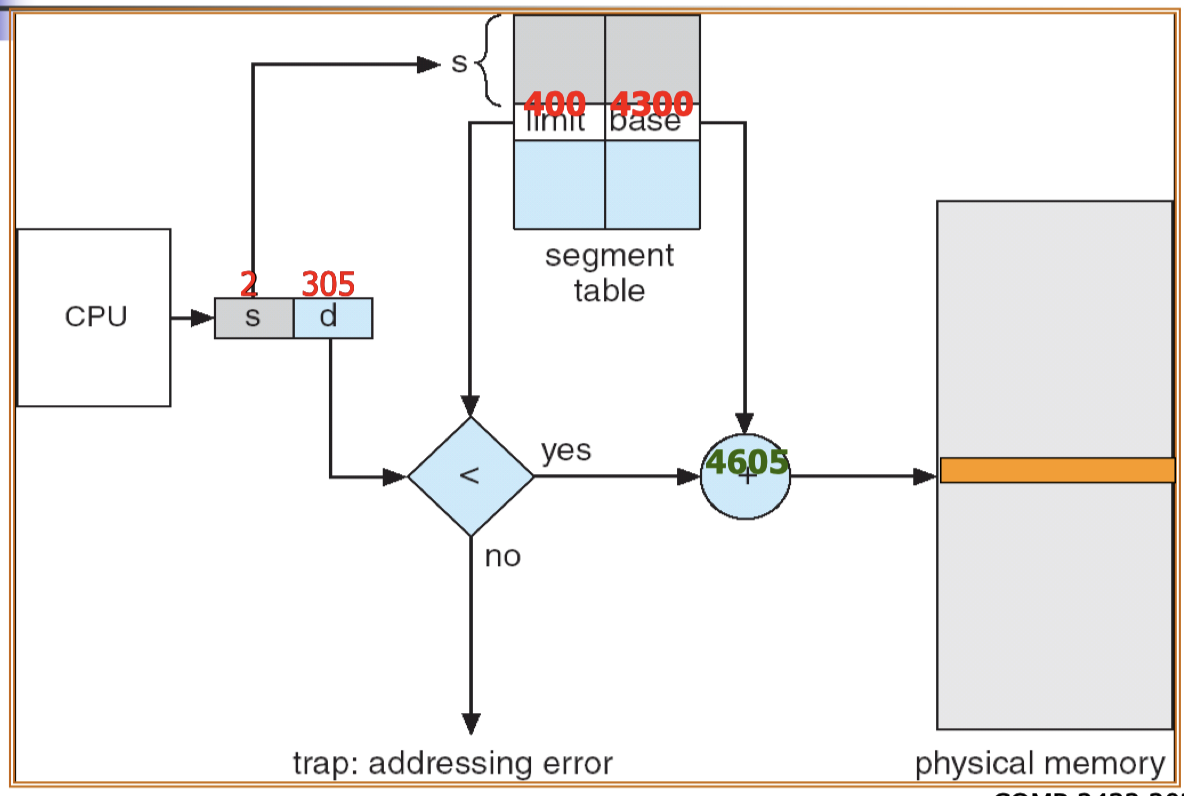
- Use of segments also allows easy sharing of program code or shared data across processes.
- Page sharing is easier, since all pages are of the same size, at fixed boundary, but segment sharing needs more works.
8. Virtual Memory
8.1 Virtual Memory
Swapping
- When there are too many processes in memory, everybody will not have sufficient memory to run. So some of them should be moved out of the memory to free up the space for others.
- Swap out:
- A process can be swapped out of memory to backing store
- Backing store is normally a fast disk large enough to hold copies of memory images for users and provide direct access to these memory images.
- Swap in:
- brought back into memory for continued execution.
- Processes can be swapped out in full (whole process) or in part (segment or page).
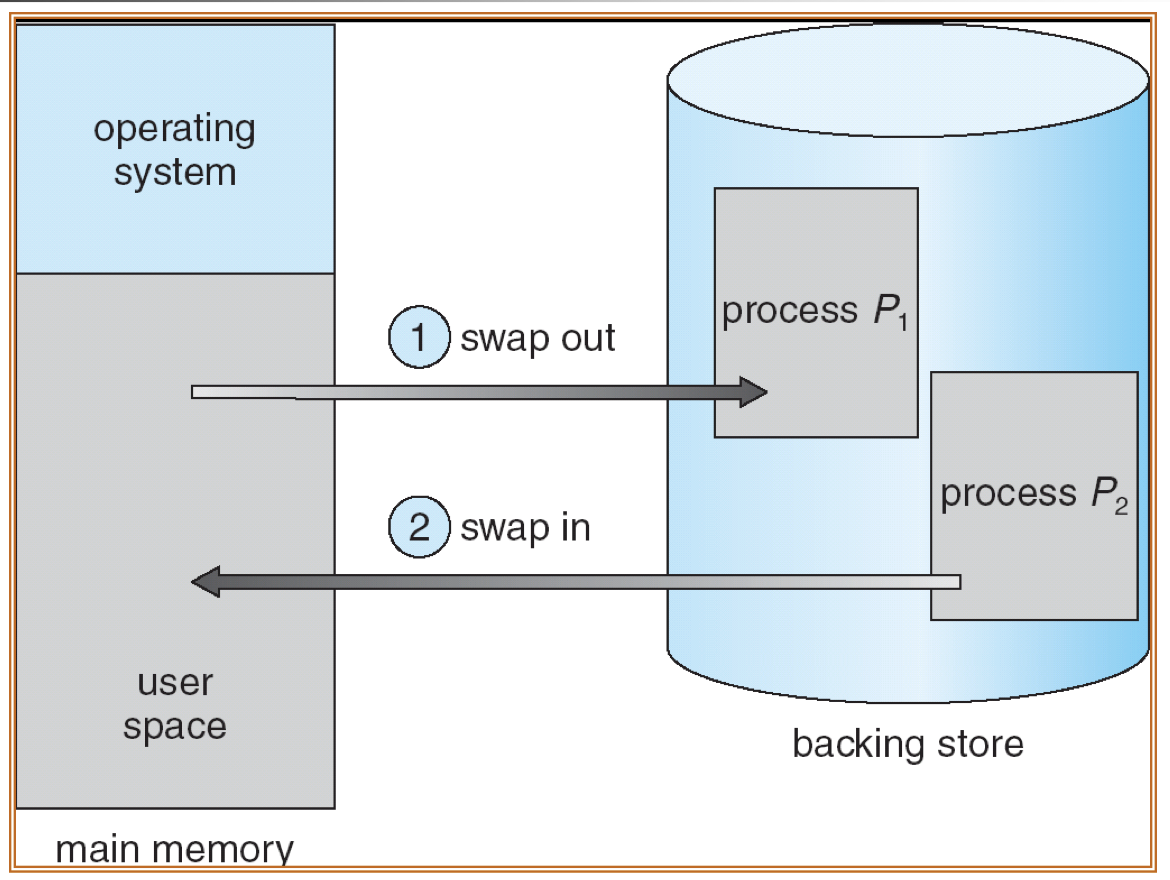
Virtual memory is mapped to physical memory.
- Some parts are stored in real memory.
- Some parts are stored on disk only.
- Move in needed part to memory (swap in) and move out unneeded part from memory (swap out).
- Memory map in virtual memory means the page table in paging.
Overlay:
- Swapping is done to different phases of program execution.
8.2 Demand Paging and Page Faults
When to bring a page from disk into memory?
- Demand paging: bring a page into memory only when it is needed.
- Avoid loading pages that are not used (effective use of I/O resource).
- To load a needed page, process must wait for I/O to complete.
- Anticipatory paging:
- predict what pages a process would need in near future and to bring them in before hand.
- No need to wait for a page to be loaded, faster response time.
- Prediction of future could be wrong and I/O would be wasted.
8.2.1 Demand Paging
A page is needed when there is a reference to it.
- A reference is a need indicated by PC or MAR.
- If the reference is invalid, process is accessing outside its space, then generate a trap.
- If the page is not in physical memory, load it from disk into memory.
Demand paging is implemented by a lazy process swapper.
- It never swaps a part of a process into memory unless the part is needed.
- A swapper that swaps pages is called a pager.
Advantages of demand paging.
- Less I/O needed.
- Less physical memory needed.
- Relatively good response.
- Can support more users.
8.2.2 Page Faults
valid-invalid bit:
- A valid-invalid bit is used to indicate whether a page is in memory.
- valid: A valid entry means that the page is in memory and the frame number could be used.
- invalid: An invalid entry means that the page is not in memory.
- Hardware will detect the invalid bit and triggers a trap, called the page fault.
- The page fault handler (a kind of interrupt handler) will ask the pager to help swapping the page into memory.
page fault handler:
The page fault handler in OS checks with the address limit stored in PCB of the process for the nature of the trap.
- If the reference is beyond the process logical address, print out segmentation fault error and terminate the program.
- If the page is just not in memory, continue with page fault handling to bring it into the memory.
Servicing a page fault:
- Get an empty frame from the free frame list.
- Schedule I/O to load the page on disk into the free frame.
- Update the page table to point to the loaded frame.
- Set the valid-invalid bit to be valid.
- Restart the instruction that caused the page fault.
8.2.3 Demand Paging Performance
Let the page fault rate be $f$.
- If $f = 0$, there is no page fault.
- If $f = 1$, every reference generates a page fault.
- Note that $0\le f \le 1$.
Effective Access Time (EAT) is the expected time to access to memory, in the presence of virtual memory.
- EAT $= (1 – f) \times$ memory access time $+ f \times$ page fault service time.
- Page fault service time = page fault overhead + time to swap the page in + restart overhead.
[Example]
8.3 Page Replacement Mechanism
Page replacement:
- Action of finding a frame in memory to be removed to free up the space in order to admit a newly needed page.
Modify page fault handler to include page replacement mechanism.
- It is more effective to remove a page that has not been changed or modified, since that page does not need to be written back on the disk.
Steps in page fault handling with page replacement:
- Find the location of the desired page on disk.
- Find a free frame:
- If there is a free frame, use it.
- If there is no free frame, use a page replacement algorithm to select a victim frame.
- Write victim frame to disk if modified.
- Bring the desired page into the (new) free frame.
- Update the page table and frame information for both the victim and the new page.
- Return from page fault handler and resume the user process generating the page fault
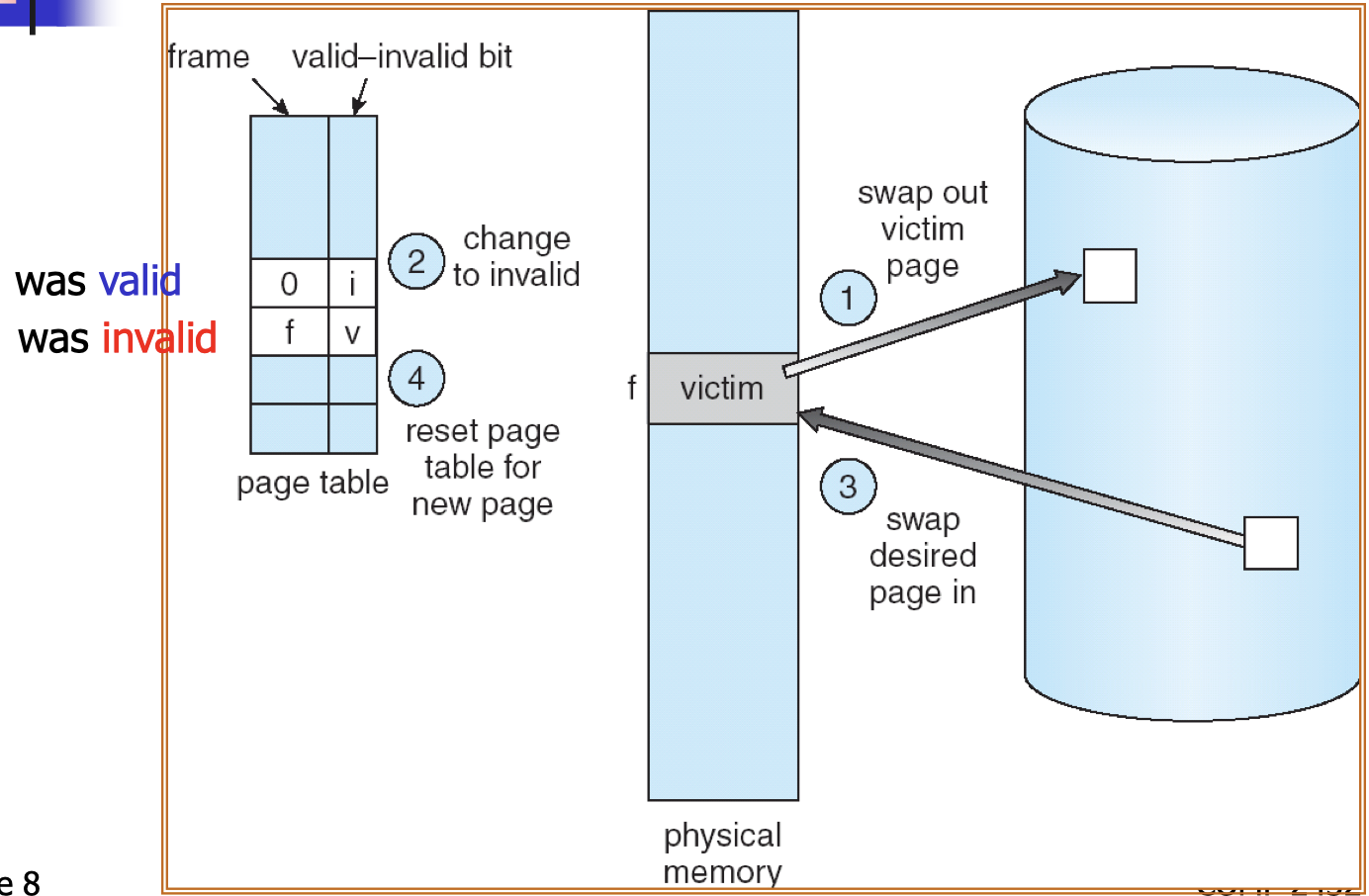
8.4 Page Replacement Algorithms
First In First Out (FIFO)
- If a page comes in earlier than another page, the earlier page will be replaced before the later page.
Optimal
- Look into the future, and replace the page that will not be needed in the furthest future. Do you have the oracle?
Least Recently Used (LRU)
- Look into the past, and replace the page that has not been used for the longest time.
8.4.1 FIFO Page Replacement
When there is no free frame, the page that has resided in the memory for the longest (the earliest page admitted) will be replaced.
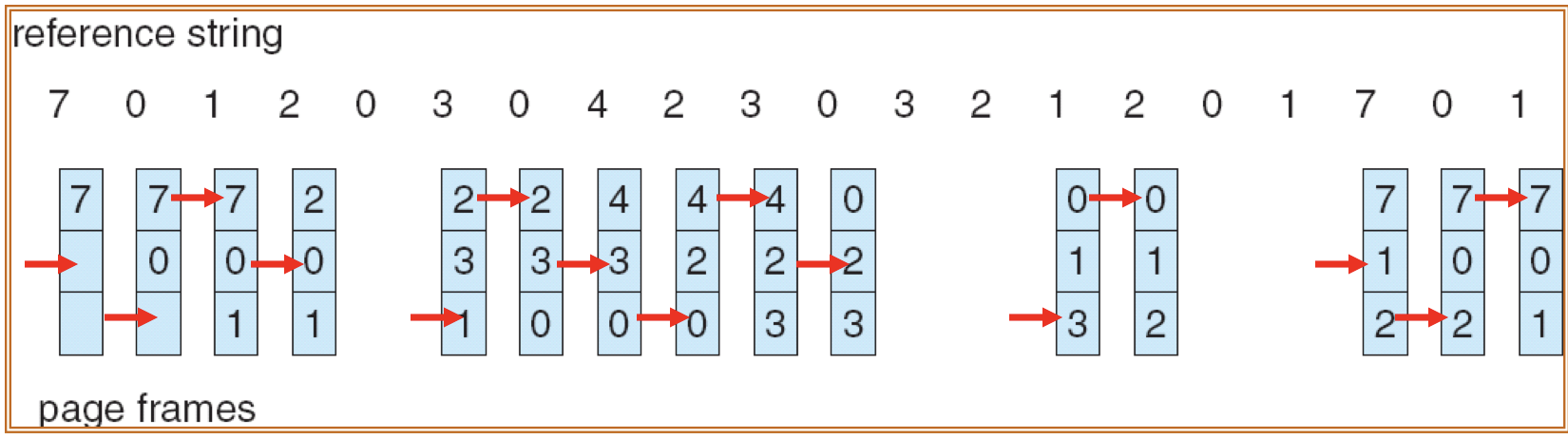
8.4.2 Optimal Page Replacement
- Replace the page that will not be used for the longest period of time in future.
- It is clear that this will generate the smallest number of page faults. But how could you know the future?
- Used as a benchmark to evaluate other algorithms.
- In this example, there are only 9 page faults.
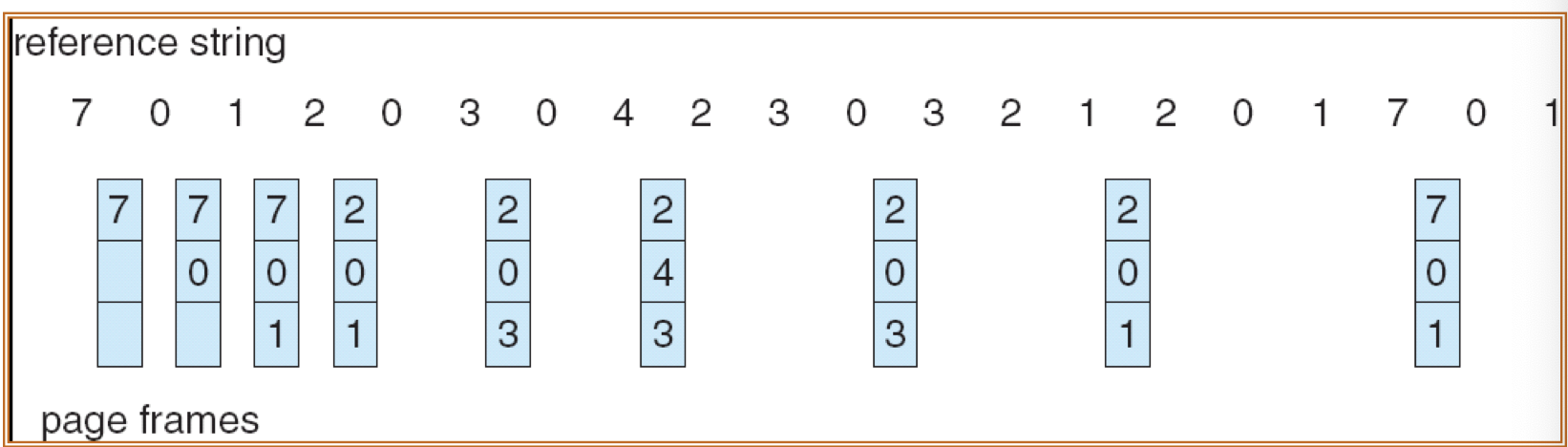
8.4.3 LRU Page Replacement
Replace the page that has not been used for the longest period of time.
- LRU is very similar to using a mirror to look into the past to reflect what the future would look like. The behavior at time $now+t$ can be reflected as now-t$.
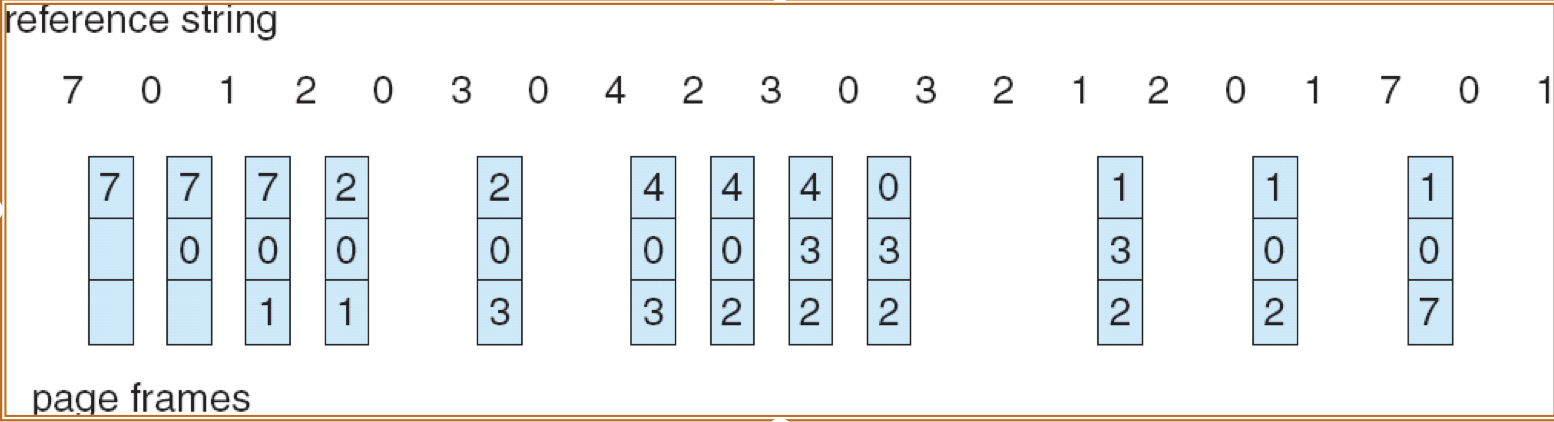
Implementation of LRU:
- Counter implementation
- Stack implementation
- Approximation implementations
- Reference bit algorithm
- Additional reference bit algorithm
- Second chance (clock) algorithm
8.4.3.1 Counter Implementation
- Every page entry has a counter.
- Whenever a page is referenced through this entry, copy the clock value into the counter.
- When a page needs to be replaced, look at the counters to determine the page with the smallest value to be replaced.
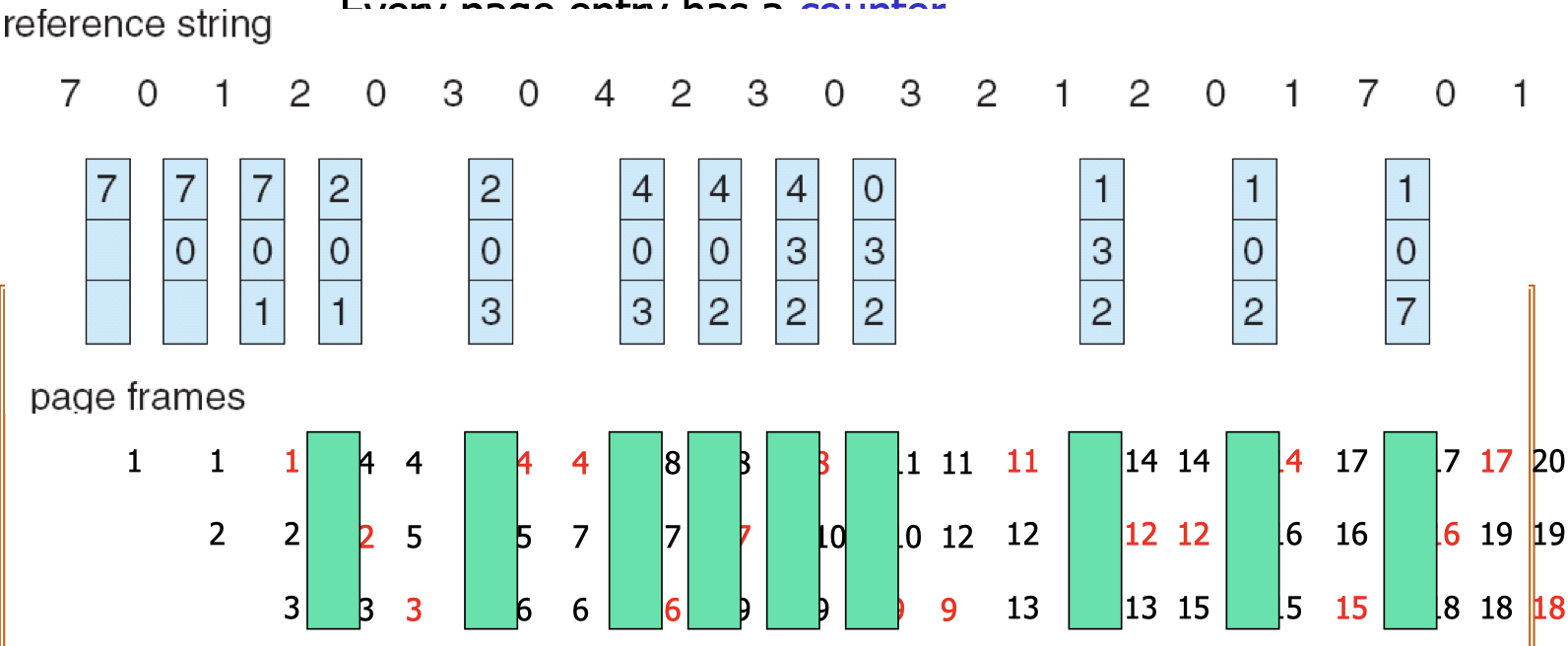
8.4.3.2 Stack Implementation
- Use stack of pages in double linked list with head/tail pointers. When a page is referenced, move it to the top of stack.
- Replace the page at the bottom of the stack.
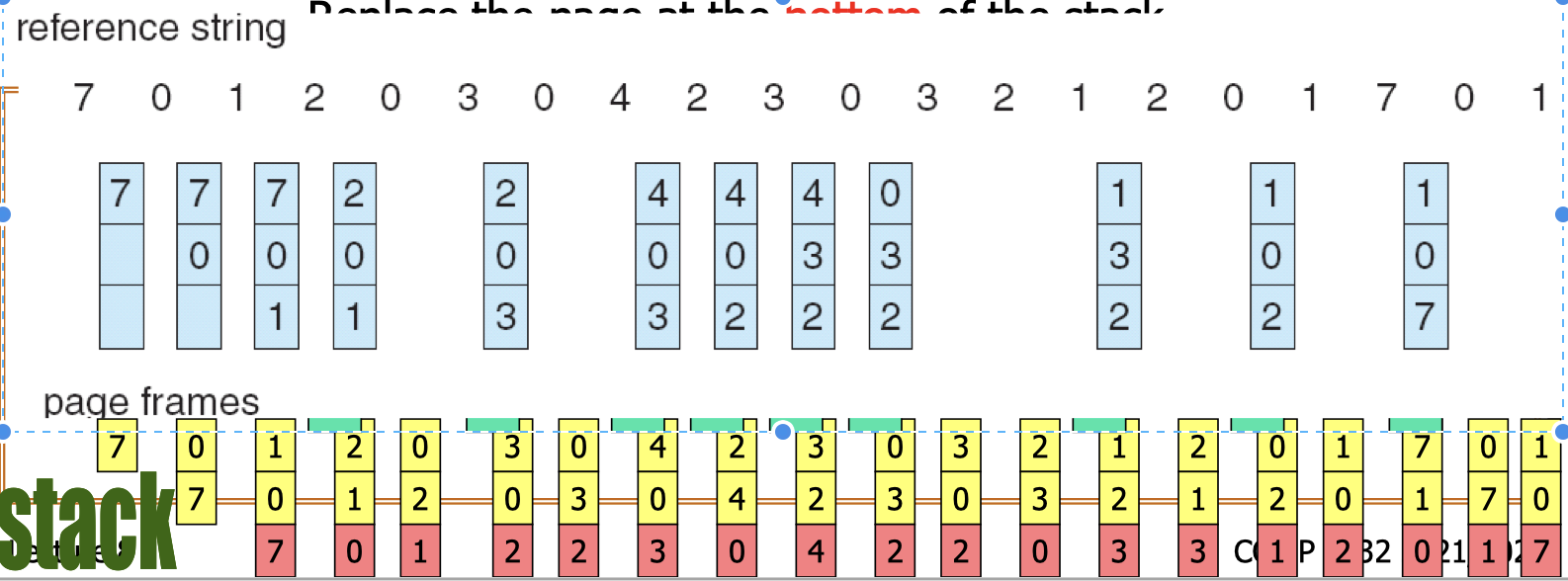
8.4.3.3 Reference Bit Algorithm
- Use hardware to help to make page selection faster.
- Each page is associated with a reference bit, initially zero. When a page is referenced, the reference bit is set to one by hardware.
- Basic algorithm: replace a page with a reference bit value of zero.
8.4.3.4 Additional Reference Bit Algorithm
Algorithm:
- Keep several bits or a byte with each page, initially 0.
- If the page is referenced, set the leftmost bit (MSB) to 1.
- At regular time interval, e.g. 100 ms, shifting the other bits right by 1 bit and discarding the low-order bit.
Example:
- never referenced in the past 8 periods, it has a value of 0.
- A page that is used once in each period has a value of 255 (11111111).
- A page used in only past 4 periods (11110000) will have a value larger than a page used in only the last fifth to eighth periods (00001111).
Placement:
- A page with smallest value is probably the least recently used.
- Replace a page with the smallest value.
- Use FIFO or random algorithm to replace a page (or all those pages) if there are several pages with the same smallest value.
8.4.3.5 Second Chance (Clock) Algorithm
- list of pages like a simple circular queue;
- hardware reference bit(0,1);
- If a page is to be replaced, look at the entry at the current pointer of the queue.
- If its reference bit is 0,
- replace the page and
- advance the queue pointer.
- If the reference bit is 1,
- then reset the reference bit to 0 and
- advance the queue pointer to next entry,
- until a page with a reference bit of 0 is found for replacement.
- If its reference bit is 0,
- A selected victim page with reference bit of one will be given a second chance.
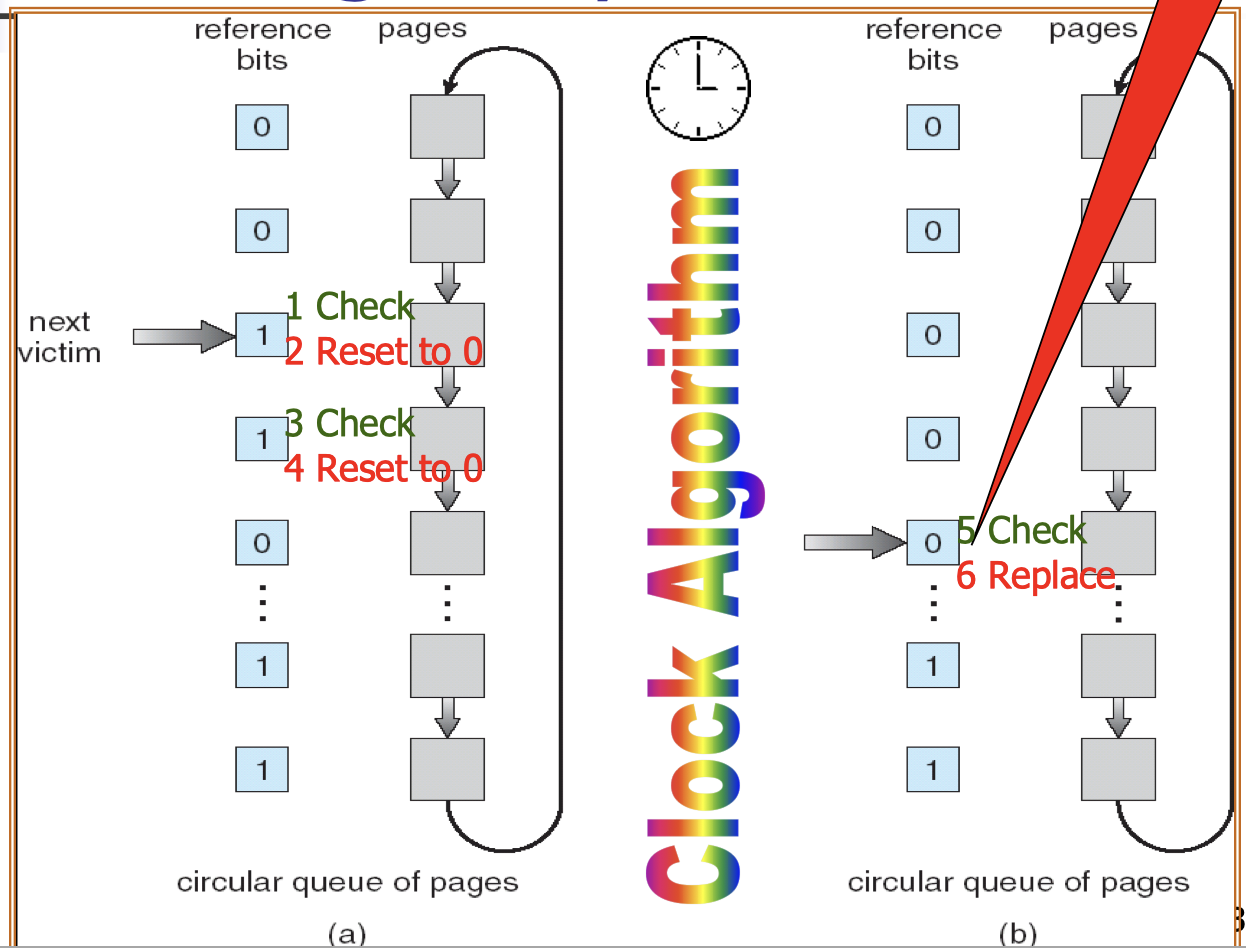
8.5 Allocation of Frames
In page replacement algorithms, we would assume that we know the number of frames for each process and look for a page to be replaced.
Fixed allocation
- Equal allocation: each process gets an equal number of frames F/n.
- Proportional allocation: each process gets a number of frames in proportion to its size, more frames for larger processes.
Variable allocation
- Allow the number of frames allocated to each process to vary over time.
- Processes that suffer from too many page faults should have more frames and vice versa.
Page replacement is also related to frame allocation.
- Local page replacement
- A process will only seek for page replacement within its own set of frames.
- Global page replacement
- A process will seek for page replacement within all frames of all processes.
- A process may take away a frame from another process.
Only local page replacement can be used for fixed frame allocation.
Both global and local page replacement can be used for variable frame allocation.
8.6 Thrashing
Thrashing:
- If a process does not have enough frames allocated for it, it will generate many page faults.
- Processes are busy.
- But they are just busy performing I/O: swapping pages in and out, without doing any useful work.
Thrashing occurs when the number of frames available is smaller than the total size of active pages of the processes in the ready queue.
- The solution is to reduce the degree of multiprogramming, not increasing it.
8.7 Working-Set
- To reduce thrashing, we should ensure that there are sufficient frames for the active pages for the processes.
- The set of active pages for a process is called its working-set.
- The working-set size of a process is the total number of pages referenced in the recent period
- When the number of frames is smaller than the total working-set size, thrashing will occur. OS must select a victim process and suspend it, removing its frames for use by other processes.
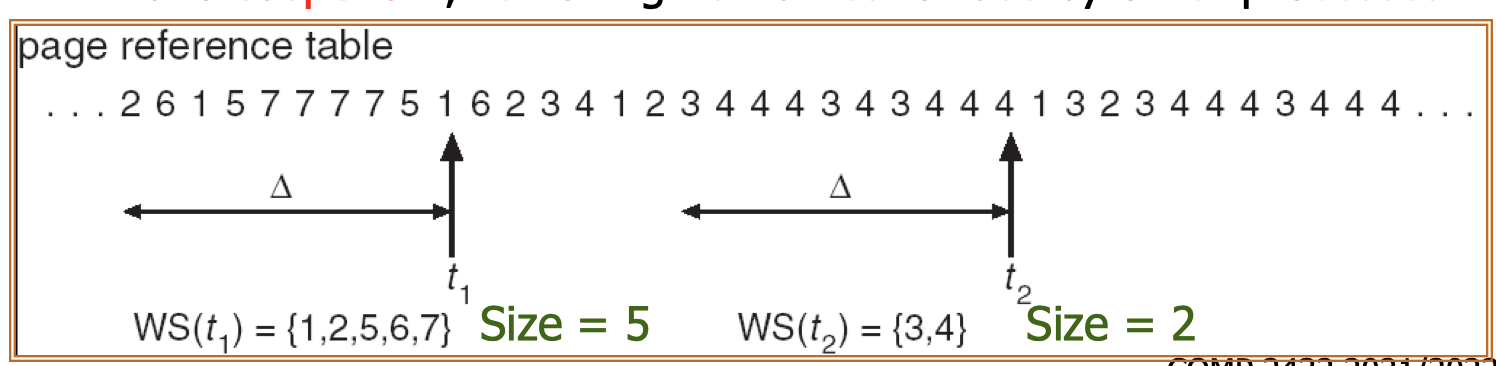
8.8 Page Fault Frequency
Count the page faults for a process over a period of time.
Define an acceptable range of page fault rate.
- If the rate is too low, there are more frames than sufficient, and OS could take away some frames to other processes.
- If the rate is too high, the process may suffer from thrashing, and OS will give more frames to it.
- If many processes have a high rate, OS will select a victim process for suspension and free its frames to other processes.
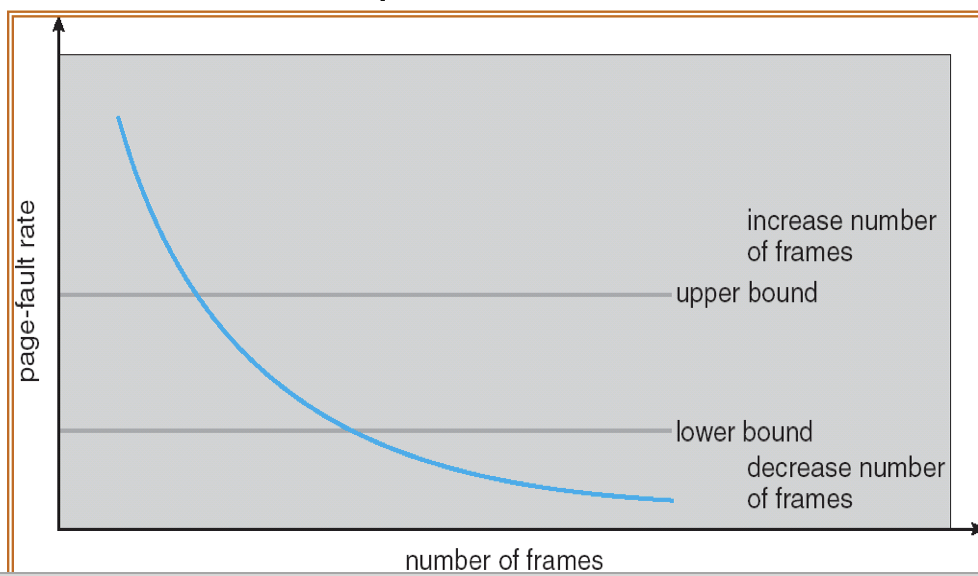
9. Deadlock
9.1 Resource Model
A resource is an object that is capable of being used.
Steps to use a resource:
- Request for the resource (acquire or open).
- Wait until the resource is allocated or granted.
- Use the resource (read or write).
- Release the resource (return or close).
A resource can only be used by a process after it issues a request to the resource manager and the manager approves its usage (grant the resource).
A process releases the resource when done to the manager so that the next process waiting in line could use it.
We assume that all processes follow this rule.
- Resources could be grouped into types.
- A process utilizes a resource through the request/use/release
cycle. A deadlock is a set of blocked processes, each holding a resource and waiting to acquire a resource held by another process in the set.
- resource deadlock
- Note that once a deadlock is there, it will be there but a livelock can be removed with a bit of luck.
Another type of deadlock is called communication deadlock
- A set of processes are waiting for a message to be sent from processes (e.g. data to be written into a pipe) within the set, or an event to be triggered by the set (e.g. go ahead signal).
9.2 Deadlock Characteristics
Deadlock can only occur if all four necessary conditions are true.
- Mutual exclusion
- Only one process at a time can use a resource.
- Hold and wait
- A process holding at least one resource is waiting to acquire additional resources held by other processes.
- No preemption
- A resource can be released only voluntarily by the process holding it, after that process completes its task.
- preemption: run until the completion;
- Circular wait
- There is a chain of waiting processes
9.3 Resource Allocation
- Set of vertices $V$, set of edges $E$.
- two types of vertices $V$:
- $P={P_1,P_2,…P_n }$ is the set of all processes;
- $R={R_1,R_2,…R_n }$ is the set of all resources types;
- two types of edges $E$:
- Request edge is a directed edge from $P$ to $R$
- $P_i\to R_j$: $P_i$ is requesting for resource $R_j$.
- Assignment edge is a directed edge from $R$ to $P$
- $R_j\to P_i$: $R_j$ is allocated/assigned to $P_i$ which holds the resource.
- Request edge is a directed edge from $P$ to $R$
- If a request can be fulfilled by the resource manager, a request edge will become an assignment edge and the direction of the edge is reversed
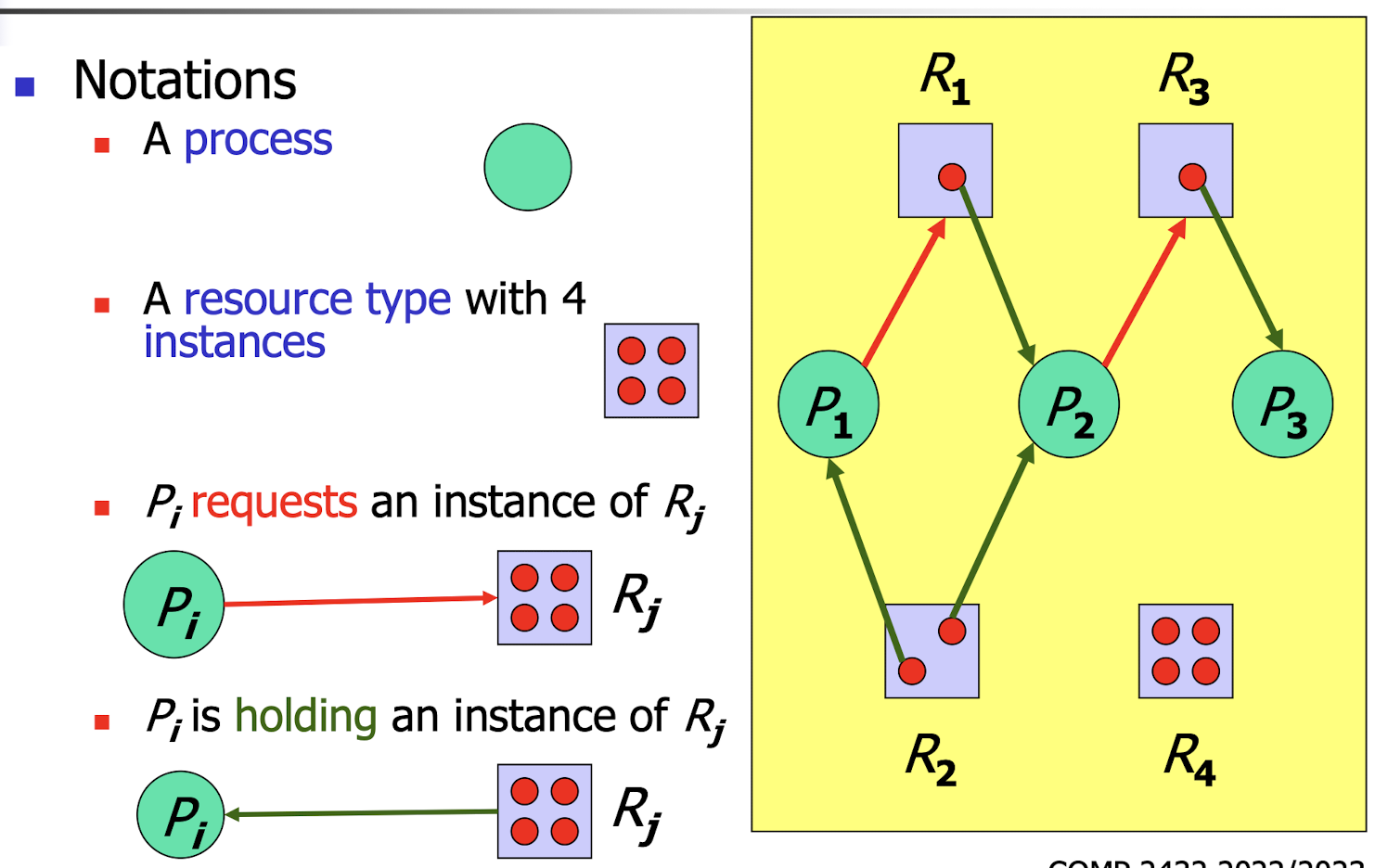
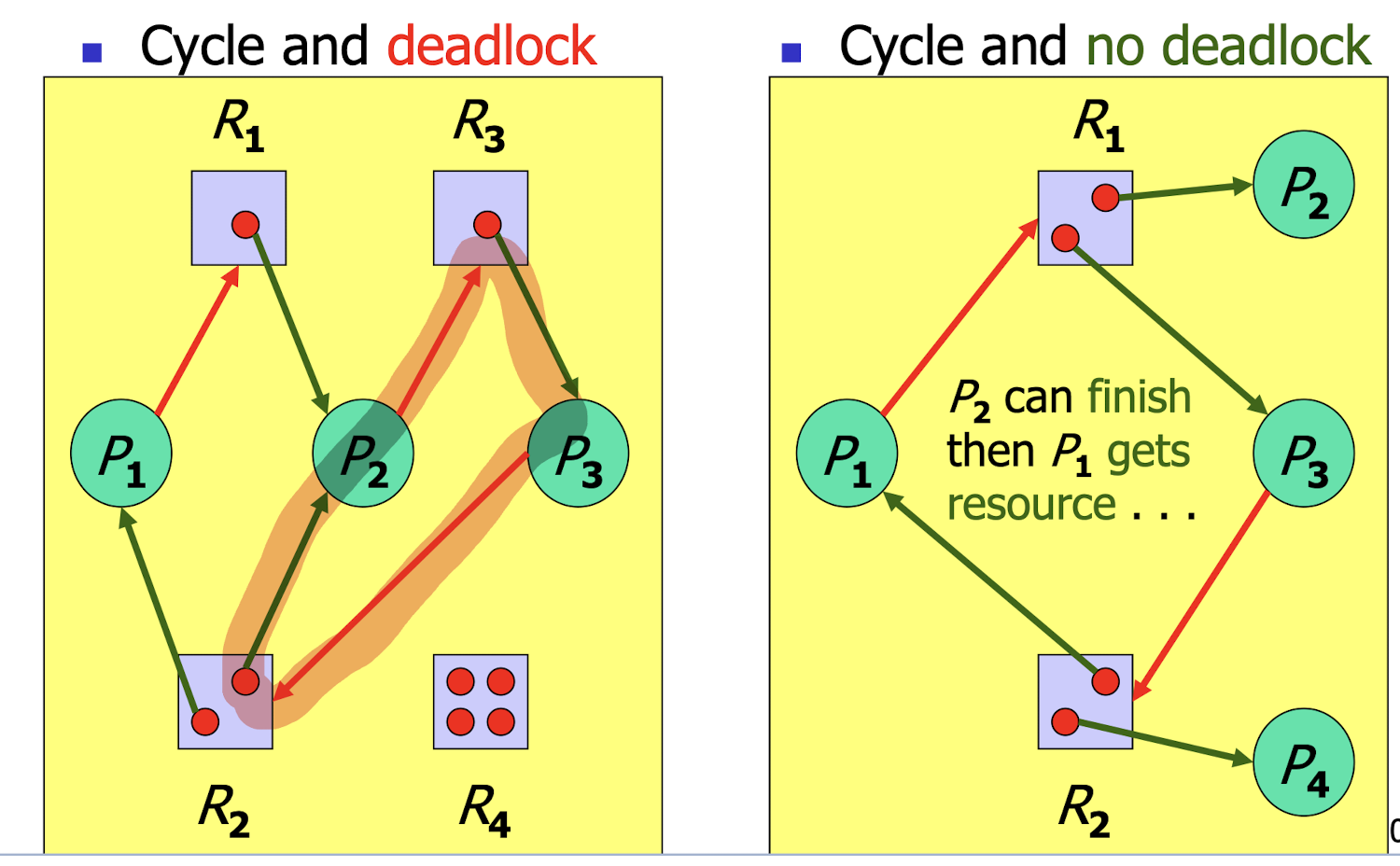
Rules:
- If the graph contains no cycle, then there is definitely no deadlock.
- If the graph contains a cycle,
- If there is only one instance per resource type, then a cycle means that there is a deadlock.
- If there are several instances per resource type, then a cycle only means that there is a possibility of deadlock.
- Thus, cycle is only a necessary condition of a deadlock, but it is not a sufficient condition for a deadlock.
Algorithm:
- Before a resource is allocated, OS checks whether the allocation would result in a cycle.
- Do not allocate the resource if a cycle is produced.
- The request to resource can be granted only if converting the request edge to an assignment edge does not result in a cycle in the resource allocation graph.
9.4 Deadlock Handling
Four types of methods to deal with a deadlock.
- Ostrich approach
- Ignore the deadlock problem and pretend that deadlocks never occur in the system.
- Deadlock prevention
- Ensure that the system will never enter a deadlock state.
- Deadlock avoidance
- Allocate the resources very carefully so that system will not enter a deadlock state.
- Deadlock detection
- Allow the system to enter a deadlock state, detect it and then recover from it.
9.5 Deadlock Prevention
There are four necessary conditions. Attack any one to ensure that it is not satisfied.
- Mutual exclusion
- For sharable resources, mutual exclusion is not true and there is no deadlock.
- Problem: some resources are inherently not sharable.
- Hold and wait
- Ensure that whenever a process requests a resource, it does not hold any other resources.
- No holding and waiting
- Example: you should return all your books before you can borrow a book from the library!
- This means that process should request and be allocated all its resources before it begins execution, or allow a process to request resources only when it has none.
- Problem: low resource utilization, starvation.
- No preemption
- Allow resources to be preempted from a process.
- If a process that is holding some resources requests another resource that cannot be allocated to it, then all resources currently being held are released (preempted).
- Preempted resources are added to the list of resources for which the process is waiting.
- Process will be restarted only when it can regain its old resources, as well as the new ones that it is requesting.
- Problem: not all resources can be preempted, starvation is possible.
- Circular wait
- Order all resource types with possibly a number.
- Each process can only request resources in an increasing order of resource number.
- Then no one can wait in a cycle, because everyone can only wait for a higher number.
9.6 Deadlock Avoidance
Use additional information about how resources are requested.
Carefully control the allocation of resources.
- The simplest and most useful model is to ask each process to declare the maximum number of resources of each type that it may need.
OS can check in advance when allocating resource to ensure that system remains in a safe state that will not enter a deadlock state.
- Deadlock avoidance algorithm dynamically examines the resource allocation state to ensure that there can never be a circular-wait condition.
- Resource allocation state is defined by the number of available and allocated resources and the maximum demands of the processes.
If a system is in a safe state, there is no deadlock.
If a system is in an unsafe state, there is a possibility of deadlock.
- Deadlock occurs only if a bad sequence of events happen.
- There may not be deadlock if there is
some luck.
Deadlock avoidance - Ensure that a system will never enter an unsafe state, with care.
Safe state
A state is safe if the system can allocate the remaining resources in a certain order so as to avoid a deadlock.
- That allocation order is indicated by a safe sequence.
- A safe sequence $
- For each $P_j$, the resources that $P_j$ can still request can be satisfied by currently available resources plus resources currently held by all preceding processes $P_k$ with $k < j$.
Based on a safe sequence,
- For each $P_j$, the resources that $P_j$ can still request can be satisfied by currently available resources plus resources currently held by all preceding processes $P_k$ with $k < j$.
- If the resources needed by $P_j$ are not immediately available, then $P_j$ can wait until all $P_k$ have finished.
- When $P_k$ finishes, $P_j$ can obtain its needed resources, execute, return its allocated resources, and terminate.
- When $Pj$ finishes, $P{j+1}$ can obtain its needed resources, and so on.
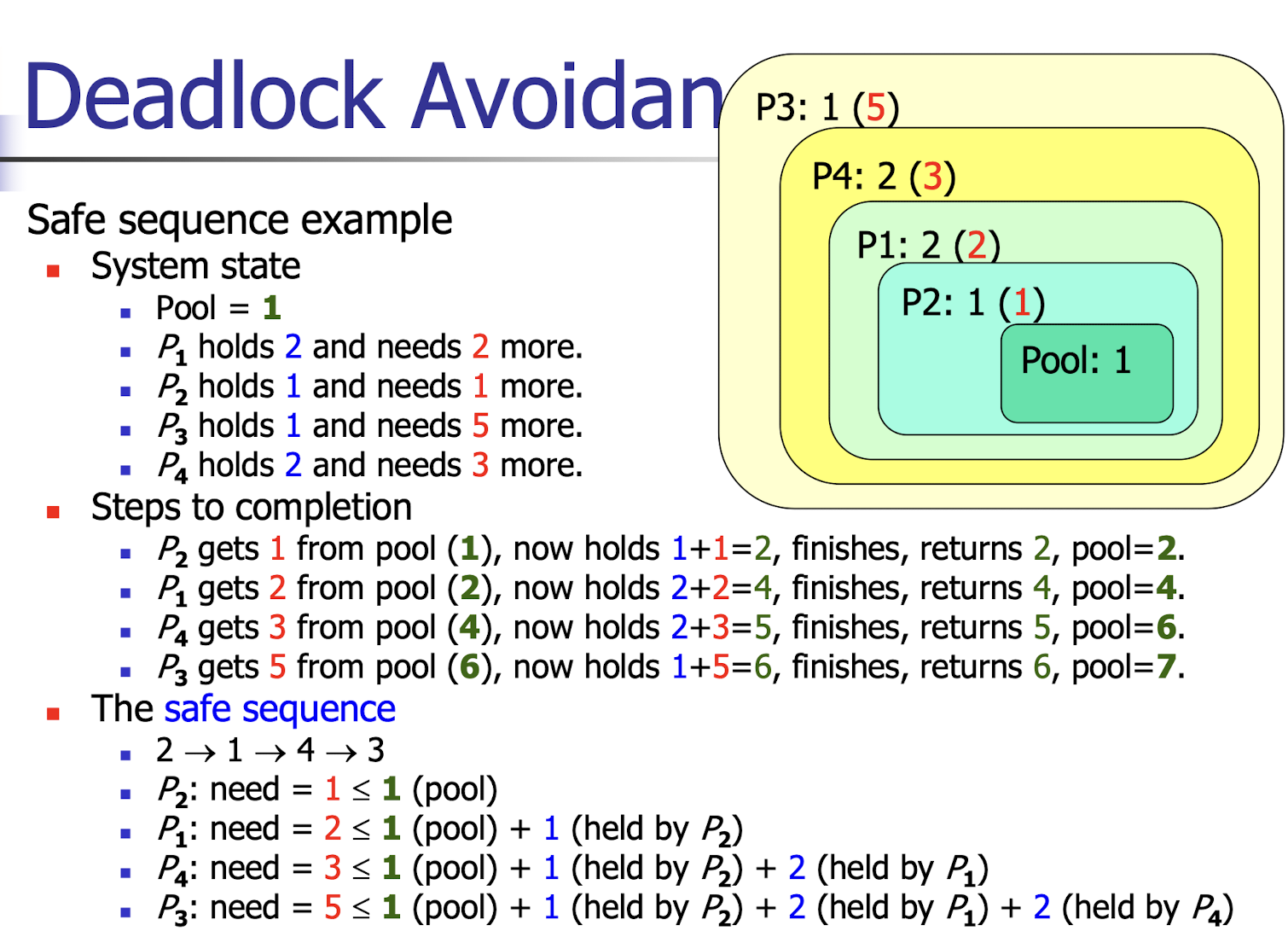
9.6.1 Banker’s Algorithm
An algorithm for multiple instances of resource types.
Assumptions:
- Each process must declare its maximum use before hand.
- When a process requests a resource, it may have to wait.
- When a process gets all its resources, it must return them in a finite amount of time.
Try to find a safe sequence pretending that the
request is satisfied.
- If a safe sequence exists, the request can be granted.
- If there is no safe sequence, granting the request will lead the system into an unsafe state. Put the request on hold until some resources are returned.
Notations
- $n$: number of processes ($P_1$ to $P_n$).
- $m$: number of resources types ($R_1$ to $R_m$).
- $Available[m]$: 1D array of $m$
- $Available[j]$ = number of instance od resource type $R_j$ available. how many remaining.
- $Max_i[m]$: 2D array of $m$
- $Max_i[j]$ = maximum number of instances of resource type $R_j$ that process $P_i$ may request.
- $Allocation_i[m]$: 2D array of $m$
- $Allocation_i[j]$ = number of instances of $R_j$ currently allocated to $P_i$. how many the OS has given to the process.
- $Need_i[m]$: 2D array of $m$
- $Need_i[j]$ = additional number of instances of R j that P i may need to complete its task. What may in the future
- $Need_i[j]= Max_i[j] - Allocation_i[j]$
Safety algorithm
(Against Need with Available)
Define temporary arrays $Work[m]$ and $Finish[n]$ boolean array
$Work = Available$
$Finish = false$
while not done do
- Find an $i$ such that $Finish[i] = false$ and $Need_i[j] \leq Work[j]$;
- if no such $i$ exists, break;
- $Work[j] = Work[j] + Allocation_i[j]$
- $Finish[i] = true$
If for all $i$, $Finish[i] = true$, then declare the system is safe;
If some are false, declare the system is unsafe.
[Example]
Request algorithm
Define $Request_i[m]$ to be requested by process $P_i$.
- If not ($Request_i \leq Need_i$), then raise error ($P_i$ has exceeded its maximum claim) and stop;
- If not ($Request_i \leq Available$), then $P_i$ must wait, since resources are not available;
- Else: pretend to allocate requested resources to
$P_i$ modifying the allocation state:- $Available = Available - Request_i$
- $Allocation_i = Allocation_i + Request_i$
- $Need_i = Need_i - Request_i$
Run safety algorithm on this pretended state.
- If safe, then resources are allocated to $P_i$.
- If unsafe, then $P_i$ must wait and the old resource allocation state is restored.
[Example]
9.7 Deadlock Detection
Detect deadlock by deadlock detection algorithm.
- Executed periodically or when system suspects a deadlock.
- The avoidance is do all things ahead, knowing all max resource need.
Execute a deadlock recovery scheme to recover from deadlock.
- Process termination
- Kill all deadlocked processes.
- Kill one victim process at a time until the deadlock cycle is eliminated.
- Consideration: priority of the process, progress of process, resources used/needed by process, number of processes killed.
- Process rollback
- Return to a safe state and restart process from that state.
- Possibility of starvation: the same process may always be picked as victim.
Wait-For Graph:
- Wait-for graph checking is the most common deadlock detection algorithm, useful when each resource has only one instance.
- Nodes of the graph are processes. (Resources are eliminated.)
- If $P_i\to R_k$ and $R_k\to P_j$ is in the resource allocation graph, then $P_i\to P_j$ is in the wait-for graph.
- There is a deadlock if and only if there is a cycle in the wait-for graph.
- Periodically, check for cycles in the wait-for graph to detect deadlock.
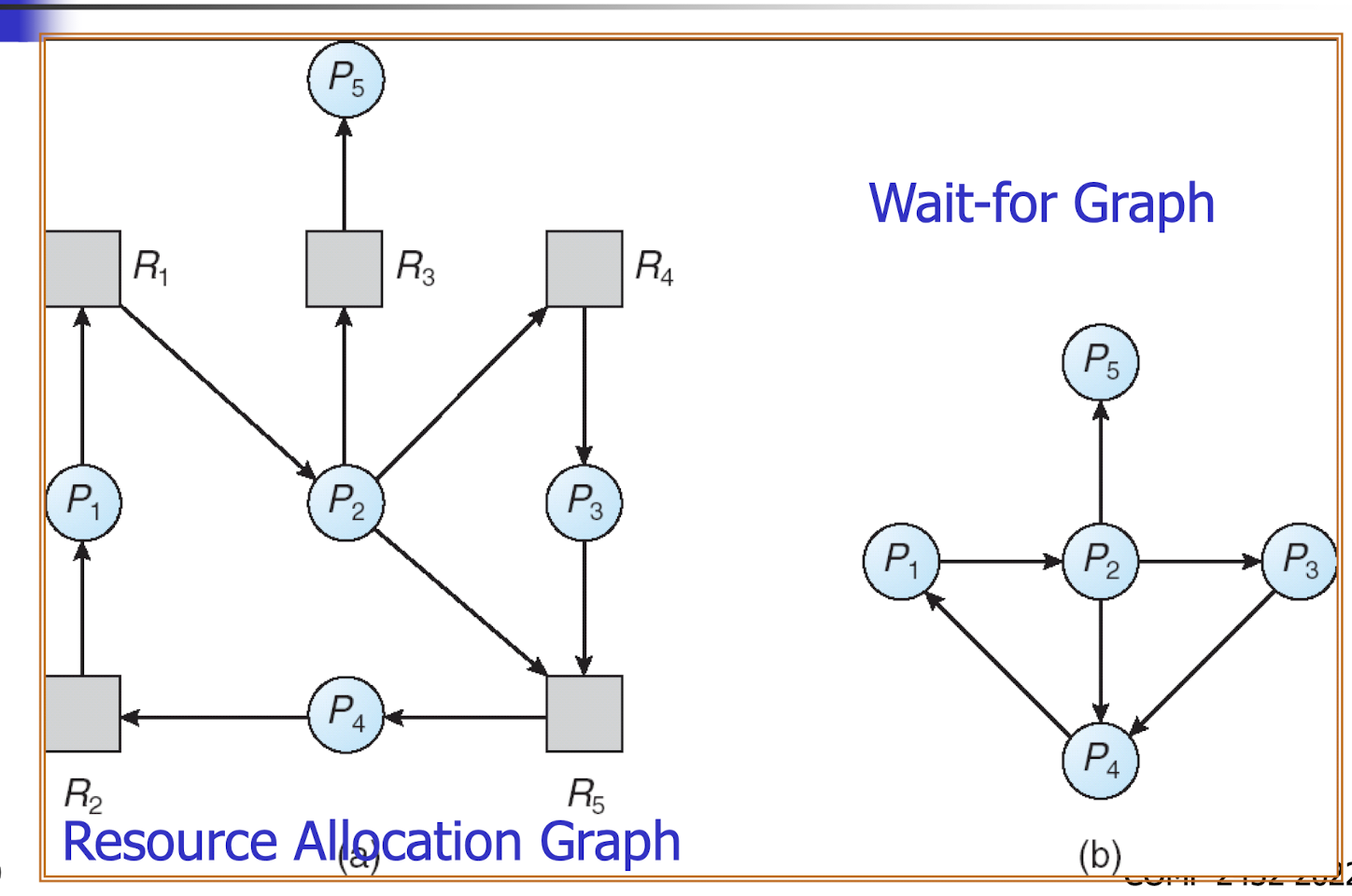
Detection Algorithm:
Notations
- $n$: number of processes ($P_1$ to $P_n$).
- $m$: number of resources types ($R_1$ to $R_m$).
- $Available[m]$: array of $m$
- $Available[j]$ = number of instance od resource type $R_j$ available.
- $Allocation_i[m]$: array of $m$
- $Allocation_i[j]$ = number of instances of $R_j$ currently allocated to $P_i$.
- $Request_i[m]$: array of $m$
- $Request_i[j]$ = number of instances of $R_j$ currently requested by $P_i$. what I really want now.
Algorithm:
(Against Request with Available: completion sequence)
Define temporary arrays $Work[m]$ and $Finish[n]$
$Work = Available$
for all $i$:
- if $Allocation_i \not ={0}$ then $Finish[i] = false$;
- else: $Finish[i] = true$
while not done do
- Find an $i$ such that $Finish[i] = false$ and $Request_i[j] \leq Work[j]$;
- if no such $i$ exists, break;
- $Work[j] = Work[j] + Allocation_i[j]$
- $Finish[i] = true$
If for all $i$, $Finish[i] = true$, then declare the system is no deadlock;
If some are false, then deadlock
- The set of processes $j$ with $Finish[j] = false$ are involved in the deadlock.
[Example]
10. Process Synchronization
10.1 Synchronization
Concurrent access to shared data may make data inconsistent.
Synchronization ensures the orderly execution of
cooperating processes.
- Synchronization requests processes to wait for the signal to go ahead, to avoid the race condition.
- Examples include sleeping barber problem, society room problem.
10.2 Producer/Consumer Problem
A solution to the producer/consumer problem is to use a few shared buffers.
- A shared buffer can be viewed as a drawer to store money that a parent is passing to a child.
- Parent puts money into an empty drawer.
- Child takes money out of a filled drawer.
- A simple solution is to have parent put money into a random drawer and child take money randomly out of the drawers.
- Problem of livelock.
- Another solution is to have parent put money starting from the first drawer and child take money from the first drawer.
- That should continue to bottom drawer and restart from top.
- This is the concept of a circular queue implementation.
10.3 Critical Section Problem
This shared resource can only be shared in such a way that at any moment, only one can use it and it cannot be used by another one before its current usage is completed.
This is consistent with our treatment of resource allocation when we deal with deadlocks.
- Resources are used through the request / use / release cycle.
In this lecture, we call the shared resource the critical section. Its name comes from a section of shared program code that can only be executed by a process at any moment, without any sharing or intermixing.
- The shared critical section is used through a similar cycle of request-to-enter-critical-section / inside-critical-section / exit-from-critical-section.
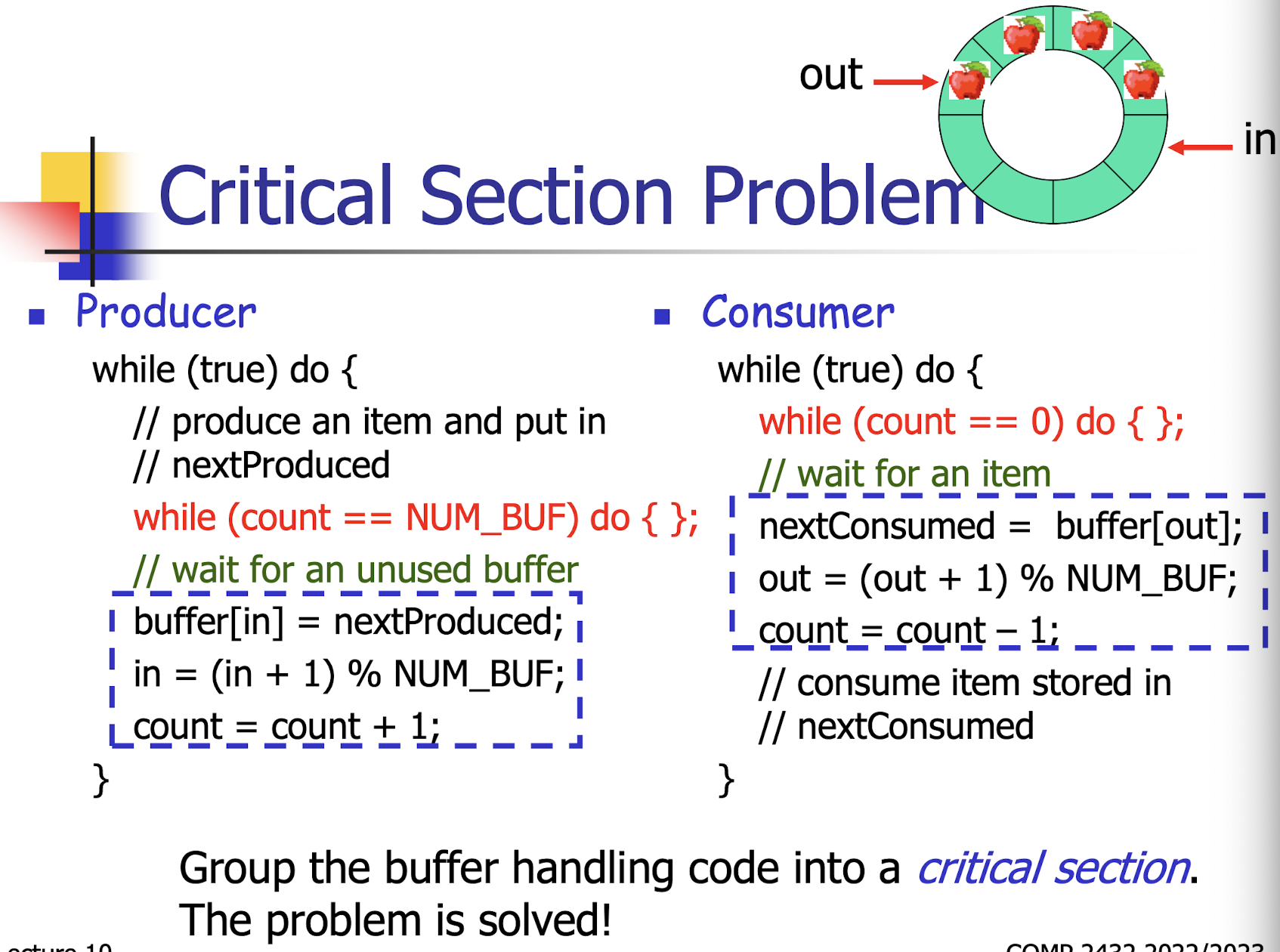
A solution to the critical section problem must avoid the problems in the Andes trains.
- The solution is made up of two separate sections of code around the critical section: entry section and exit section.
1 | |
We can only make two very simple assumptions.
- Each process executes at a non-zero speed (very slow or very fast, but will not use it forever).
- There is no limitation on the relative speed of the processes.
A solution should satisfy three properties.
- Mutual Exclusion (safety) (first fulfil)
- one is in, other can not go in. (ONLY ONE, one crash)
- If process is executing in its critical section, then no other processes can be executing in their critical sections. That is, at most one process could be in CS.
- Progress (liveness) (second fulfil)
- one can go in, it will go in. (MUST ONE, can go in)
- If no process is executing in its critical section and there exist some processes that wish to enter their critical sections, then some of the waiting processes will eventually enter the critical section. That is, at least one process could enter CS.
- Bounded Waiting (fairness) (third fulfil)
- tell the waiting time beforehand.
- A bound must exist on the number of times that other processes are allowed to enter their critical sections after a process has made a request to enter its critical section and before that request is granted. That is, there is no starvation.
10.4 Peterson’s Algorithm
(Dekker’s Algorithm: more complicated)
(Lamport’s Bakery Algorithm: more complicated)
Peterson’s algorithm for ONLY two processes.
Two processes share two variables.
int turn = 1;// indicate whose turn it is to enter the critical section.boolean flag[2] = false;// indicate whether the process is ready to enter the critical section.
1 | |
1 | |
1 | |
Who goes first depends on the turn variable’s order
- Mutual Exclusion: achieved by critical section
- Progress: achieved by “turn” variable
- No fairness problem: achieved by “you go first” (turn=j)
- but not fair when “I go first” (turn=i)
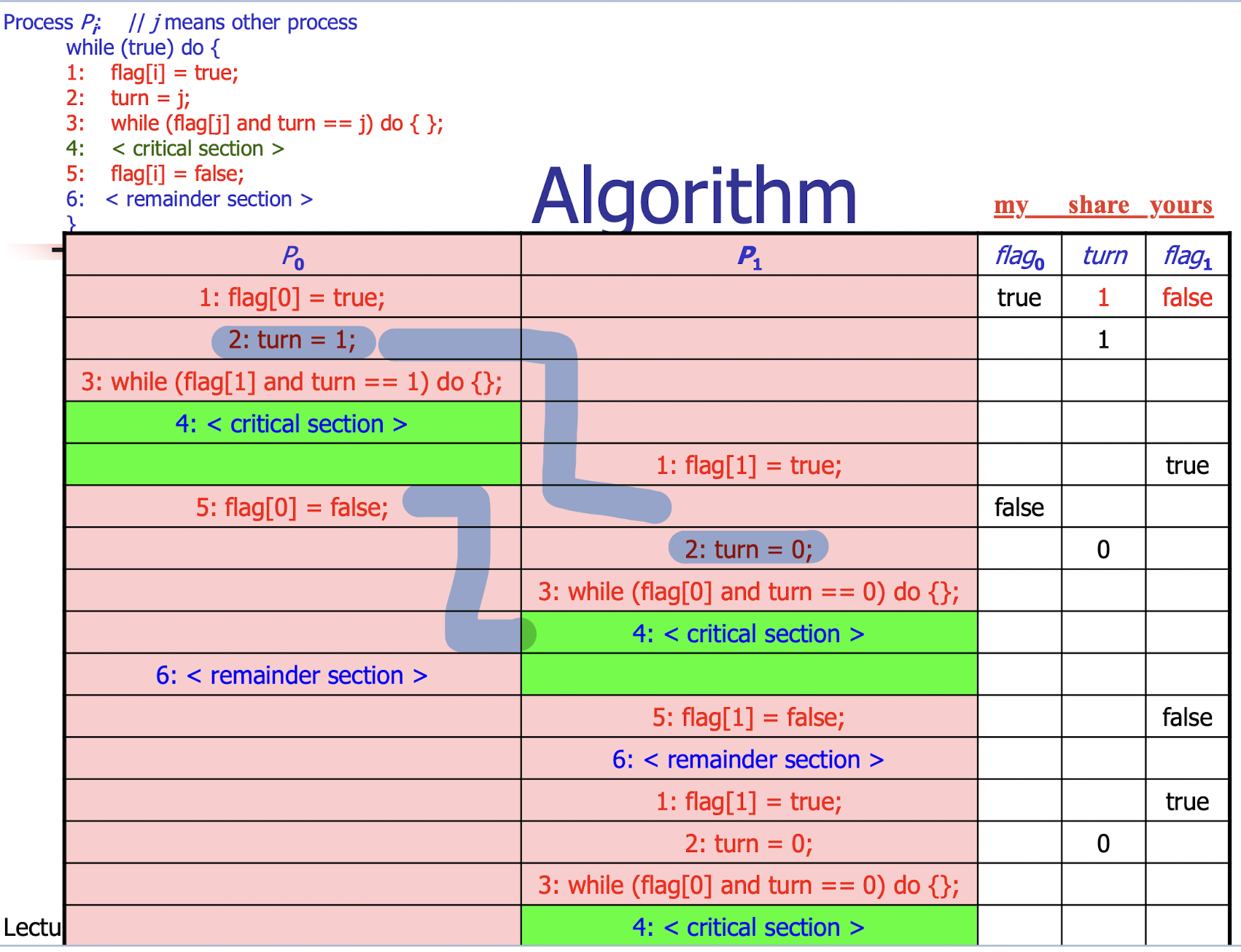

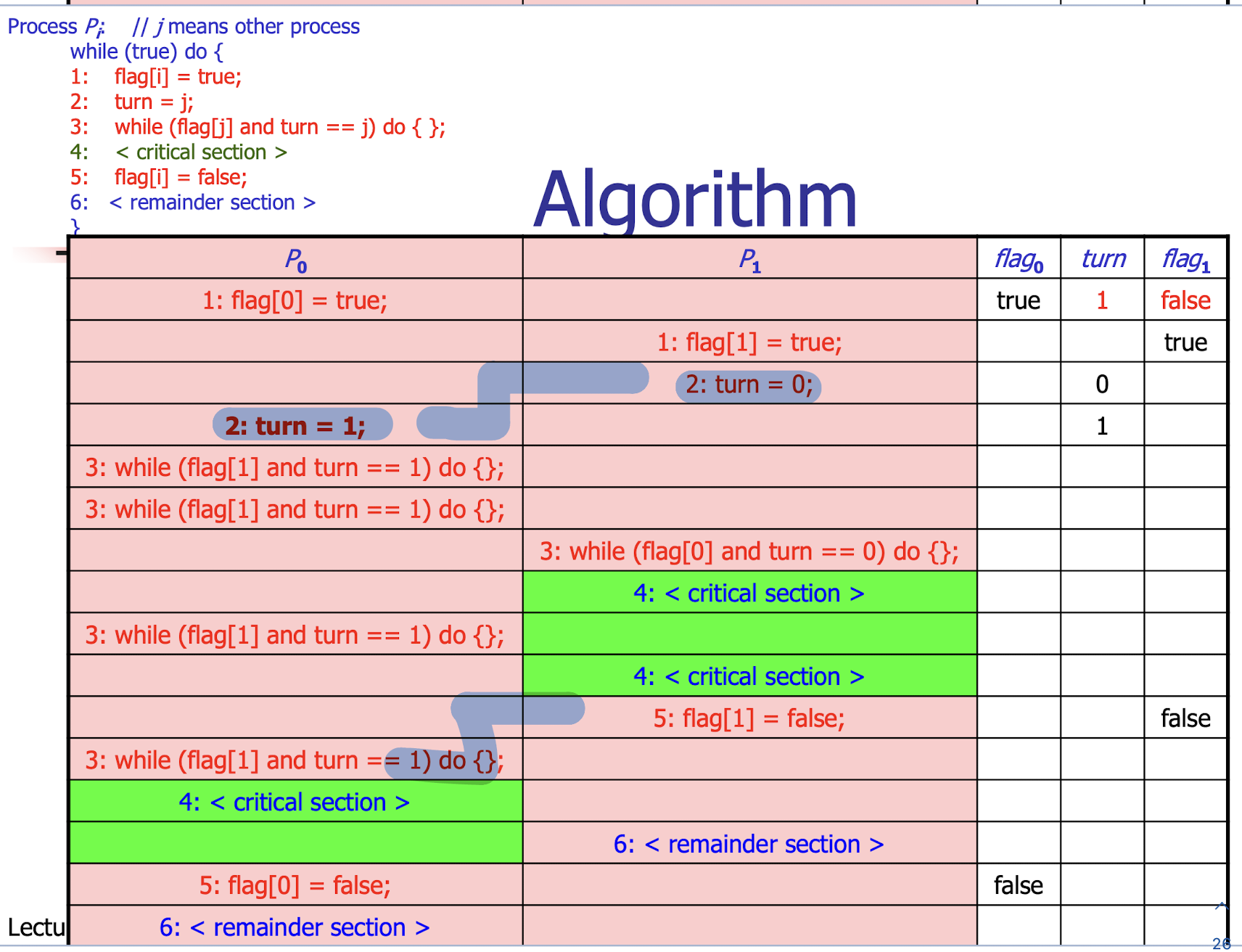

10.4.1 Busy Waiting Solution
Problems with common solutions to the critical section problem, including Peterson’s algorithm:
- There are while-loops for processes to wait until they can enter the critical section.
- This is called busy waiting: a process is busy in waiting and this uses up and wastes the precious CPU cycle.
- If you are the CPU scheduler, you will not know whether a process is waiting to enter the critical section (CPU is wasted) or just running healthily in the remainder section (CPU is used).
We should provide better solutions so that any process waiting to enter critical section should release the CPU to other processes because
- The waiting process is waiting for something to happen, but that something will not happen if it continues to hold the CPU and not allow other processes to use the CPU to make the event that it is waiting for happen. (wasting and doing nothing)
10.5 Semaphores
We want a synchronization tool that does not require busy waiting.
Instead, the OS could suspend (put into the suspend queue, not waiting queue)the process waiting to enter the critical section.
The most common tool is the semaphore.
- A semaphore S s an integer variable. like the resource.
- It provides two standard operations: P(S) and V(S).
- Originally, semaphore means flag signal (for Andes trains?)
P(S) means that the process will wait on S until S becomes positive.
- to wait for the resource to become available.
- then decrease S by one. to use it.
- (put following statement into the critical section, disablel the interrupt to ensure exe in ONE).
while (S<=0) do{};S = S - 1
V(S) means that S will be increased by one and the process waiting on S could proceed.
- S is released.
S = S + 1;
Two types of semaphores
- Binary semaphores: integer value can only be 0 or 1. (one resource)
- Counting semaphores: integer value can be any positive number. (many resources)
Binary semaphores are easy to implement.
- They are also called mutex locks (they look like locks and they help to ensure mutual exclusion or mutex).
- Providing critical section with semaphore S initialized to 1.
1 | |
[Example]
S should be initialized to 1.0: no one go into;>1: all go into, crash;
10.5.1 Semaphore Implementation
Note that some books use wait() and signal() to mean P() and V().
- They are not used here to avoid confusion because Java provides wait() and notify(), but the meanings are different from P() and V() of semaphores. Java synchronized objects are actually similar to monitors.
The implementation of semaphores must guarantee that no two processes can execute P() and V() on the same semaphore at the same time.
- To ensure no two processes executing P() and V() on the same semaphore at the same time, we could implement P() and V() inside a critical section.
- This implementation itself becomes the critical section problem if P() and V() implementation codes are placed inside critical sections.
- What is the solution to this circular / recursive problem?
In a simple way, we could allow busy waiting in the critical section implementation for P() and V().
- Implementation code is short and very little busy waiting.
To avoid busy waiting, OS associates an integer value and a list of processes waiting with each semaphore.
- The integer value is the semaphore value. A negative value indicates the number of processes waiting on the list.
Two operations on the waiting list:
Block(): place the process on the waiting list.Wakeup(): remove an appropriate process from the waiting list and move it to the ready queue.
P(S):
while (S<=0) do{};S = S - 1
V(S):
S = S + 1

- disable the interrupt: put it into the critical section.
10.5.2 Use of Semaphores
(like the share memory, pipe is used to message passing)
Semaphores are used to solve different types of synchronization problems.
Consider the sequencing problem for three children.
- Assume that parent creates three children, P1,P2 and P3.
- P1 is designed to read data, P2 to process data and P3 to write results and they must be executed in that order.
- Parent has no way to enforce that ordering
- A typical way of synchronization is to use two semaphores.
- Semaphore
canProcess = 0; - Semaphore
canWrite = 0; - set initial value to 0, let first one to set to 1
- Semaphore
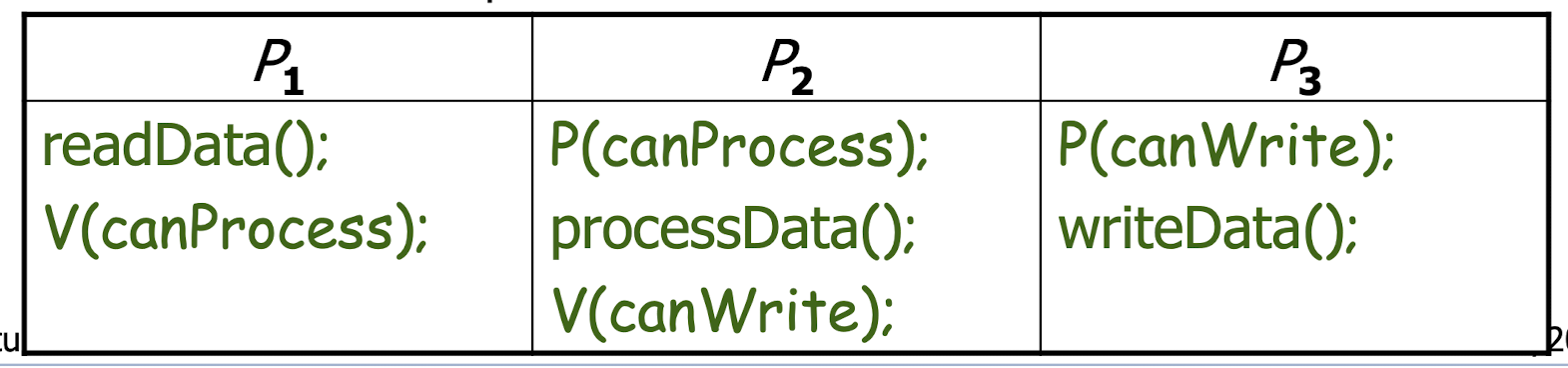
Semaphores could be used to solve other synchronization problems.
- Producer/consumer (or bounded buffer) problem.
- Dining-philosophers problem.
- Sleeping-barber problem.
- Cigarette-smoker problem.
- Readers/writers problem.
- Society-room problem.
Let us use semaphores to solve the producer /
consumer problem (bounded buffer problem) with N buffers.
- Define a semaphore to implement critical section.
- Semaphore mutex = 1;
We want a critical section to add or remove item!
Structure of producer:1
2
3
4
5
6while (True) do {
# produce an item
P(mutex); # check the buffer before go into to add
# add item to buffer
V(mutex);
}
Structure of consumer:1
2
3
4
5
6while (True) do {
P(mutex);
# remove item from buffer
V(mutex);
# consume the item
}
[Example]
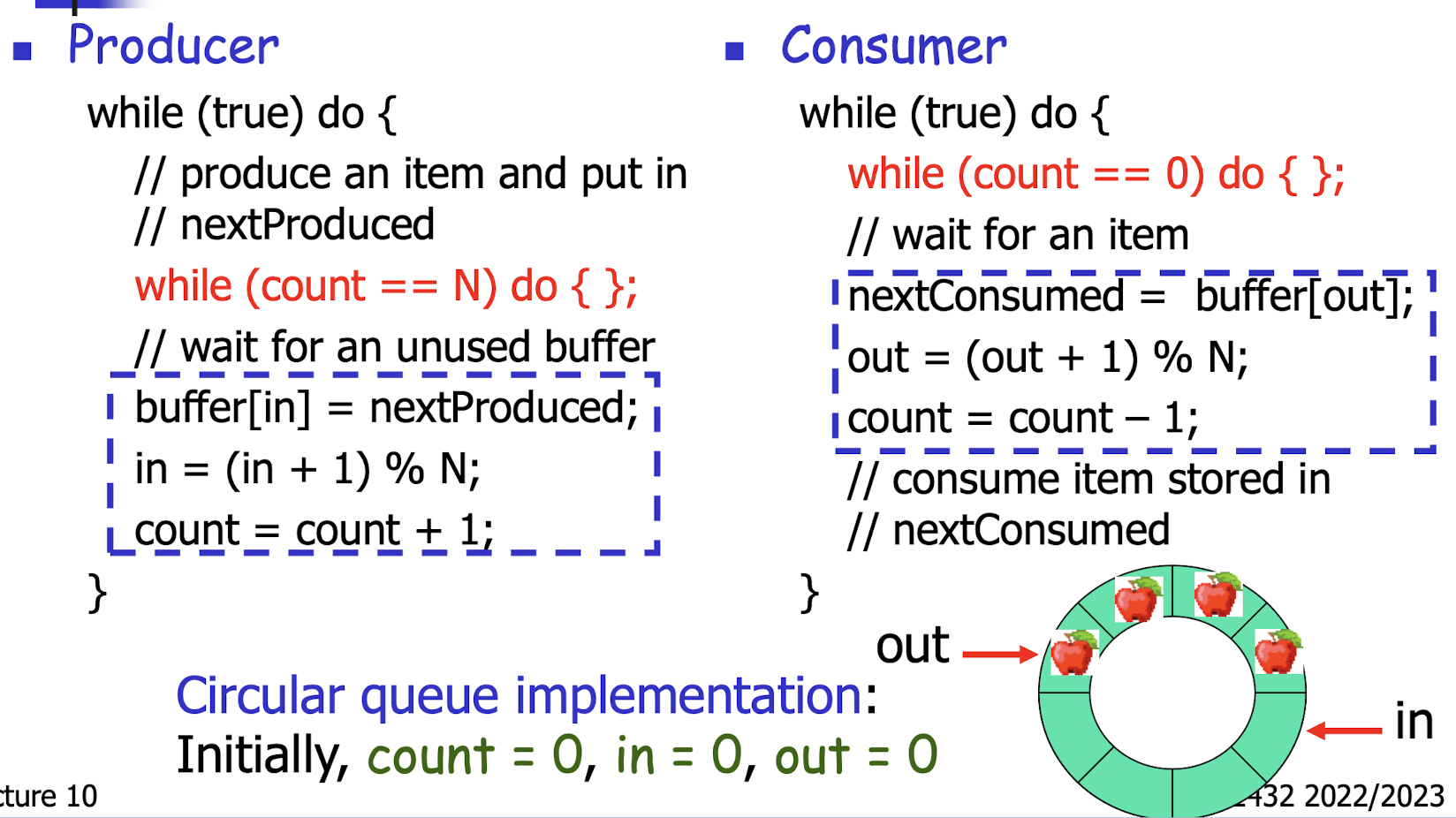
11. File System, Secondary Storage, and Protection
11.1 File
11.1.1 File Concept
A file is a named collection of related information that is stored on a secondary storage, such as a disk.
- A file is the smallest unit of allocation to the secondary storage that can be seen by a user.
- A user can only assess data stored on the secondary storage via the file.
- Information in a file is defined by its creator.
Information about files are often maintained in the directory structure.
A file system is a collection of files in an organized way, with proper storage and directory structure.
A disk may be divided into many parts.
- A part may hold an individual file system.
- This is called a partition .
Sometimes, several disks are combined together to hold one large file system. - This collection of disks is also called a partition.
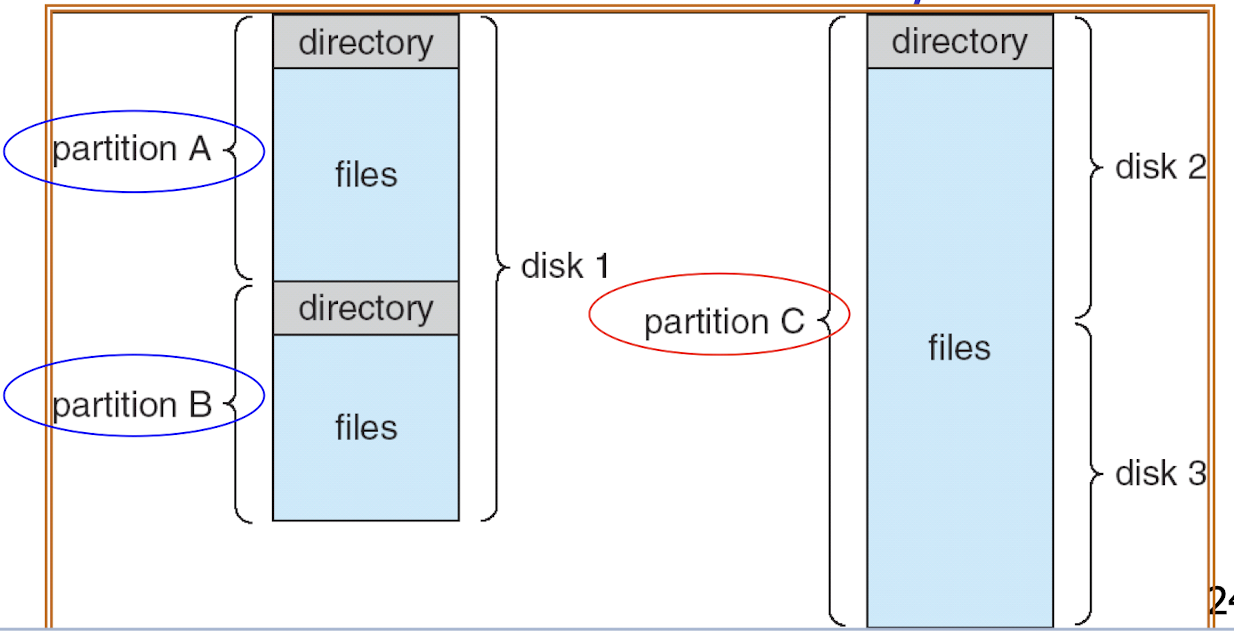
11.1.2 File Attributes
A file has many properties, described by its attributes.
- Name: textual file name, the only information that a human can read directly.
- Identifier: unique tag or number that identifies a file within the file system.
- Type: needed for systems that support different types of files, e.g. text versus binary file.
- Location: pointer to the file location on storage device.
- Size: current file size and/or maximum size (in bytes or blocks).
- User or owner identification: who creates or owns the file.
- Protection: decide on who can do reading, writing, executing.
- Time and date information: when a file was first created, last modified or last accessed.
Values of the attributes for a file are stored in the directory structure or directory entry.
11.1.3 File Operations
A file is an abstract data type (ADT), that provides a basic set of operations.
- Create: allocate storage for a file and create an entry to store the file attributes.
- Read: return data from the file, normally start reading data from the current read pointer.
- Write: store data into the file, often start from the current write pointer.
- Reposition within file: move the read and write pointers.
- Delete: remove the file entry and release the allocated storage.
- Truncate: delete all contents of the file to make it an empty file.
Besides the basic operations of reading data from and writing data to a file, two more common operations are often provided in the implementation of most file systems.
- Open: make a file ready for reading/writing.
- Actions involve searching for the file entry containing file attributes in the directory structure and moving the content of the entry into memory.
- Close: mark the completion of operation on file.
- Actions involve moving the content of the file entry in memory back to directory structure on disk.
To manage an opened file, some pieces of data have to be maintained by OS.
- File pointer: a pointer to the last read/write location.
- There is one pointer for each process that has opened the file.
- File-open count: a counter for the number of times that the file is opened.
- A file entry in memory (open-file table) can be deleted when the last process using the file closes it. This is also called the reference count (as used in Java garbage collection).
- It is similar to number of times that a pipe is closed in Unix/Linux. A process can only read the end-of-file marker when all processes close a pipe on the other end.
- Disk location of the file: where the file resides on the disk.
- A copy of this information is often stored in memory.
- Access rights: access mode that the file is opened by a process.
- There is one set of rights for each process on each file.
11.1.4 File Types
Two major types of files:
- Program files
- Source code
- Object code
- Executable program
- Data files
- Character or ASCII file
- Binary file
- Free-formatted text file
- Formatted or structured file
- There are different subtypes of files.
- They are often indicated by the file extension.
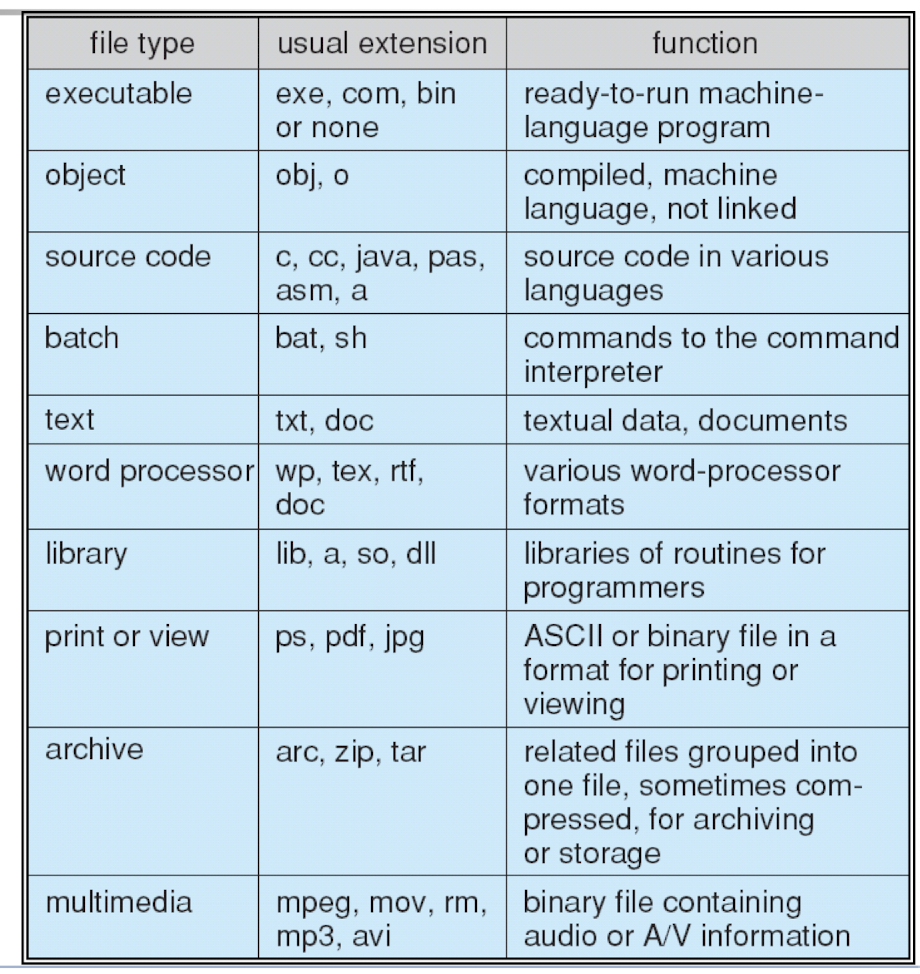
11.1.5 File Structure
A file may be structured or unstructured.
- Unstructured
- The file is just a sequence of words or bytes.
- Simple record structure
- Each record is stored in a line or a fixed number of lines.
- Fixed length records.
- Variable length records.
- Complex structure
- Formatted document.
- Relocatable load file.
Unix only supports a simple unstructured file of consecutive bytes.
- Application programs must interpret the file content by themselves.
- Magic number of a file helps with this step.
1 | |
11.1.6 Access Methods
Several methods to access data stored in a file, not all supported by all systems.
- Sequential access
- Data are accessed in order, from beginning to the end.
- Most systems support sequential access.
- Direct access
- Also called relative access.
- File is composed of fixed-length records.
- Data can be accessed directly, based on record number.
- Indexed access
- A separate index file contains pointers to the data blocks of a data file (direct file or relative file).
- Direct access to required data blocks can be achieved via searching the index.
Sequential access operations:
- Read next: return next data item and advance file pointer.
- Write next: update next data item and advance file pointer.
- Reset: put the file pointer back to the beginning.
- It is like the rewind operation.
- Skip forward/backward: move the file pointer forward without reading or move it backward.
- Backward skipping is only supported in some systems.
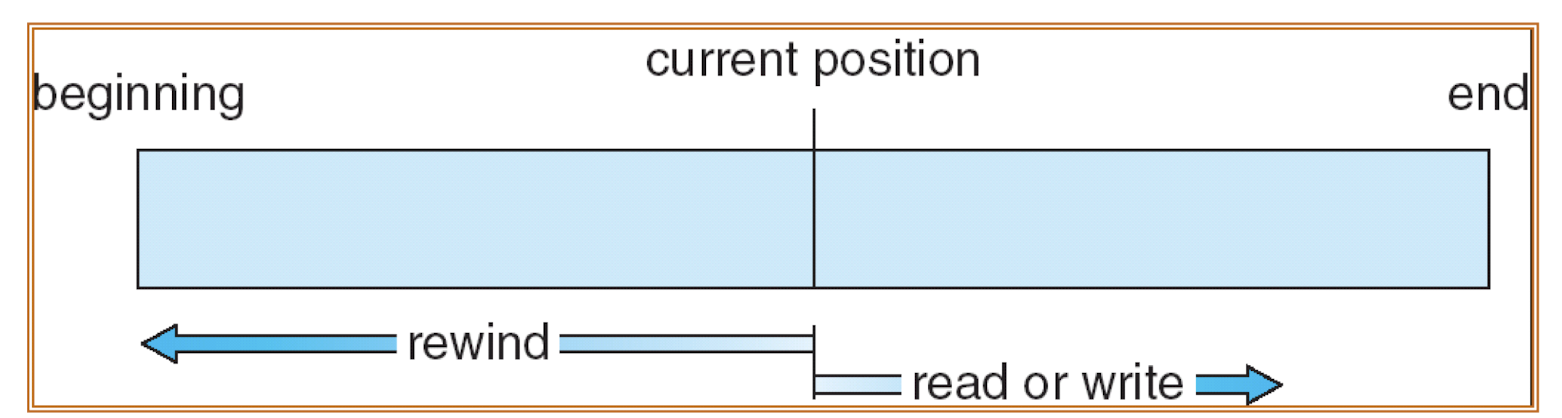
Direct access operations:
- Read n: return the n th data item or block.
- Write n: update the n th data item or block. A system that provides sequential access operations Read next and Write next can support the two direct access operations above through a new operation Position n.
- Position n: move the file pointer to the n th data item or block.
- Read n and Write n could be implemented using Position n and then Read next and Write next.
Sequential access can also be provided easily by a system that only supports direct access.
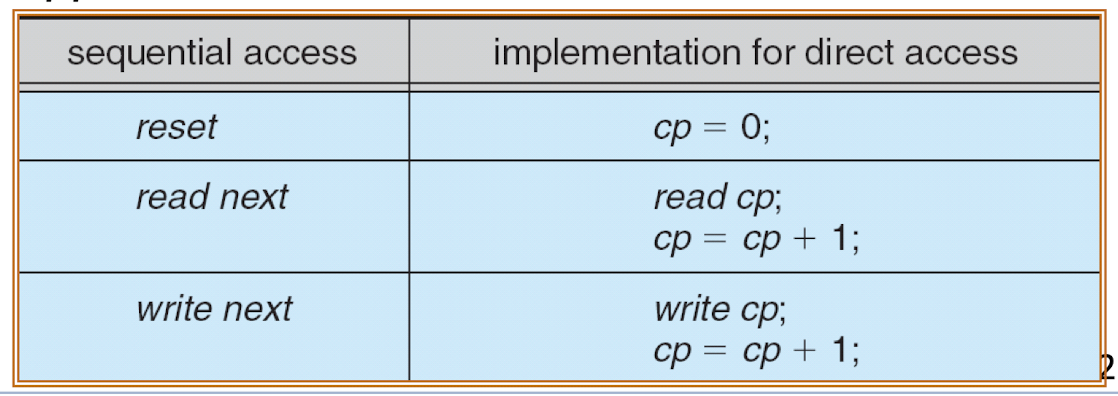
Indexed access
- Use of index allows direct access to data.
- Data is stored in a direct or relative file.
- Multiple indexes could be maintained to allow direct access to different parts of data based on the index.
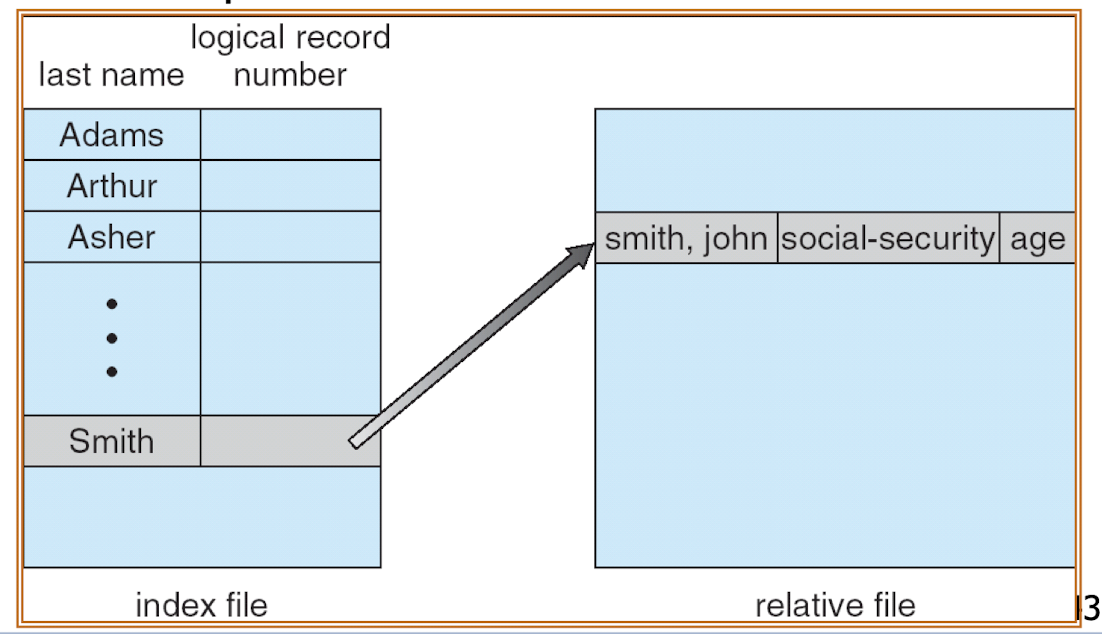
11.2 Directory
A directory is a collection of nodes or entries containing information about all files.
Both directory structure and files reside on the disk.
In Unix/Linux, the directory structure itself is implemented as a file.
11.2.1 Directory Structure
Operations on a directory:
- Search for a file: find whether a particular file exists and get its entry.
- Create a file: add a new entry for a new file.
- Delete a file: remove an entry for a file.
- List a directory: get the files in a directory and their file entries.
- Rename a file: change the name of the file inside the entry.
- Traverse the file system: access every directory and then all files within stored under the file system.
11.2.2 Single-Level Directory
A single directory for all users.
- All files are stored in a single directory.
- Adopted in old Macintosh File System.
- Advantage: simple
- Naming problem: two users may try to use the same name for different files.
- Grouping problem: how to distinguish files belonging to a user from another versus isolating only files of a particular type (e.g. batch files).
11.2.3 Two-Level Directory
Separate directory for each user.
- Each user now owns a separate one-level directory.
- A Master File Directory (MFD) contains individual User File Directories (UFD).
- Each user may create a file with same name as other users.
- Faster searching for a file and easier access control.
- More difficult for a user to access files of another user when they cooperate: access rights need to be controlled and users need to name another user’s file.
11.2.4 Tree-Structured Directories
Extend two-level directory into multiple levels like a tree.
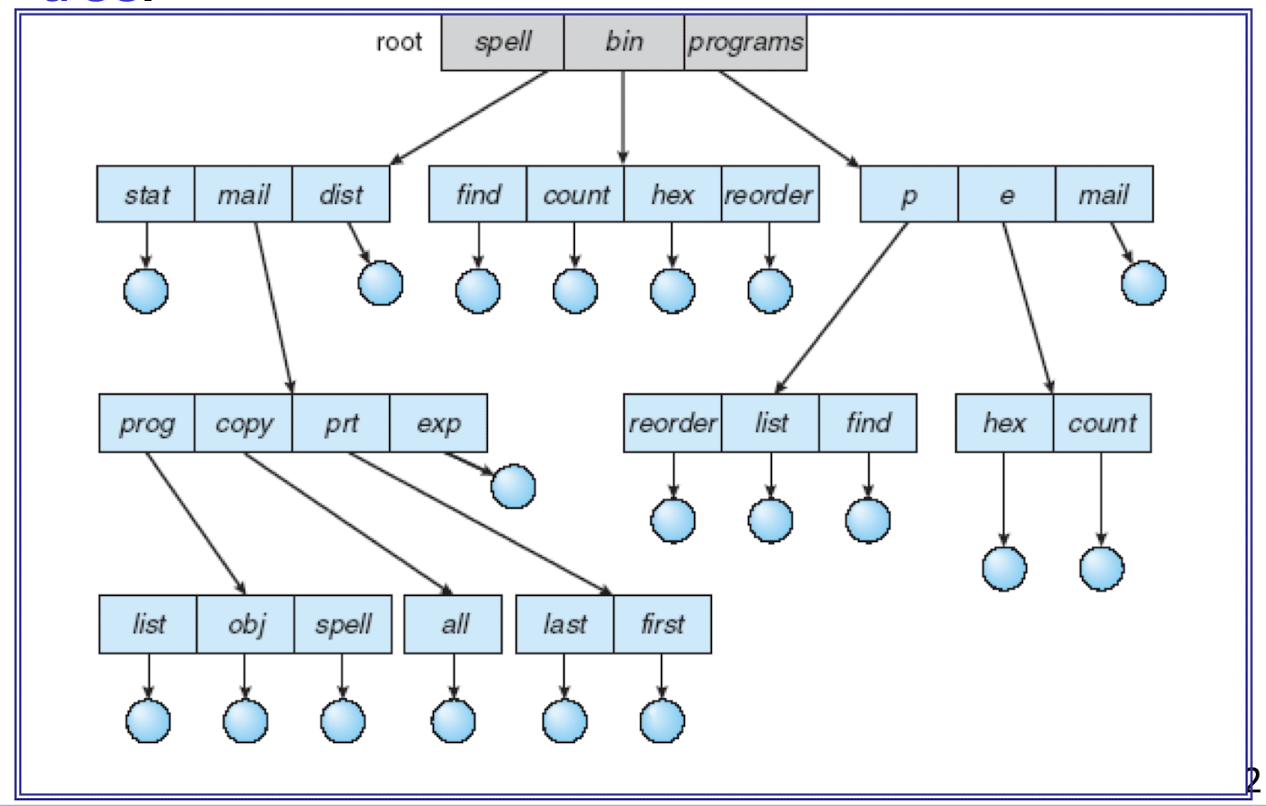
More efficient searching on even fewer files.
Grouping capability of files belonging to a particular group, e.g. files for a certain subject or with a certain nature.
A current working directory is maintained to define the default searching place for files.
- Path names should be given to locate for a file.
- Can use absolute or relative path names (from the current working directory).
Creating a new subdirectory is done in the current directory.
Deleting a subdirectory could lead to the deletion of all files under it.
Adopted in MS-DOS.
11.2.5 Acyclic-Graph Directories
Allow for shared subdirectories and files in tree- structured directories so as to form a graph.
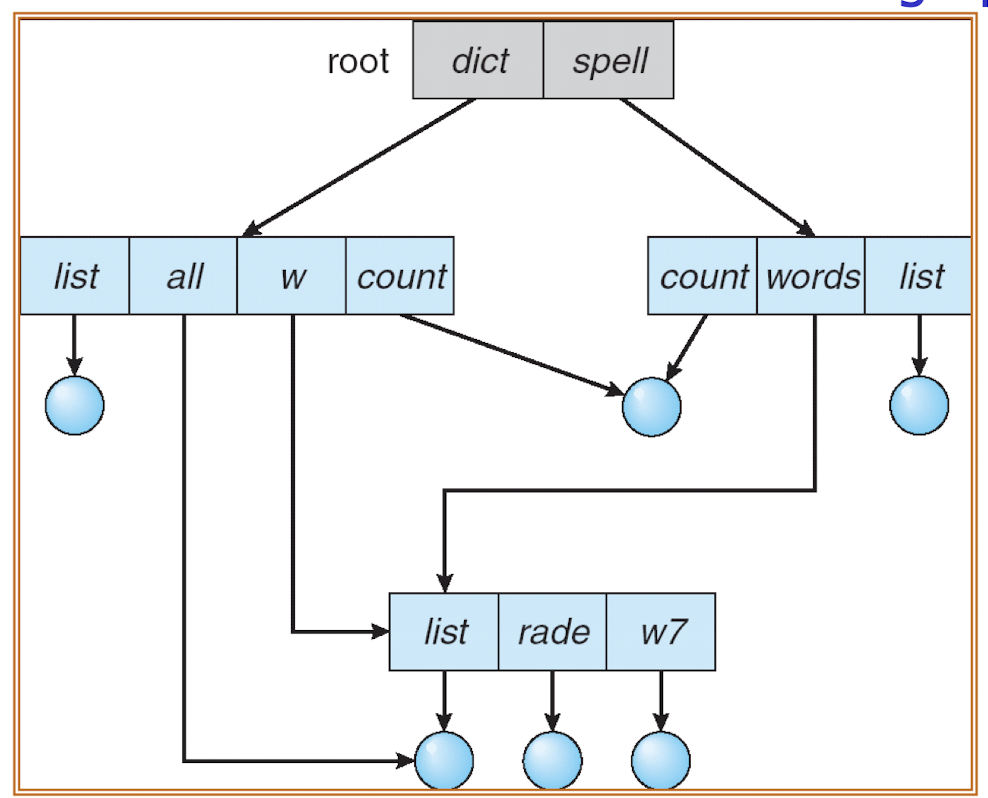
Allow for files or directories to be shared.
- File may be referenced via two different names.
- It is the same physical file (a single copy) accessible under two different names.
- This is called aliasing.
- Changing the content of the shared file via one name will cause changes to the physical file and these changes will be reflected via another name.
Aliasing of a file name could create problems.
- If we count the total number of files, the same file under two names would be double-counted.
- If the file under a name (e.g. dict/w/list) is deleted, the physical file referred by that name (dict/w/list) is deleted, but the path under the other name (spell/words/list) still exists and a user may access it through this other name.
- This is the dangling pointer problem.
- In C, you may copy a pointer to another and both pointers refer to the same memory block allocated via malloc().
- Deletion of the block via one pointer via free() will cause problem when it is accessed via the other pointer, especially the freed memory is reallocated.
Solution.
- Do not delete a file until there is no more access path (or link) to it.
- We need to keep all the access paths or links to each file.
- Instead of keeping all the links to a file, we can keep a count of the number of links. When the number of links goes to zero, the file can be deleted. This number is called the reference count.
11.2.6 General Graph Directories
Allow for cycles in directories to exist to form a general graph.
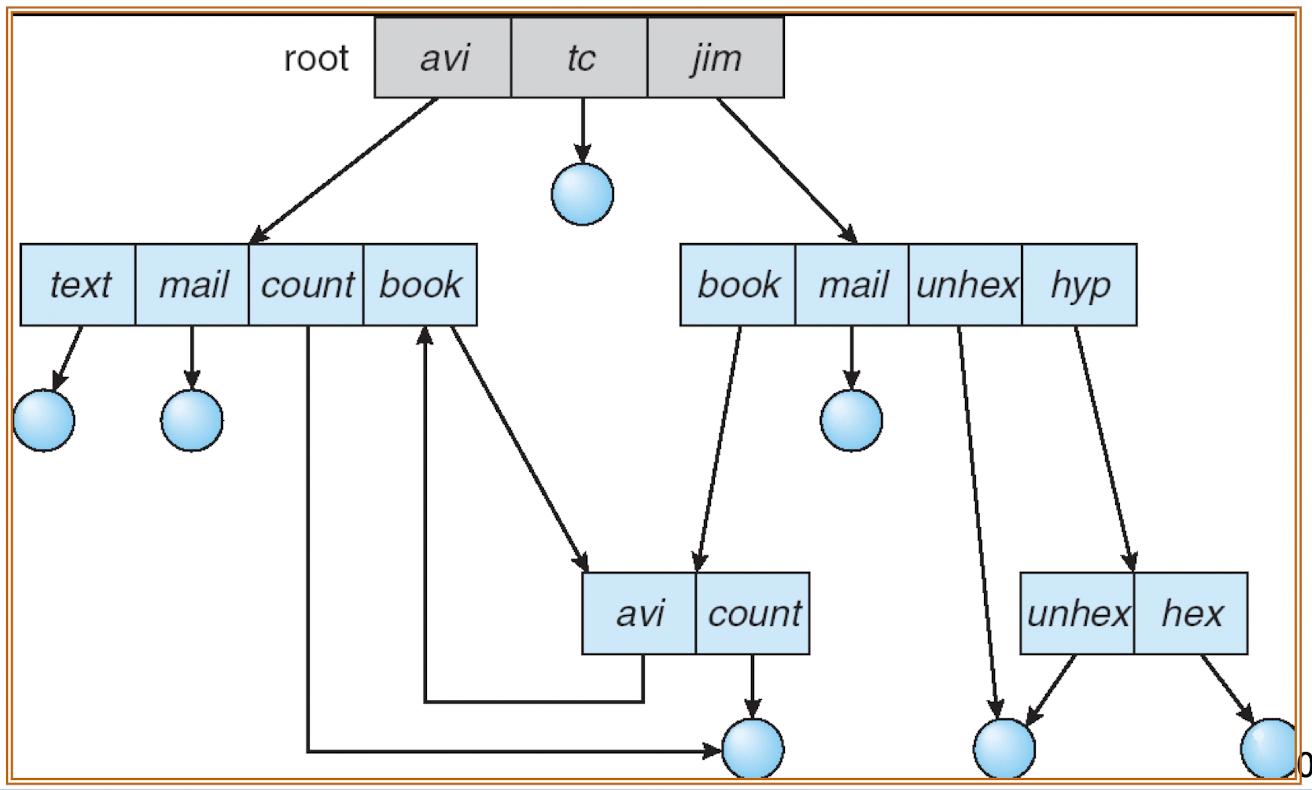
11.2.7 File Sharing
File sharing on multi-user systems is desirable.
Sharing may be done through a protection scheme.
- User IDs identify users, allowing permissions and protections to be set on a per-user basis.
- Group IDs allow users to be in groups, permitting group access rights.
With distributed systems where multiple machines are connected together via a network, files may be shared across the network.
Remote file systems use networking to support accesses to file systems under different systems.
- Manually via programs like FTP or winscp.
- Automatically using distributed file systems, e.g. transparent use of
J: driveon both PC and Unix/Linux. - Semi-automatically via the web.
Client-server model allows clients to mount remote file systems from servers.
- A server can serve multiple clients.
- Standard operating system file calls are translated into remote calls to be executed at the remote machine.
Network File System (NFS) developed by Sun (now Oracle) is a common distributed file-sharing method.
- It is the standard Unix client-server file sharing approach.
Storage-Area Network (SAN) provides large storage capacities to a large user population.
- It uses a high-speed network dedicated to the task of transporting data for storage and retrieval.
Cloud storage is the newest technology to host data in a collection of nodes over the cloud.
- Service is usually provided by third party, usually data center.
- Common storage: iCloud, dropbox, Google drive.
11.3 Storage
11.3.1 File Storage Allocation
Linked allocation
- Simple.
- Directory points to first data block.
- A pointer at the end of first data block points to a second data block and so on.
- Only efficient for sequential access, but bad for random access.
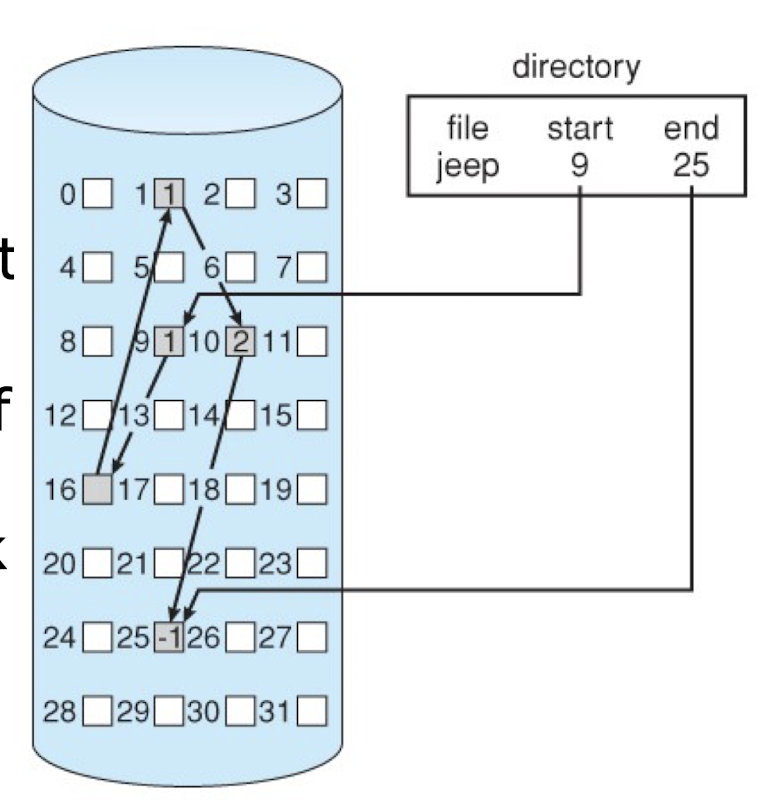
Indexed allocation
- Combine all indexes for accessing each file into a common block.
- Can store them in a FAT table.
- More efficient for random access.
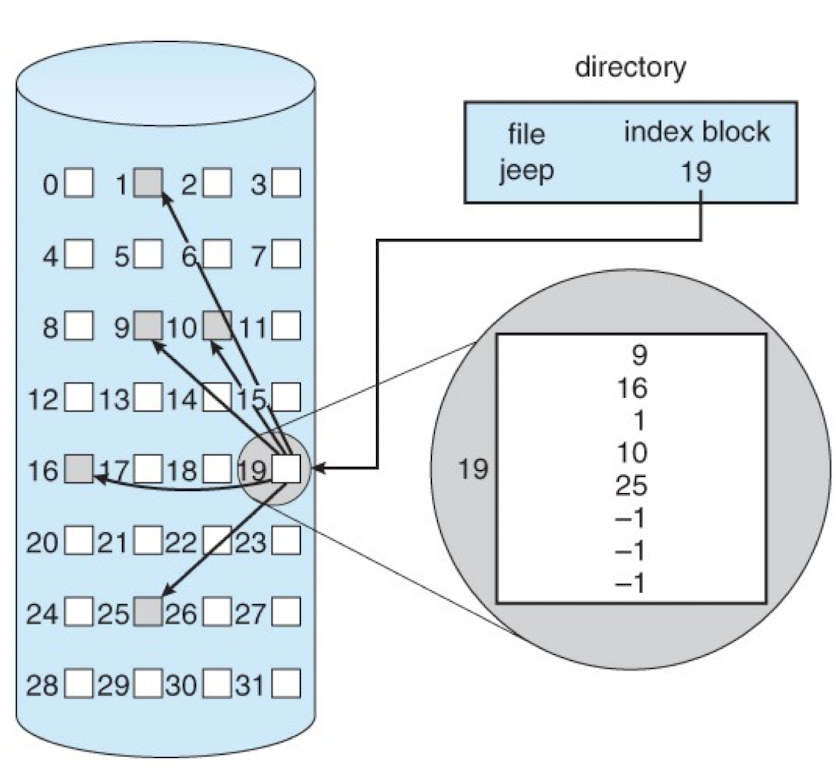
11.3.2 Secondary Storage
Recall that a file is a named collection of related information that is stored on a secondary storage, such as a disk.
Secondary storage refers to storage outside memory.
- Magnetic drum
- Magnetic tape
- Hard disk
- Solid State Drive (SSD)
- Networked disk / storage
Secondary storage can also be configured to store data in specialized format, e.g. information in a database
11.3.3 Disk Storage
A computer system can access its local storage (local disk / local drive), or storage over the network (remote disk / network drive).
- Local storage is easy to use, but it cannot be shared easily. You may install dropbox or Foxy to allow external access, but you may lose control over who can access what.
- Remote storage is flexible, but it relies on the availability of network. How do you like a Netbook?
Three major types of disk storage organization.
- Host-attached storage
- Network-attached storage
- Storage-Area network
11.3.4 Host-Attached Storage
This is the most standard arrangement. Storage is directly attached to computer and is accessed via I/O port.
- IDE or ATA hard disk (at most 2 per I/O bus).
- SCSI hard disk (at most 16 per I/O bus).
To improve fault-tolerance, i.e. to make hard disk surviving disk failure, one could use mirror hard disk.
- Two hard disks writing the same data simultaneously. Primary hard disk provides read/write and secondary (mirror) hard disk serves as data backup.
- If primary fails, secondary can provide data for reading.
- Simple, but expensive.
Mirror hard disk arrangement can be generalized into RAID (Redundant Array of Inexpensive Disk).
- There are 7 levels of RAID: RAID 0 to RAID 6.
- Improved parallelism for data access, and fault-tolerance over single hard disk for RAID 1 to RAID 6.
RAID 0 means nothing.
- No overhead
RAID 1 means mirror.
- 100% overhead
RAID 5 is the most commonly adopted.
- 1/n overhead for n data disks.
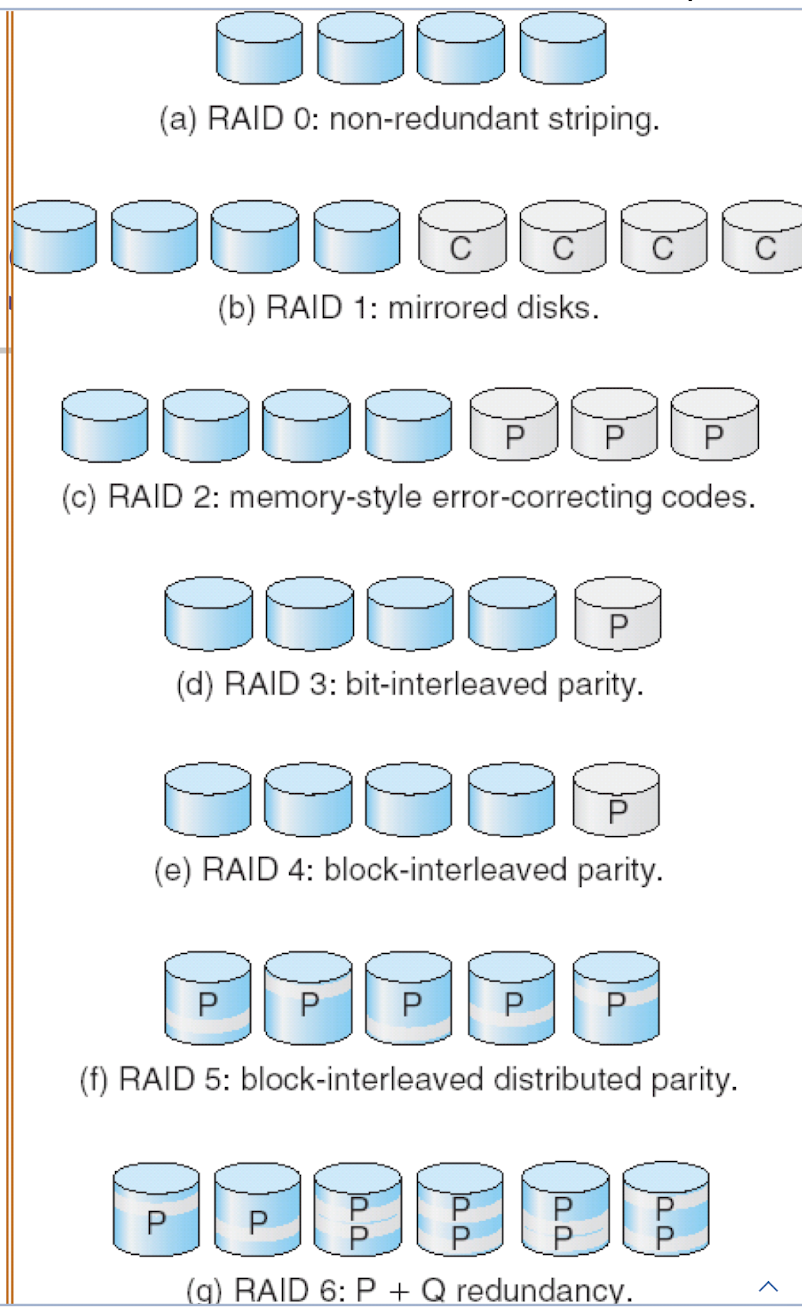
11.3.5 Network-Attached Storage
Network-attached storage (NAS) is a special purpose storage system accessible over the network.
- The same network is used for normal networking operation and accessing remote data.
Unix NFS (Network File System) is often NAS-based.
- Remote procedure call can be used to access file content.
- NFS makes remote file access transparent to a user.
Departmental storage had also been NFS-based.
- In Unix/Linux, compare access to local files under /tmp and remote files under /home/12345678d.
- You may not see any difference, but when the network is slow, you will notice a difference.
11.3.6 Storage-Area Network
Storage Area Network (SAN) is a current technology to provide large storage to a large user population.
- Instead of sharing the same network with other services, it has a high-speed private data network dedicated to the task of transporting data for storage and retrieval.
- Operate on special storage protocols, not network protocols.
- Connect together computers and storage devices to allow sharing of the pool of storage devices.
- Adopted by large institutions, e.g. J: drive attached to SAN.
11.3.7 Tertiary Storage
Primary storage refers to memory: directly accessible by CPU.
Secondary storage refers to hard disk or SSD: needs to access via I/O bus and DMA to bring into memory for usage.
Tertiary storage refers to CD-ROM and DVD: accessible via I/O bus only if they are placed inside the disk drive.
This forms the hierarchical storage structure, increasing in capacity, increasing in access time, but decreasing in cost.
- To complete this hierarchy, cache memory sits between primary memory and CPU.
- Virtual memory frame sits between secondary disk and memory.
- Temporarily cached file sits between tertiary storage and local disk.
Tertiary storage is used to store gigantic amount of data, e.g. video recorded via surveillance cameras, traffic monitoring images, medical images, SETI signals, data gathered by CERN
LHC (Large Hadron Collider).
Tertiary storage is commonly used for backup and
more for archival, targeted at storing for 100 years.
- Large storage and slow access in storage hierarchy.
Robotic optical jukebox allows fast insertion of a selected DVD from a collection of cartridges of DVDs to the disk drive to support tertiary storage - A cartridge can hold 30 to 50 discs, with 20 to 40 cartridges.
- A quad layer Blu-ray disc can store 128GB, with future technology storing 200GB.
- A storage unit could hold more than 100 discs.
- This is commonly used in many companies to store large amount of information, e.g. banks.
- Access time is about 5 to 10 seconds from jukebox to load.
Offline-storage physically isolates the storage to sustain disasters like fire or earthquake.
11.4 Protection
Protection
- Mechanisms and policy to keep programs
and users from accessing or changing stuff they should not do. - Issues internal to Operating System.
Security
- Authentication of user, validation of
messages, malicious or accidental introduction of flaws, etc. - Issues external to Operating System.
11.4.1 Protection
OS consists of a collection of objects (hardware or software resources), each has a unique name and can be accessed through a well-defined set of operations.
Goal:
- To ensure that each object is accessed correctly and only by those processes that are allowed to do so.
Guiding principles: - Principle of least privilege
- Programs, users and systems should be given just enough privileges to perform their tasks.
- Limit damage if entity has a bug or gets abused.
- Can be static (during life of system or process) or dynamic (changed by process as needed, e.g. domain switching, privilege escalation).
- Separate policy from mechanism
- Mechanism: the stuff built into the OS to make protection work.
- Policy: the information that says who can do what to whom.
A domain structure is built for protection of resources or objects.
A process should be allowed to access only those resources that it has authority.
A process should only access those resources that it requires currently to complete its task.
- This is called the need to know principle.
- Damage is limited in case of a bug in the process, like the process boundary limit enforced in memory management.
A process operates within a protection domain to access an object.
- This process inside a domain is often considered a subject.
11.4.2 Domain
A domain specifies a set of objects and their operations.
The ability to execute an operation on an object is an access right to the object.
A domain is a collection of objects and their associated access rights.
Access-right = <object-name, rights-set>
- The rights-set is a subset of all valid operations that can be performed on the object

11.4.3 Access Matrix
Access control is achieved via access matrix.
View protection need as a matrix.
- Rows represent domains.
- Columns represent objects.
Access(i, j) is the set of operations that a process executing in Domain i can invoke on Object j.
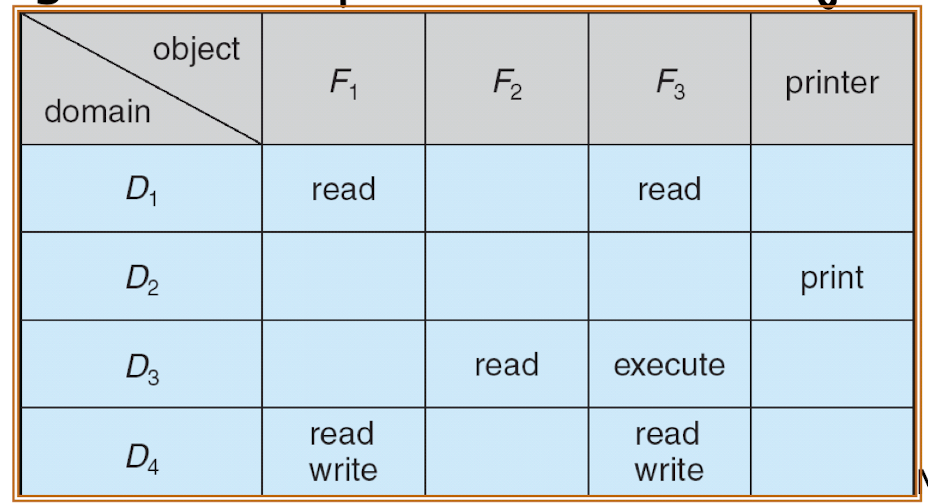
If a process in Domain Di tries to do “op” on object Oj, then “op” must be in the access matrix.
User who creates object can define access column for that object.
Can be expanded to dynamic protection.
- Operations to add, delete access rights.
- Special access rights:
- owner of Oi
- copy op from Oi to Oj (denoted by “*”)
- control – Di can modify Dj access rights
- transfer – switch from domain Di to Dj
- Copy and Owner applicable to an object.
- Control applicable to domain object.
Access matrix design separates mechanism from policy.
- Mechanism: OS provides access matrix and rules and ensures matrix is only manipulated by authorized agents and rules are strictly enforced.
- Policy: user dictates policy on who can access what object and in what mode.
11.4.4 Implementation
Global table
- Store ordered triples
<domain, object, rights-set>in table. - Check for < Di, Oj, Rk > to execute operation M on object Oj within domain Di.
Access control lists for objects
- Each column implemented as an access list for one object.
- Resulting per-object list consists of ordered pairs
<domain, rights-set>. - defining all domains with non-empty set of access rights for the object.
Capability lists for domains
- Each row implemented as a capability list for one domain.
- Object represented by its name or address, called a capability.
- To execute operation M on object Oj, process requests operation and specifies a possessed capability as parameter.
- A capability is like a “secure pointer” implemented by OS and is accessed indirectly.
11.4.5 Protection on File Systems
Files should be protected against indiscriminated or unauthorized access.
File owner or creator should be able to control:
- What operations can be executed on the file.
- Who can perform operations on the file.
Types of access to control:
- Read: read the file.
- Write: write the file.
- Execute: load and execute the file.
- Append: add new information to the end of the file.
- Delete: remove the file and free its space.
- List: give the name and attributes of the file.
Most common mechanism is Access Control List.
- Each file is associated with a list, showing who can do what.
In Unix/Linux:
- There are three modes of accesses: read, write, execute.
- There are three classes of users: owner, group, other (public or universe).
- For example, the command chmod 751 myfile will define the access control list on myfile to be something like
<owner: read, write, execute><group: read, execute><other: execute>
A group is defined by the OS (as instructed by the system administrator)
Users are added to the group by the administrator, e.g. students can be classified into groups of year1, year2, year3, year4.
12. Security and Case Studies
12.1 Protection and Security
Protection
- Mechanisms and policy to keep programs and users from accessing or changing stuff they should not do.
- Issues internal to Operating System.
Security
- Authentication of user, validation of messages, malicious or accidental introduction of flaws, etc.
- Issues external to Operating System.
System is secure if resources are used and
accessed as intended under all circumstances.
Problems:
- Intruders (or crackers) attempt to breach security.
- A threat is a potential security violation.
- An attack is an attempt to breach security.
Attack can be accidental or malicious.
It is easier to protect against accidental than malicious misuse.
Security Violation Categories
Breach of confidentiality
- Unauthorized reading of data.
Breach of integrity
- Unauthorized modification of data.
Breach of availability
- Unauthorized destruction of data.
Theft of service
- Unauthorized use of resources.
Denial of service (DOS)
- Prevention of legitimate use.
- Distributed DOS (DDOS) becomes common in recent years
through internet.
Breaching Security
Masquerading
- Pretending to be an authorized user to escalate privileges.
Replay attack
- Save a previous message and replay it or with message modification.
Man-in-the-middle attack
- Intruder sits in data flow, masquerading as sender to receiver and vice versa.
Session hijacking
- Intercept an already-established session to bypass authentication.
Program Threats
Trojan horse
- Code segment that misuses its environment.
- Exploits mechanisms for allowing programs to be executed by other users.
- Spyware, pop-up browser windows, covert channels.
Trap door
- Specific user identifier or password that circumvents normal security procedures.
Logic bomb
- Program that initiates a security incident under certain circumstances.
Stack and buffer overflow
- Exploits a bug in a program (overflow either stack or memory buffers): gets() in C.
- Write past arguments on stack into return address on stack.
- When routine returns from call, returns to hacked address.
Viruses
- Code fragment embedded in legitimate program.
- Self-replicating, designed to infect other computers.
- Very specific to CPU architecture, operating system, applications.
- Usually borne via email or as a macro.
Security Measure Levels
It is impossible to have absolute security, but should make cost high enough to deter most intruders.
Security must occur at four levels to be effective.
- Physical level
- Data centers, servers, connected terminals
- Human level
- Avoid social engineering, phishing, dumpster diving
- Operating system level
- Protection mechanisms, debugging
- Network level
- Intercepted communications, interruption, DOS
Security is as weak as the weakest link in the chain.
- Very often this weakest link is the human!
Cryptography
Cryptography allows transforming data (text) into something not readable by outsiders (ciphertext) without secret key.
It is the broadest security tool available.
OS and information inside a computer could be trusted.
- Create, manage, protect process ID, communication port.
- Internal to computer, source and destination of messages are known and protected.
Source and destination of messages on network cannot be trusted without cryptography.
- Local network – IP address?
- WAN / Internet – how to establish authenticity
Cryptography can constrain potential senders (sources) and / or receivers (destinations) of messages.
- Enable confirmation of source, receipt only by certain destination, trust relationship between sender and receiver.
Authentication
Authentication is the act of confirming the truth of an attribute of a single piece of data claimed true by an entity.
- It is most often related to the confirmation of a person or an agency on network.
It can be used to constrain set of potential senders of a message, and to prove that message is unmodified.
Closely related to and complementary to cryptography.
Proving you are who you claim by
- Knowledge factor: something you knows, e.g. password, PIN, challenge response, security question.
- Ownership factor: something you own, e.g. ID card, octopus card, cell phone with built-in hardware token, digital certificate.
- Inherence factor: something you are, e.g. fingerprint, palm print, retinal pattern, face, voice.
Information Security
Measures taken to prevent unauthorized use of electronic data, including disclosure, alteration, substitution, or destruction of the data concerned.
It goes beyond just the OS, the computer system, the network, to the full application environment.
Three major requirements: CIA
- Confidentiality: concealment of data from unauthorized parties.
- Integrity: assurance that data is genuine.
- Availability: system still functions efficiently with security provisions.
Another common requirement is non-repudiation, i.e. you cannot deny you have done something, e.g. sending a signed message, having purchased a product.
Lab & Tut
1. Processes in Unix / Linux

2. Unix / Linux Signals
Signal Number (N) | Signal Constant | Description
2 | SIGINT | Interrupt from keyboard (Ctrl-C), same as kill -2 PID
3 | SIGQUIT | Quit terminal
4 | SIGILL | Illegal instruction
8 | SIGFPE | Floating point error
9 | SIGKILL | Kill process, strongest kill signal, can not be ignored
11 | SIGSEGV | Segmentation fault, invalid memory reference
13 | SIGPIPE | Pipe without reader
15 | SIGTERM | Terminate process, same askill PID
3. Signal Handling
signal(): to install the signal handler to the program before it takes effect.
1 | |
Reset the signal handler back to its default setting:
Use SIG_DFL as the second argument of signal():
signal(SIGXXX, SIG_DFL)
1 | |
To ignore the signal
Use SIG_IGN as the second argument of signal():
signal(SIGXXX, SIG_IGN)
1 | |
KILL signal (kill -9) CANNOT be caught nor ignored, as designed by Unix / Linux systems.
4. Useful Shell Command
alias:
- make ls behave like what you like by setting an alias for the command:
1 | |
hardware platform that you are using:
1 | |
detail of the hardware platform:
1 | |
full name of your machine:
1 | |
command prompt is defined within the variable PS1
\u \h:${PWD}$:
\umeans the user name (whoami)\hmeans the machine name (hostname)- variable PWD in the current shell.
[Example]
export PS1="Mickey@\h:"
- Mickey@apollo2:
export PS1="($PWD) $(whoami)-"
- (/home/12345678d) 12345678d-
export PS1="$(uname)@\h [\!]:"
- Linux@apollo2 [30]
- 30 is the current command number, you could type
An environment variable can be created via the export
remove the environment variable by the unexport command.
export PATH="$PATH:.": This command has the effect of inserting the current directory “.”
PATH: the environment variable that contains the list of directories to search for executable files.
5. Processing Exit Status
Between 0 and 255, 0 means success, and non-0 means some failure.
$?: in bash that will store the exit status of the command or process just executed.
- 127: command not found
- 139: segmentation fault
- 136: arithmetic error
-1 = 255, 0 = 256.
References
A. Silberschatz, Peter Baer Galvin, and G. Gagne, Operating system concepts. Hoboken (Nj): Wiley, Cop, 2018.
Slides of COMP2432 Operating Systems, The Hong Kong Polytechnic University.
个人笔记,仅供参考
PERSONAL COURSE NOTE, FOR REFERENCE ONLY
Made by Mike_Zhang