Introduction to Data Analytics Course Note
Made by Mike_Zhang
所有文章:
Introductory Probability Course Note
Python Basic Note
Limits and Continuity Note
Calculus for Engineers Course Note
Introduction to Data Analytics Course Note
Introduction to Computer Systems Course Note
个人笔记,仅供参考
FOR REFERENCE ONLY
Course note of COMP1433 Introduction to Data Analytics, The Hong Kong Polytechnic University, 2022.
Mainly focus on
Mathematical tools for data analytics
- Probability and Statistics;
- Calculus (differentiation and integration);
- Linear Algebra (vector and matrix basics);
Programming with R language
- Basics;
- Data Input and Manipulation;
- Statistics;
- Data Analytics.
1 An Introduction
1.1 Probability & Statistics

1.2 Calculus Preliminary

1.3 Derivatives of Common Functions
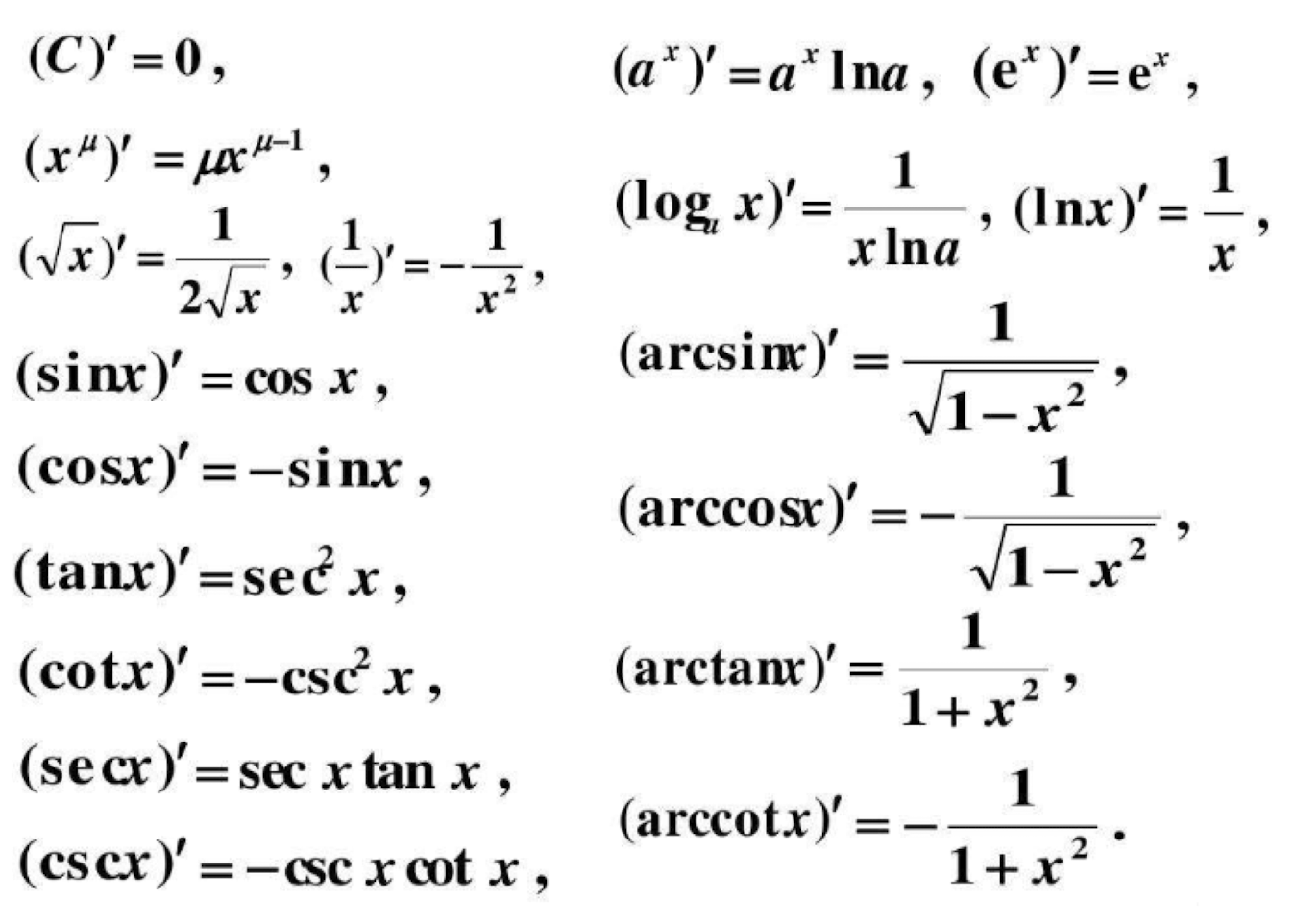
1.4 Matrix Product

2 Probability
2.1 Sample Space
- The set of all possible outcomes of an experiment.
2.2 Event
- Subsets of the sample space.
2.3 Frequency
Run a random experiment $n$ times, during which an event $A$ occurs $m$ times:
frequency of $A$’s occurrence is
2.4 Probability
a numerical description of how likely an event is to occur and or how likely that a proposition is true.
The probability of $A$ occurs:
- $0\le P(E)\le 1$ for each even $E$;
- $P(S)=1$;
If the events, A and B, are disjoint events(mutually exclusive), the probability that either event occurs is
2.5 Conditional Probability
The probability of an event $A$ given that an event $B$ has occurred, is called the conditional probability of $A$ given $B$ and is denoted by the symbol $P(A|B)$ and read as ‘the probability of $A$ given that $B$ has already occurred.
If $A$ and $B$ are two events with $P(A)\neq 0$ and $P(B)\neq 0$,then
The probability that both of the two events $A$ and $B$ occur is
2.6 Law of Total Probability
Assume that $B_1,B_2,…,B_n$ are collectively exhaustive events where $P(B_i)\gt 0$, for $i=1,2,…,n$ and $B_i$ and $B_j$ are mutually exclusive events for $i\neq j$.
Then for any event $A$:
2.7 Bayes’ Formula
Inverts the conditioning

Suppose that $B_1,B_2,…,B_n$ are n exhaustive events and exhaustive events, then:
$\because P(B_k\cap A) = P(B_k)\cdot P(A|B_k) $
$ \text{ :based on the Conditional Probability}$
$\text{,and }P(A)=P(B_1)P(A|B_1)+P(B_2)P(A|B_2)+…+P(B_n)P(A|B_n) $
$\text{based on the Law of Total probability}$
2.8 Independent Events
knowing $F$ occurred doesn’t change the probability of $E$:
In this case:
2.9 Text Classification
- Learn: text map to labels.
2.10 Naïve Bayes classifier
Bayes’ Rule Applied to Documents and Classes (Multinomial Naive Bayes)
- A generative and linear classifier.
- Naive Bayes classifier has many assumptions including ignoring the words order and words are independent with each other, which makes it does not exhibit high accuracy.
$d$: document;
$c$: class;
To get the maximum value of $P(c|d),c \in C$, which means given the document $d$, find its class with the maximum probability.
The goal: to get the maximum value of
which is
$MAP$ is maximum a posteriori = most likely class,
Bayes’ Formula,
where $P(d)$ is not related to $c$,
where $d$ is represented with $x_1,x_2,…,x_n$, e.g. words in an email,
and $P(c)$ is the frequency of occurrence of this class, by count the relative frequencies, e.g. the frequencies of normal emails and spam emails,
Based on:
Bag of Words assumption: Assume position doesn’t matter;
Conditional Independence: Assume $P(x_j|c_j)$ are independent;
then,
therefore
then for all words:
$positions$ = all word positions in the test document
for $(1)$,
Multiplying floating point numbers may cause underflow loss,
then based on,
then for $(1)$,
- For the maximum likelihood estimates $P(c_j)$:
Get the frequencies of the class appear in the dataset.
- For the Parameter estimation $P(w_i|c_j)$:
($V$ is the vocabulary maintaining all the words used for classification in dataset we trained)
Get the frequencies of the word $w_i$ appears within all word in the dataset with class $c_j$.
Problem:
No training of some words will lead the result to 0 directly, which is improper.
Solution:
Laplace (add-1) Smoothing for Naive Bayes
Problem:
For the Unknown word.
Solution:
Ignore them, remove them from the test document
Problem:
Deal with the stopwords(e.g.,
the,a)
Solution:
Sort the whole vocabulary by frequency in the training, call the top 10 or 50 words the stopwords list, and remove them from the dataset.
It’s more common to ignore stopwords lists and only use all the words.
2.11 Tutorial: Exercises - Discrete Random Variables
[Example]

[Solution]

PMF: Probability Mass Function

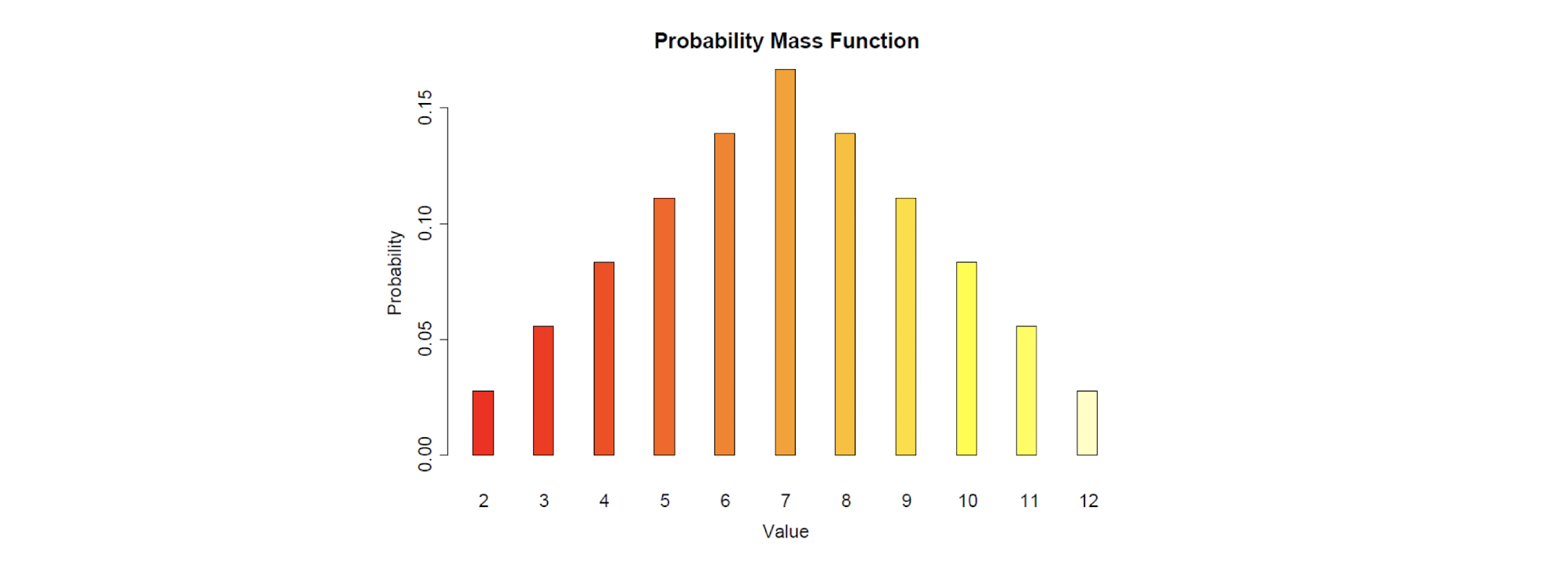
CDF: Cumulative Distribution Function

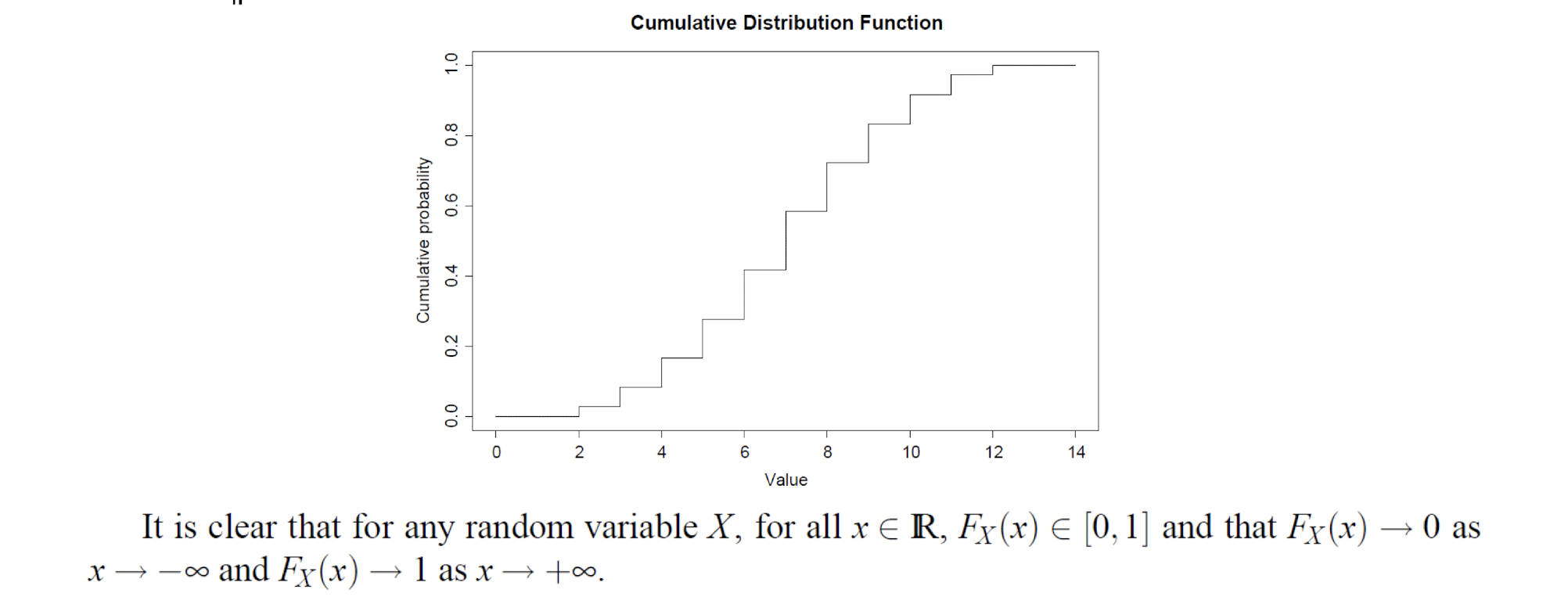

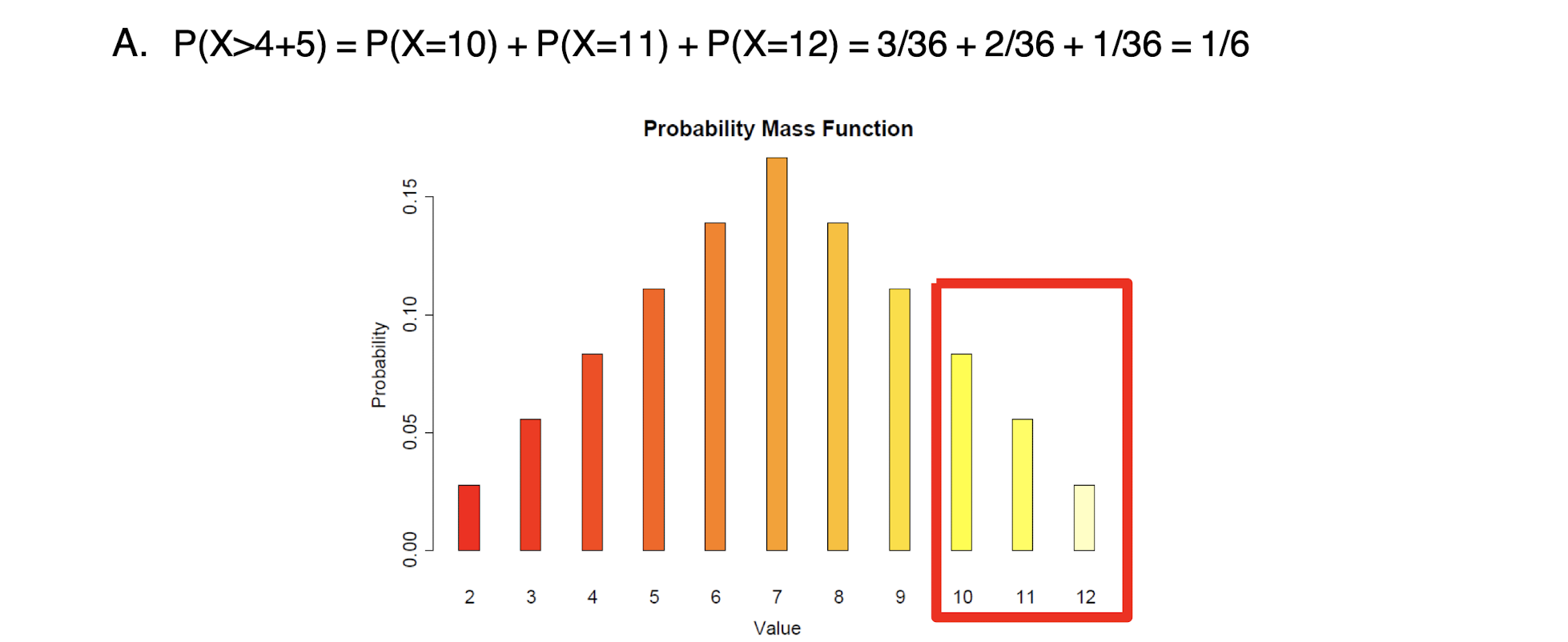
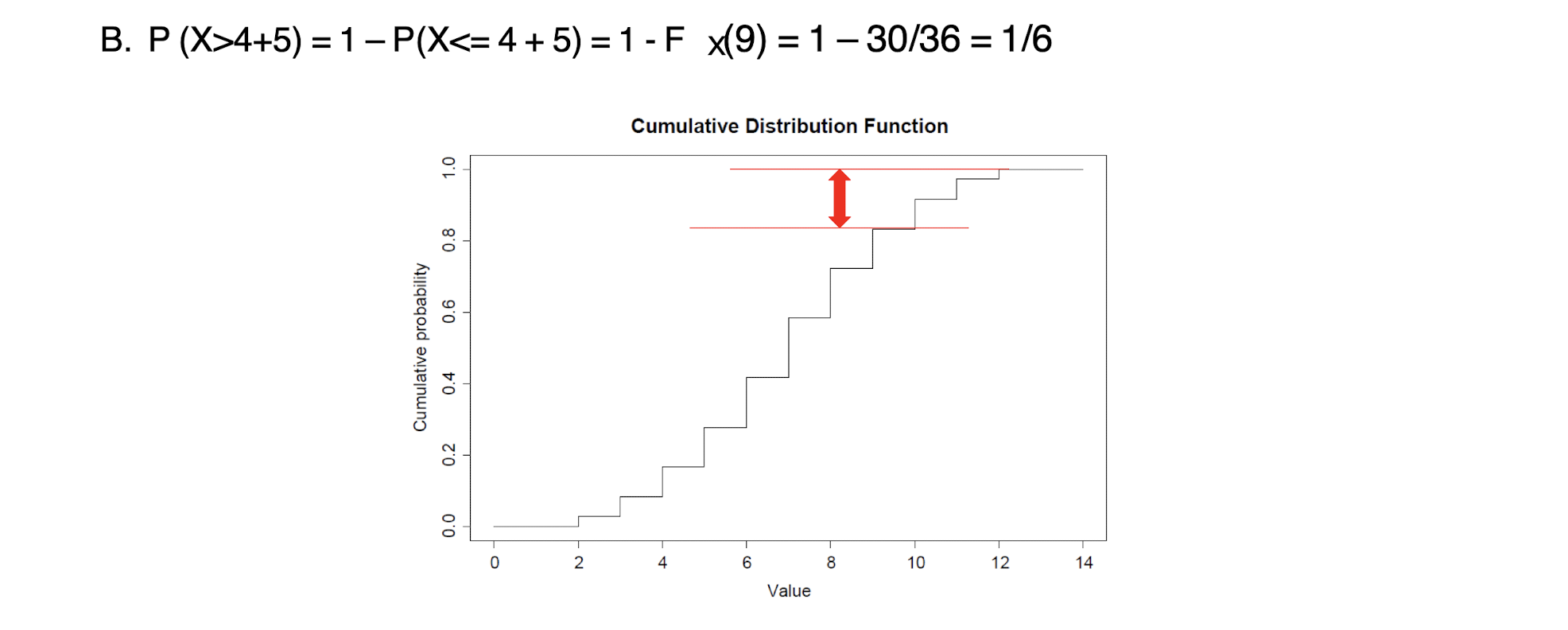
3 Statistics Basics for Data Analytics
3.1 Expectation of Random Variables
Mean of $X$
the weighted average sum of $X$
- $E[aX]=aE[X]$
- $E[aX+b]=aE[X]+bs$
For the probability density function(PDF) $f(x)=P(X=x)$:
3.2 Variance and Standard Deviation of Radom Variables
$\mu = E[X]$
the Variance:
The weighted square distance from the mean.
the Standard Deviation:
The weighted distance from the mean.
For the probability density function(PDF) $f(x)=P(X=x)$:
3.3 Sample Statistics
Assumptions:
- The population is infinite (or very large).
- The observations are independent.
Statistic itself is a random variable
3.3.1 Sample Mean
3.3.2 Sample Variance and Standard Deviation
Sample Variance:
Standard Deviation:
3.3.3 Other of Sample Statistics
- order statistic: observation are ordered in size;
- sample median:
- $n$ is odd: mid-value of the order statistic;
- $n$ is even: average of the two middle values;
- sample range: Max - Min
3.3.4 Expected Value and Variance of Sample Mean
Sample Mean:
It is also a Radom Variable.
The Expected value of Sample Mean:
The Variance of Sample Mean:
($n\to +\infin \implies \sigma_{\bar{X}}^2 \to 0$)
[Proof]
Set:
Then:
3.3.5 Markov Inequality and Chebyshev’s Inequality
Markov Inequality:
$X\ge 0,\epsilon \gt 0$
[Proof]
Chebyshev’s Inequality:
[Proof]
$P(|X-\mu |\ge \epsilon)=P((X-\mu )^2\ge \epsilon^2)\le \frac{E[(X-\mu )^2]}{\epsilon^2}=\frac{\sigma^2}{\epsilon^2}$
3.3.6 Law of Large Number
According to the Chebyshev’s Inequality:
then, for any random variables:
for $n\to +\infin,\; P(|X-\mu |\ge \epsilon)=1,\; \forall \epsilon \gt 0$
Means the sample mean approximates the population mean for very large $n$.
3.3.7 General and Standard Normal
$X$ is general normal, $X\sim N(\mu ,\sigma^2)$
Properties:
- $E[X]=\mu$
- $Var(X)=\mu^2$
- $\frac{X-\mu}{\sigma}\sim N(0,1)$
when $\mu =0,\sigma=1$:
$X$ is standard normal, $X\sim N(0,1)$
3.3.8 Central Limit Theorem
Sample Mean:
The Expected value of Sample Mean:
The Variance of Sample Mean:
$\bar{X}$ is approximately general normal (or satisfies normal distribution) for very large $n$.
$\frac{X-\mu_{\bar{X}}}{\sigma}=\frac{X-\mu}{\frac{\sigma}{\sqrt{n}}}$ is approximately normal normal for very large $n$.
3.3.9 Confidence Interval Estimate
For the continuous random variable $X$, $\forall x \in \Bbb{R}$
So $X\sim N(0,1)$
For thr cumulative distribution function:
or,
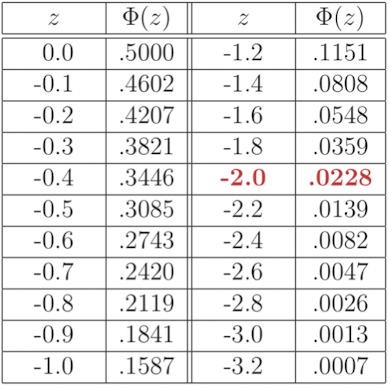

Then for $\frac{X-\mu}{\frac{\sigma}{\sqrt{n}}}$ is approximately standard normal for very large $n$.
[Example]

3.3.10 Hypothesis Testing
[Example]

[Example]

For hypothesis $H$, p-value = $p$;
We accept $H$ at the level of significance $A$, where $p\gt A$;
We reject $H$ at the level of significance $R$, where $p\lt R$;
3.4 Naïve Bayes classifier (Cont.)
See in 2.10
3.5 Tutorial – Statistic Basics


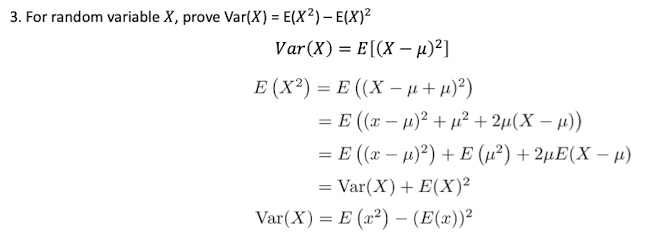


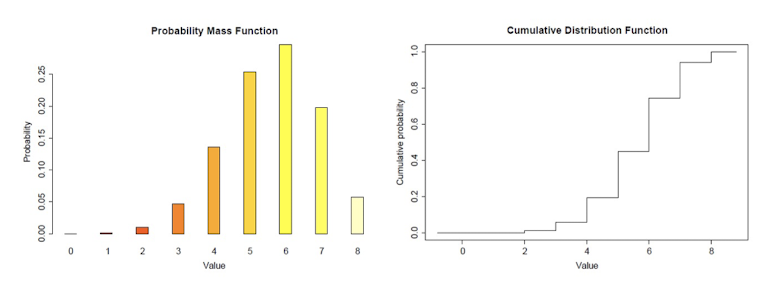

4 Linear Algebra Basics
4.1 Vectors
An order list of numbers:
Dimension: count of entires;
n-vector: Vector of dimension $n$;
Scalars: numbers in the vector.
4.1.1 Vectors Addition
Adding the corresponding elements, to form another vector of the same size.
Properties:
$a,b,c$ are same size vectors;
4.1.2 Scalar-Vector Multiplication
Scalar: $\beta$;
n-vector: $a$;
Properties:
4.1.3 Inner Product
dot product
n-vector $a$ and $b$:
Properties:
4.1.4 Vector Norm
Euclidean Norm of n-vector:
Properties:
- Homogeneity:
- Triangle Inequality:
- Non-negativity:
- Definiteness:
4.1.5 Vector Distance
Euclidean Distance of two n-vector:
4.1.6 Vector Angle
Angle $\theta$ between two non-zero vector $a$ and $b$:
Properties:
- $\theta = \frac{\pi}{2}$: $a\bot b$;
- $\theta = 0$: $a$ and $b$ are aligned, $a^Tb={\lVert a \rVert\cdot \lVert b \rVert}$;
- $\theta = \pi$: $a$ and $b$ are anti-aligned, $a^Tb=-{\lVert a \rVert\cdot \lVert b \rVert}$;
- $\theta \in (0,\frac{\pi}{2})$: $a$ and $b$ make a acute angle, $a^Tb\gt 0$;
- $\theta \in (\frac{\pi}{2},\pi)$: $a$ and $b$ make a obtuse angle, $a^Tb\lt 0$.
Proof:
4.2 Clustering
$N$ n-vector, $x_1,x_2,\cdots, x_n$:
Cluster them into $k$ clusters(groups),
Goal is to make vectors in the same cluster to be close to each other.
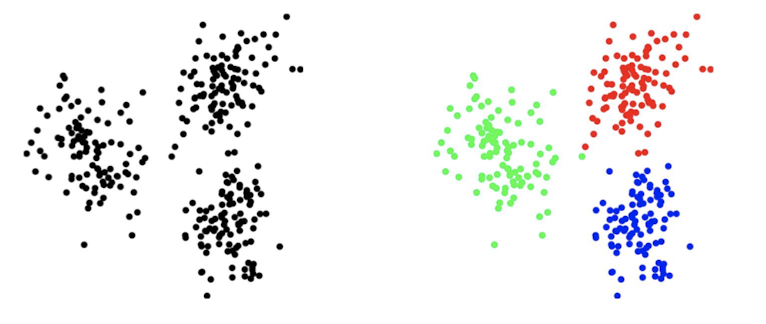
4.2.1 Clustering Objective
Group Assignment:
$ci$: the index of a group;
Assigned to vector $x_i,\; x_i\in G{c_i}$.
Group Representatives:
n-vectors $z_1,z_2,\cdots,z_k$
Clustering Objective:
Smaller, the better
4.2.2 K-means Clustering Algorithm
Repeatedly alternate between updating the group assignments, and then updating the representatives, then $J^{cluster}$ goes down.
Algorithm:
Given $x_1,x_2,\cdots , x_N$ N vectors, and initially $z_1,z_2,\cdots , z_k$ k representatives which is randomly selected at begin;
Repeat:
- Update group assignments: assign $i$ to $Gj$, $i= argmin{j’}\lVert xi-z{j’}\rVert$, let $x_i$ assigned to the group associated with the nearest representative;
- Update representatives: $zj=\frac{1}{|G_j|}\sum{i\in G_j}x_i$, to be the mean of the vectors in group $j$.
Until group representative stop change.
4.3 Matrices
Rectangular array of numbers:
A $2\times 3$ matrix, $M_{2,3}$
- size: (row dimension)×(column dimension), e.g., $2\times 3$;
- entries: the elements;
- $M_{i,j}$: entry at $i^{th}$ row and $j^{th}$ column;
- equal: have same size and all corresponding entries are equal;
column vector: $n\times 1$ Matrix;
row vector: $1\times n$ Matrix;
number: $1\times 1$ Matrix;
4.3.1 Transpose of Matrices
$A^T$: Transpose of Matrices
4.3.2 Addition, Subtraction, and Scalar Multiplication of Matrices
- Add: Same size matrix
- Subtract: Same size matrix
- Scalar multiplication:
Properties:
4.3.3 Matrix–Vector Product
matrix $A$ of $m\times n$, n-vector $x$, $y=Ax$:
4.3.4 Matrix Multiplication
matrix $A$ of $m\times p$, $B$ of $p\times n$, $C=AB$:
5 Calculus Basics
5.1 Functions
$y$ is a function of $x$, the value of x corresponds to one and only one value of $y$.
$x$: independent variable;
$y$: dependent variable.
5.1.1 Optimization of a Function
Optimization: Find a set of variables $x_1,x_2,\cdots,x_n$ that maximize or minimize $f(x_1,x_2,\cdots,x_n)$.
5.2 Derivatives
Derivative of $f(x)$:
- The slope of tangent line (instantaneous rate of change) at $(x,f(x))$;
Differentiation:
- the process of calculating derivative of $f(x)$;
5.2.1 Useful Derivative Rules
Power Rule:
Exponential Rule:
Logarithm Rule:
Derivatives for constants:
5.2.2 Properties of Derivatives
Constant:
Sum and Difference Rules:
Product Rule:
Quotient Rule:
Chain Rule:
5.2.3 Partial Derivatives
- For a function with several variables;
- Derivative with respect to one of those variables;
- with others as constants;
- Denoted as $\frac{\delta f}{\delta x}$ or $\frac{df}{dx}$.
5.2.4 Gradient
- For $f(x_1,x_2,\cdots,x_n)$,
- Gradient is the vector holding all partial derivatives:
- $\nabla f = (\frac{\delta f}{\delta x_1},\frac{\delta f}{\delta x_2},\cdots, \frac{\delta f}{\delta x_n})$;
- It points the direction of the greatest rate of change.
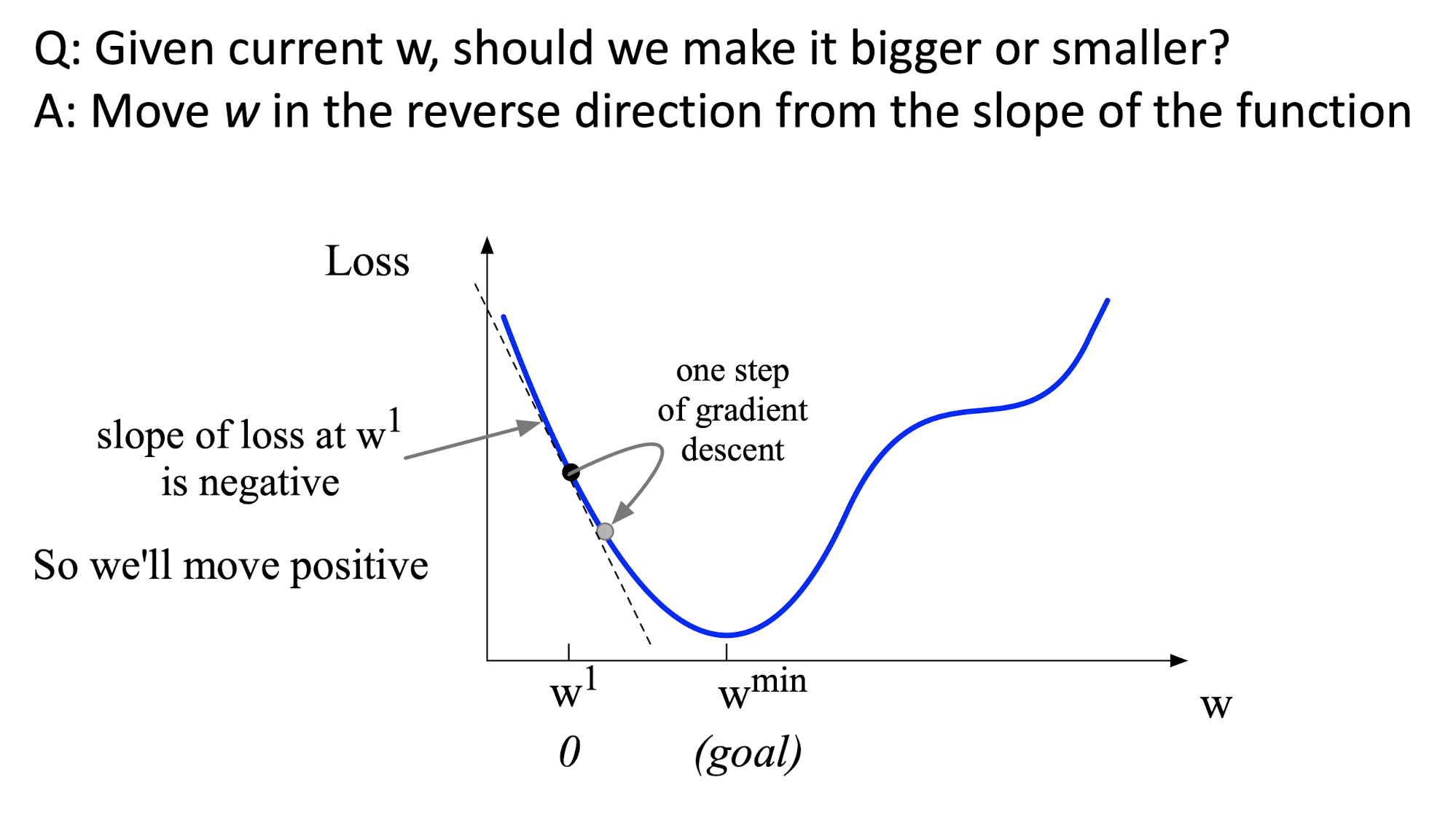
- Moving in the opposite direction of the gradient of the loss function.
- $\eta$: the moving step length, to avoid pass the goal.
5.2.5 The Training of Machine Learning
Generative Classifier:
- Calculus the probability of each object;
- Run model for each one;
- e.g. Naïve Bayes classifier.
Discriminative Classifier:
- Distinguish one from another;
Input: $x_1,x_2,\cdots,x_n$, the feature representation;
Output: $\hat{y}$, the prediction, via $p(y|x)$ function.
The object function to learn: cross-entropy loss, using gradient descent tor optimizing.
Linear Regression:
- Input: feature $x_1,x_2,\cdots,x_n$, and weight over feature $\theta_1,\theta_2,\cdots,\theta_n$;
- Output: $\hat{y}=h_\theta(x)=f(\theta^Tx)$, where $f(a)=a$, which is linear.
In order to get from numbers to 0-to-1, need to use sigmoid or logistic function:
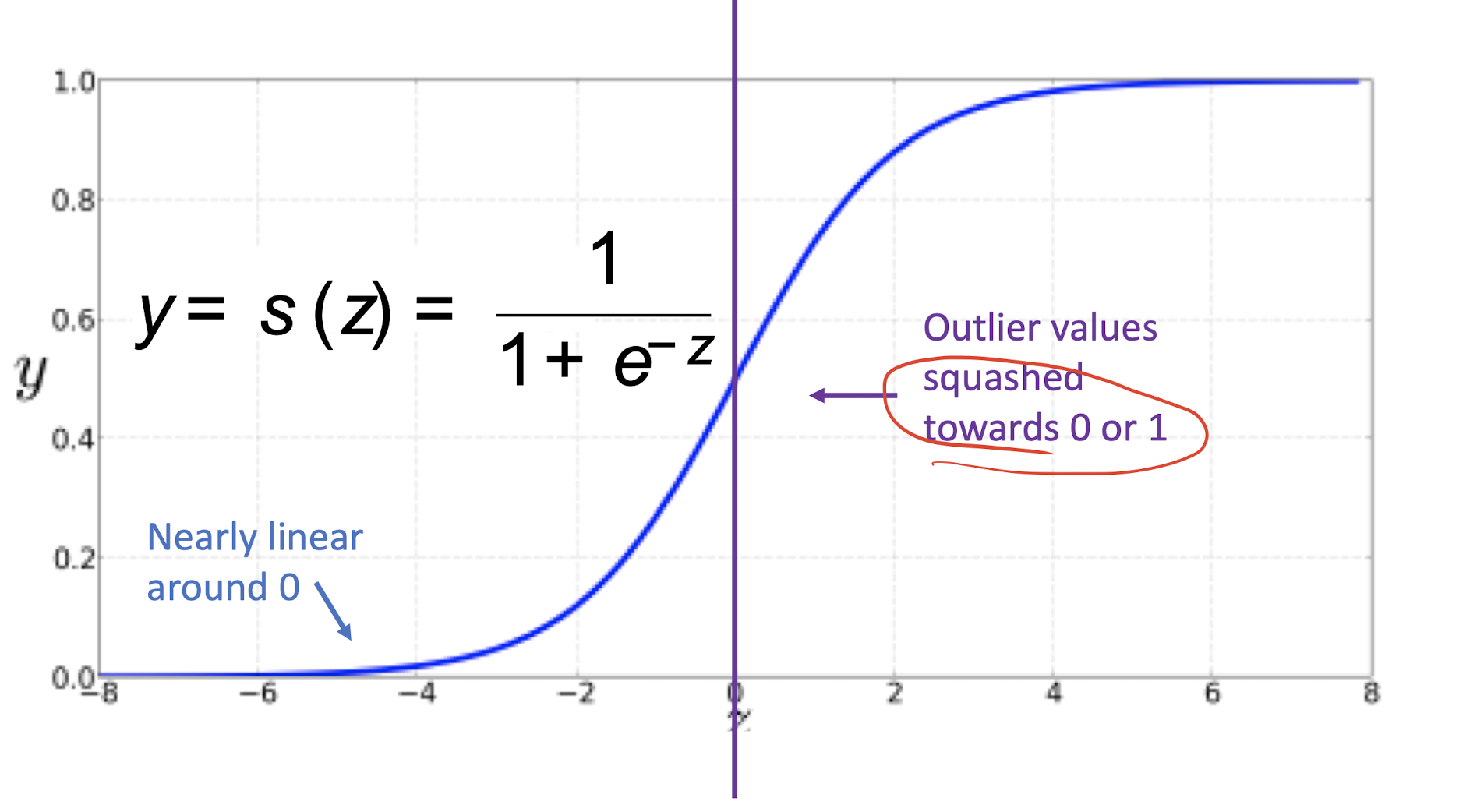
Sigmoid or Logistic Regression:
- Input: feature $x_1,x_2,\cdots,x_n$, and weight over feature $\theta_1,\theta_2,\cdots,\theta_n$;
- Output: $\hat{y}=h_\theta(x)=f(\theta^Tx)$, where $f(a)=\frac{1}{1+exp(-a)}$, which is sigmoid or logistic.
- Only fix to binary classification, not 3 or 4…
A recipe:
- Training Data: ${xi,y_i}{i=1}^N$, where $x$ is the feature and $y$ is the label.
- Decision function: $\hat{y}=f_\theta (x_i)$, where $f$ is the sigmoid function;
- Loss function: $l(\hat{y},y_i)\in \Bbb{R}$;
- The Goal: $\theta^*=argmin\theta \sum^N{i=1}l(f_\theta (x_i),y_i)$;
- Training with SGD, small steps opposite the gradient:

5.3 Integrals
Definite Integrals:
- $f(x)$: integrand;
- $F(x)$: antiderivative of $f(x)$.
Indefinite integrals:
5.3.1 Properties of Integrals
Sum and Difference Rules:
Power Rule:
Exponential Rule:
Chain Rule:
6 Programming with R
6.1 R Basic
- Created objects are held in memory;
- The workspace (the collection of objects you currently have) is not saved on disk unless you tell R to do so;
- Save:
save.image(); - Check the current working directory:
getwd(); - Save to a specific file and location:
save.image("path") - List the objects in the current workspace:
ls(),ls(pattern="x"); - Remove onr or more objects:
remove(x,x2); - Quit R:
q(); - Load the workspace:
load("path"); - Help:
1 | |
Assignment operators:
<-: An arrow formed by a smaller than character and a hyphen without a space;=: equal character;
Naming rules:
- CANNOT contain ‘strange’ symbols like
!, +, -, #; - A dot
.and an underscore_are allowed, also a name starting with a dot; - CAN contain a number but CANNOT start with a number;
- Case sensitive,
Xandxare two different objects, as well astempandtemP.
- CANNOT contain ‘strange’ symbols like
Check packages currently attached in the system:
search();- Check available library can be used in the system:
library();
6.2 R Data types
6.2.1 Vectors
Vector is the core element of R, it includes scalars, characters, logical values, but not mixed.
Using c(...) to initialize:
1 | |
Concatenate two vector into a new vector:
1 | |
Starts at index 1 instead of 0!
ELements referencing:
v[x]1
2
3
4
5
6
7> v <-c(1,2,3,4,5,6,7,8,9,10)
> v[2]
[1] 2
> v[1]
[1] 1
> v[0]
numeric(0)v[n:m]
inclusively1
2
3
4> v[2:3]
[1] 2 3
> v[4:10]
[1] 4 5 6 7 8 9 10Accessing from 1 to n+1:
v[1:(n+1)], instead ofv[1:n+1];v[c(a,b,c,...)]
Accessing via data vector;1
2
3
4> v[c(1,3,5)]
[1] 1 3 5
> v[c(1:6)]
[1] 1 2 3 4 5 6v[-x]
Ignore some elements;1
2
3
4
5
6> v[-1]
[1] 2 3 4 5 6 7 8 9 10
> v[-5]
[1] 1 2 3 4 6 7 8 9 10
> v[-(1:5)]
[1] 6 7 8 9 10v[x<y]
Accessing via boolean expression,TRUEfor selected,FALSEfor ignore;1
2
3
4> v[v>5]
[1] 6 7 8 9 10
> v[v %% 2 == 1]
[1] 1 3 5 7 9names()
Give names to some elements, and accessing via names;1
2
3
4
5
6
7
8
9
10
11> value <- c(1,2,3)
> names(value) <- c('one','two','three')
> value
one two three
1 2 3
> value['one']
one
1
> value[c('one','three')]
one three
1 3
6.2.2 Matrices
两种方法:
1 | |
1 | |
- Based on vector
v, create ar*cmatrix - Created column by column
byrow=FALSE: fill the matrices by columns (default)dimnames: provides optional labels for the columns and rows
1 | |
byrow=TRUE: fill the matrices by row:
1 | |
Convert vector directly into matrix:
1 | |
[Example]
1 | |
6.2.3 Dataframes
A data frame is more general than a matrix, in that different columns can have different modes (numeric, character, factor, etc.).
Creation form Column Data:
1 | |
1 | |
Identify the elements of a Dataframe:
1 | |
6.2.4 Lists
A list is an ordered collection of objects (components). It allows you to gather a variety of (even unrelated) objects under one name.
List Creation:
1 | |
1 | |
List containing:
1 | |
List Position Indexing:
Identify elements of a list:
1 | |
or
1 | |
l[n]
Special case, return a list of only one element.
1 | |
6.3 Data Input and Processing
Import Data:
1 | |
Export Data:
1 | |
Viewing data:
1 | |
6.3.1 Missing Data
NA: not available;NaN: Not a NUmber(dividing by zero);
is.na(x): returns TRUE of x is missing
1 | |
na.rm=TRUE: remove missing data
1 | |
complete.cases(): returns a logical vector indicating which cases are complete.
1 | |
na.omit(): returns the object with list-wise deletion of missing values.
1 | |
6.4 New Variable
Use the assignment operator
<-or=to create new variables.
1 | |
or using attach:
1 | |
or,
1 | |
6.5 Arithmetic Operators

6.6 Logical Operators

6.7 Control Structure
- if-else:
1 | |
- for:
1 | |
- while:
1 | |
- switch:
1 | |
- ifelse:
1 | |
6.8 Numeric Functions

6.9 Character Functions

6.10 Probability Functions


6.11 Statistical Functions


6.12 Barplot
Using ggplot2 library
Install:1
2> install.packages("ggplot2")
> library("ggplot2")
Barplot mainly use for category, on discrete data.
Example:
1 | |
ggtitle: chart title;xlab,ylab: Label for x-axis/y-axis;Identity: Make the heights of the bars to represent values in the data.fill: fill with colors or fill with some properties;position:="dodge"To create interleaved bars;
6.13 Histograms
Mainly use for the frequency distribution of a quantitative variable, on continuous variable.
Example:
1 | |
6.14 Scatter Plot
Mainly for the relations between data.
Example
1 | |
- Set the
color:
1 | |
- Set the
shape:
1 | |
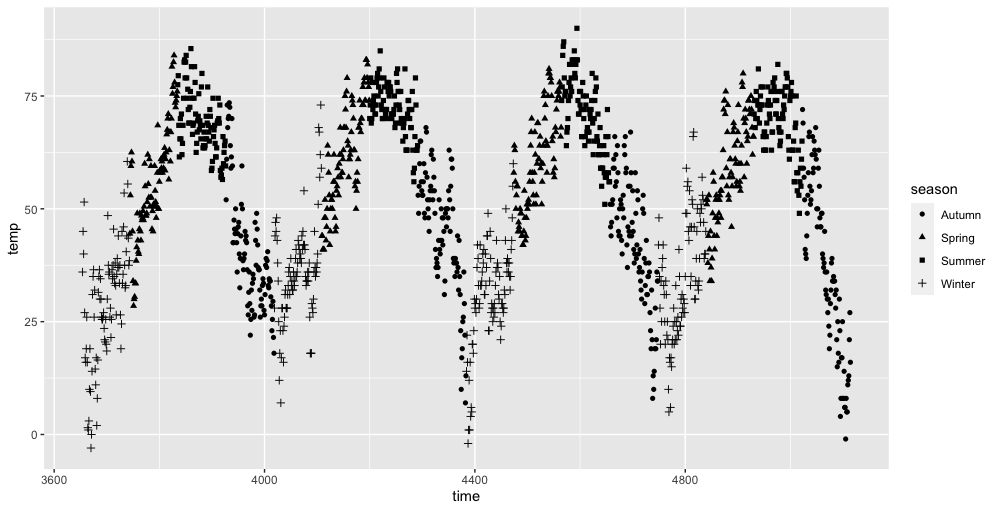
7 Data Analytics with R
7.1 Simulations
A simulation is an approximate imitation of the operation of a process or system.
7.1.1 Generate Random Numbers
rnorm($\text{amount},\mu,\sigma$): generate random Normal variates with a given mean and standard deviation;- generated continuously variables;
dnorm: evaluate the Normal probability density (with a given mean/SD) at a point (or vector of points);pnorm: evaluate the cumulative distribution function for a Normal distribution.
1 | |
7.1.2 Number Seed
A random seed is a number used to initialize a pseudorandom number generator (a starting point).
1 | |
1 | |
7.1.3 Simulating a Linear Model
1 | |
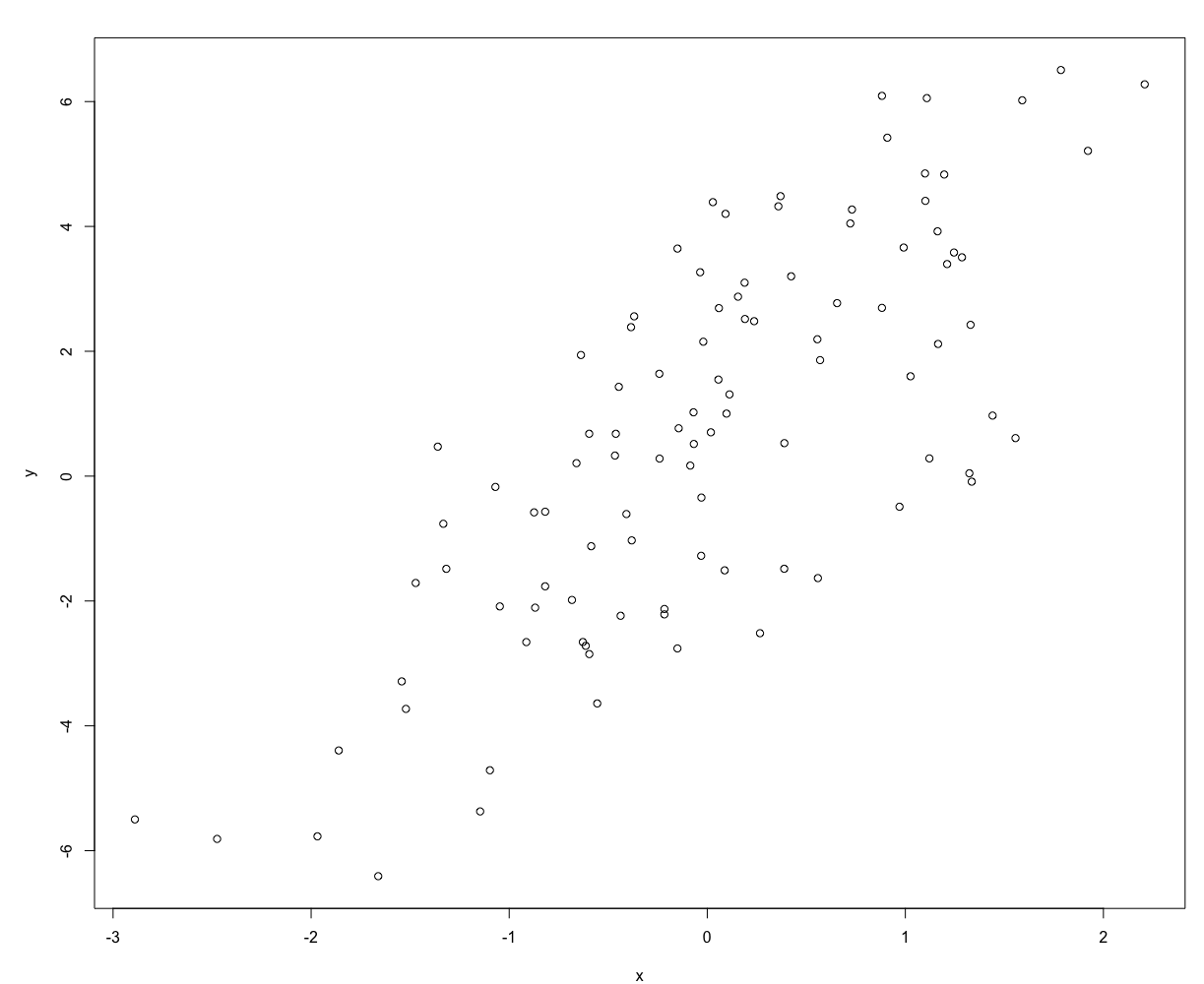
7.1.4 Random Sampling
The
sample()function draws randomly from a specified set of (scalar) objects allowing you to sample from arbitrary distributions of numbers.
1 | |
To sample a data frame:
sample the indices into an object rather than the elements of the object itself.

7.2 Monte Carlo Simulation
A method of estimating the value of an unknown quantity using the principles of inferential statistics
Inferential statistics:
Population: a set of examples
Sample: a proper subset of a population
Key fact: a random sample tends to exhibit the same properties as the population from which it is drawn
Confidence in our estimate depends upon two things
- Size of sample;
- Variance of sample.
Monte Carlo Principal:
In repeated independent tests with the same actual probability 𝑝 of a particular outcome in each test,the chance that the fraction of times that outcome occurs differs from p converges to zero as the number of trials goes to infinity
Intuition: if deviations from expected behaviour occur, these deviations are likely to be evened out by opposite deviations in the future.
Monte Carlo simulation is based on the law of large numbers.
The confidence of the estimation largely depends on the variance of samples.
The training method of Naïve Bayes can be seen as the Monte Carlo simulation.
Larger sample size may be helpful to draw unbiased results.
It is NOT a very effective method possibly allow 100% accuracy.
Poisson distribution
is often used to model rare events that are extremely unlikely to occur within a very short period of time or simultaneously (e.g. within 0.0001s).
describes the probability of a given number of events occurring in a fixed interval of time and/or space.
Exponential Distribution
used to model the time that elapses before an event occurs, e.g., the time between two events.
Exponential Distribution VS. Poisson Distribution
The inter-arrival times of events in a Poisson process with rate $\lambda$ is exponential and mean $\frac{1}{\lambda}$.
7.3 Regression and Time-series Analysis
7.3.1 Linear Regression
Introduction
Having bivariate data $(x_i,y_i)$,
Goal: find a model of the relationship between $x$ and $y$, and build a function $y=f(x)$ fitting the data.
Assumptions: $x_i$ is not random, and $y_i$ is function of $x_i$ plus some random noise.
$x$: the independent or predictor variable;
$y$: the dependent or response variable.
Implementation
Goal: find line $y=\beta_1x+\beta_0$ fitting the data.
Assumptions: Each $y_i$ is predicted by $x_i$ up to some error $\epsilon_i$:
So the error is:
Our goal is to find the $\beta_1$ and $\beta_0$ that minimize the sum of the squares of the errors which is:
Assume the found $\beta_1$ and $\beta_0$: $\hat{\beta_1}$ and $\hat{\beta_0}$:
Need to use calculus to find.
where:
Or simply:
Note
Linear Regression is not only fit in the line, can be in parabola.
Simple Linear Regression is fit a line to bivariate data.
Residuals
The error $\epsilon_i$ is called the residual, which is random noise or measurement error.
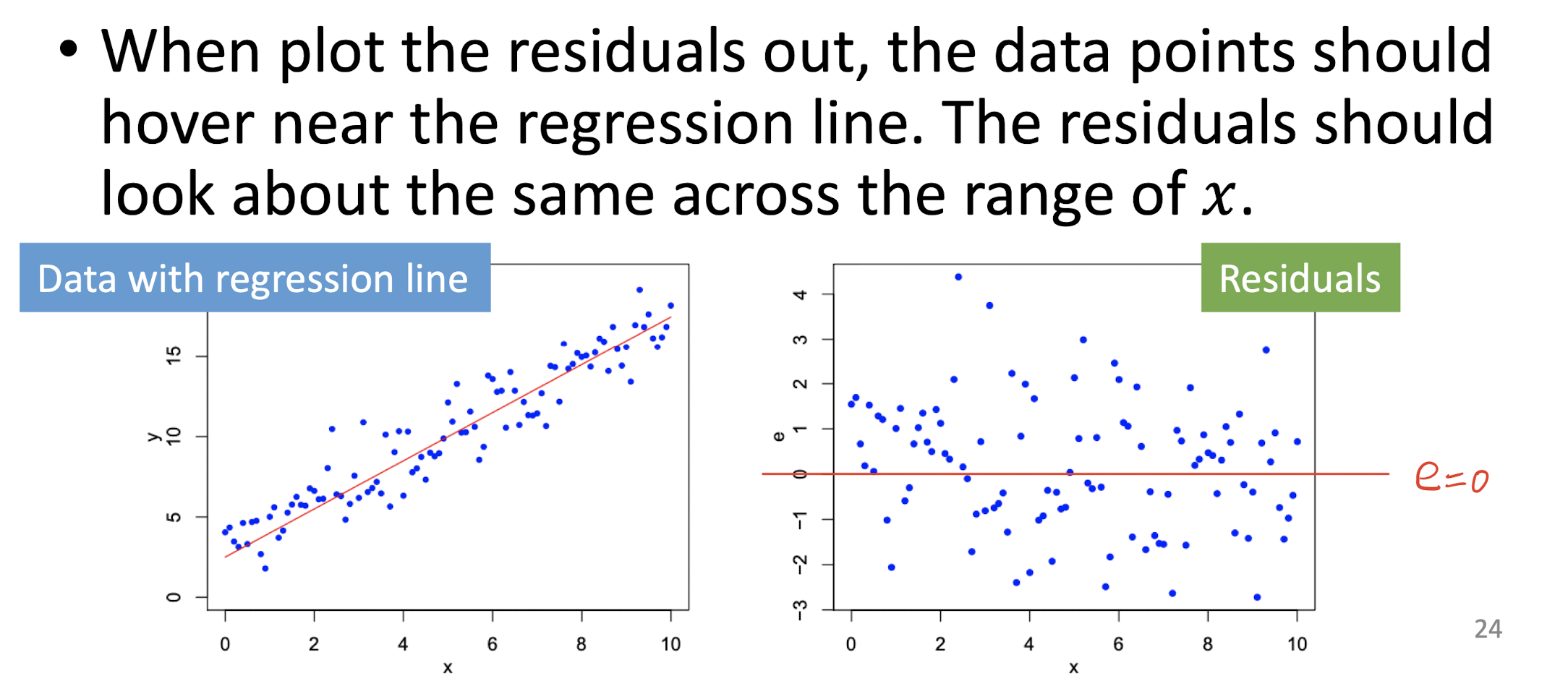
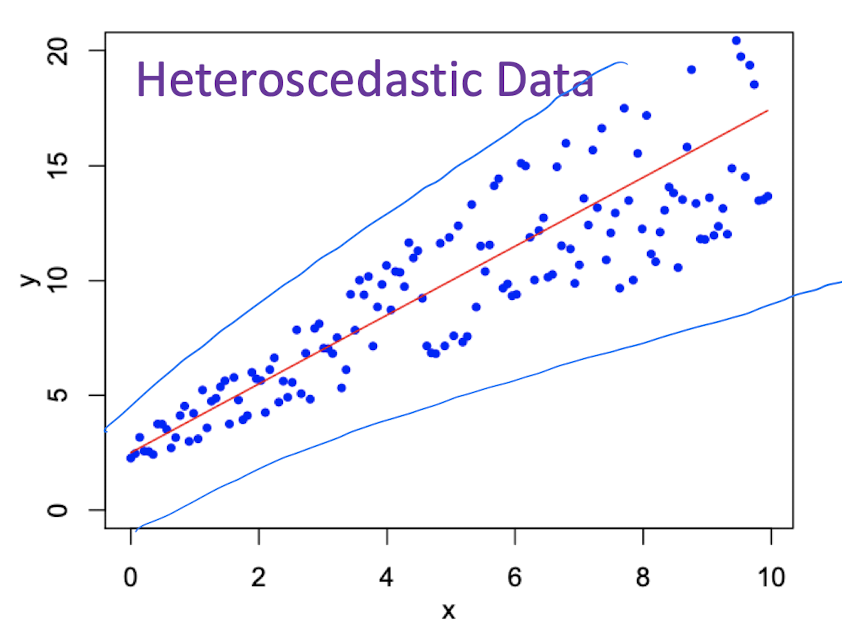
Homoscedasticity and Heteroscedasticity
Homoscedasticity: the residuals $\epsilon_i$ have the same variance for all $i$, means data points should hover near the regression line more evenly.
Heteroscedasticity: the residuals $\epsilon_i$ have the different variance for all $i$, means data points would not hover near the regression line more evenly.
Linear Regression for Multivariate
multivariate data: $(x_1,x_2,…,x_i,y_i)$
The fit line is $y=\beta_0+\beta_1x_1+\beta_2x_2+…+\beta_ix_i$
So,
7.3.2 Polynomial Regression
Linear Regression’s Linear means the exponent of $\beta_i$ is 1;
Polynomial Regression’s Polynomial means the exponent of $\beta_i$ can be greater than 1.
For parabola:
The fit curve is $y=\beta_0+\beta_1x+\beta_2x^2$
So,
7.3.3 Fit Measurement
For
Total Sum of Squares (TSS):
Residual Sum of Squares (RSS):
The goodness of fit:
With larger variance, more complicated.
Overfitting:
More complex model, better fitness;
Tradeoff between goodness of fit and complexity.
7.3.4 Time-series Analysis


References
Slides of COMP1433 Introduction to Data Analytics, The Hong Kong Polytechnic University.
个人笔记,仅供参考,转载请标明出处
FOR REFERENCE ONLY
Made by Mike_Zhang