Introduction to Computer Systems Course Note
Made by Mike_Zhang
所有文章:
Introductory Probability Course Note
Python Basic Note
Limits and Continuity Note
Calculus for Engineers Course Note
Introduction to Data Analytics Course Note
Introduction to Computer Systems Course Note
个人笔记,仅供参考
FOR REFERENCE ONLY
Course note of COMP1411 Introduction to Computer Systems, The Hong Kong Polytechnic University, 2022.
Mainly focus on
- Data representation
- Machine language
- Processor architecture
- Memory hierarchy
- Virtual memory
- System-level I/O
- Networking
1 Data representation I
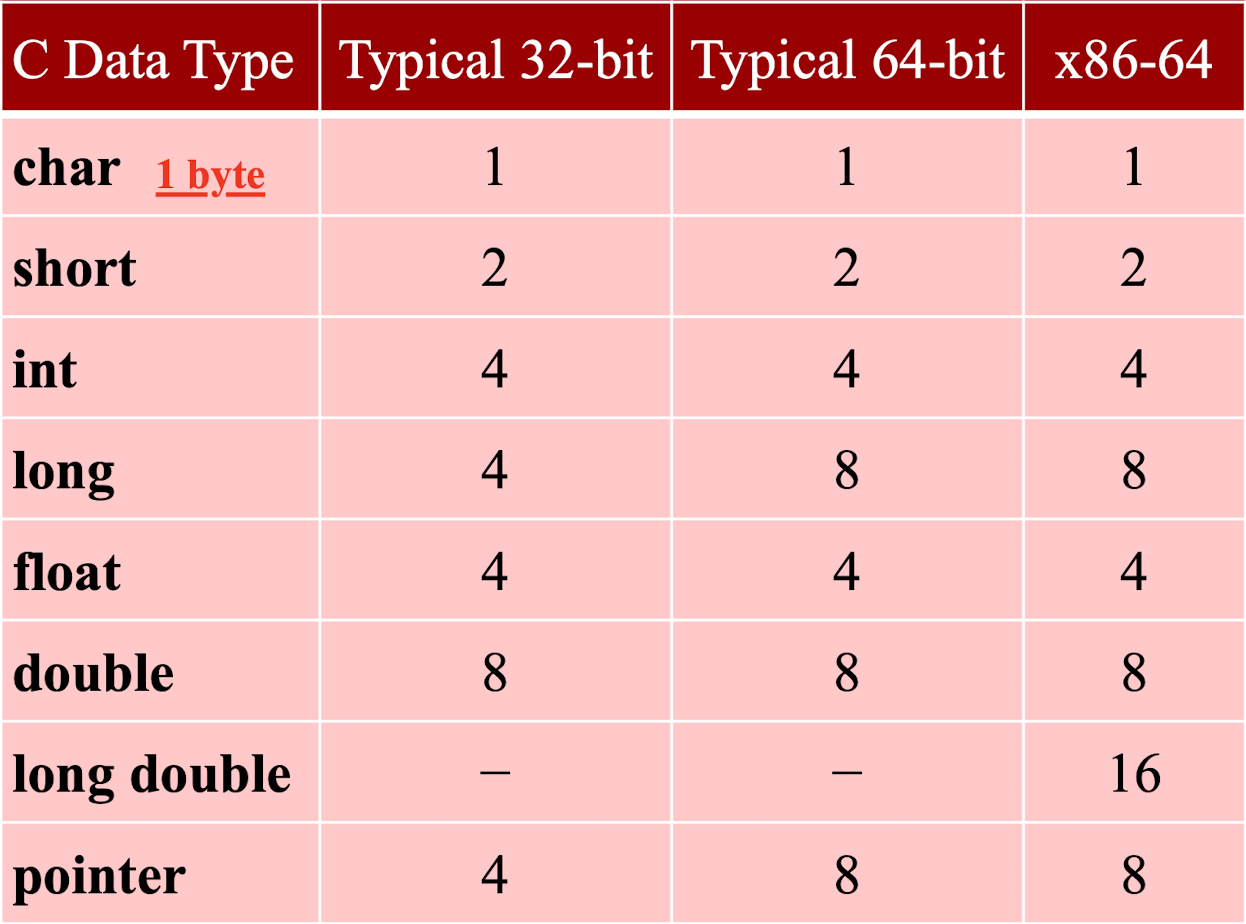
Use C code to get the size of a data type:
1 | |
1.1 Unsigned & Signed Integer
binary: 8 bits $\to$ 1 byte, not convenient to represent;
hexadecimal: 2 bits $\to$ 1 byte, easy to represent.
1.1.1 Bit-Level Operations in C
Use logic expression on single bit,
Trueas 1 andFalseas 0;
Apply to any “integral” data type:long,int,short,char,unsigned, applied bit-wise;
Return any value;
&: AND (Intersection in Set)|: OR (Union in Set)~: NOT (Complement in Set)^: Exclusive-OR (Symmetric difference in Set)
1.1.2 Logic Operations in C
Trueas nonzero andFalseas 0;
Always return 0 or 1.
&&: Logic AND;||: Logic OR;!: Logic NOT.
1.1.3 Shift Operations
- Left Shift
x << y- Shift bit-vector x left y positions
- Left: Throw away;
- Right: Fill with 0’s.
- Right Shift
x >> y- Shift bit-vector x right y positions
- Right: Throw away;
- Left:
- Logical shift: Fill with 0’s;
- Arithmetic shift: Fill with most significant bit
1.1.4 Encoding Integer
- Unsigned
- Two’s Complement
1.1.5 Range
- Unsigned
- $UMin = 0$;
- $UMax = 2^w-1$;
- Two’s Complement
- $TMax = 2^{w-1}-1$
- $TMin = -2^{w-1}$;
$|TMin|=TMax+1$ (Asymmetric Range for Two’s Complement)
$UMax = 2\times TMax+1$
$UMax=T2U(-1)$
$U2T(2^{w-1})=U2T(TMax+1)=TMin$
$T2U(TMin)=TMax+1$
1.2 Conversion & Casting
Conversion:
- By default: signed integers;
- suffix
U: Unsigned;
A mix of unsigned and signed in single expression:
signed values implicitly cast to unsigned
[Example]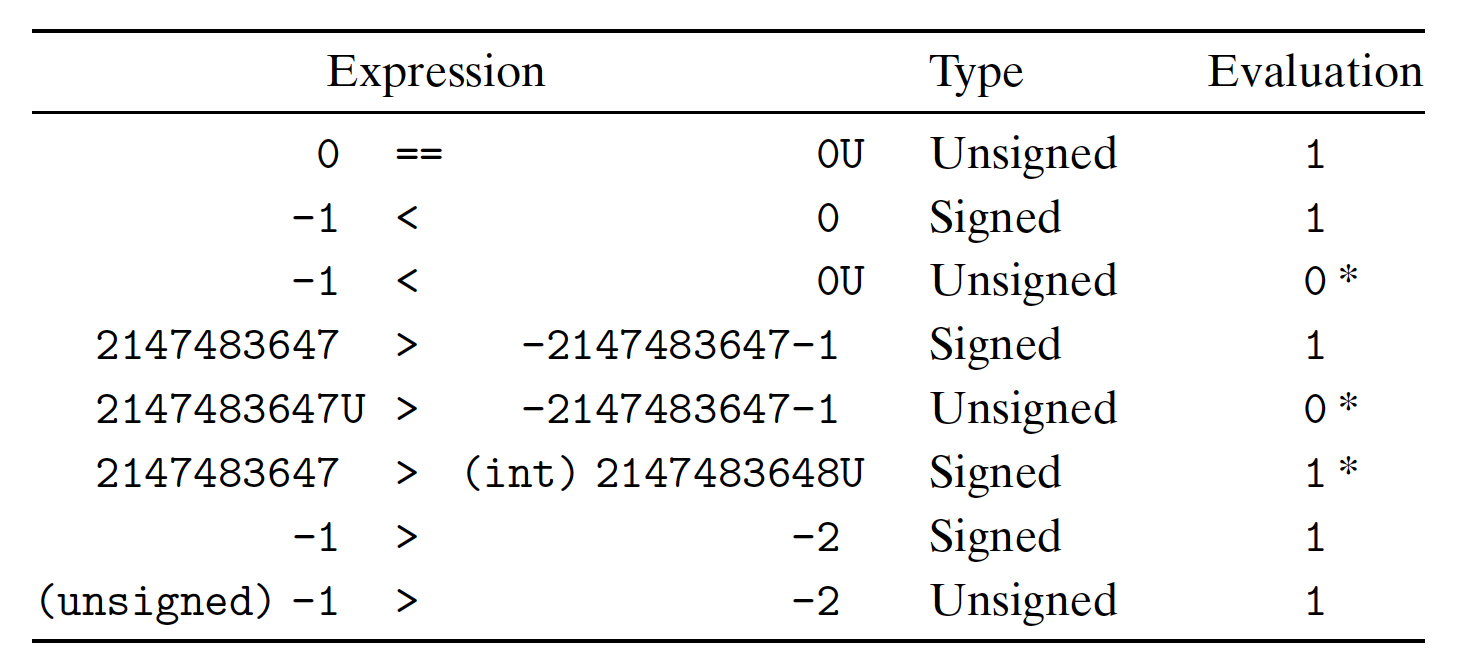
Casting:
- Truncating of unsigned number:
- $x$: the original number w-bit; $x’$: the result of truncaing of $x$ to k-bit:
- Truncating of two’s complement number:
- $x$: the original number w-bit; $x’$: the result of truncaing of $x$ to k-bit:
1.3 Addition & Multiplication & Shifting
1.3.1 Addition
- Unsigned
- Two’s Complement
1.3.2 Multiplication
- Unsigned
- Two’s Complement
1.3.3 Shift with Power-of-2
- Unsigned and Signed shift for Multiplication with Power-of-2
Most machines shift and add faster than multiply.
$x K$:
Convert the constant K in binary, consider a run of ones from bit position $n$ down to bit position $m$ ($n\ge m$), $x K$ can be represented in:
$(x<<n)+(x<<(n-1))+…+(x<<m)$, or
$(x<<(n+1))-(x<<m)$
- Unsigned shift for Quotient with Power-of-2
1.4 Memory & Pointers & Strings Representations
1.4.1 Memory
- Programs refer to data by address;
- Each byte has a address;
- Word Size: how many data can be transferred in the I/O BUS at a clock time;
1.4.2 Byte Ordering
- Big Endian:
- Least significant byte has highest address;
- Sun, PPC Mac, Internet
- Little Endian
- Least significant byte has lowest address;
- x86, ARM processors running Android, iOS, and Windows
[Example]

1.4.3 Pointer
- Size of a pointer: depends on the word-size of a computer
- size of 4: 32-bit;
- size of 8: 64-bit.
1.4.4 String
- Array of characters;
- Encoded in ASCII format;
- String should be null-terminate: Final character = 0;
1 | |
2 Data representation II
2.1 Fixed Pointer Representation
Write a decimal number in binary:
then
Limitations:
- Can only exactly represent numbers of the form $\frac{x}{2^k}$
- Limited range of numbers, can not represent very large and very small numbers, due to the point is fixed.
Judge whether a decimal number can be exactly represented:
write into form of $\frac{x}{2^k}$, if can write, YES; if can not, NO;
e.g., $0.18=\frac{9}{50}$, not in that form, NO.
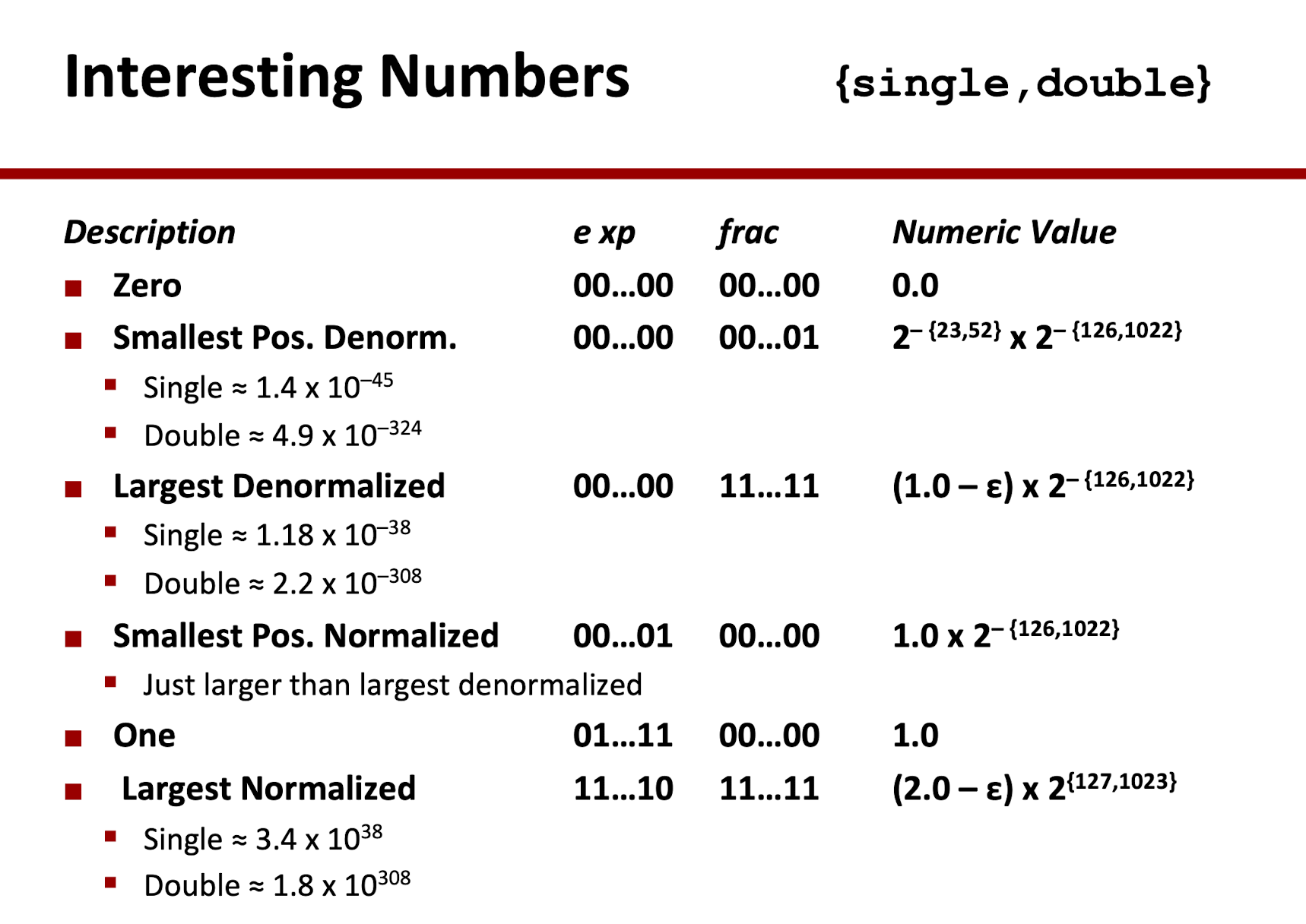
2.2 IEEE 754 Floating Point Representation
2.2.1 Numerical Form
$s$: sign bit, determines positive(0) or negative(1);
$M$: significand, fractional value in $[1.0,2.0)$;
$E$: exponent, weights value by power of two.
2.2.2 Encoding

In binary
$s$ is the sign bit;
$exp$ is the encoded $E$;
$frac$ is the encoded $M$
Categories of single-precision floating-point values in IEEE 754:
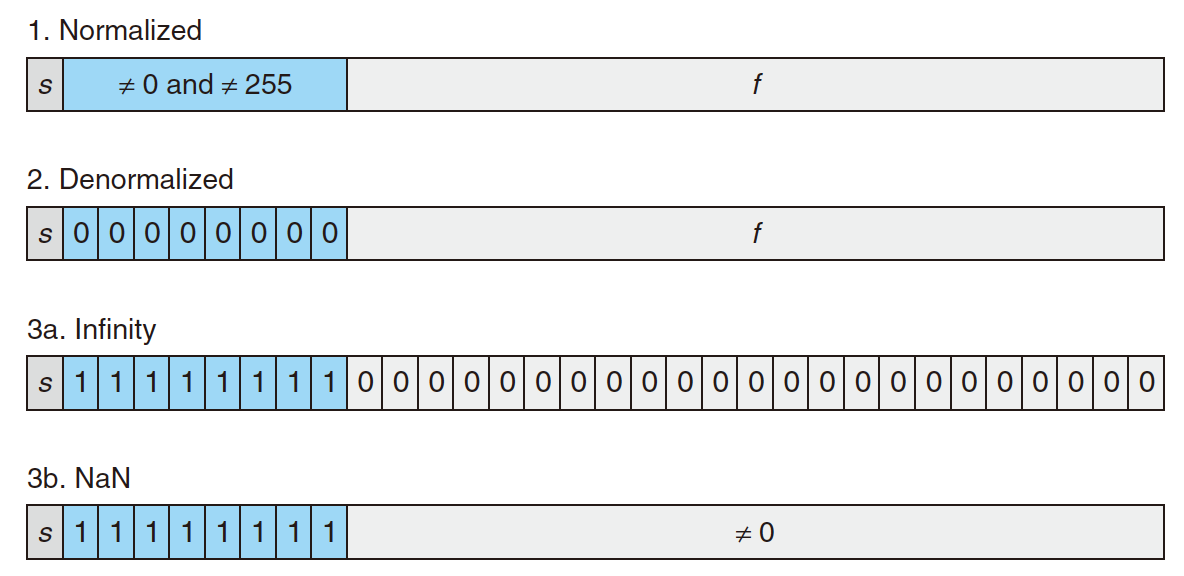
2.2.2.1 Normalized
The $exp$ is neither all $1$s nor $0$s, $exp\ne 0000\;0000(0)$, $exp\ne 1111\;1111(255)$;
$s$: 1-bit sign bit
$exp$: 8-bit, encode in biased $(2^{k-1}-1)$, $exp=E+127$, $E=exp-127$, $[-126,127]\to [0000\;0001,0111\;1111]$;
$f$: 23-bit,encoded with hidden-1, $M=1.f=1.xxx…x_2$.
2.2.2.2 Denormalized
The $exp$ is all $0$s, $exp= 0000\;0000(0)$;
$s$: 1-bit sign bit
$exp$: 8-bit, encode to $0000\;0000$, $E=1-(2^{k-1}-1)$, $E=1-127=-126$;
$f$: 23-bit,encoded without hidden-1, $M=0.f=0.xxx…x_2$.
With the feature of $exp$ and no hidden-1, the denormalized value can represent value $0$ and very close to $0.0$.
$exp=0000\;0000$, $frac=0000\;0000$: represent $0$;
$exp=0000\;0000$, $frac\ne 0000\;0000$: represent values very close to $0$;
2.2.2.3 Special Values
The $exp$ is all $1$s, $exp= 1111\;1111(255)$;
$s$: 1-bit sign bit
$exp=1111\;1111$, $frac=0000\;0000$: represent $\infin$;
$s=0$: $+\infin$,$s=1$: $-\infin$;
represent the overflow result;$exp=1111\;1111$, $frac\ne 0000\;0000$: represent $NaN$ (Not-a-Number);
like $\sqrt{-1},\infin-\infin, \infin \times 0$
2.3 Rounding
Using the Round-To-Even
Round to 3 d.p.
- $G$: Guard bit, the LSB of rounded result;
- $R$: Round bit, first bit to remove;
- $S$: $S=X|X|X$, Stick bit, OR of remaining bis.
$R\;XXX\lt$ half-way(e.g., 1/2), means $R=0$, then round down;
$R\;XXX\gt$ half-way(e.g., 1/2), means $R=1,S=1$, then round up;
$R\;XXX=$ half-way(e.g., 1/2), means $R=1,S=0$, then round to even:if $G=1$: round up(+1);
if $G=0$: round down;
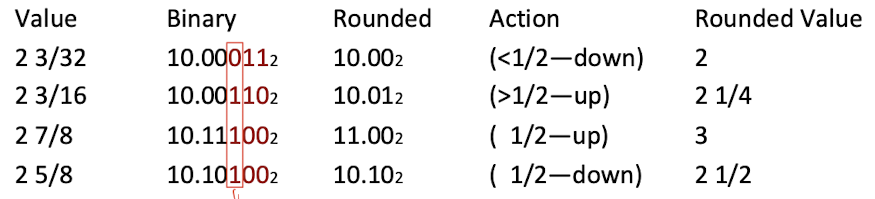
Rounding may cause overflow, then use Postnormalize:
- Shifting the overflowed value right once and incrementing the exponent
2.4 Floating Point Operations
- First compute the exact result;
- Fix:
- Possibly overflow if exponent too large;
- Possibly round to fit into $frac$
2.4.1 Floating Point Multiplication
E.g.
Result:
$(-1)^{s} M2^{E}$
$s=$ $s_1$^$s_2$ (exclusive-OR)
$M=M_1\times M_2$
$E=E_1+E_2$
Fix:
- if $M\ge2$, overflow, then Postnormalize, shift M right, increment E;
- if $E$ out of range, then the result is overflow;
- Round $M$ to fit the precision.
Note on Mathematical Properties:
- Has Commutative;
- No Associative, may cause overflow;
- Has 1 is multiplicative identity;
- No Distributive.
2.4.2 Floating Point Addition
E.g.
Result:
$(-1)^{s} M2^{E}$
- First need to get them lined up:
- increase $E_2$ to equal to $E_1$,
- shift $M_2$ right $E_1-E_2$
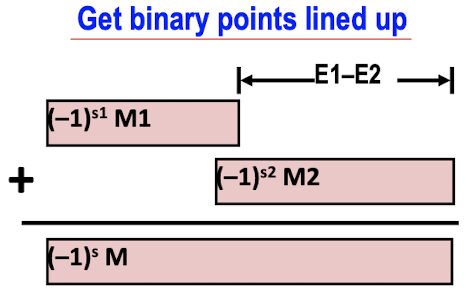
- $s$ and $M$ depends on the result;
- $E=E_1$
Fix:
- if $M\ge2$, overflow, then Postnormalize, shift M right, increment E;
- if $M\lt1$, then Postnormalize, shift M left, decrement E;
- if $E$ out of range, then the result is overflow;
- Round $M$ to fit the precision.
Note on Mathematical Properties:
- Has Commutative;
- No Associative, may cause overflow;
- Has 0 is multiplicative identity;
- Almost Additive Inverse(except $\pm \infin$ and $NaN$).
2.4.3 Float Point Comparison
- Floating Point 0 = Integer 0
- Must first compare sign bits;
- Must consider $−0$ = $0$;
3 Machine language
3.1 History of Intel processors and architectures
- Complex instruction set computer (CISC)
A single instruction consists of several lower-level operations;- Data transfer from memory, computation, saving result into register;
- Different memory addressing modes can be used.
3.2 C assembly machine code
Architecture:
- The parts of a processor design that one needs to understand or write assembly/machine code;
- Specification of the instruction set and registers
ISA:
Instruction Set Architecture;Microarchitecture:
Implementation of the architectureMachine Code:
The byte-level programs that a processor executesAssembly Code:
A text representation of machine code, more readable for human.Turning C into Object Code:
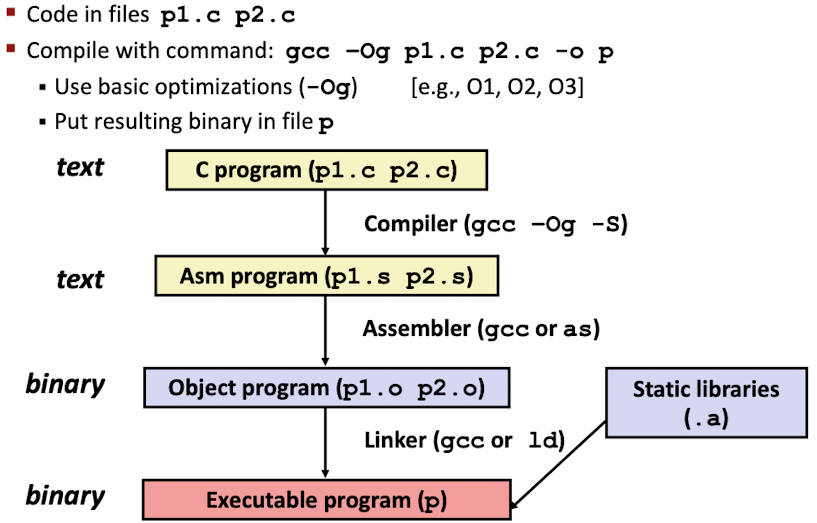
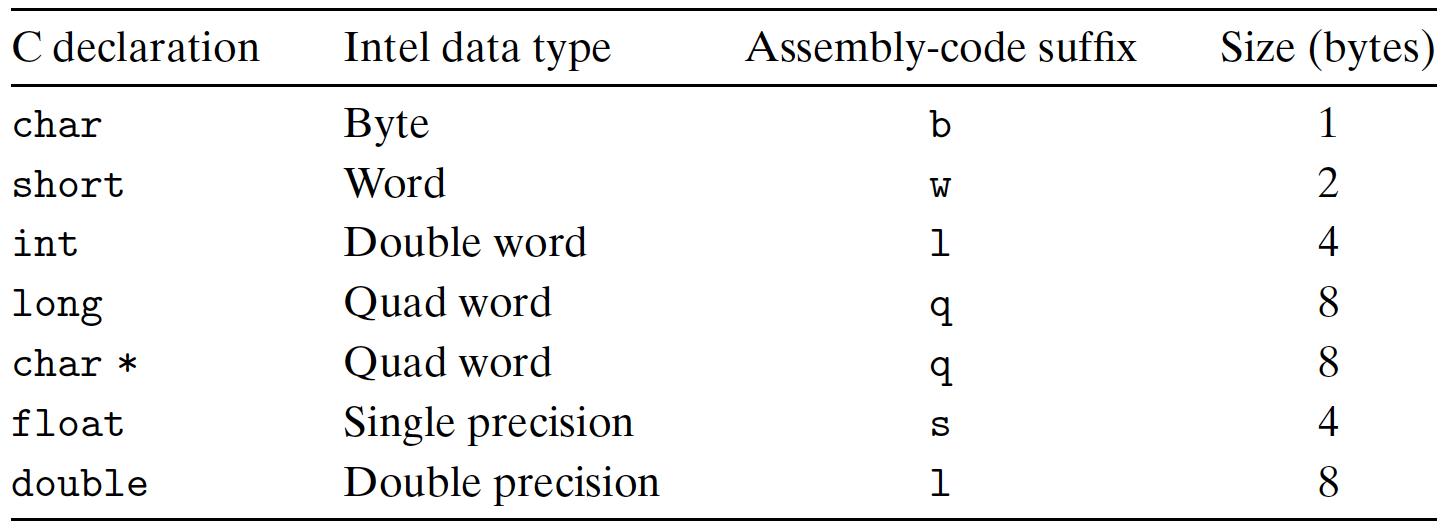
- Size of C Data Types in x86-64:
3.3 Registers, operands, move
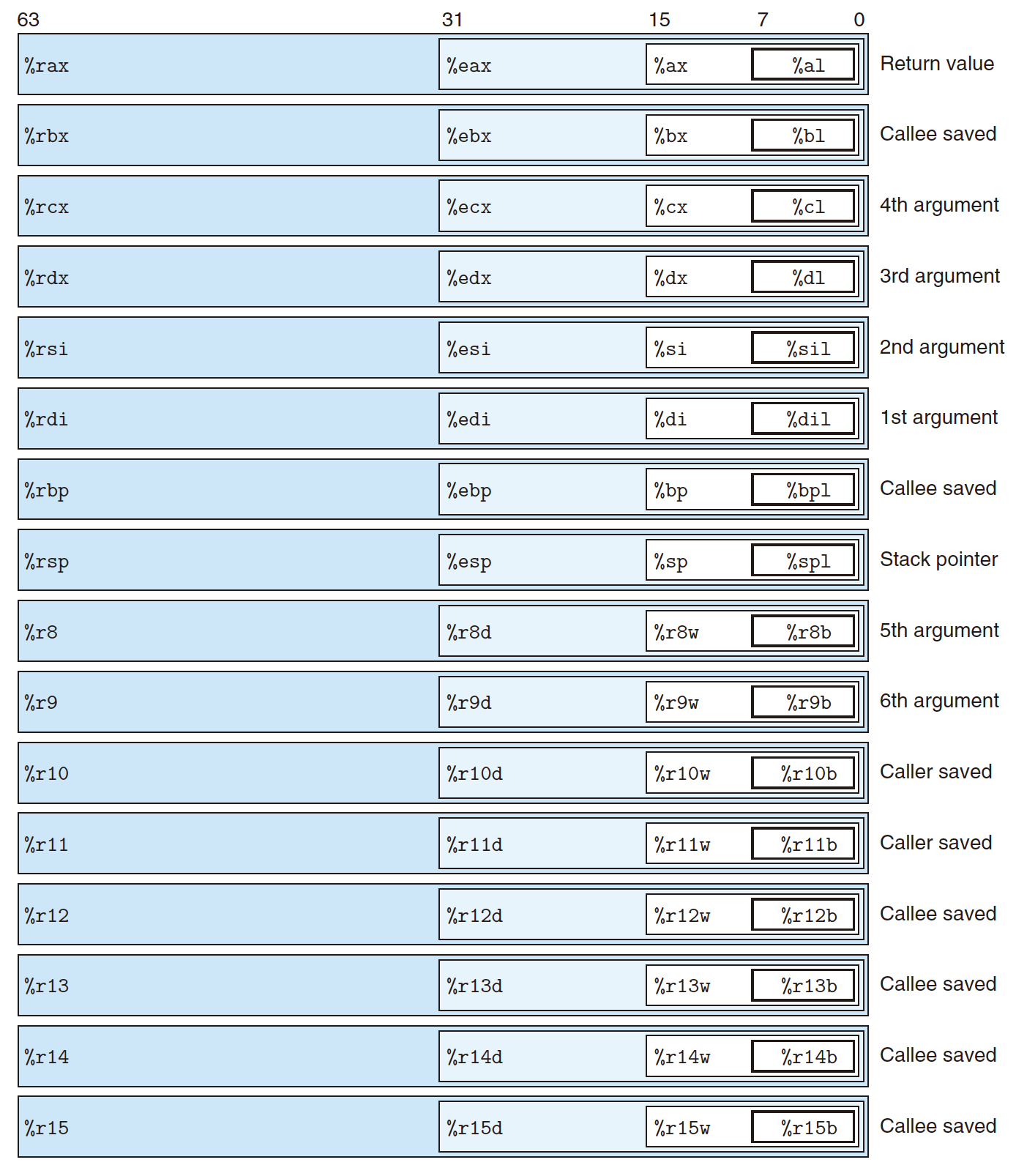
3.3.1 x86-64 Integer Registers
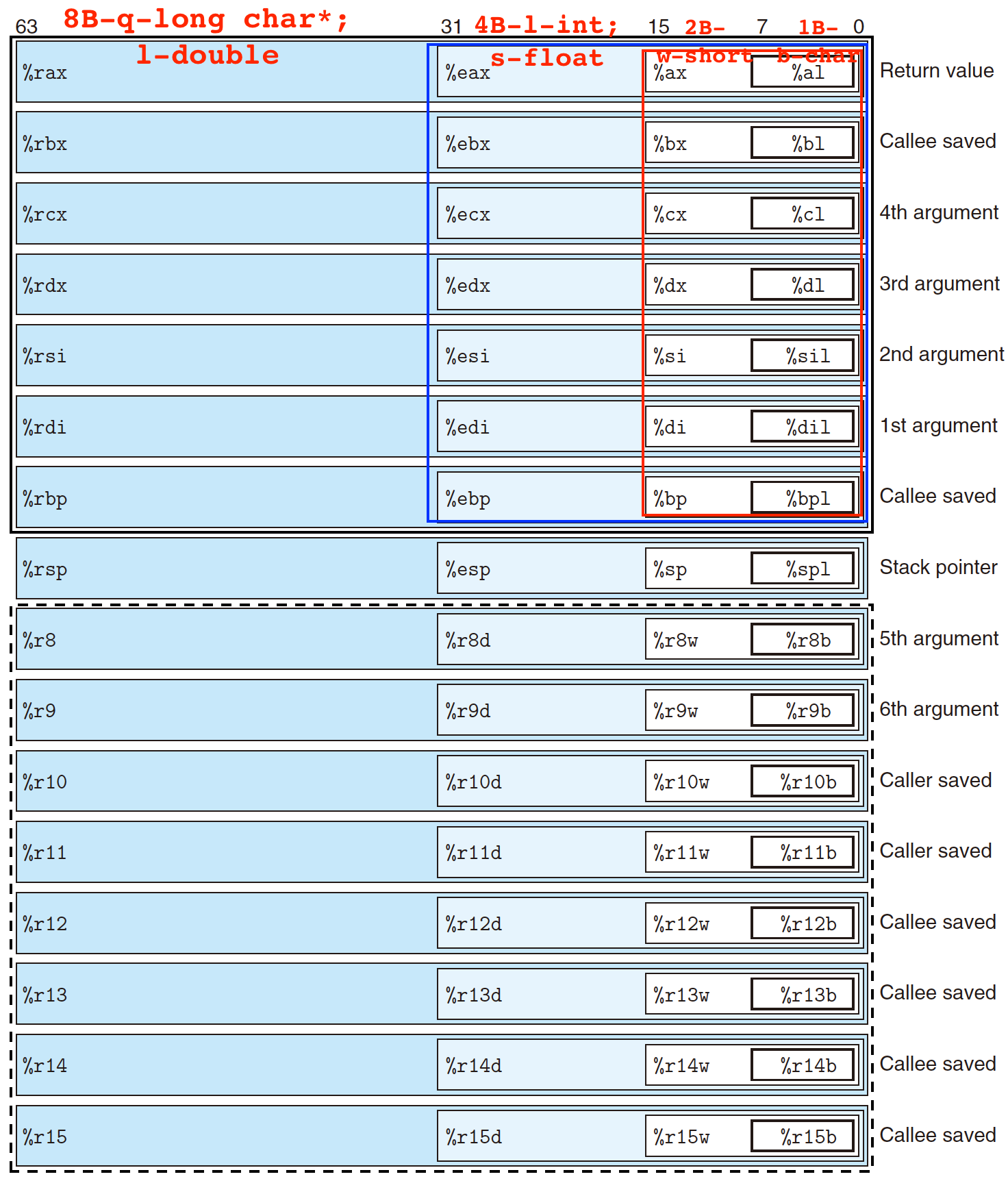
x86-64 CPU has a set of 16 64-bit general-purpose register, storing integer data and pointers(addresses):
- Start from 8086, 8 16-bit register (in RED box):
%axto%bp; - Then to IA32, extended to 8 32-bit register (in BLUE box) :
%eaxto%ebp; - Finally to x86-64, extended to 8 64-bit register (in BLACK box):
%raxto%rbp, as well as additional new 8 64-bit register (in DOT LINE box) :%r8to%r15;
Different registers have different functions:
%rsphas a specific function: stack pointer, indicate the end position of run-time stack;- Other 15 registers have more flexible functions.
Instructions can operate on different data size in low-order of the 16 registers:
- 8-bit instruction: can access least significant 1 byte;
- 16-bit instruction: can access least significant 2 byte;
- 32-bit instruction: can access least significant 4 byte;
- 64-bit instruction: can access entire register;
3.3.2 Operand Types
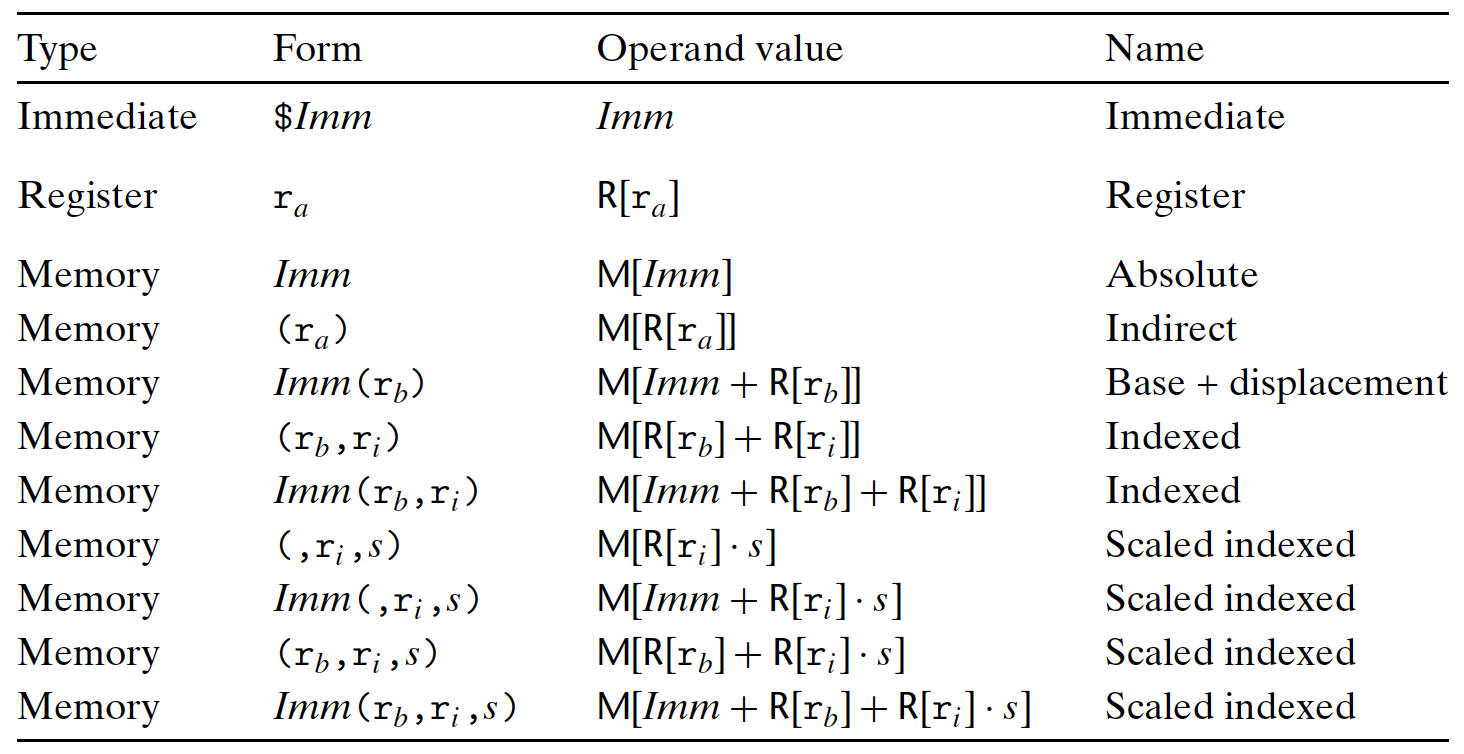
Three Types:
- Immediate:
- constant value, started with
$, followed by a integer in standard C notation;
- constant value, started with
- Register:
- contents of a register, each bit length of instruction has its specific among of bits (e.g., 8-byte register:64 bits);
- Notation $r_a$ indicates the register $a$ and its value in reference $R[r_a]$ indexed by the register identifiers in an array $R$;
- Memory:
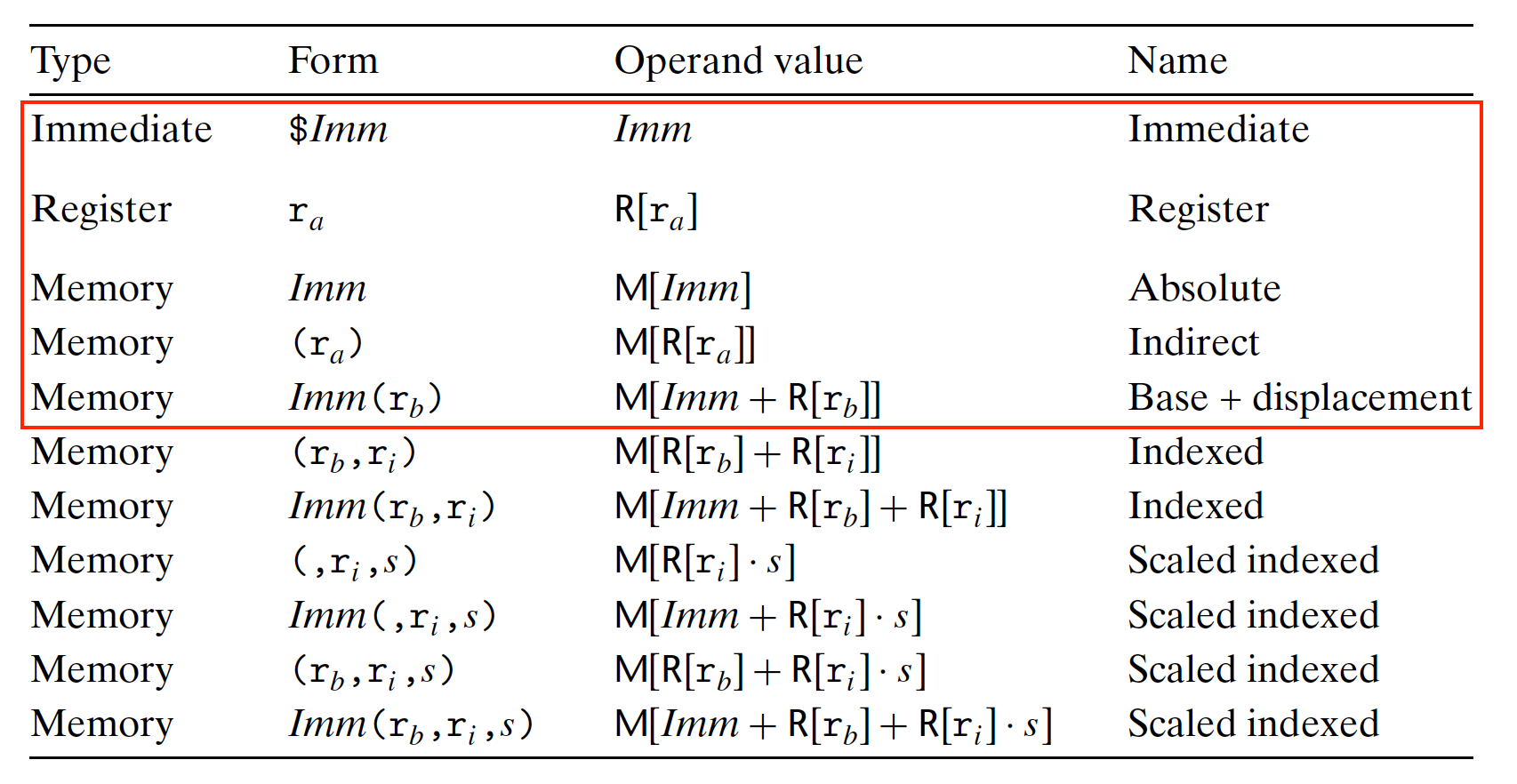
- Access memory location based on the computed address - effective address;
- $M_b[Addr]$: reference to the $b$-byte value in memory starting at address $Addr$;
- $Imm(r_b,r_i,s)$: the most general form:
- $Imm$: immediate offset;
- $r_b$: base register, 64-bit (like the start of array);
- $r_i$: index register, 64-bit (the index of the array);
- $s$: scale factor, must be 1,2,4, or 8 (fix to the data length);
- effective address $=Imm+R[r_b]+R[r_i]\cdot s$;
- The value is $M[Imm+R[r_b]+R[r_i]\cdot s]$;
- These complex addressing modes useful in Array and structure elements referencing.
- Simple Memory Addressing Modes:
- Normal: $(R)\to Mem[Reg[R]]$, Register $R$ specifies memory address, Pointer dereferencing in C;
movq (%rcx),%rax - Displacement: $D(R)\to Mem[Reg[R]+D]$, Register $R$ specifies start of memory region;
movq 8(%rbp),%rdx
- Normal: $(R)\to Mem[Reg[R]]$, Register $R$ specifies memory address, Pointer dereferencing in C;
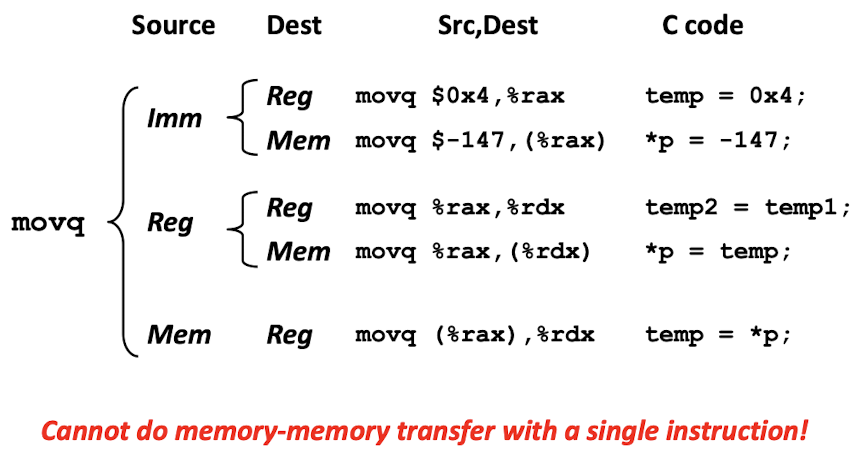
3.3.3 Moving Data
Copy data from a source location to a destination location, without transformation.
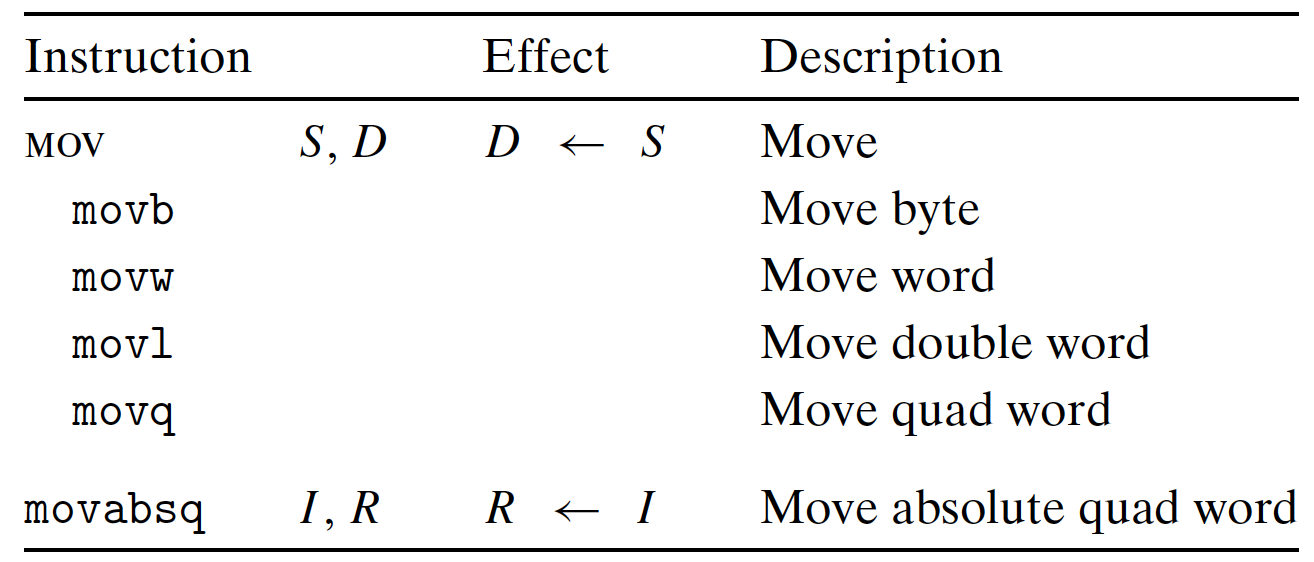
Source(S):
- value of immediate;
- value in register;
- value in memory.
Destination(D):
- register;
- memory address.
Copy from a memory to another memory:
Can not directly copy, first load the memory value to a register, then write the register value to the destination memory.
For register operand:
- The size of the register must match the last character of the instruction(
b,w,l,q); - The
MOVinstruction will only update the specific byte indicated by the destination operand,
Except themovlinstruction with the register destination, it will set high-order 4-byte to 0. (For the convention in x86-64 from 64-bit to 32-bit to adopt)
3.4 Arithmetic & logical operations
3.4.1 Two Operand Instructions

- S: immediate value, register, memory location;
- D: register, memory location;
- S, D can NOT both be memory;
- Source operand first, Destination second;
Fun S, D—>D = D fun Ssubq %rax, %rdx:%rdx = %rdx - %rax(Subtract%raxfrom%rax)
For Shift Instructions:
Source and Destination can be register or memory location.
Shift amount (2 ways):
- immediate value:
k - single-byte register
%cl:- based data: w-bit (i.e. 8,16,32,64);
- shift amount: value of low-order m-bit of
%cl, $2^m=w,m=\log_2w$;- e.g. 8-bit: lower 3-bit value of
%cl; - 64-bit: lower 6-bit value of
%cl;
- e.g. 8-bit: lower 3-bit value of
- Example:
%cl= 0xFF = 1111 1111:salb: 8-bit, shift lower 3-bit value = 111 = 7;salw: 16-bit, shift lower 4-bit value = 1111 = 15;
Left Shift:
SAL: arithmetic left shift;SHL: logical left shift;- Same effect, fill right with zero;
Right Shift:
SAR: arithmetic right shift, fill copy of the sign bits;SHR: logical right shift, fill left with zeros;
3.4.2 One Operand Instructions

Unary Instructions:
- Operand can be register or memory location.
3.4.3 Address Computation Instruction
leap Instructions:
- load effective address instruction;
- read memory address to a register;
- NO access to the memory, just load the address;
- $\&S$: C address operator, like a pointer;
[Example]
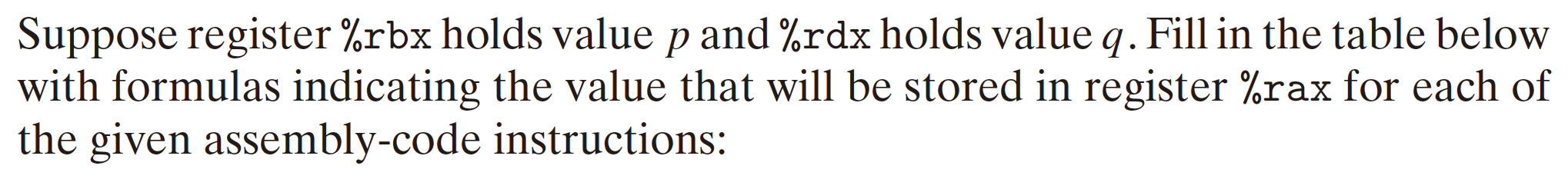
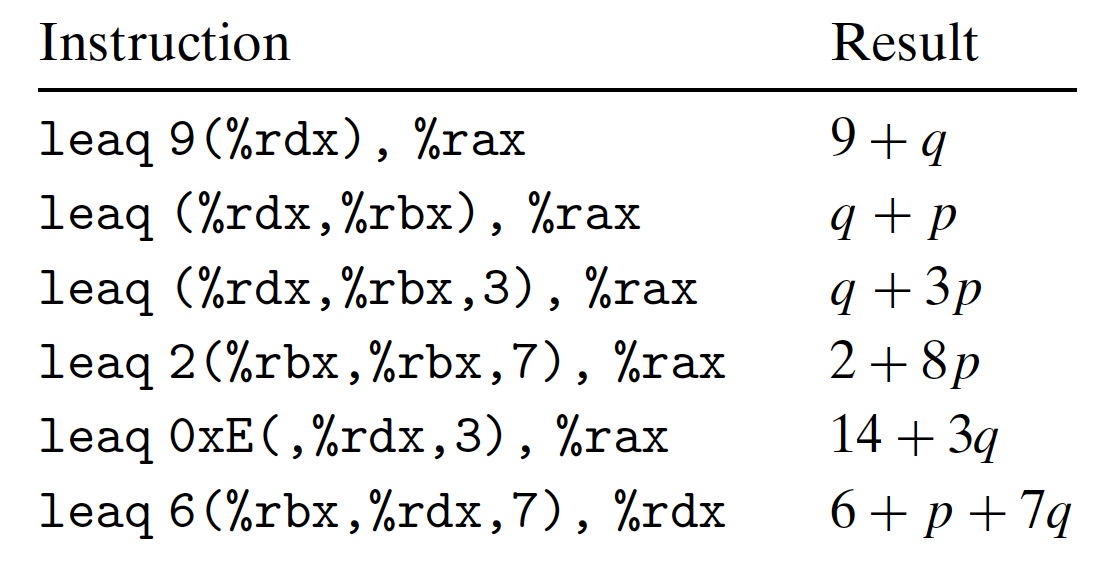
Important Usage:
- Computing addresses without a memory reference;
- Computing arithmetic expressions of the form $x + k\times y,k=1,2,4,8$:
[Example]

3.5 Conditional Codes
Condition Codes(CC): Describe attributes of the most recent arithmetic or logic operation.
CF: Carry Flag, the carry out of the MSB, to detect overflow for unsigned operations;ZF: Zero Flag, Yielding zero;SF: Sign Flag, Yielding a negative value;OF: Overflow Flag, overflow due to two’s complement, negative or positive.
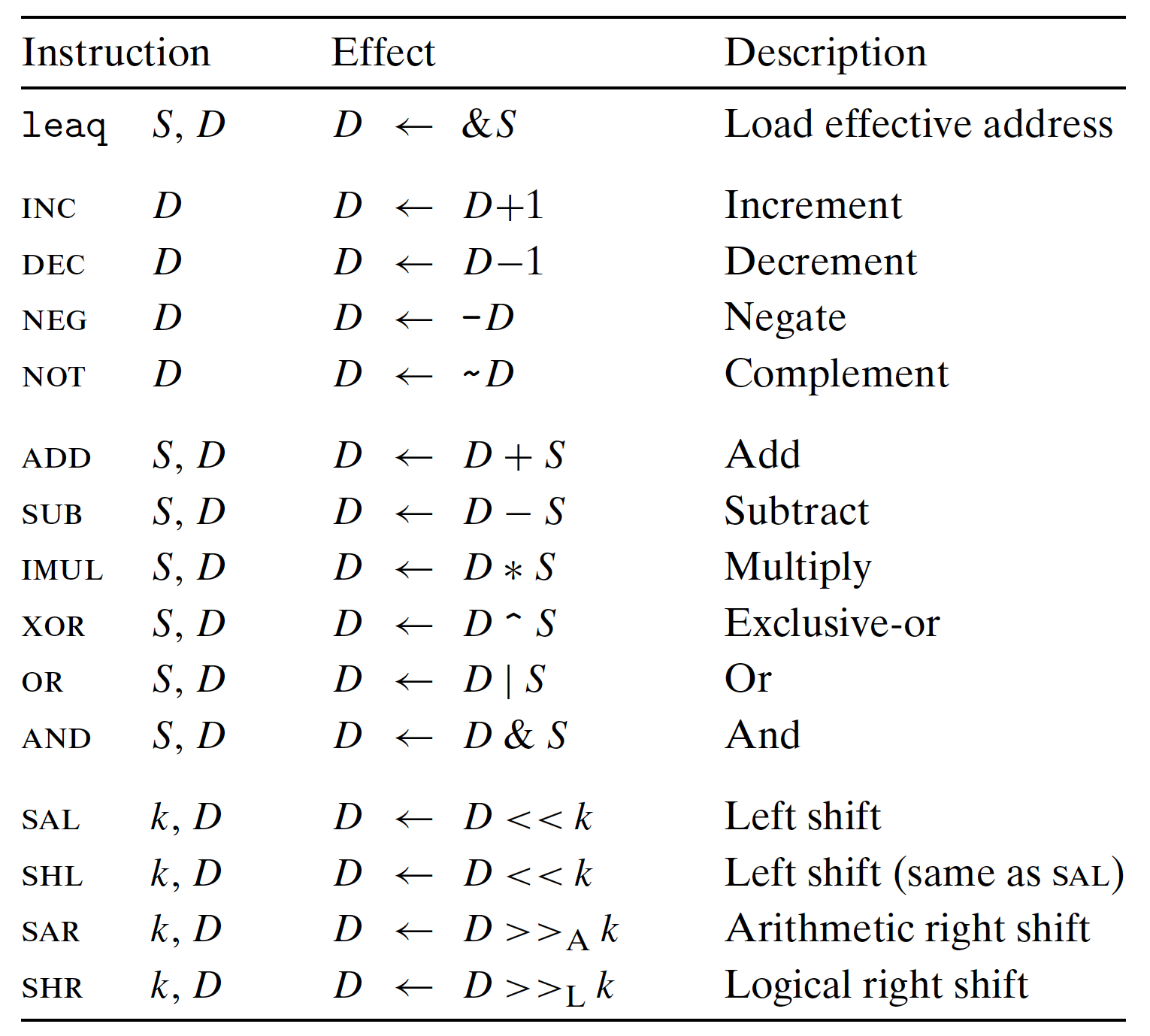
In above Integer arithmetic operations:
- For
leaq: do not update to CC, only compute the address; - For others: causes the CC to be set,
- For logical operations (e.g.
XOR),CFandOFset to 0; - For shift operations,
CFset to the last bit shifted out;OFset to 0; - For
INCandDEC:OFandZFwill be set, NO change toCF.
- For logical operations (e.g.
[Example]

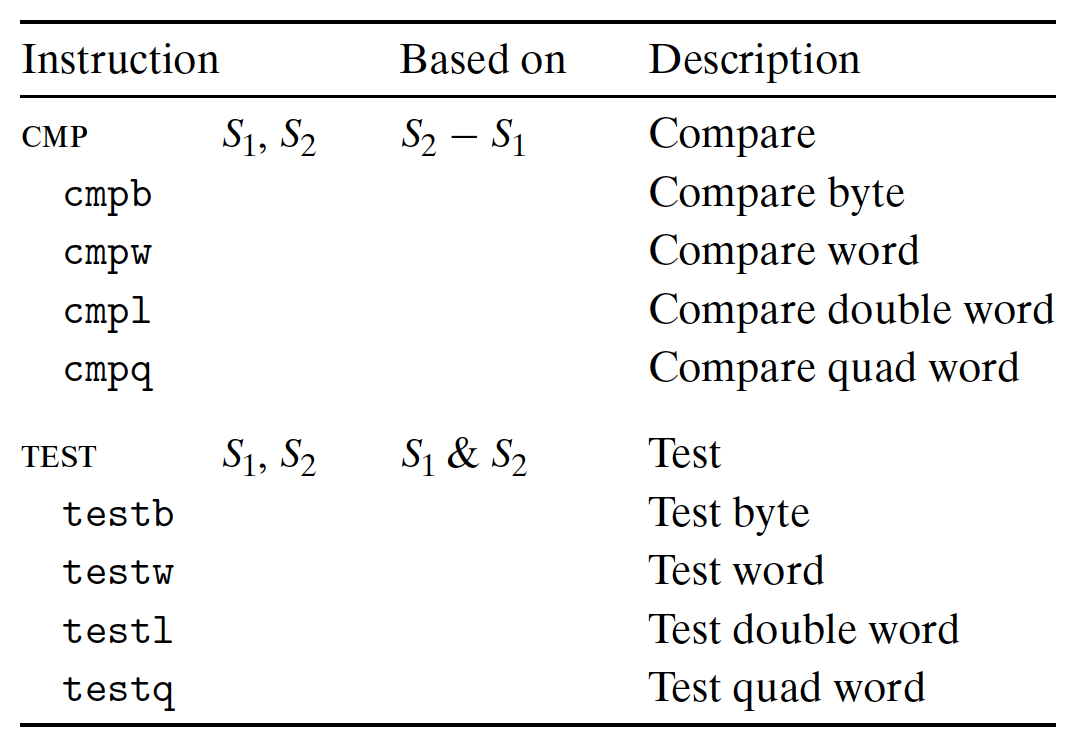
CMPandTESTset CC without changing any other registers:
CMP:
- Set CC based on the difference;
- Same as
SUB, without changing the destination; CMP S1, S2:S2-S1, in reverse order;ZF: 0 means two operands are equal;- Other flags: the ordering relation between them;

TEST:
- Same as
AND, without changing the destination; - Two same operands: to detect whether it is negative, zero or positive;
- Marked operand: to detect some specific bits.

3.5.1 Reading Conditional Codes
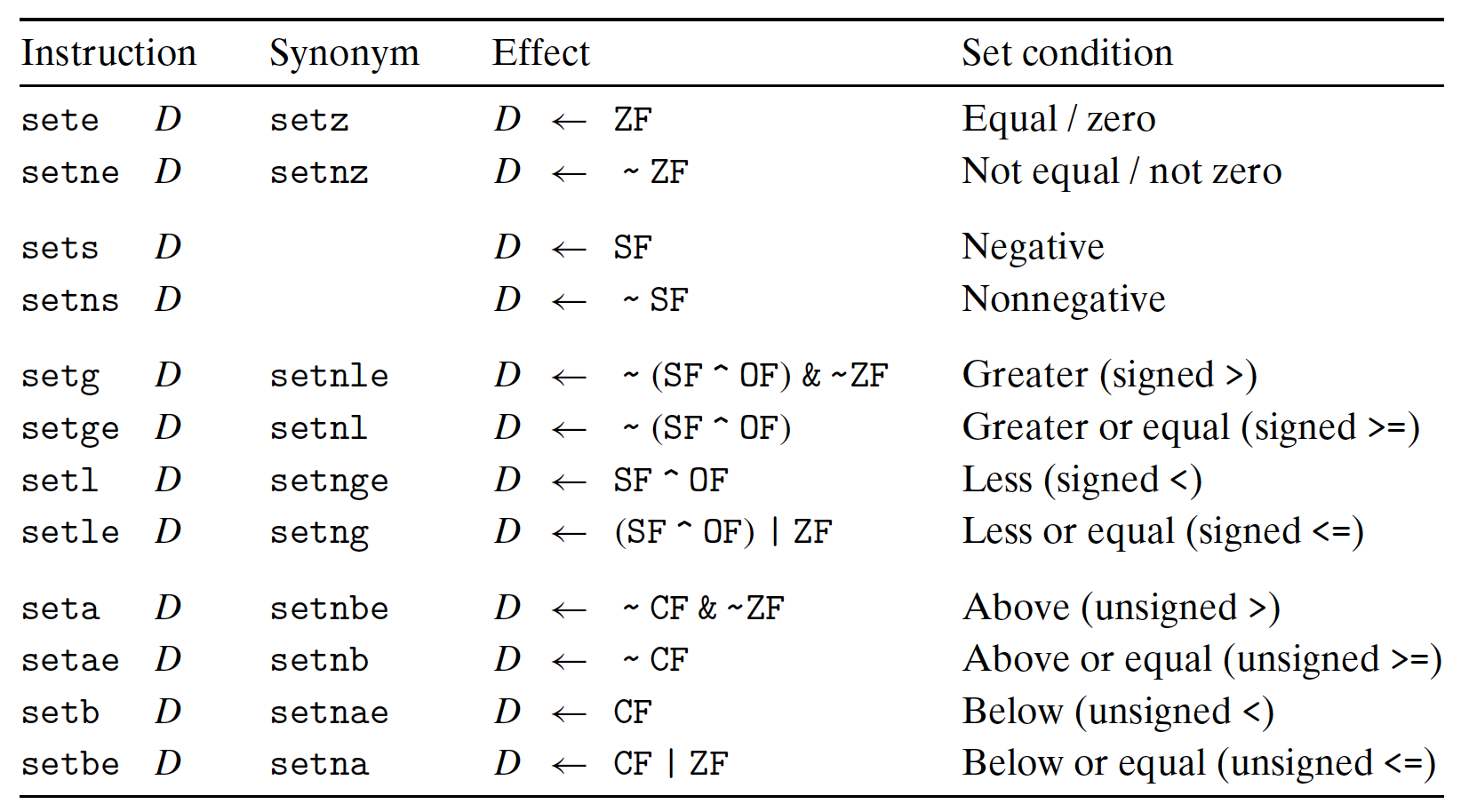
Using the CC:
- Set single bit to 0 or 1 based on the combinations of the CC;
- Conditionally jump;
- Conditionally transfer data.
For the first case, the SET instructions:
- Destination: low-order single-byte register, or single-byte memory location;
- Will not alter the remaining bytes, need to clear upper bits to 0, using e.g.
movzbl.
- Will not alter the remaining bytes, need to clear upper bits to 0, using e.g.
[Example]
For a < b expression in C:

3.6 Conditional Branches
Jumping:
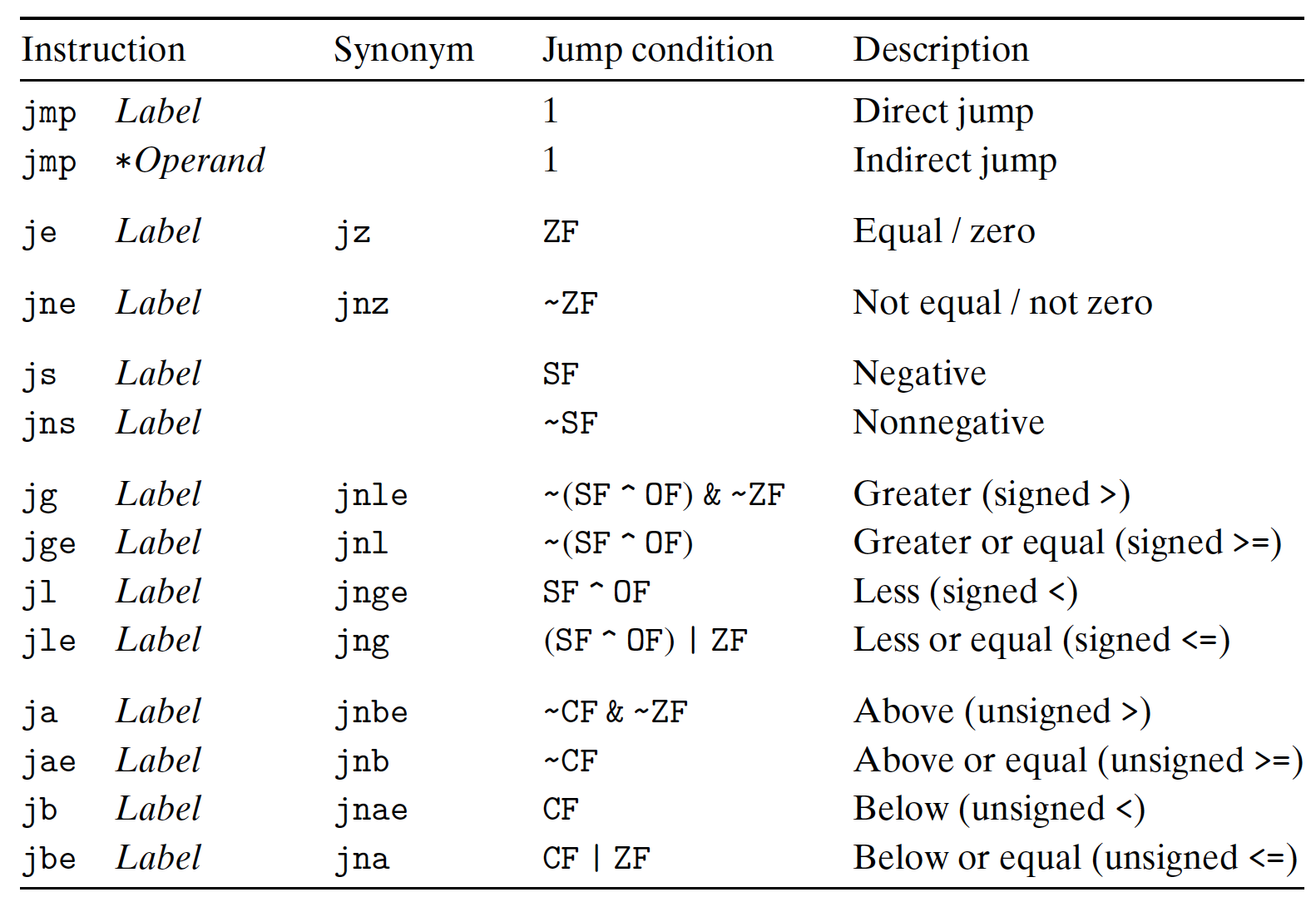
Goto Code:

General Conditional Expression:val = Test? Then_Expr : Else_Expr;

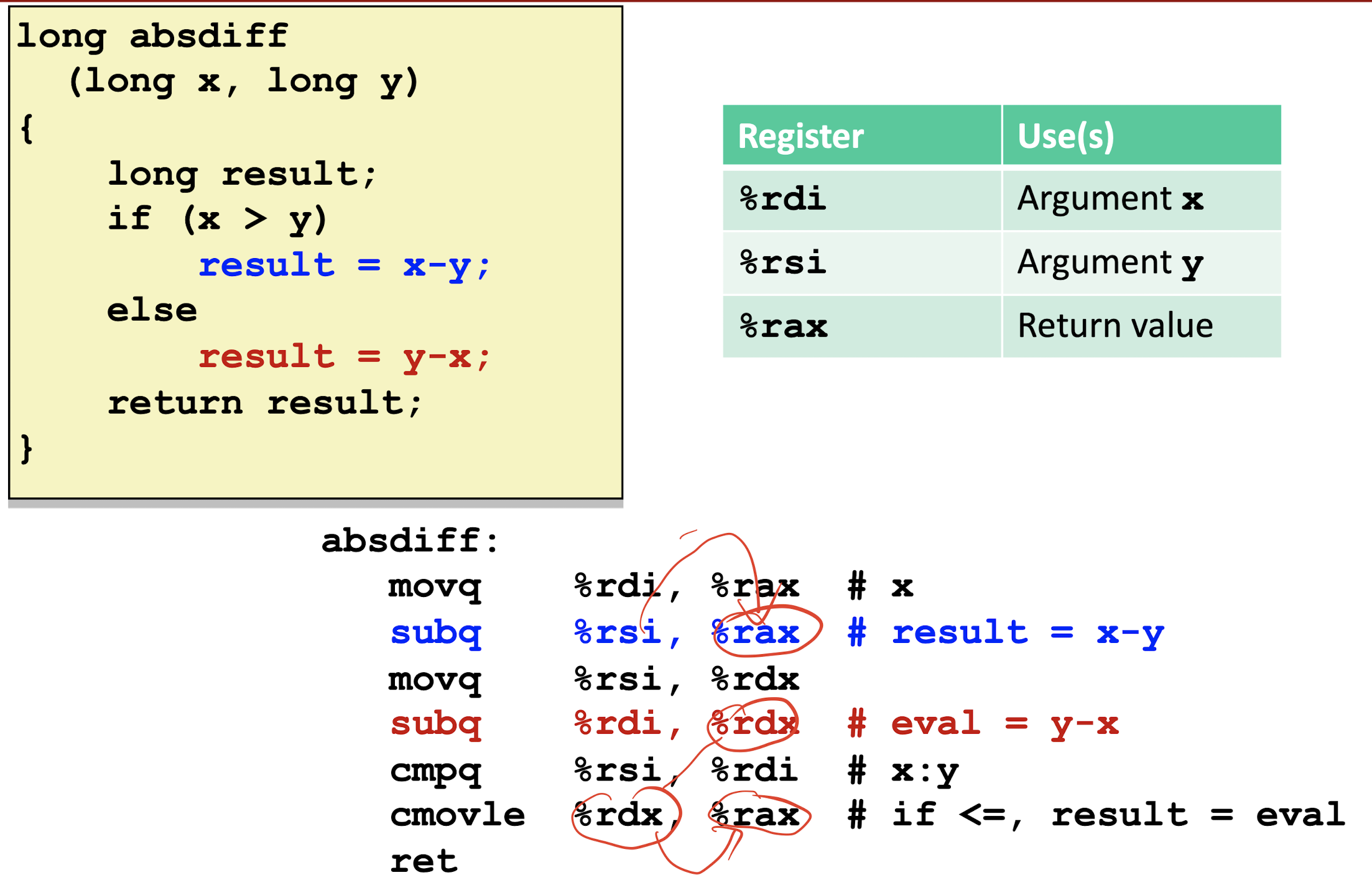
Conditional Move Branches:
All
Then_ExprandElse_Exprwill be executed, not required jump to save time.
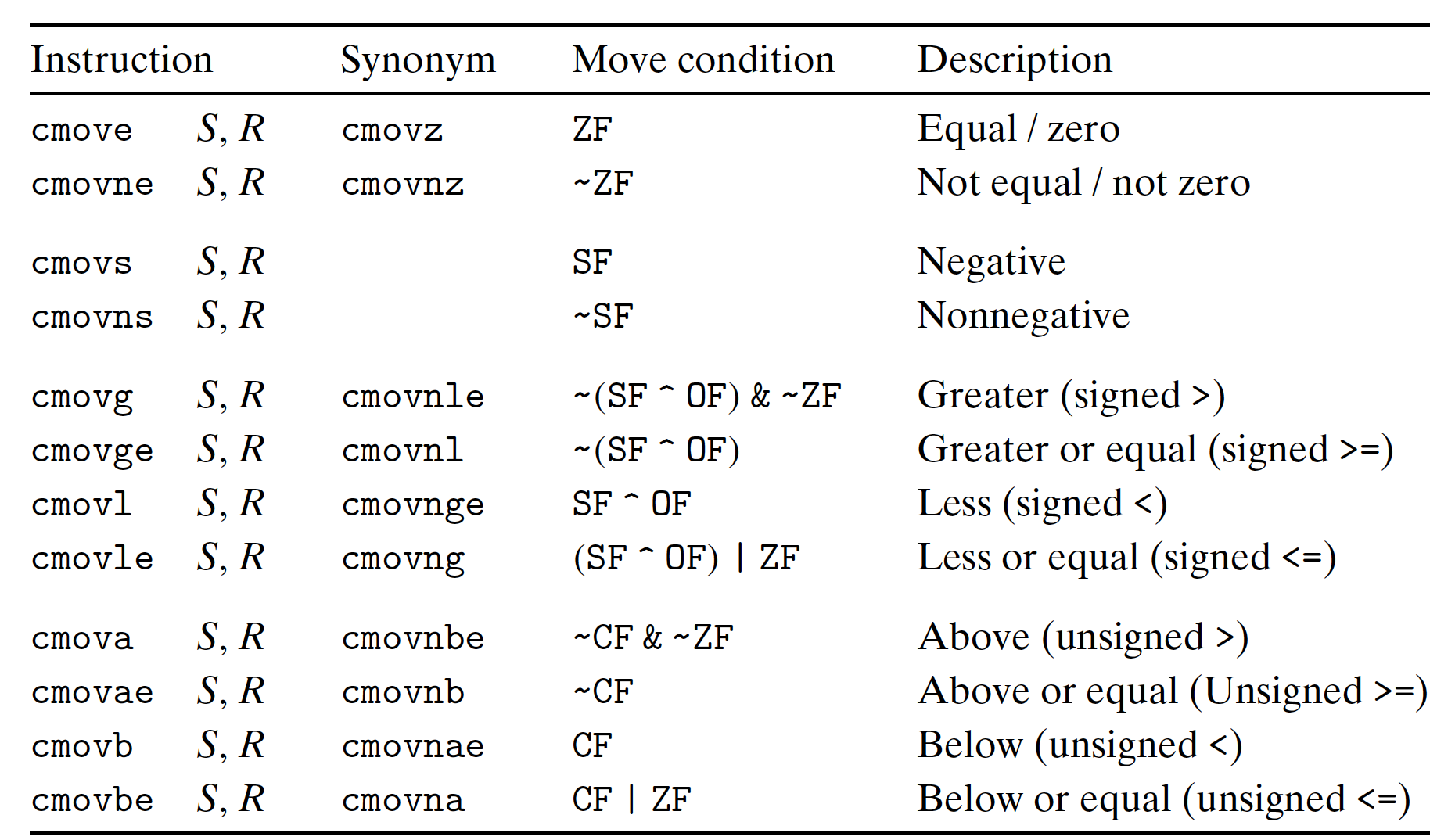

Bad Cases for Conditional Move:
Expensive Computations
val = Test(x) ? Hard1(x) : Hard2(x);- Both function need to be executed;
- Only use it when computations are very simple;
Risky Computation
val = p ? *p : 0;- Both value get computed;
- May be
*0, null pointer, error! - May have undesirable effect.
With side effects
val = x > 0 ? x*=7 : x+= 3;- Both value get computed;
- Same variable got change;
- MUST be side-effect free!
3.6 Loops
3.6.1 Do-while Loop



3.6.2 While Loop
- Jump-to-middle Translation
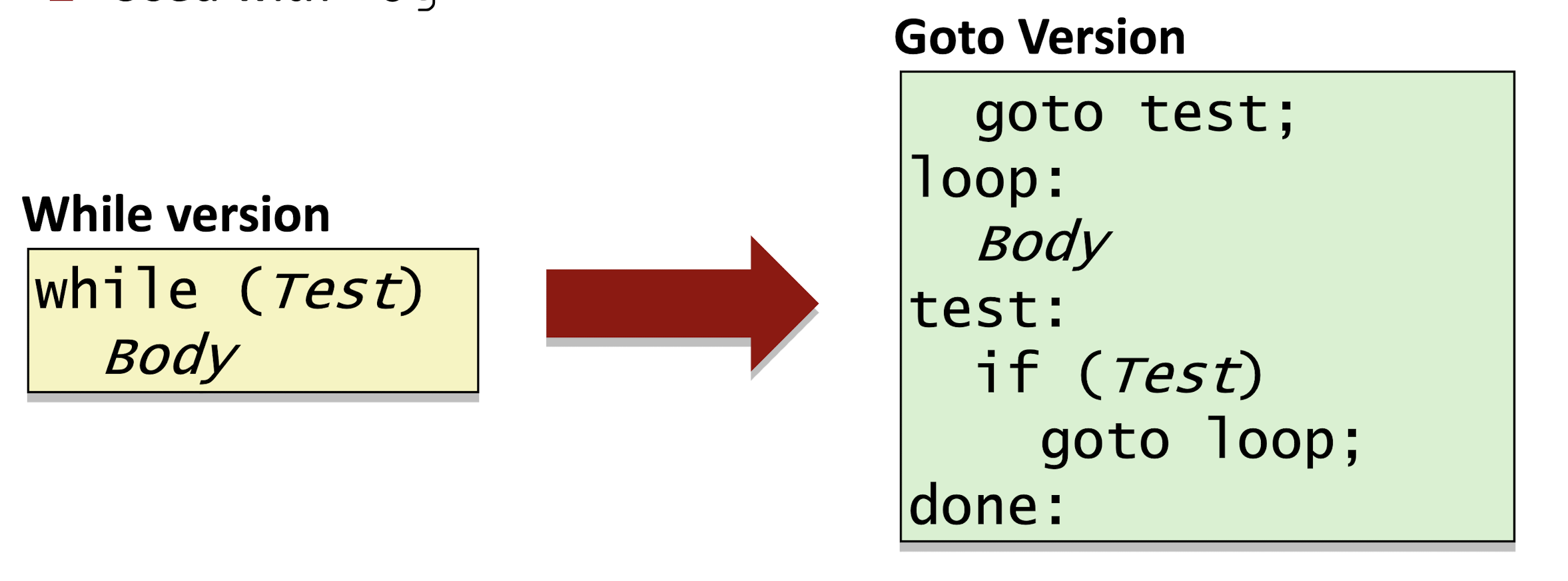

Jump to the test at very beginning, then jump to the middle for body.
- Do-while translation
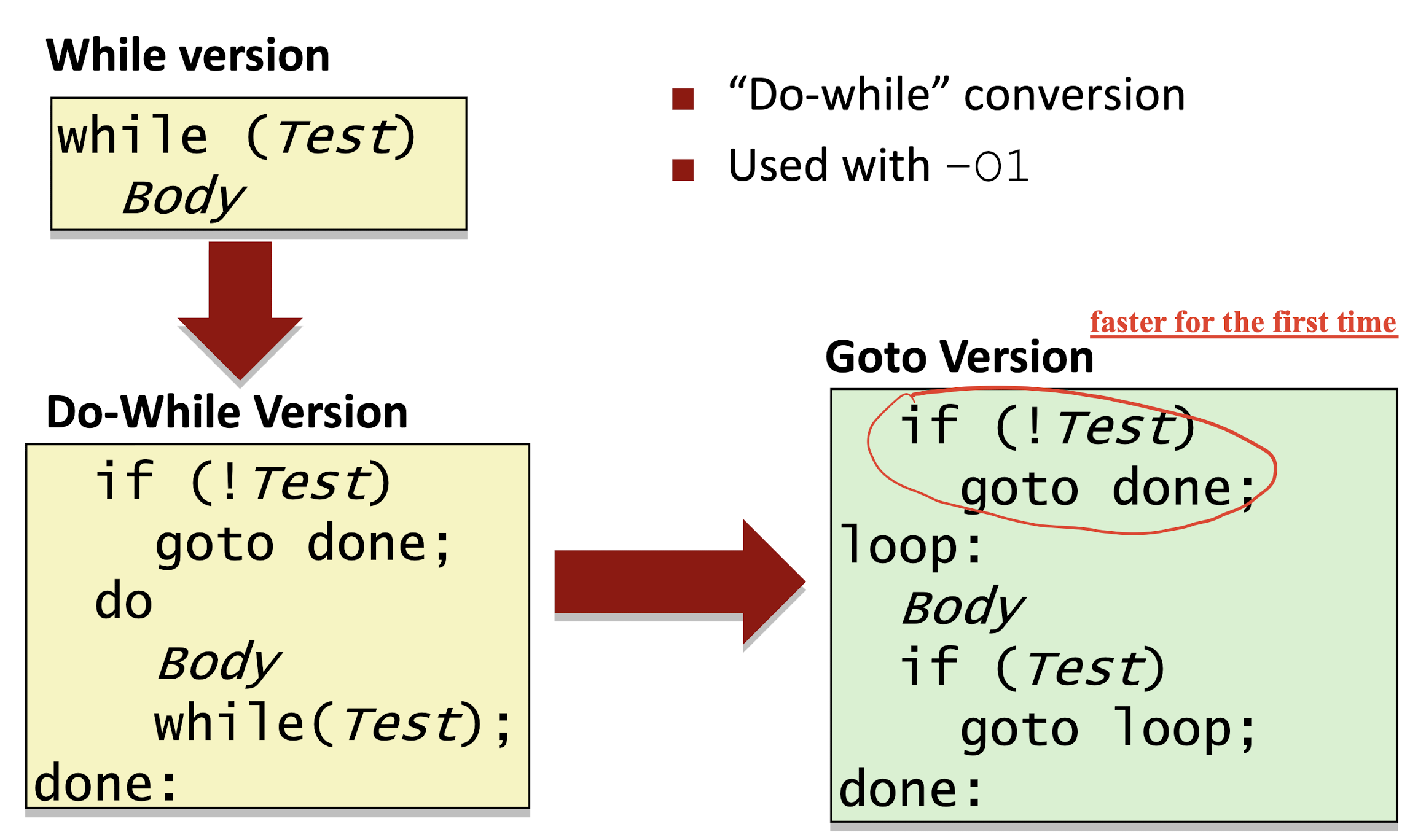

3.6.3 For Loop

For-while conversion:

For to Do-while conversion:

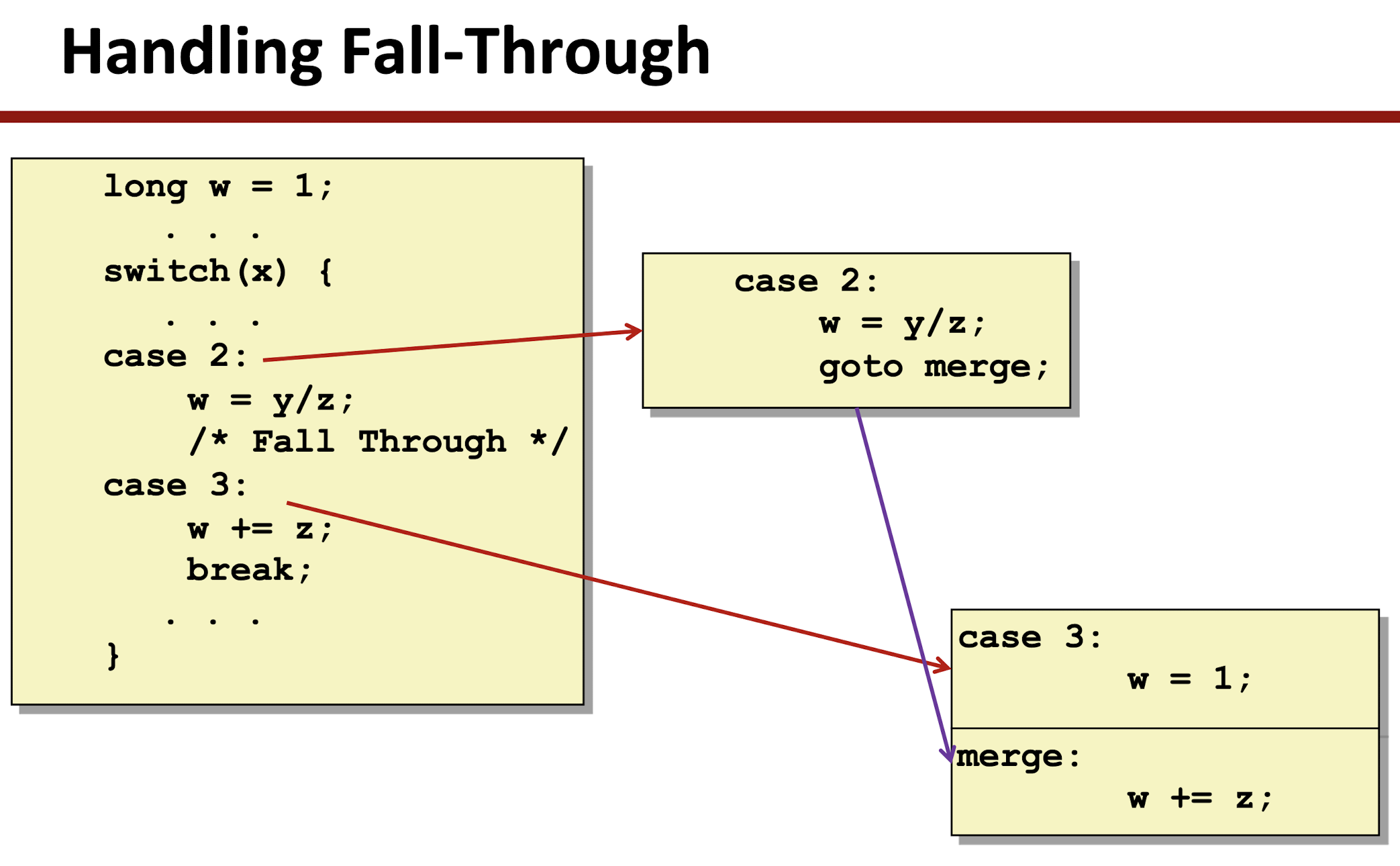
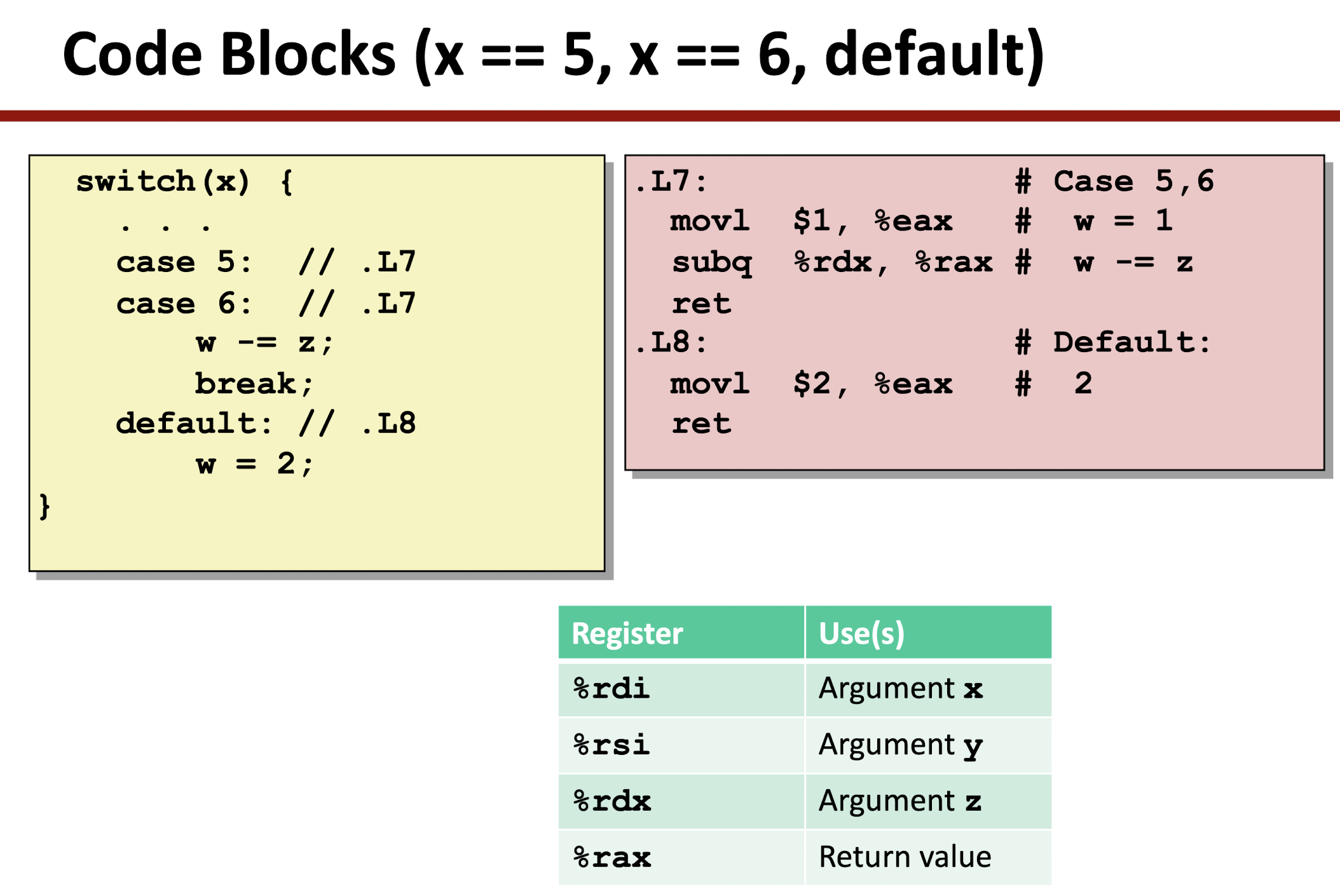
3.7 Switch Statement

- Check the range of
x:

- Take the jump table as a Array, using indirect jump to assess memory jump target:

jmp: unconditionally jump, direct and indirect jump:- direct jump: jump target encoded in the instruction, giving the target label, e.g.
jmp .L1;
- indirect jump: jump target read from register or memory address, using
*following by an operand specifier, e.g.,jmp *%rax: register jump target;jmp *(%rax): memory location target;
- direct jump: jump target encoded in the instruction, giving the target label, e.g.


4 Processor Architecture
4.1 Instruction Set Architecture
Y86-64 programmer-visible state
The programmer can access and modify these processor state.
Similar to x86-64, but more simpler and less compact.
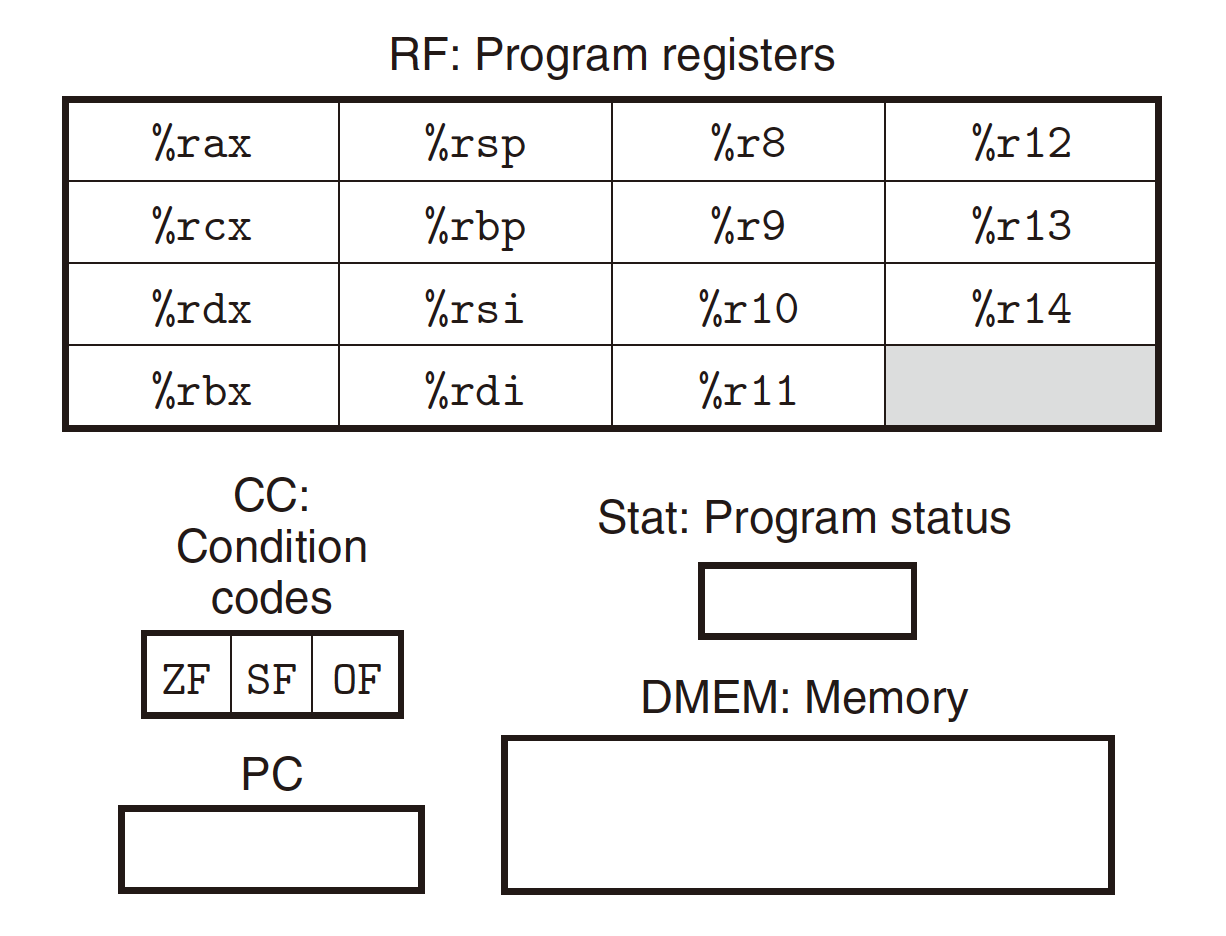
Comparing with the register part of x86-64:
Y86-64 Program Registers
- 15 Program Resister;
- No
%r15, to simplify the encoding; - 64-bit word, 8 words;
%rspfor Stack Pointer, NO fixed meaning or value for others.

Condition Codes
- CC: Condition Code;
- 3 single-bit codes;
- ZF, SF, OF;
- ZF: Zero Flag. The most recent operation yielded zero.
- SF: Sign Flag. The most recent operation yielded a negative value.
- OF: Overflow Flag. The most recent operation caused a two’s-complement overflow—either negative or positive.
Program Counter
- PC: Program Counter;
- Store the address of currently executing instruction.
Memory
- Virtual memory;
- In the Operand forms, only represented in base and displacement, NO index and scale in x86-64.
Program State
- Stat: Program State;
- The overall state of program execution;
- Normal operation or exception.
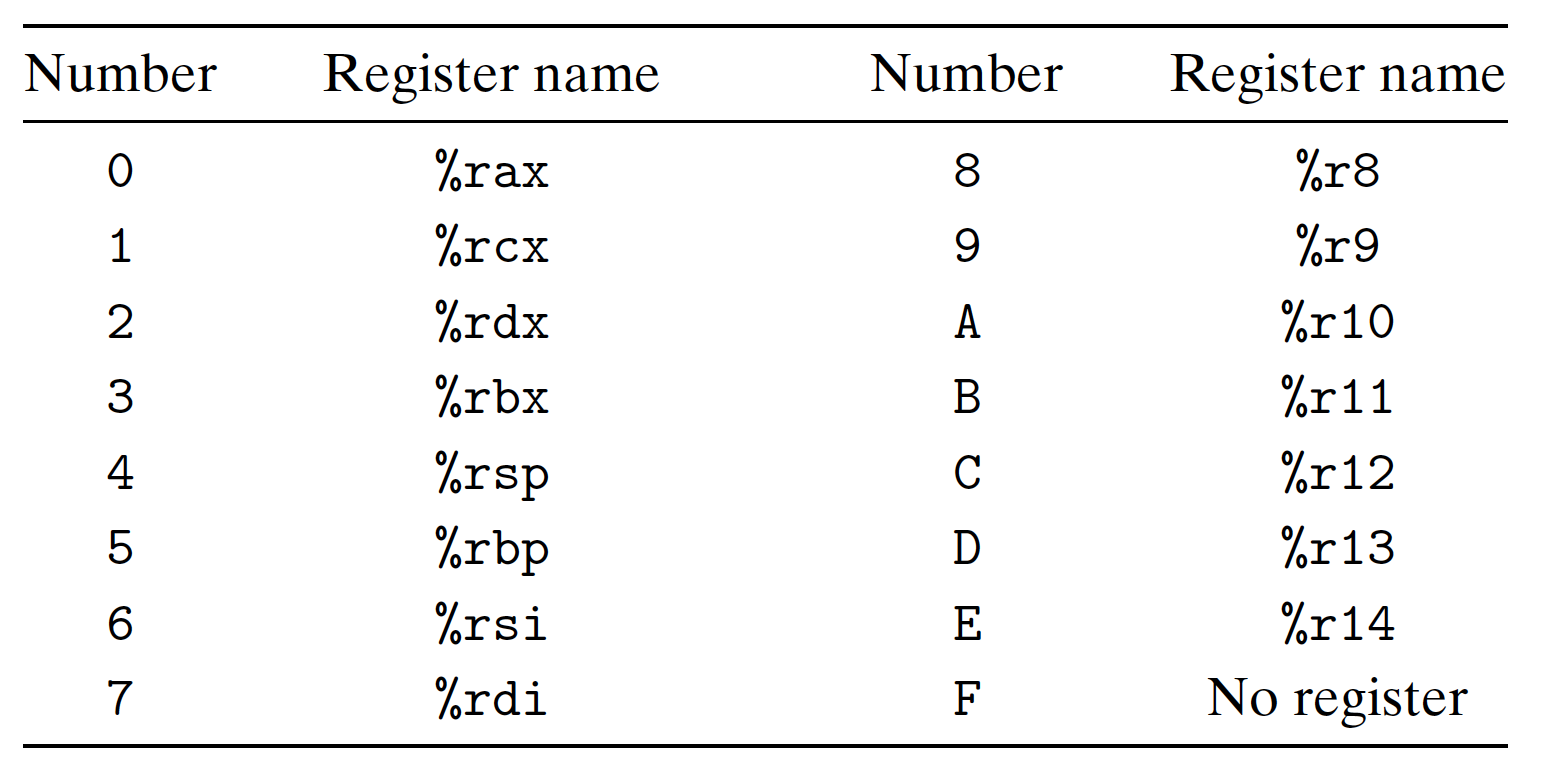
Y86-64 Instructions
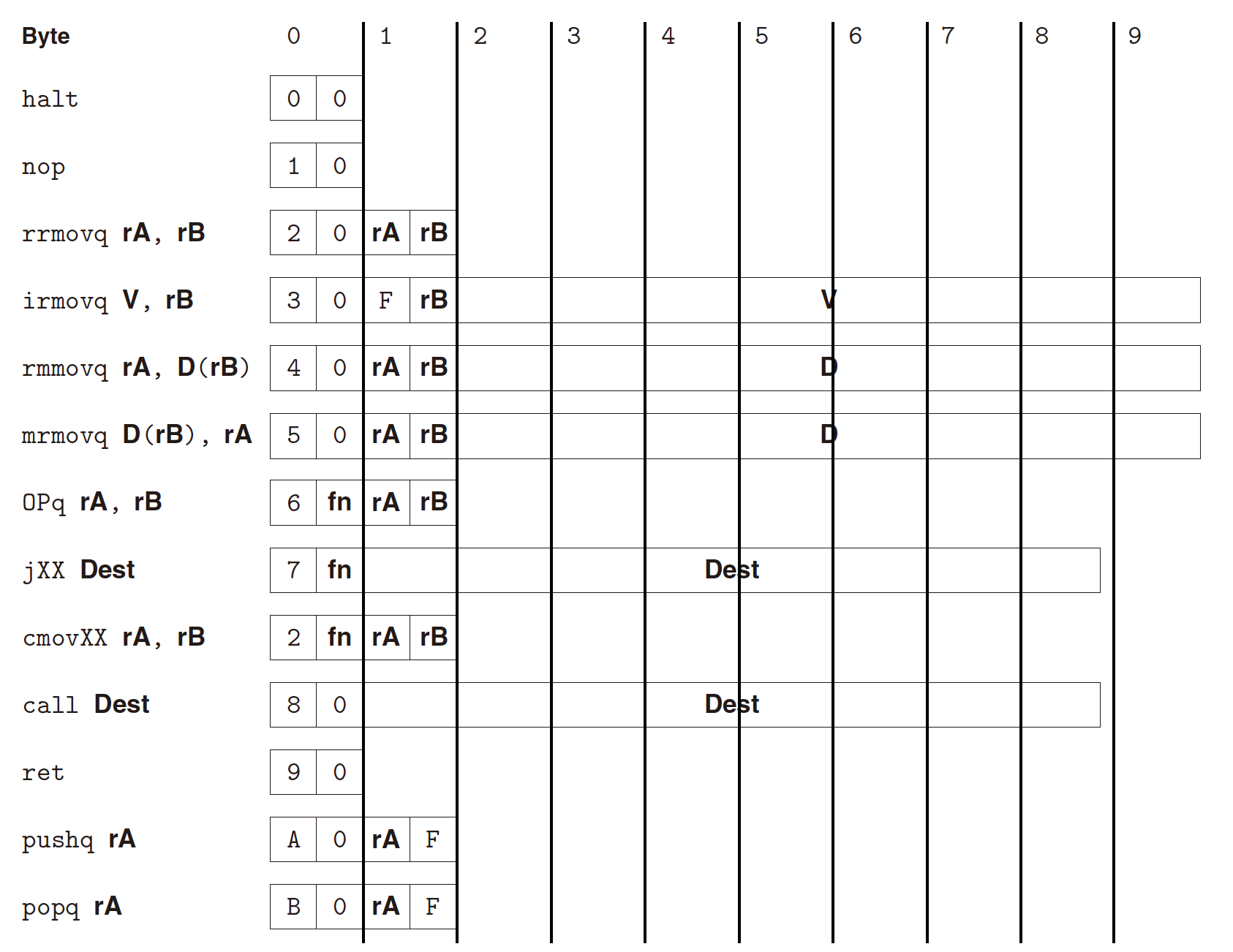
- A subset of x86-64 instruction set;
- 8-byte integer operations;
- fewer address modes;
- smaller set of operations;
- Each instruction set including:
- 1-byte instruction specifier (e.g.,
0|0forhalt), including(op|fn):- 4-bit operation code(
op) and, - 4-bit function code(
fn) to specify a particular function ;
- 4-bit operation code(
- (possibly) 1-byte register specifier (e.g.,
rA|rB,F|rB); - (possibly) 8-byte constant word (e.g.,
V,D,Dest);
- 1-byte instruction specifier (e.g.,
- 4 types of instruction: 1-byte, 2-byte, 9-byte, and 10-byte instruction;
- 1-byte:
halt,nop,ret(only instruction specifier); - 2-byte:
rrmovq rA, rB,OPq rA, rB,cmovXX rA, rB,pushq rA,popq rA(only instruction specifier + register specifier); - 9-byte:
jXX Dest,call Dest(only instruction specifier + constant word); - 10-byte:
irmovq V, D(rB),rmmovq rA, D(rB),mrmovq D(rB), rA(instruction specifier + register specifier + constant word);
- 1-byte:
- Encoded in hexadecimal value.
movq Instructions:
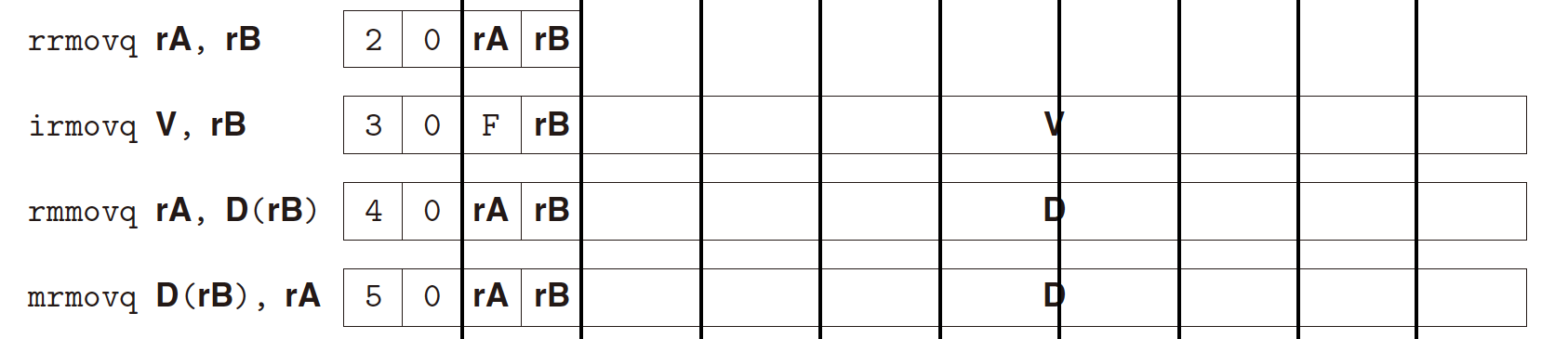
- subset of x86-64 movq instruction set;
- Indicating the movement: source $\to$ destination;
- Source: first character - immediate(
i), register(r), memory(m); - Destination: second character - register(
r), memory(m);
- Source: first character - immediate(
- NO memory(
m) location $\rightarrow$ another memory(m) location; - NO immediate(
i) data $\rightarrow$ memory(m);
The movement is from the first argument to the second argument, usually
rA(V)$\to$rB,
exceptmrmovq D(rB), rA, which isrB$\to$rA
The immediate value(
V) and displacement(D) is 8-byte constant word.memory reference: only base and displacement(e.g.,
D(rB),rBfor base,Dfor displacement), NO second index register or scale;
OPq Integer Operation Instructions:
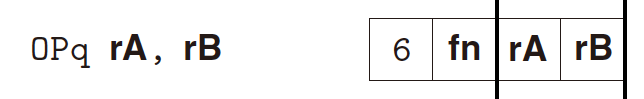
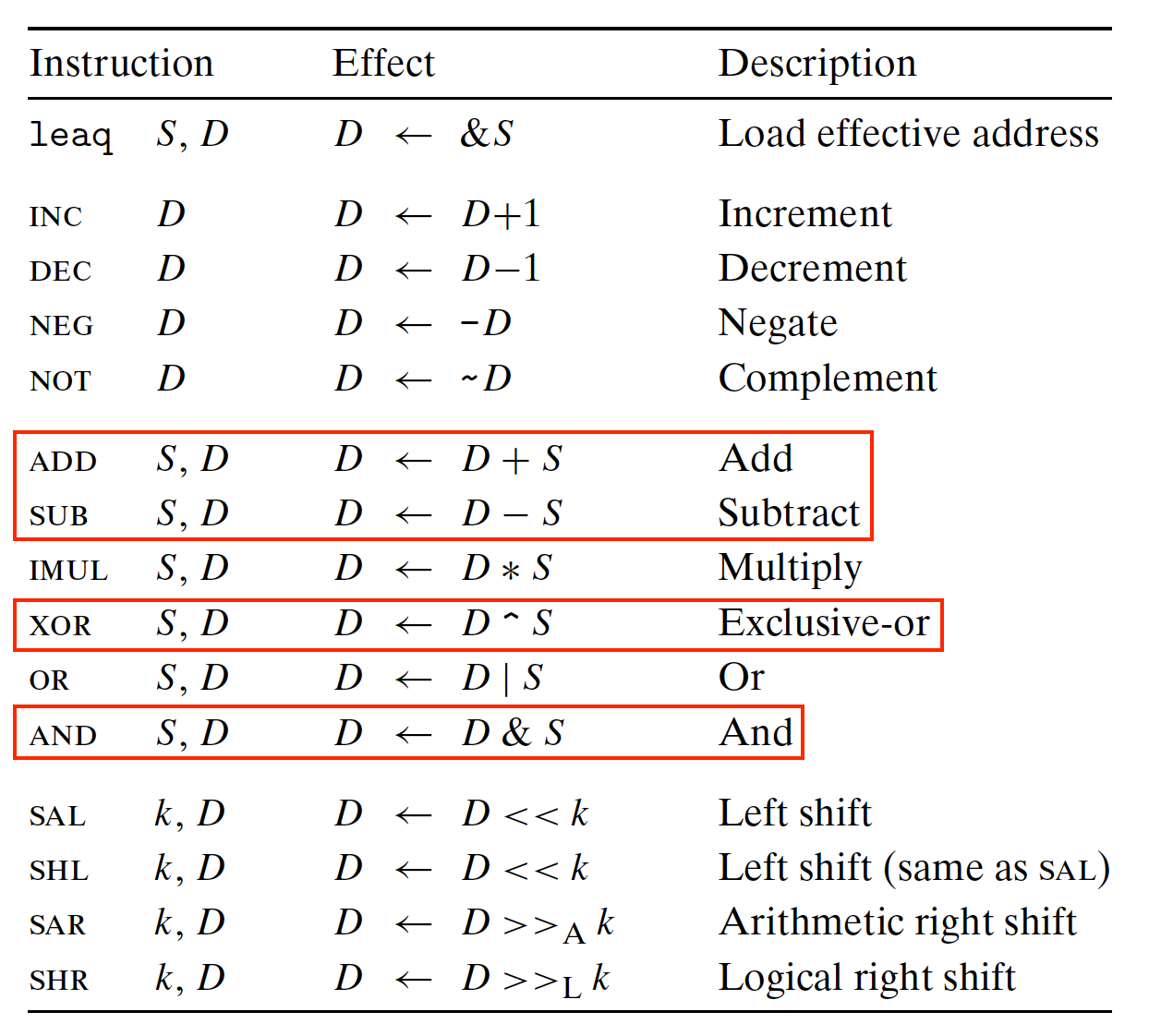
- subset of x86-64 Integer arithmetic operations;
- 2-byte instruction;
- 4 instructions:
addq,subq,andq,xorq; - Only operate on register data, NOT on memory data;
- Sets 3 conditional code
ZF,SF, andOF. - Function code for
fn:
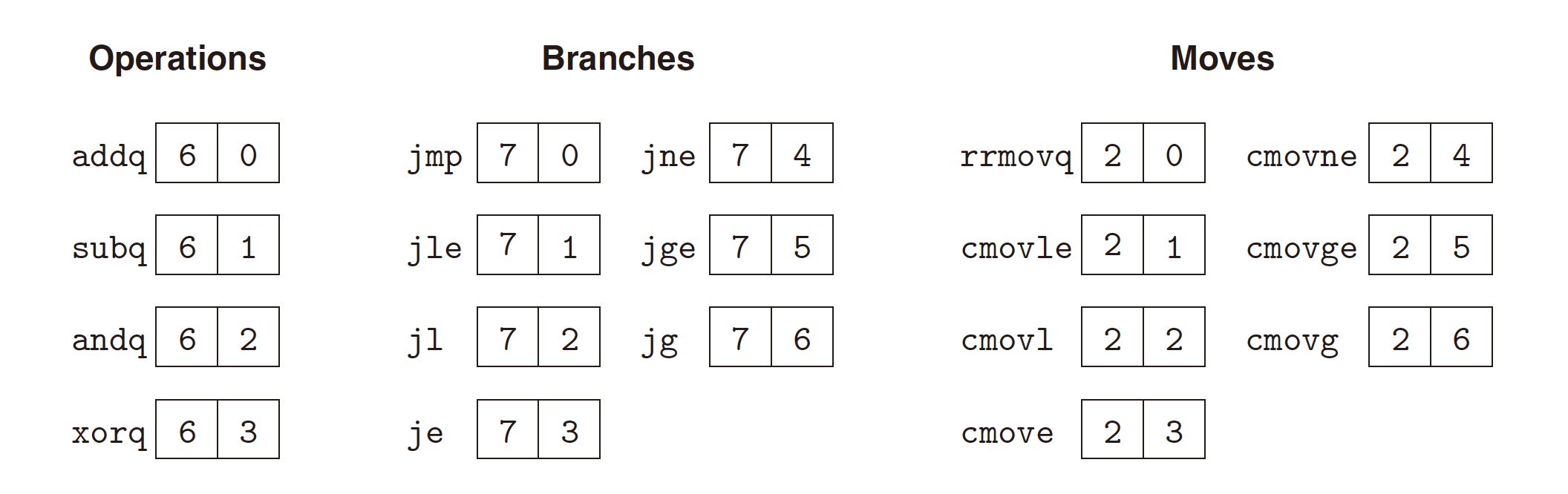
4.2 Logic Design
4.2.1 Logic Gates
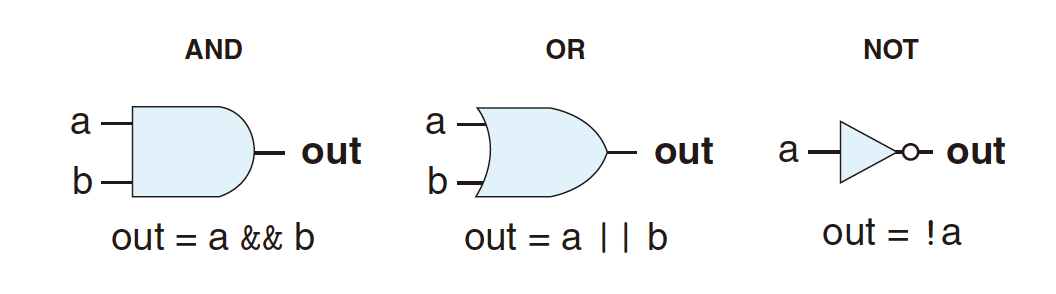
- With some delay
4.2.2 Bit Equality
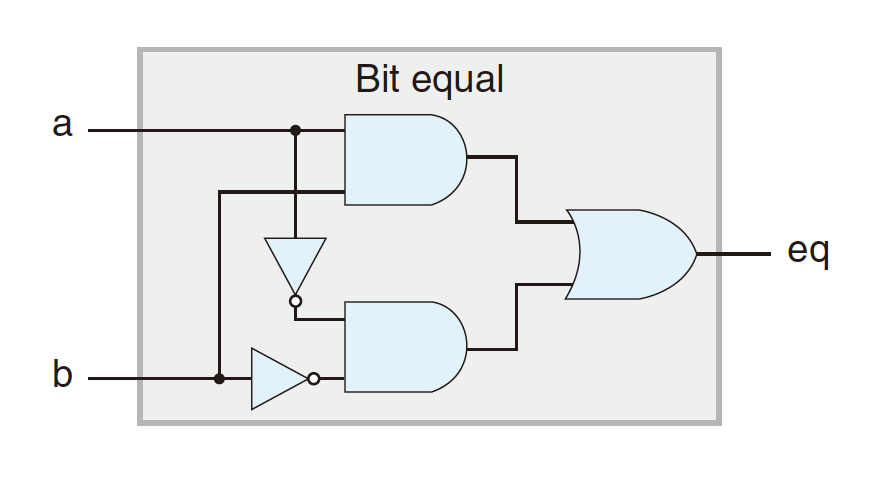
bool eq = (a&&b)||(!a&&!b)- Generate 1 if a and b are equal;
Word Equality (64-bit):
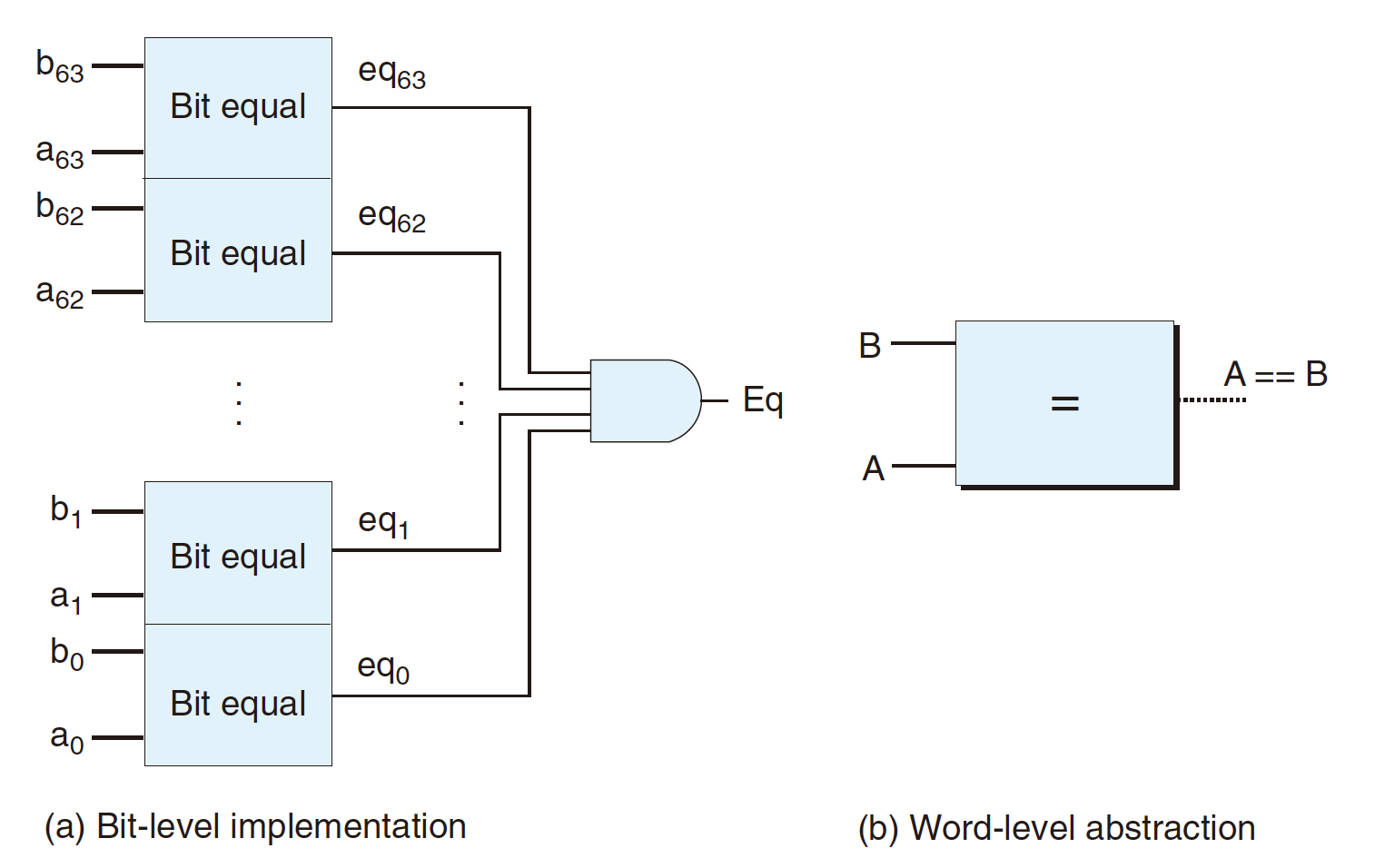
4.2.3 Word Multiplexor
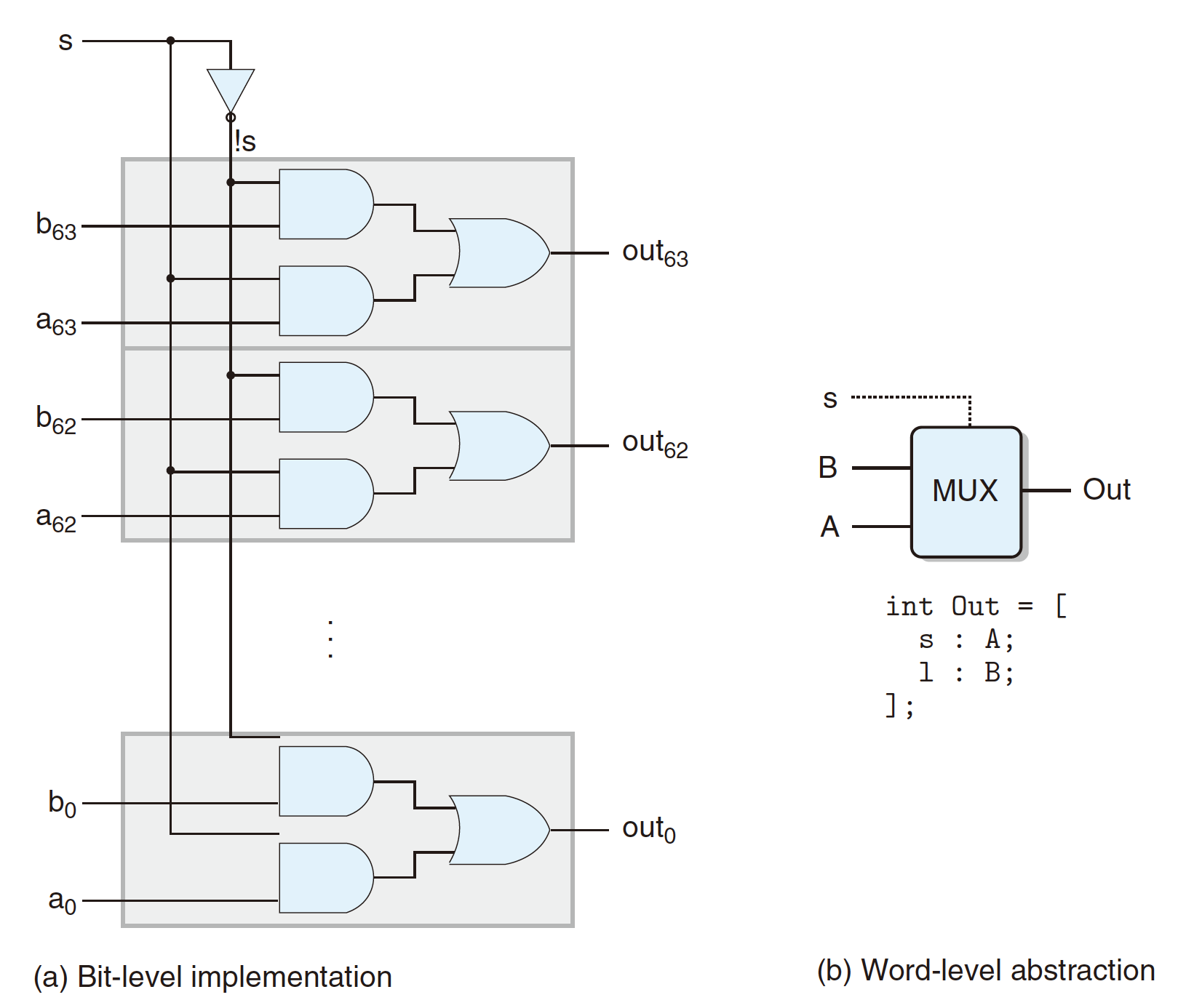
- Select input word
AorBdepending on control signals;
1 | |
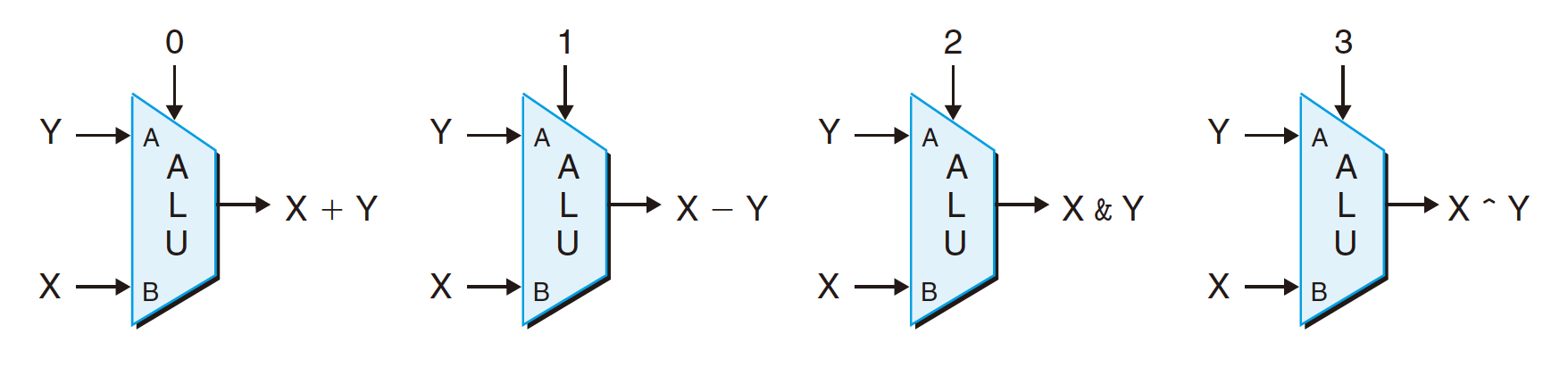
4.2.4 Arithmetic Logic Unit
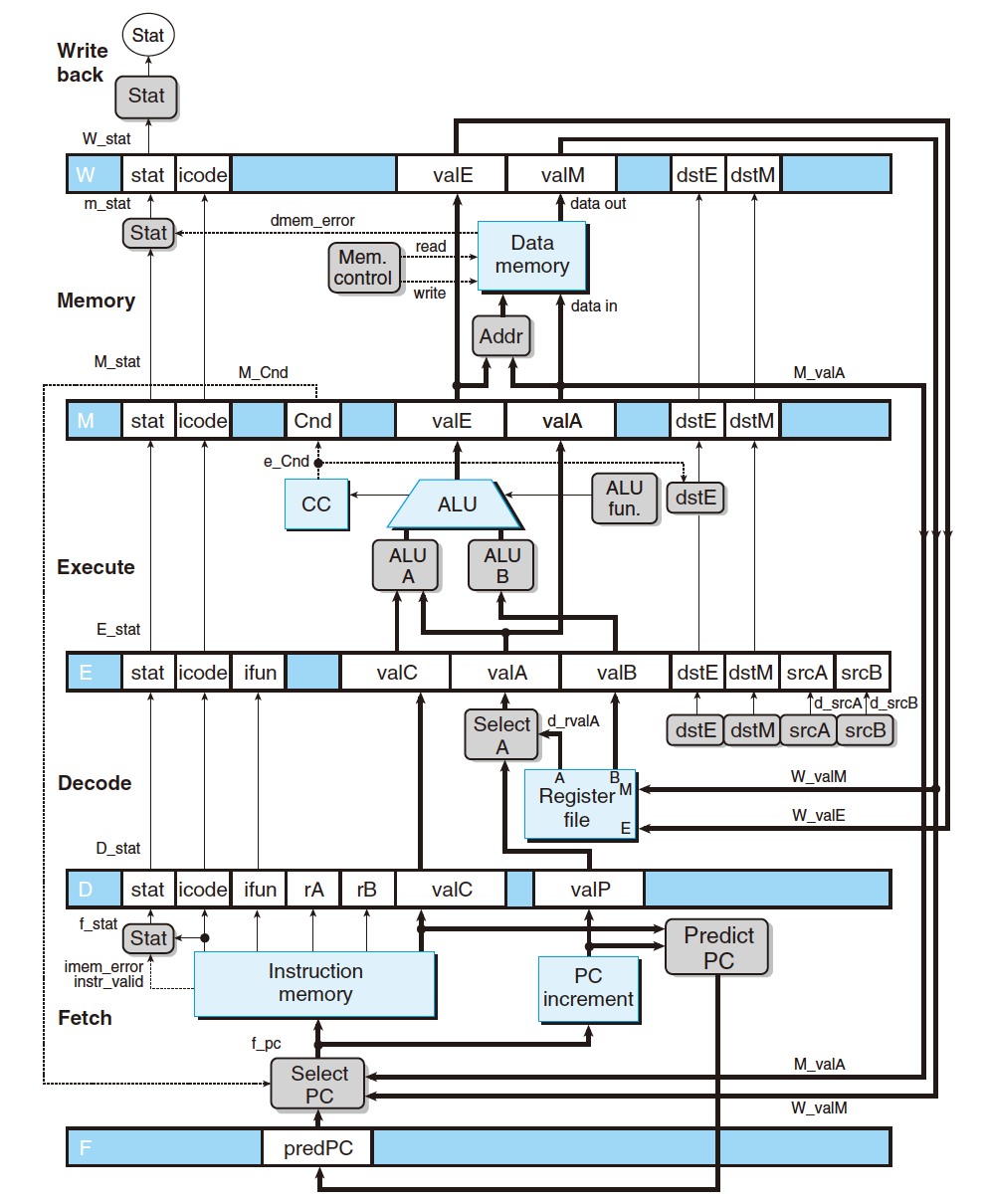
4.3 SEQ Stages
3 Important Components: Combinational Logic, Storage Elements and Clock.
6 stages: Fetch, Decode, Execute, Memory, Write Back, and PC Update.
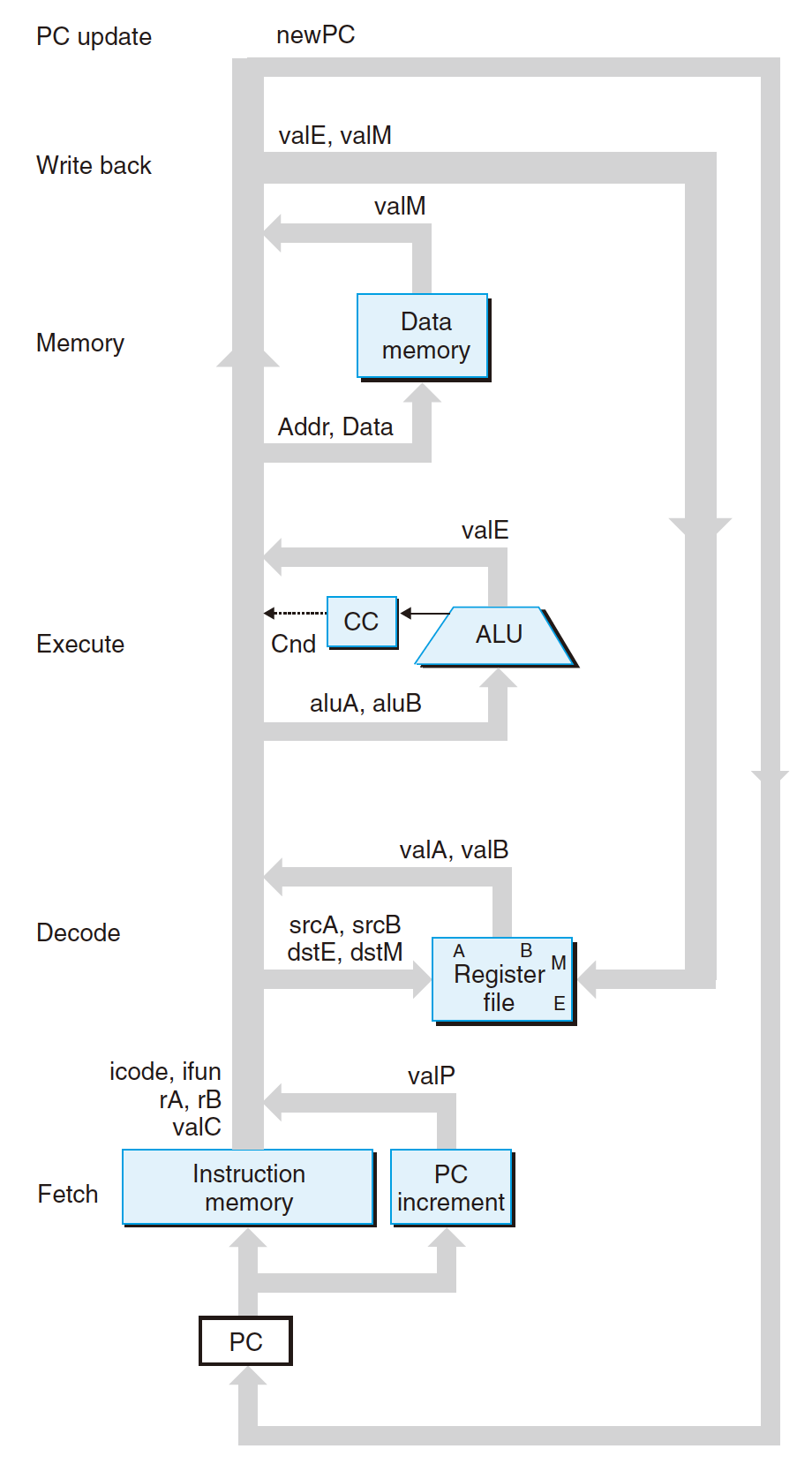
4.3.1 Fetch
- According to the PC as the RAM address, read instruction byte from memory;
- Read first two 4-bit(1 Byte) instruction specifier byte, including the
icodeandifun; - Read the register specifier byte -
rAandrB; - Read 8-byte constant word -
valC; - Compute the next instruction address following the current one,
valP = PC + len(fetched instruction)
4.3.2 Decode
Read register value from Register File.
- Read from
rA,rB; - Assign value to
valAandvalB; - OR read from stack pointer
%rsp(e.g.,pushq,popq,call,ret).
4.3.3 Execute
- The ALU(Arithmetic/Logic Unit):
- Do the operation based on the
ifun, or - Compute the effective memory address(e.g., base address
ADDdisplacement), or - Increase or decrease the stack pointer.
- Do the operation based on the
- Assign the result value to
valE; - Set the
CC(Condition Code);
For
cmovXX(conditional move) andjXX(jump) instruction:
This stage will evaluate theCCwithifun(move condition OR jump condition);
if condition holds, do the move or jump.
4.3.4 Memory
- 8-byte;
- Write data into memory, usually write into $M_8[valE]$;
- Read data from memory, store in
valM.
4.3.5 Write Back
- Write the data back to register from the Decode Stage (e.g.,
rA,rB,%rsp)
4.3.6 PC Update
- Set
PC(Program Counter) to the address ofnext instruction; - In Fetch Stage,
valP = PC + len(fetched instruction)does not update the value ofPC, but in this Stage, assign valP toPCto truly updatePC,PC = valP; - Based on execute result, set
PCtovalCorvalP(e.g., injXXorcmovXX).
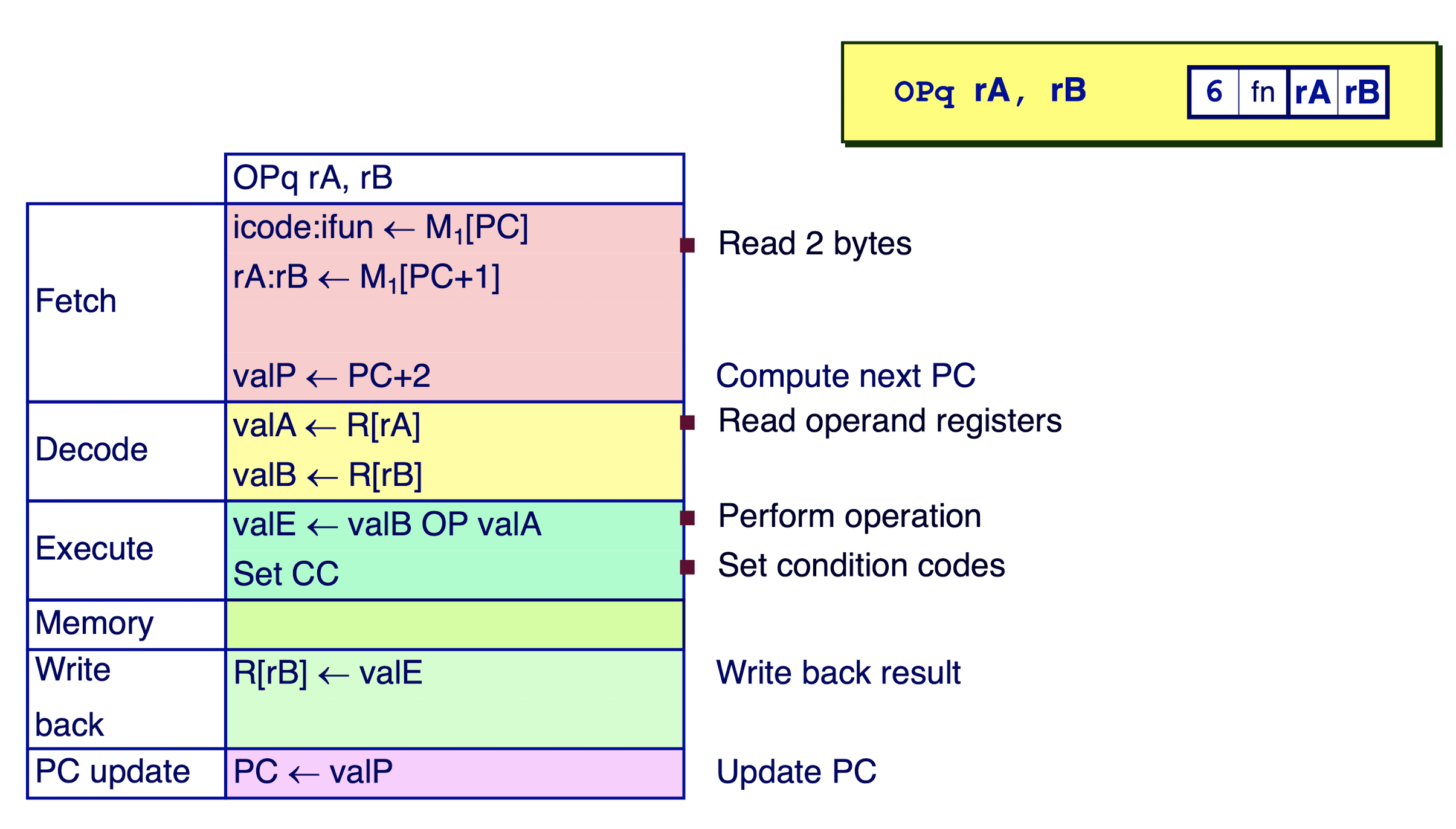
Executing Arith. / Logical Instruction:
Executing Move Instruction: rmmovq:
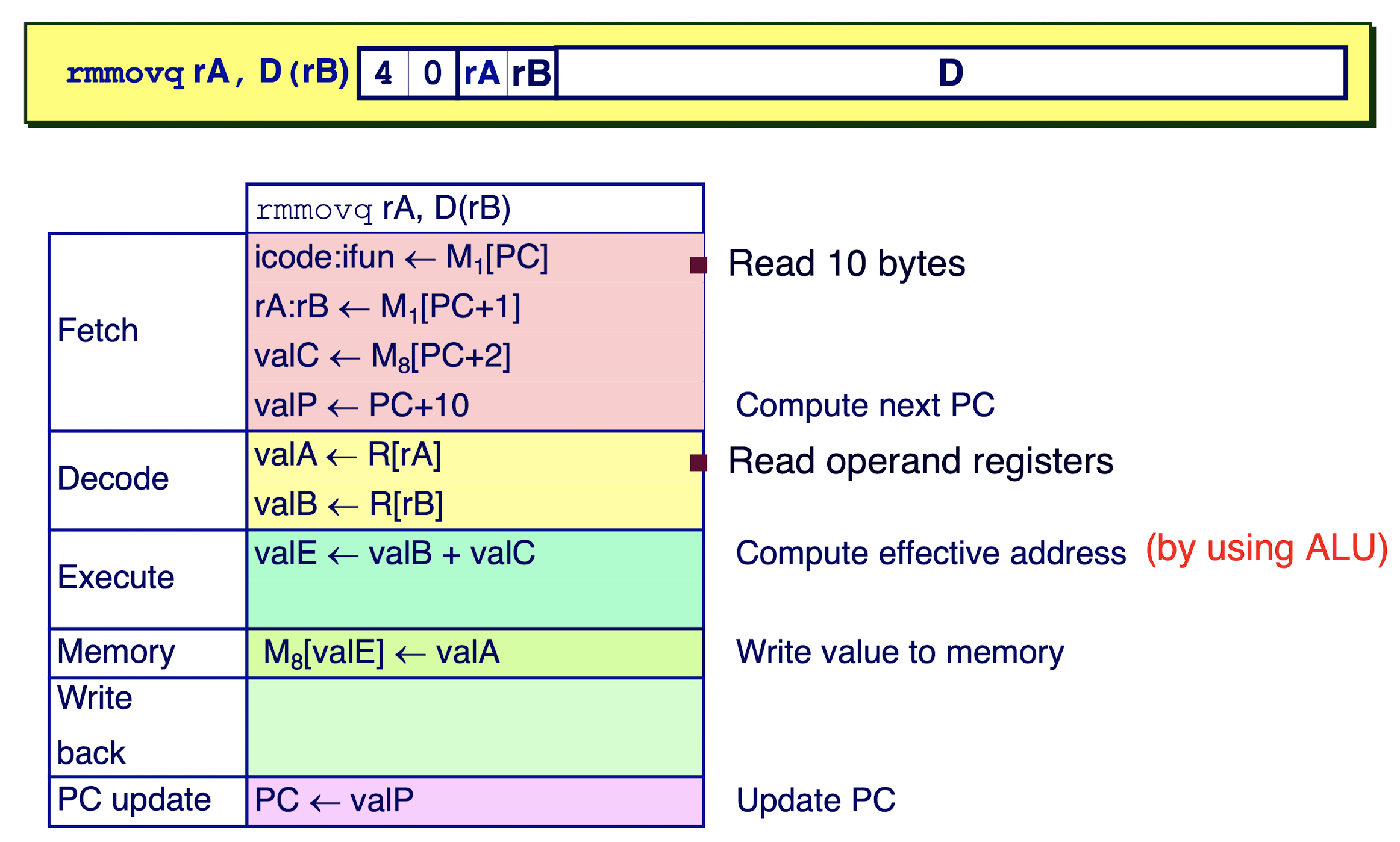
Executing Jumps:
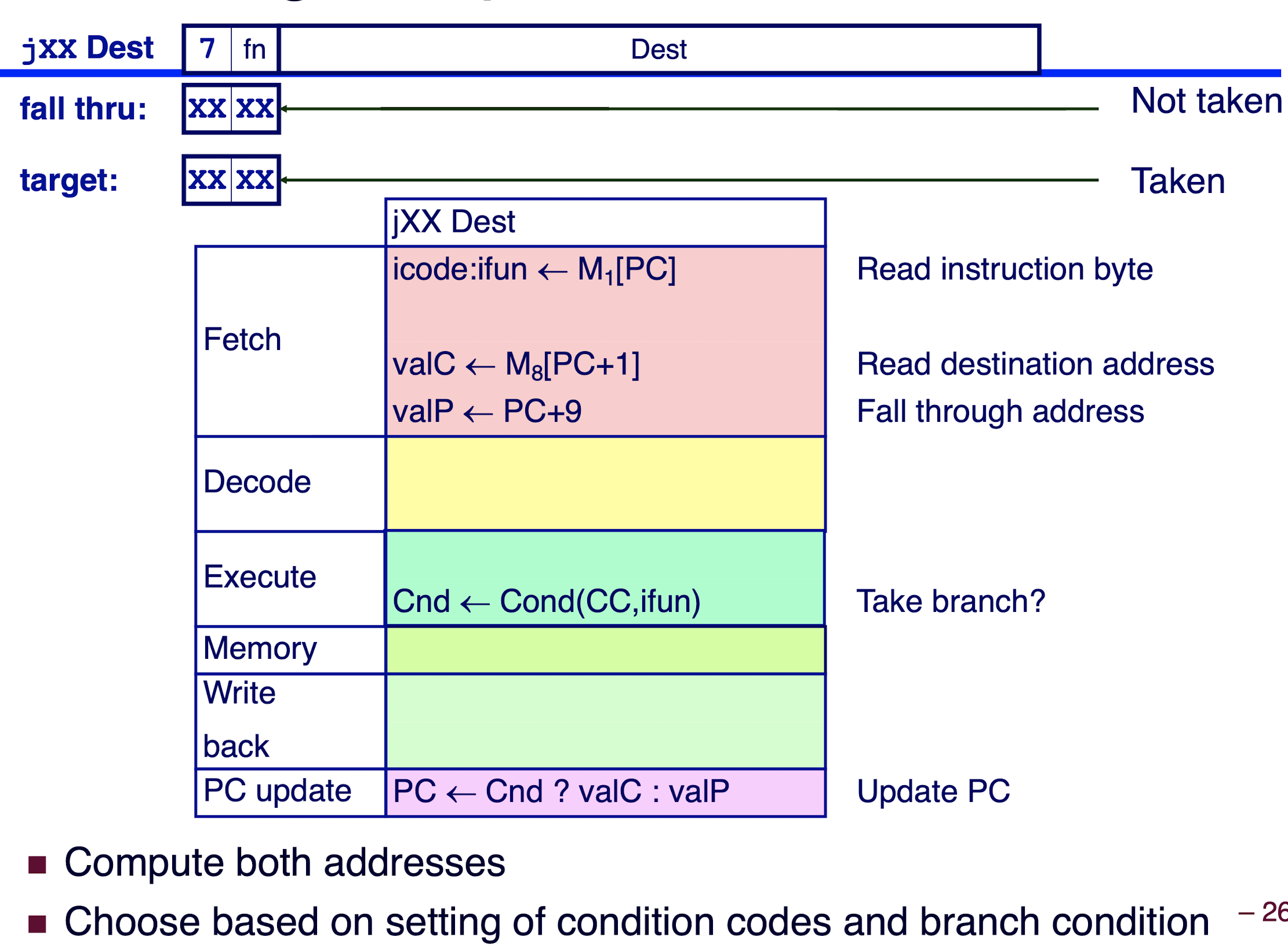
4.4 Pipelining
Unpipelined:
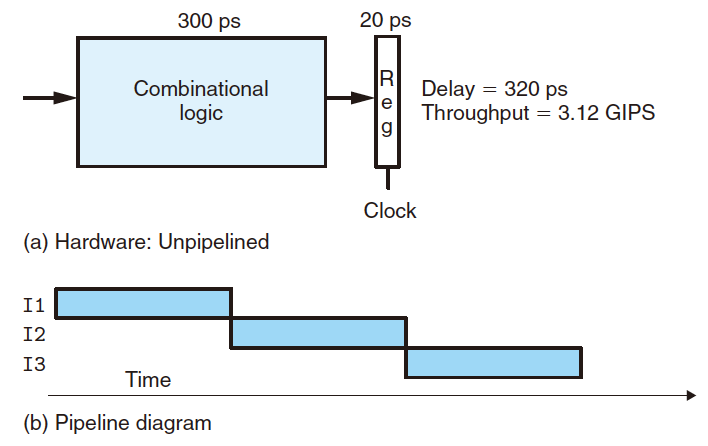
Pipelined:
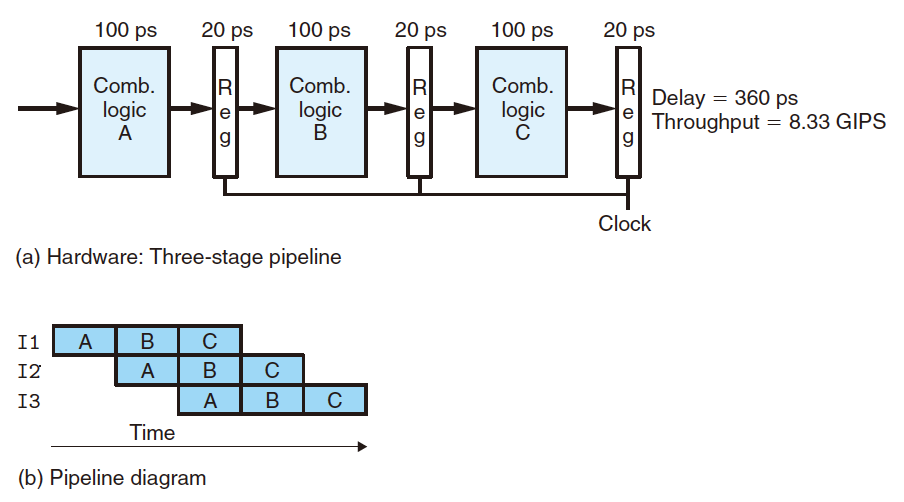
- Divide combinational logic into parts;
- Begin new instruction as soon as previous one completes one stage;
- Overall latency increases.
Limitation of the Pipelining:
- Nonuniform Partitioning:
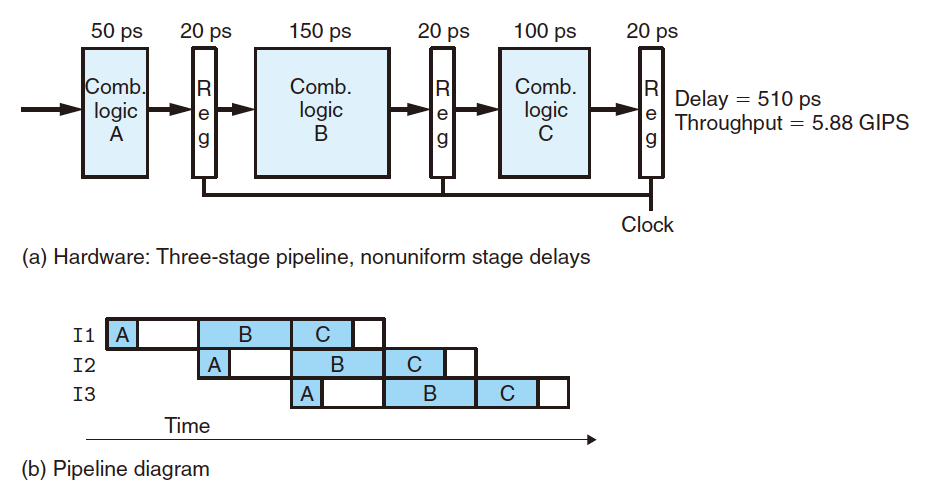
The clock operation rate is limited by the delay of the slowest (longest) stage;
May cause the waste of the CPU resource.
- Diminishing Returns of Deep Pipelining:
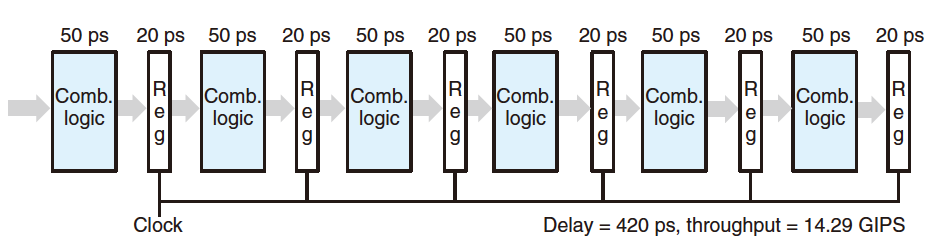
Cut the time required by each computation block by two, but we do not get a doubling of the throughput, bue to the delay of the pipeline registers.
4.4.1 Pipeline Stages
Shift the PC computation from the end of the clock to the beginning, to get the value of the current PC of the instruction.
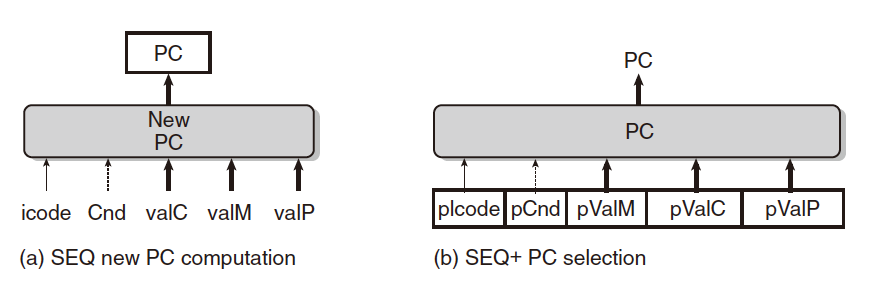
Pipeline Register:
4.4.2 PC Prediction
- Start fetching new instruction after current one has completed fetch stage
- Guess the next PC:
- Unconditional Jump:
valC(the destination); - Non-jump instruction:
valP(the next instruction); - Conditional Jump:
valC(predict the branch will always taken).
- Unconditional Jump:
4.4.3 Data Hazard in Pipeline
Data Dependencies: Some instruction depends on result from previous ones.
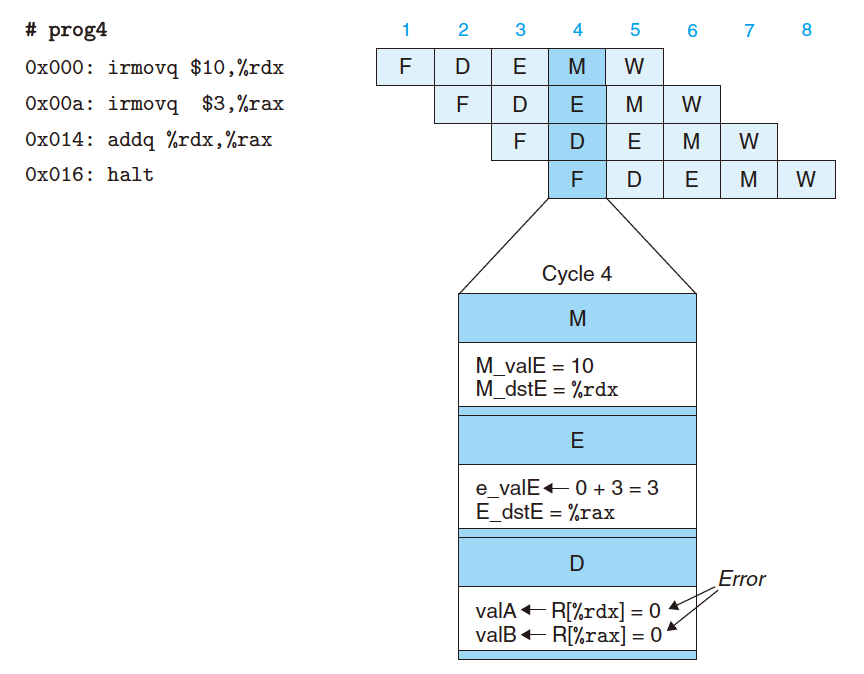
Values in
%rdxand%raxhave not been updated yet!
Solution: Stalling
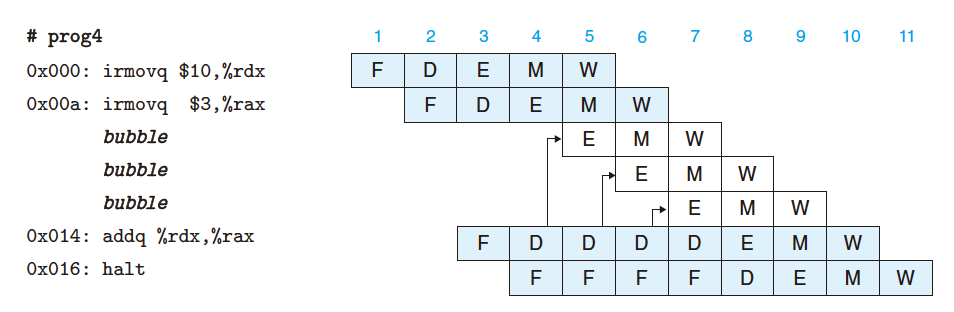
4.4.4 Branch Misprediction
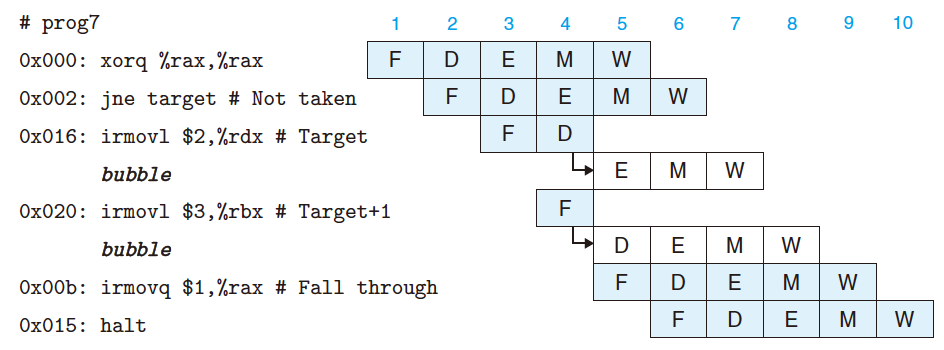
- Predict the branch is taken (Target);
- Fetch 2 instructions at target.
- Once reach the execute stage and find the branch is NOT taken:
- Cancel the misfetced instructions by inserting bubbles;
- No side effect but waste of some clock cycles.
5 Memory Hierarchy
5.1 Access Latency
- CPU one instruction execution time: 1 cycle (1GHz CPU, 1 cycle = 10-9s);
- Fetch one word from main memory: 10 ~ 100 cycles;
- Fetch a block of data from dicks: 10,000 ~ 1,000,000 cycles.
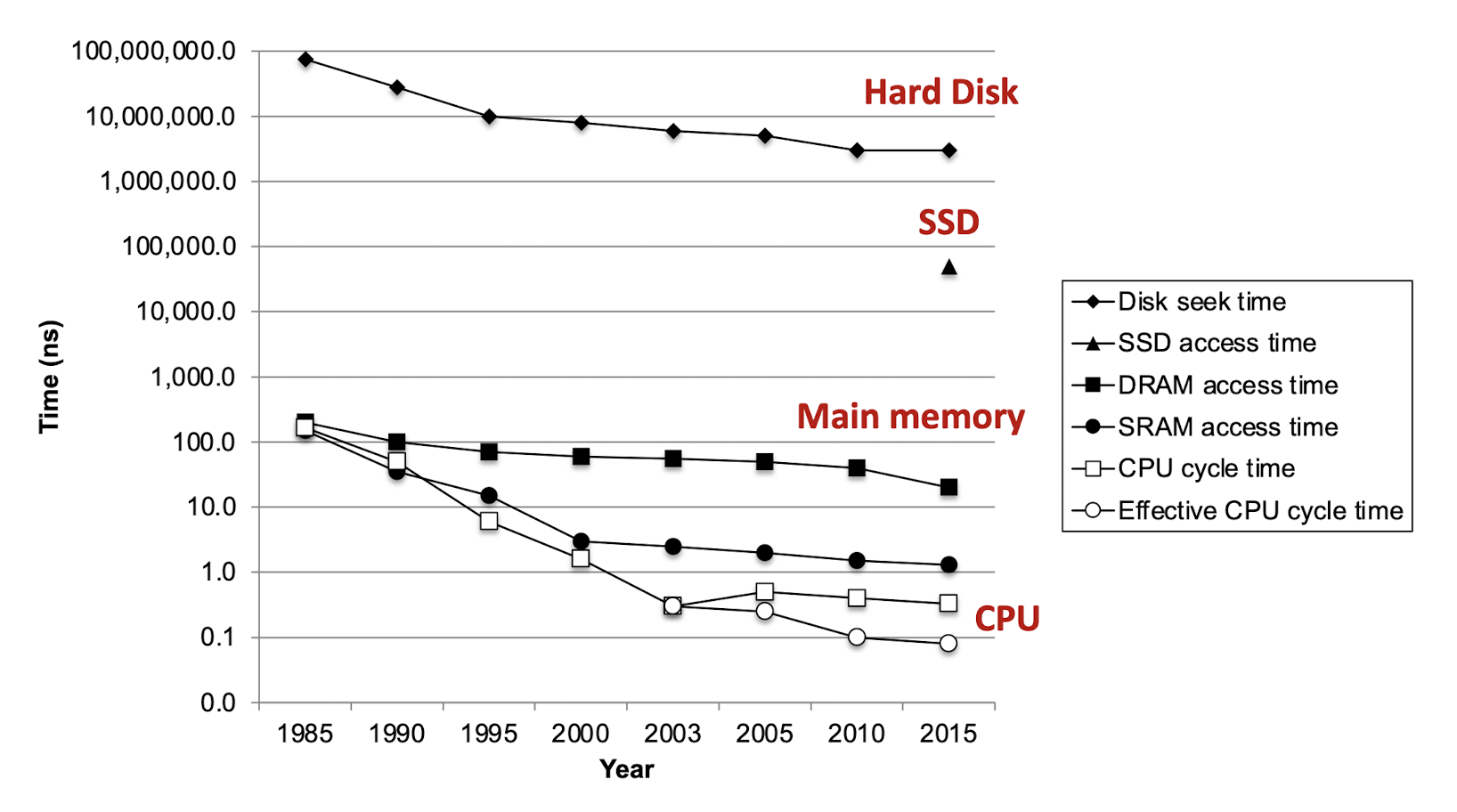
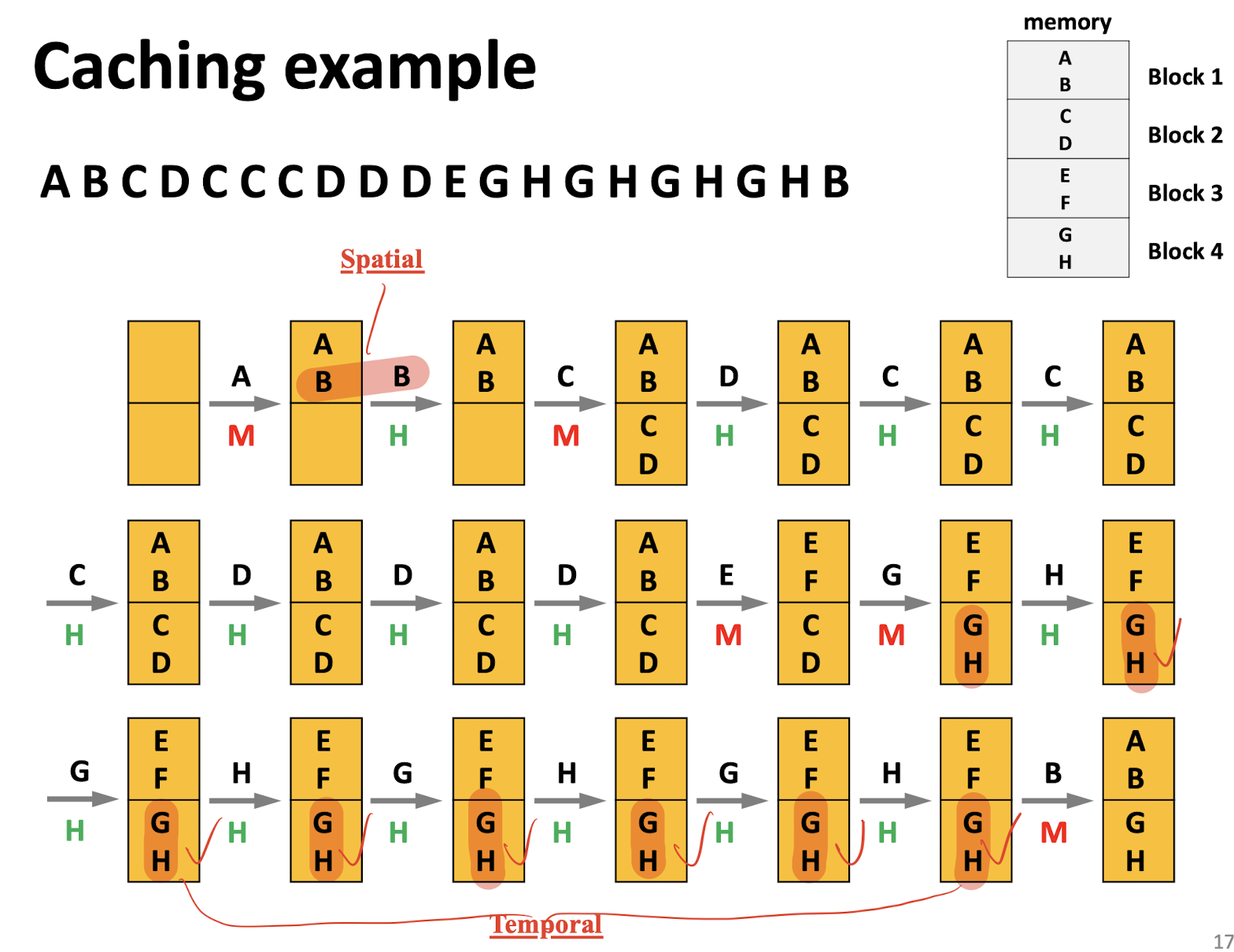
5.2 Locality
Principle of locality:
- Programs tend to use data and instructions with addresses near or equal to those they have used recently;
Temporal locality (Time respective):
- Recently referenced items (data, instructions) are likely to be referenced again in the near future;
Spatial locality (Space respective):
- items (data, instructions) with nearby addresses tend to be referenced close together in time


Locality measurement:
Stride(Space): The distance of two adjacent data accesses in memory location, in the unit of 1 data element;
Stride-1 reference pattern: access the data one by one according to their memory addresses, such as the good locality example;
Stride-k reference pattern: for example, the bad locality example generally has a stride-4 reference pattern.
The smaller the stride, the better the locality.
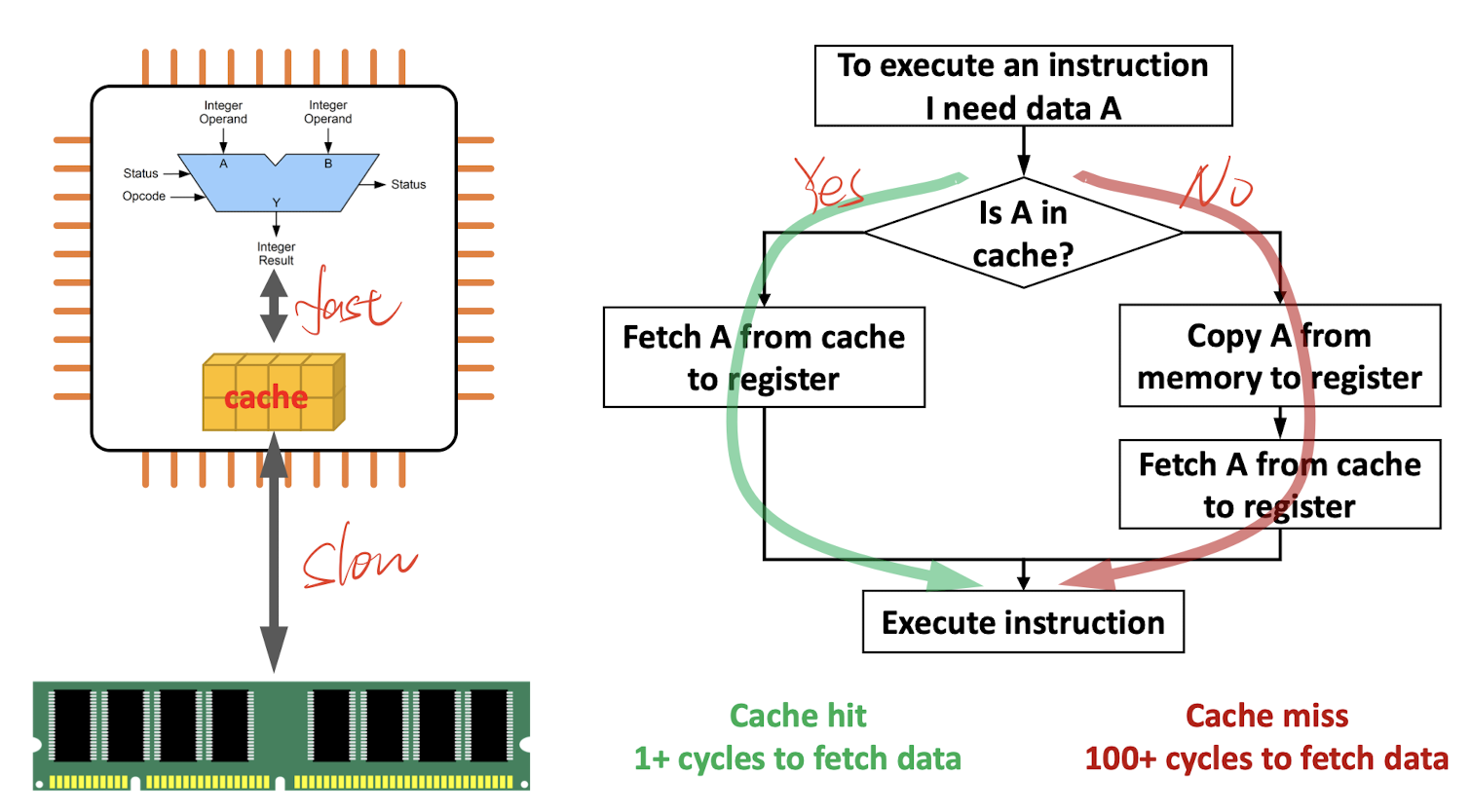
5.3 Caching
Adding a small but fast memory inside the CPU
Most programs runs iteration, and access same data frequently, so use cache to store the recently used data, saving time when access the same block of data, rather then still access from main memory. And cache is much closer to CPU than memory, have faster speed.
Hit: the needed data have already been fetched inside the cache before;
Miss: the needed data is NOT in the cache now, need to be accessed from the main memory;


Hints to software developers:
- Caching leverages locality, good locality make good use of cache;
- Focus your attention on inner loops;
- Spatial locality: reducing by reading data sequentially with stride-1 with same order stored in the memory;
- Temporal locality: reducing by using data as often as possible once it has been read from memory recently.
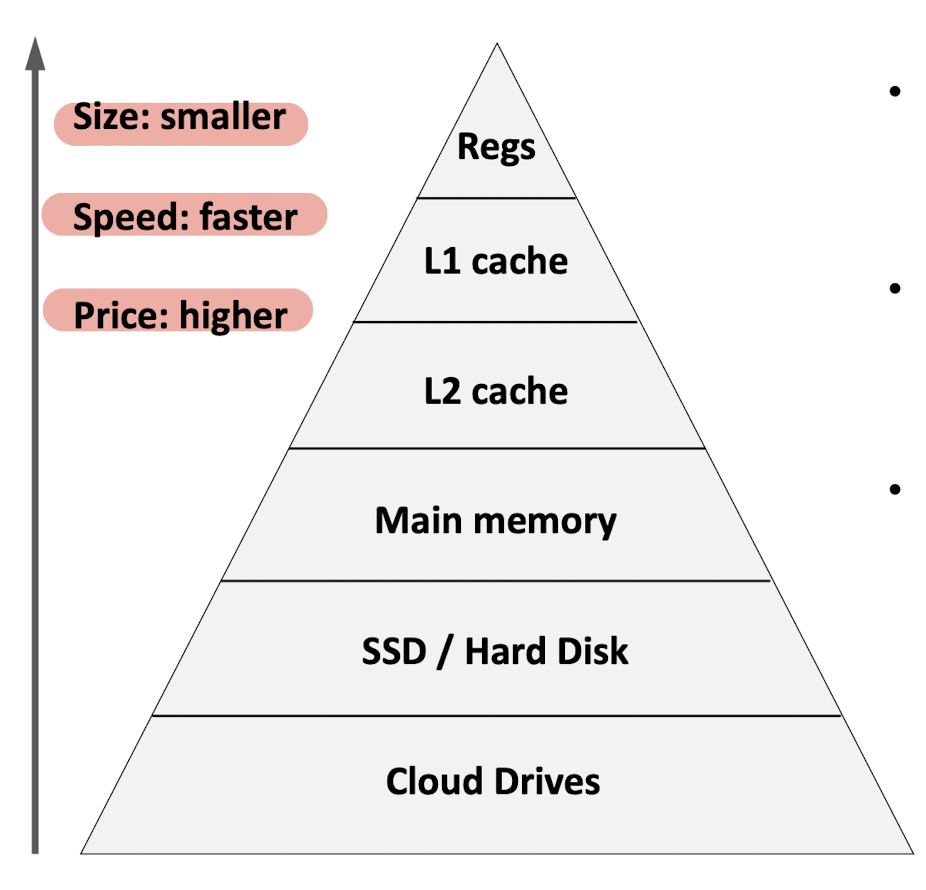
5.4 Memory Hierarchy & Caching
- Level
Kcan be the cache of the LevelK+1, storing the subset data of higher one. - Memory system working at a high speed at the highest level with less capacity, but have the storage space of the lowest level with low speed but large capacity.
5.5 Cache Management
- Cache block size:
- Bigger size has bigger spatial locality;
- But too big may cause many data unused and cause waste of space and time;
Replacement policy:
- The new coming data is going to replace which data in the cache;
- Intuition: keep the data with more usage frequency in the cache, replace the less used one.
- FIFO: if the cache is full, and a new cache block will be loaded into the cache, the cache block that are installed earliest in absolute time will be evicted;
- LRU: if the cache is full, and a new cache block will be loaded into the cache, the least recently accesses block will be evicted。
Set-associative design of cache:
- When the cache is large, take too long time to find;
- Partition the cache into groups, map different data into different groups.
6 Concurrency
Concept of concurrency:
There are more than one programs, before one running program finishes, another program has stared execution;
The operating system offers the capability to shift between programs.
Processes:
An instance of a running program;
can create multiple processes of a “program”.
Process abstractions:
- Logical control flow:
Exclusive use of the CPU, e.g. Registers;
Provided by kernel mechanism called context switching.- Private address space:
Exclusive use of main memory;
Provided by kernel mechanism called virtual memory.
Workflow of switching:
- Start P1;
- Save the context of P1 (Register) to P1’s memory region;
- Load the context of P2;
- Start execute P2;
…
Context Switching:
- kernel:
A shared chunk of memory-resident OS code manages Processes.
Control flow passes from one process to another via a context switch:
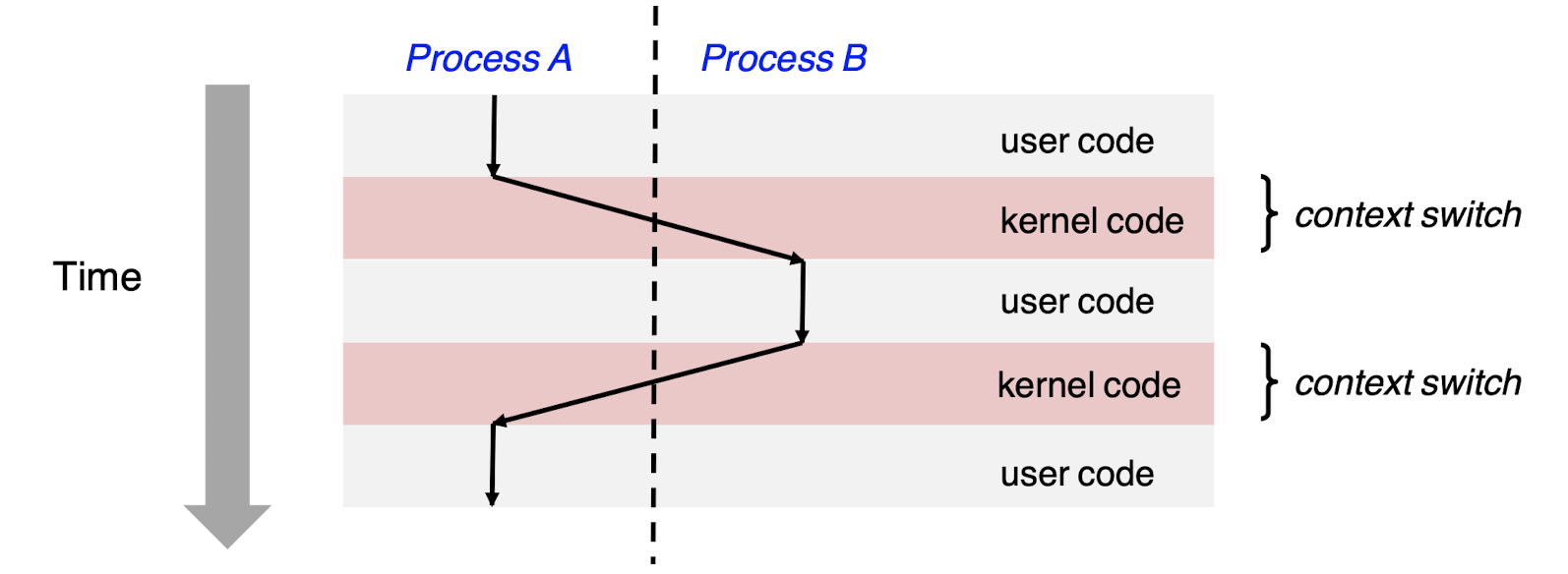
6.1 Write Concurrent Program
Process in three states:
- Running: Process is either executing, or waiting to be executed;
- Stopped: Process execution is suspended and will not be scheduled until further notice;
- Terminated: Process is stopped permanently.
Creating Processes:
fork():
- Parent process creates a new running child process;
- Returns 0 choose to run the child process, child’s PID to parent process;
- After return, the process will run the code after the
fork()line; - Child get an identical (but separate) copy of the parent’s child;
- Child has a different PID than the parent.
- After return, the process will run the code after the
- Called once but returns twice.
Terminating Processes:
Process becomes terminated for one of three reasons:
- Receiving a signal whose default action is to terminate
- Returning from the
mainroutine - Calling the
exitfunction
exit(int status):
- Terminates with an exit status of status;
- Convention: normal return status is 0, nonzero on error;
- called once but never returns.
1 | |
Output:
1 | |
- Can’t predict execution order of parent and child.
Synchronizing parent with child:
int wait(int *child_status):
- Suspend current process until one of its children terminates;
- Return value is the
pidof the child process that terminates; child_status: Ifchild_status != NULL, the integer it points to will be set to a value that indicates the reason why the child terminates;
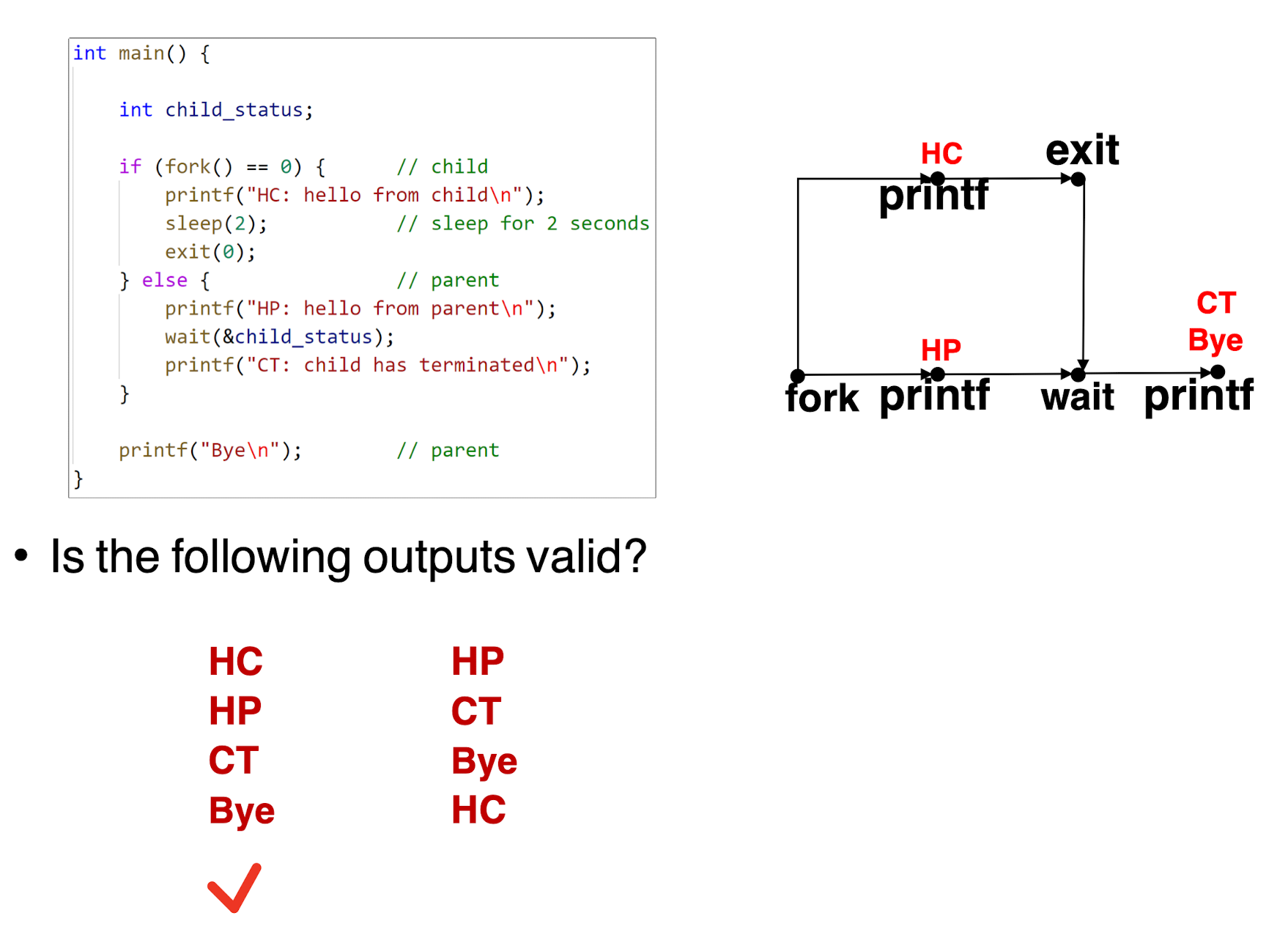
7 Virtual Memory
7.1 Address Spaces
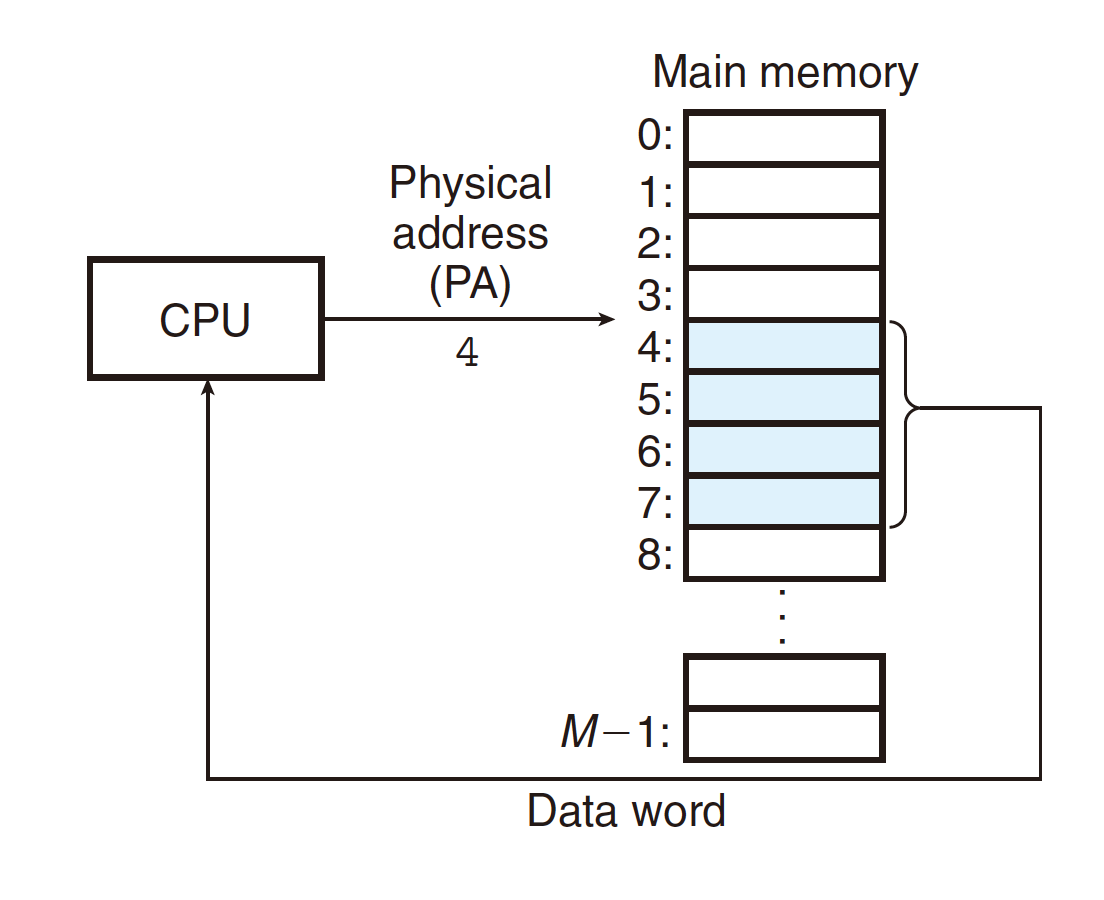
Linear address space: consecutive non-negative integer addresses:
Virtual address space: use $n$-bit integers as virtual addresses, total $N = 2^n$ virtual addresses:
Physical address space: use $m$-bit integers as physical addresses, total $M = 2^m$ physical addresses:
In general, $N$ is larger than $M$
7.2 Tool for Caching
Virtual Memory is an array of $N$ consecutive bytes stored on disk.
SRAM cache: the L1, L2, and L3 cache memories between the CPU and main memory;DRAM cache: the VM system’s cache that caches virtual pages in physical memory.pages: cache block;
Three stages of a Virtual page:
- Unallocated: Pages that have not yet been allocated (or created) by the VM system. Unallocated blocks do not have any data associated with them, and thus do not occupy any space on disk;
- Cached: Allocated pages that are currently cached in physical memory;
- Uncached: Allocated pages that are not cached in physical memory.
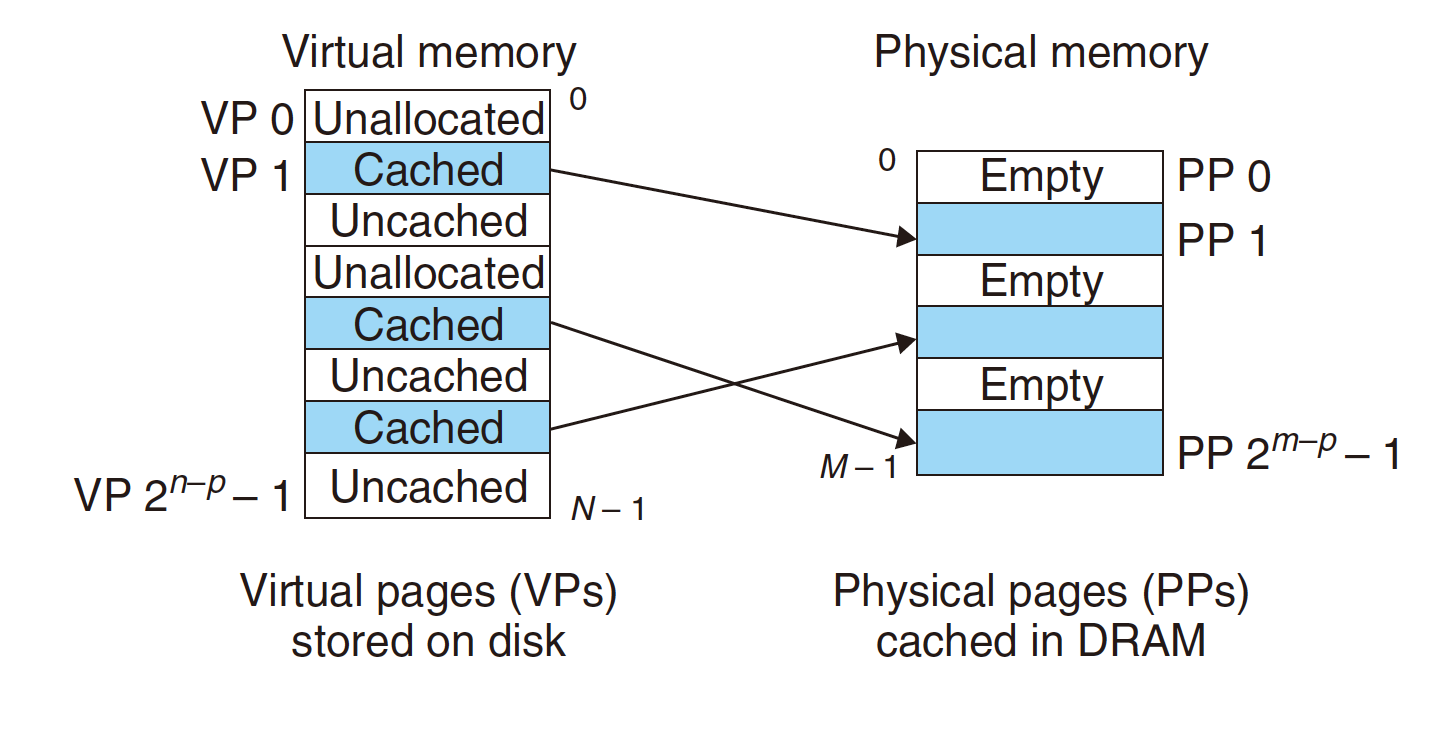
DRAM Cache Organization
Large page (block) size: typically 4 KB to 4 MB.
- To get more hit.
Fully associative:
- Any virtual page (VP) can be placed in any physical page (PP);
- Size of VP = size of PP.
Sophisticated replacement algorithms for DRAM cache.
Write-back
- Writes are not immediately performed in the disk;
- Write to the disk when a page is evicted from DRAM cache.
Page Table
An Enabling Data Structure.
An array of page table entries (PTEs) that maps virtual pages to physical pages.
- Store in the main memory, each process has a page table stored in the mei memory.
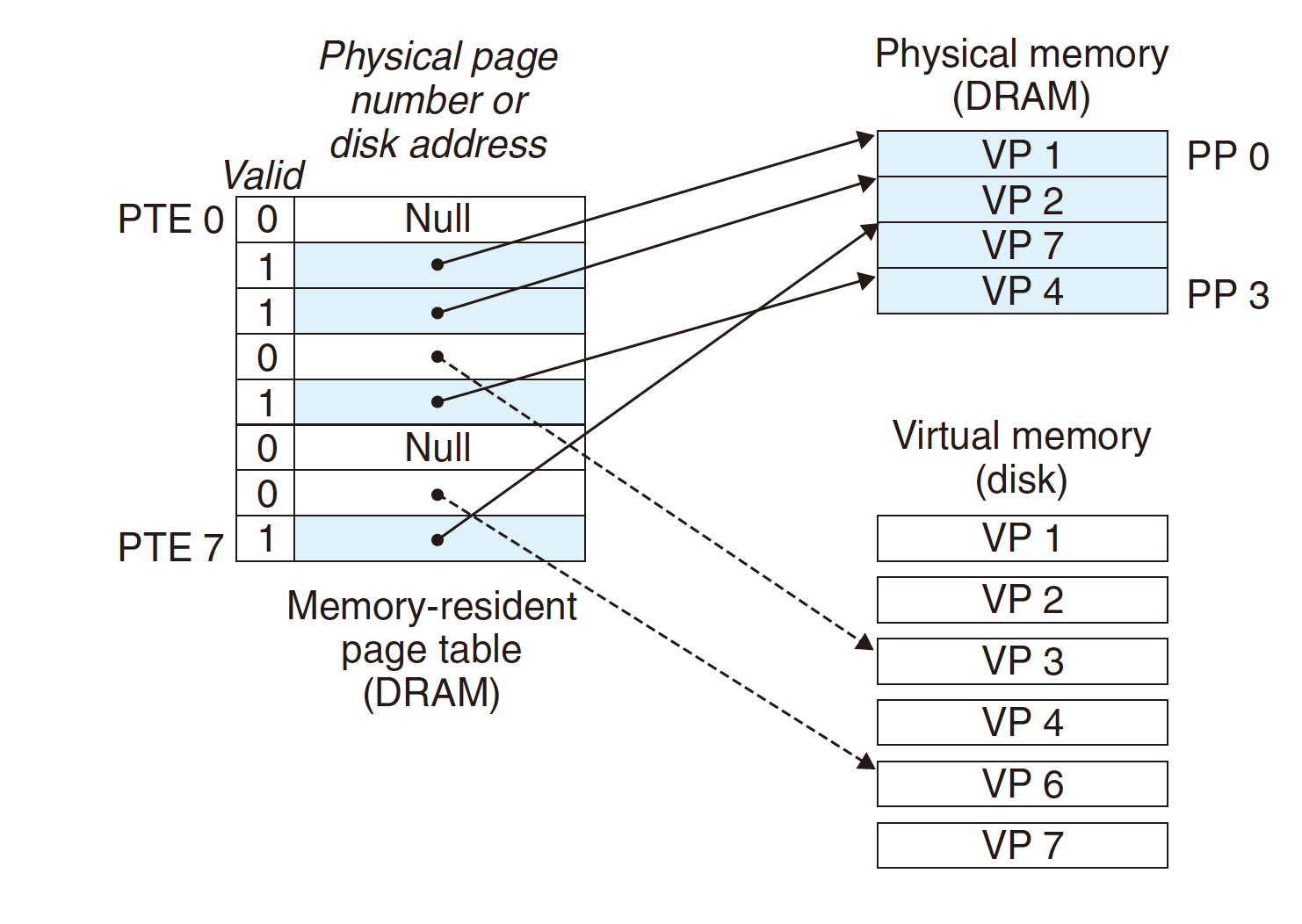
valid bit: indicates whether the virtual page is currently cached in DRAM.
address field:
- if valid bit is 1, is the start of the corresponding physical page in DRAM where the virtual page is cached;
- if valid bit is 0:
nulladdress indicates that the virtual page has not yet been allocated;- or the address points to the start of the virtual page on disk.
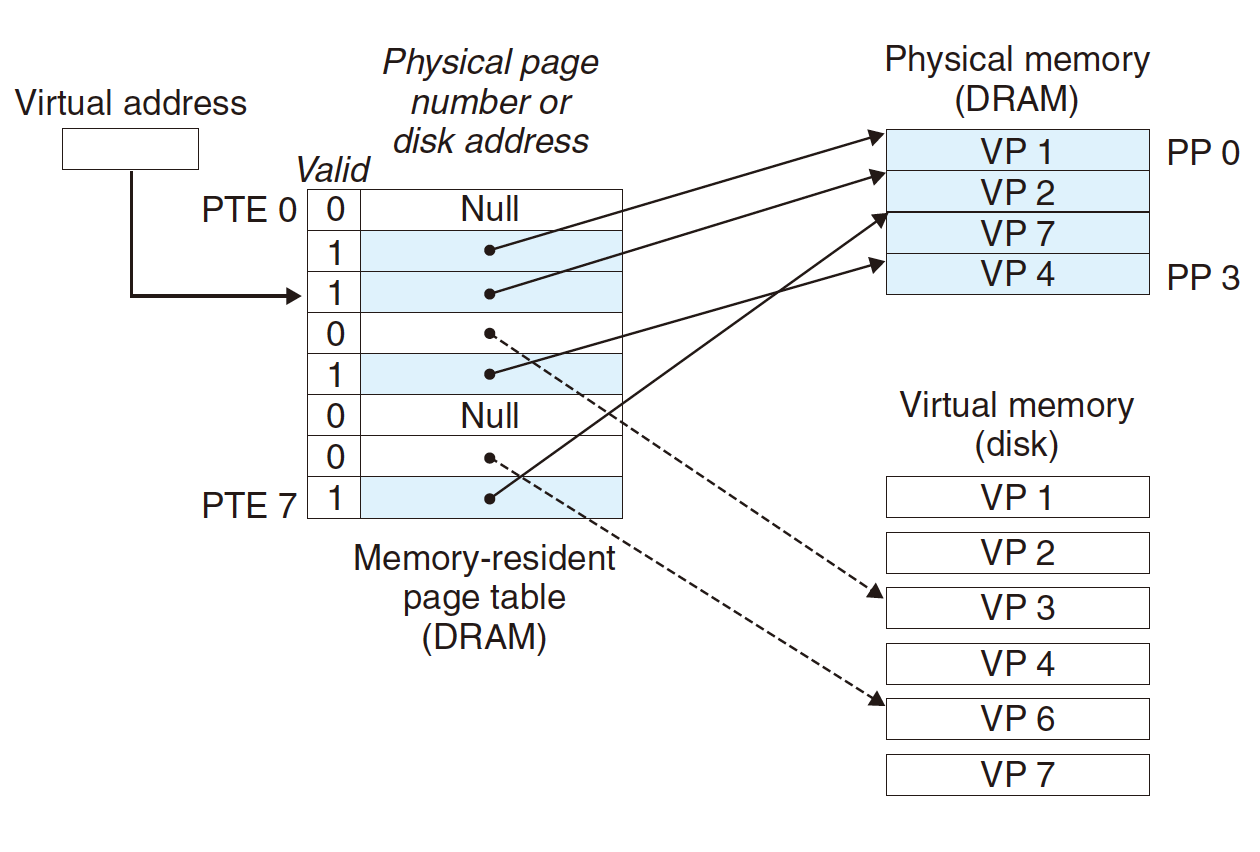
Page Hit
reference to VM word that is in physical memory
Third data is hit, just read from the PM.
Page Fault
reference to VM word that is not in physical memory
Fourth data is missed (fault):
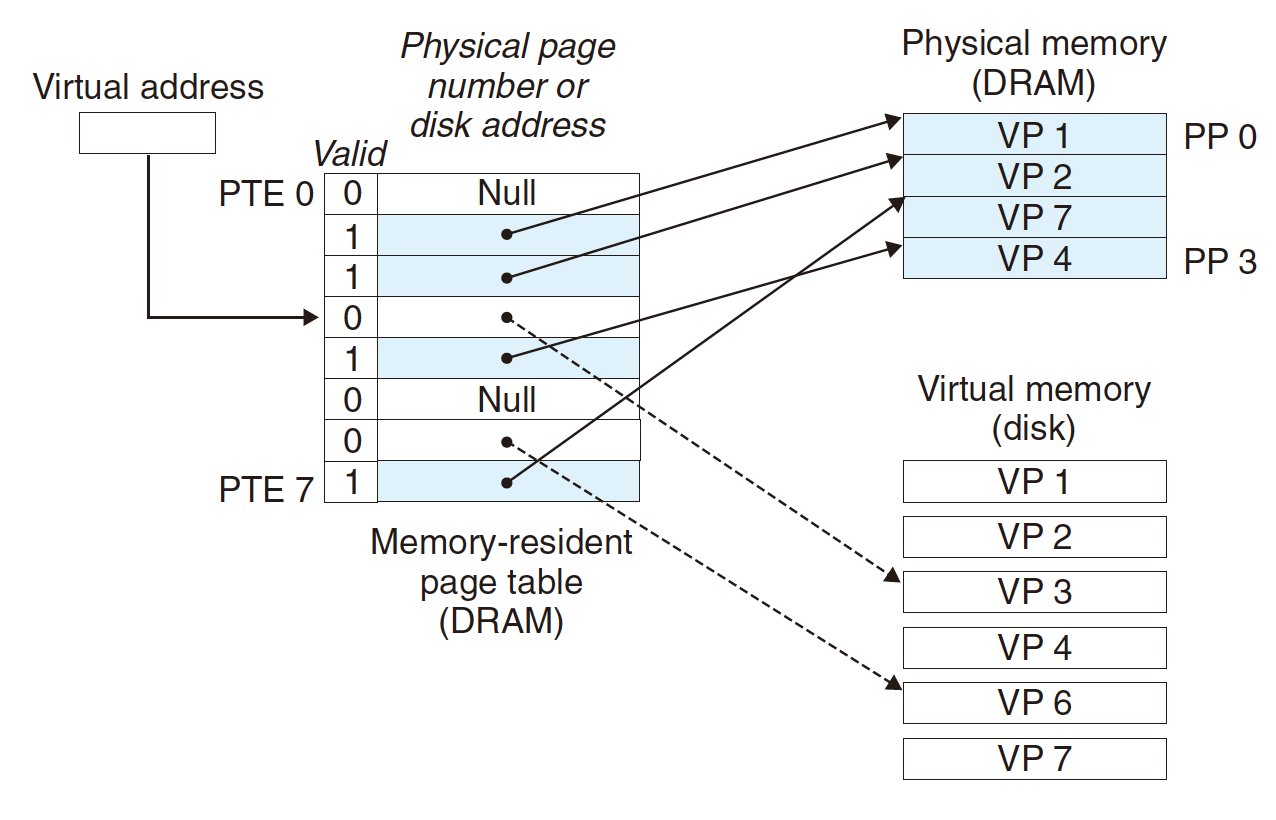
- Page miss causes page fault (an exception);
- Page fault handler selects a victim to be evicted (here
VP4); - Read VP3 from Virtual Memory to PM and cache it in DRAM;
- Restart, hit!
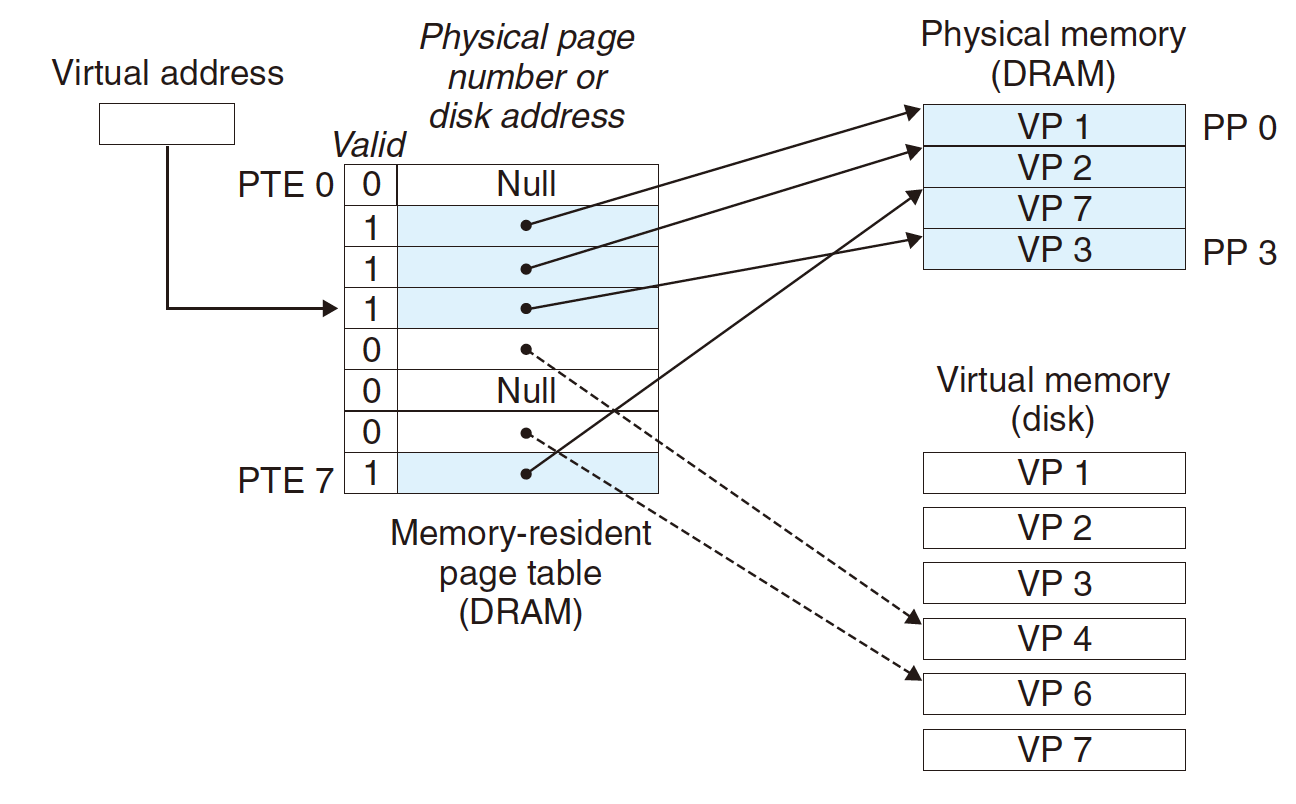
Allocating Pages
Allocating a new page (VP 5) of virtual memory.
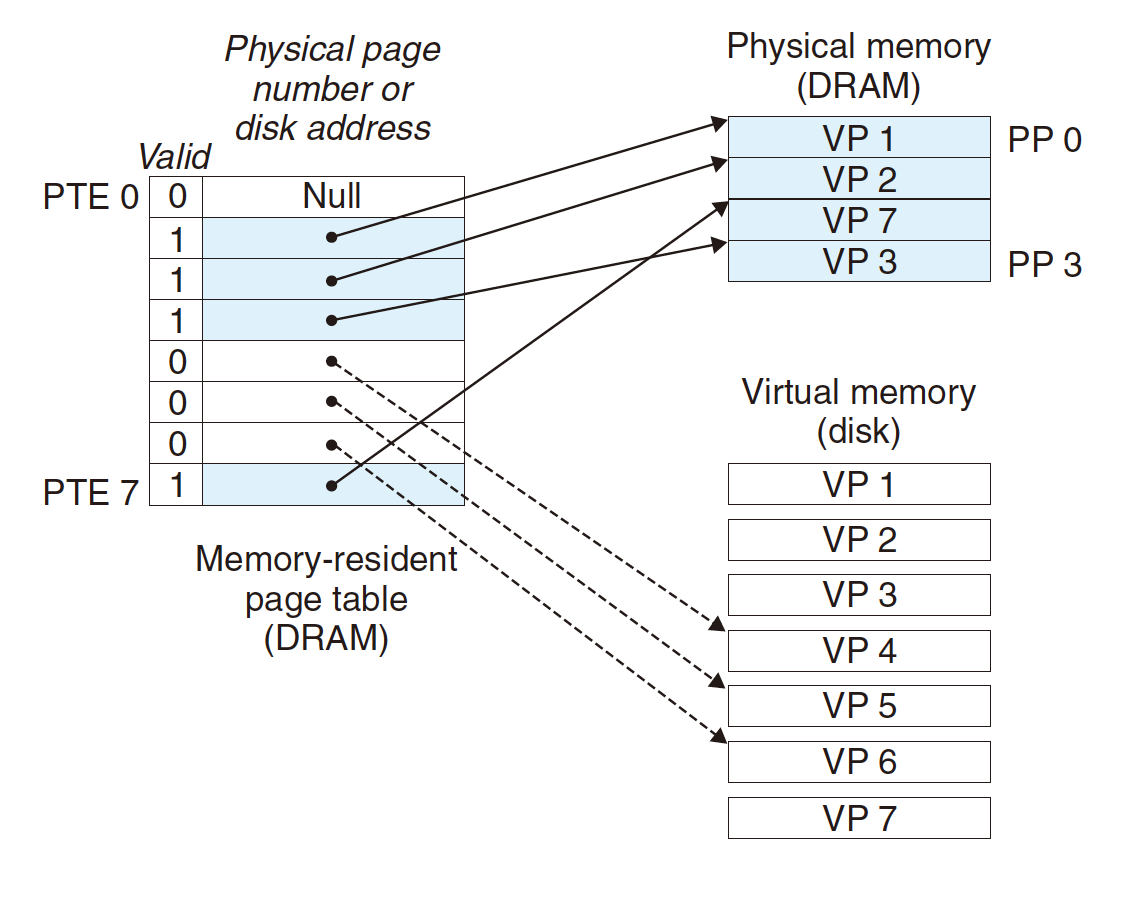
Locality
- Virtual memory works efficiently because of locality;
- working set: At any point in time, programs tend to access a set of active virtual pages;
- If (working set size < main memory size):
- Good performance for one process after compulsory misses;
- If ( SUM(working set sizes) > main memory size):
- Thrashing: Performance meltdown where pages are swapped (copied) in and out continuously.
7.3 Too for Memory Management
Each process has its own virtual address space.
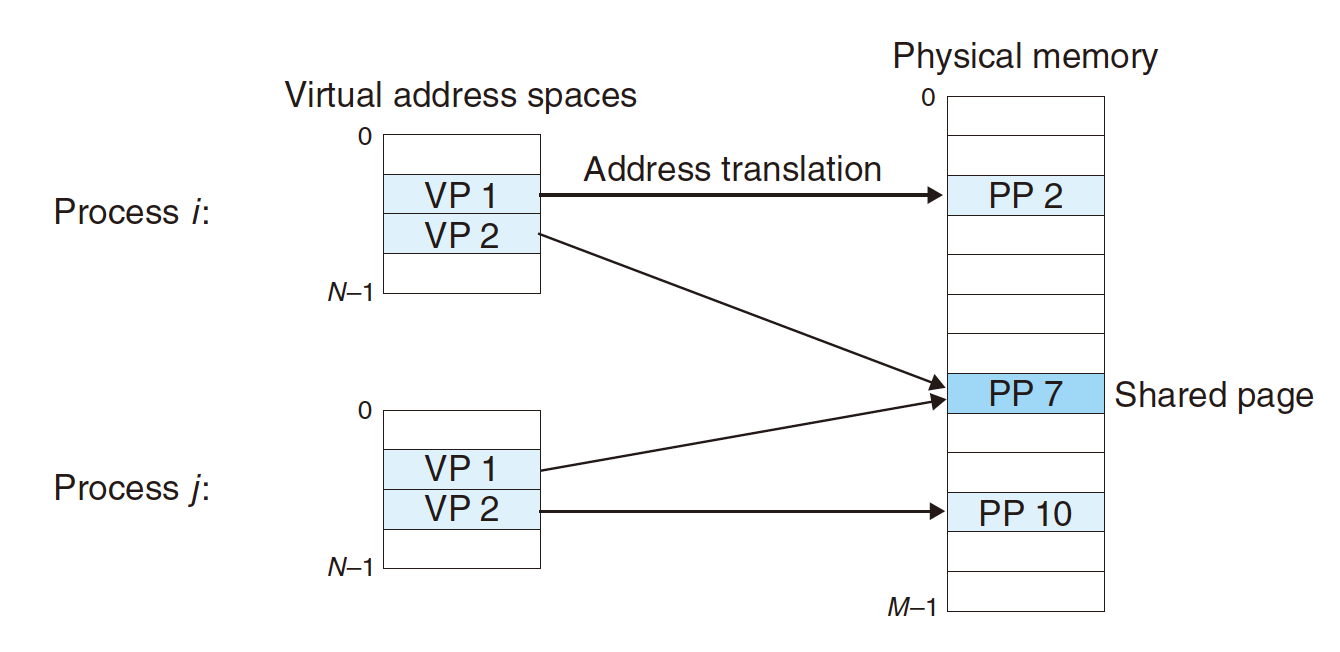
Simplifying memory allocation:
- Each virtual page can be mapped to any physical page;
- A virtual page can be stored in different physical pages at different times.
Sharing code and data among processes:
- Map virtual pages to the same physical page (
PP 7).
7.4 Tool for Memory Protection
Extend page table entries (PTEs) with permission bits.
- Memory management unit (MMU) checks these bits on each access
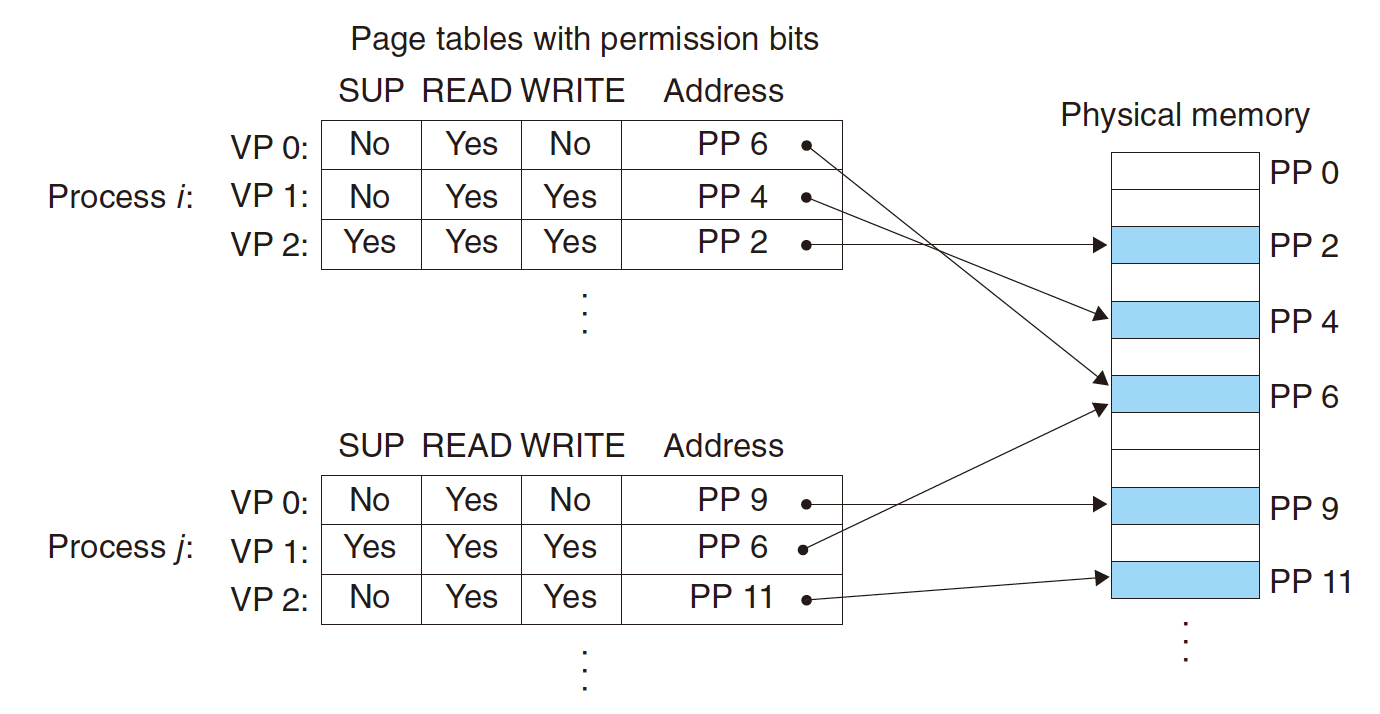
SUP: Super user or Supervisor;
- whether processes must be running in kernel (supervisor) mode to access the page.
- 1: Processes running in kernel mode can access any page,
- 0: Processes running in user mode are only allowed to access pages.
READ: Read;WRITE: Write;EXEC: Execute.
7.5 VM Address Translation
$MAP(a)=a^\prime$: Hit, data at virtual address $a$ is at physical address $a\prime
$ in P
$MAP(a)=\empty$: Fault, data at virtual address $a$ is not in physical memory

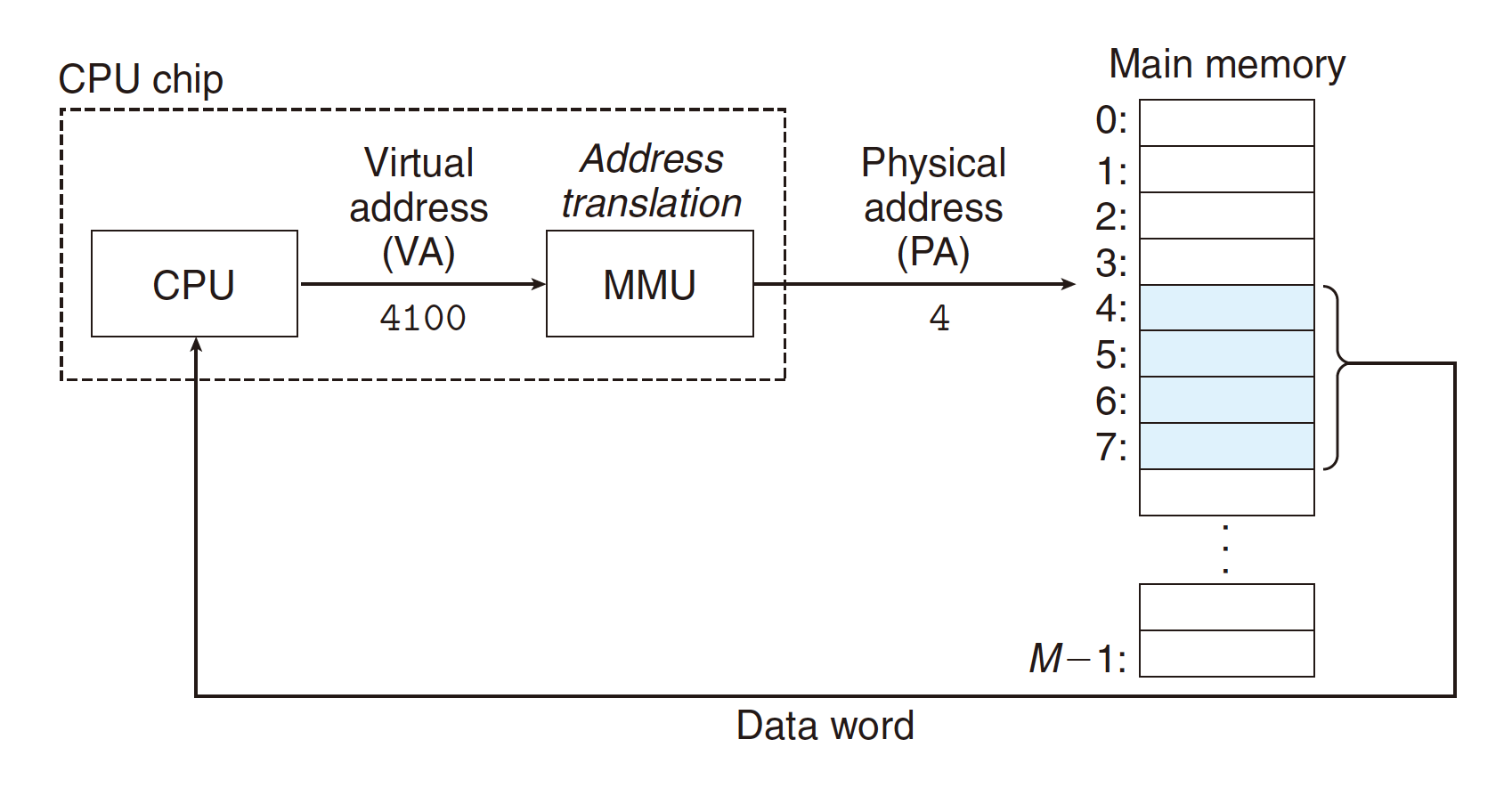
Address Translation With a Page Table
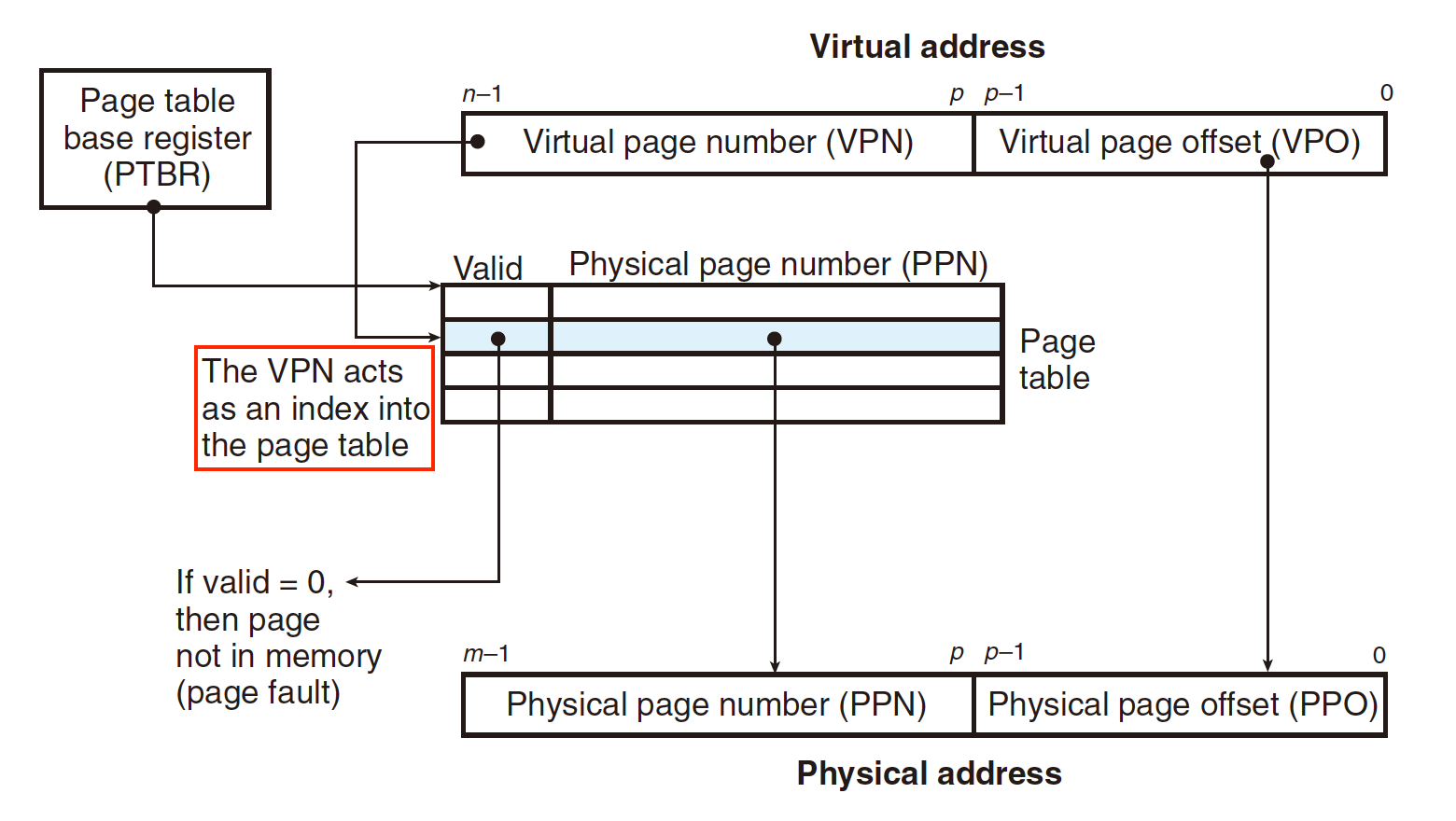
The VPN is like a index to the Page Table
Hit:
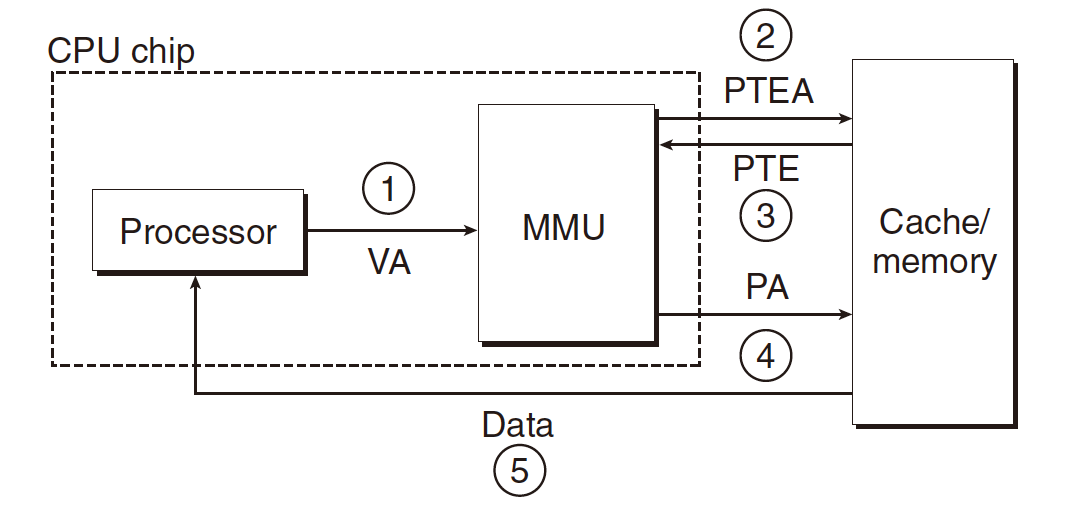
1.Processor sends virtual address to MMU
2-3. MMU fetches PTE from page table in memory
4.MMU sends physical address to cache/memory
5.Cache/memory sends data word to processor
Fault:
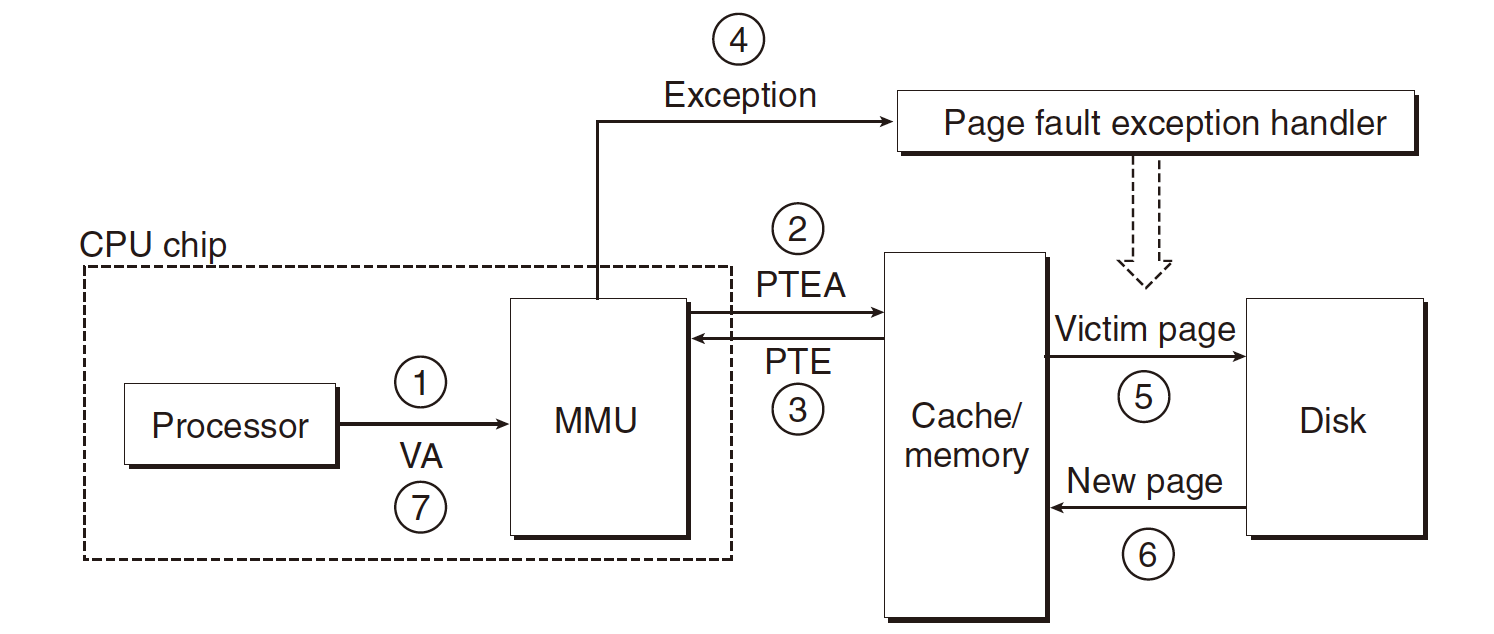
1.Processor sends virtual address to MMU
2-3. MMU fetches PTE from page table in memory
4.Valid bit is zero, so MMU triggers page fault exception
5.Handler identifies victim (and, if dirty, pages it out to disk)
6.Handler pages in new page and updates PTE in memory
7.Handler returns to original process, restarting faulting instruction
7.6 Integrating VM and Cache
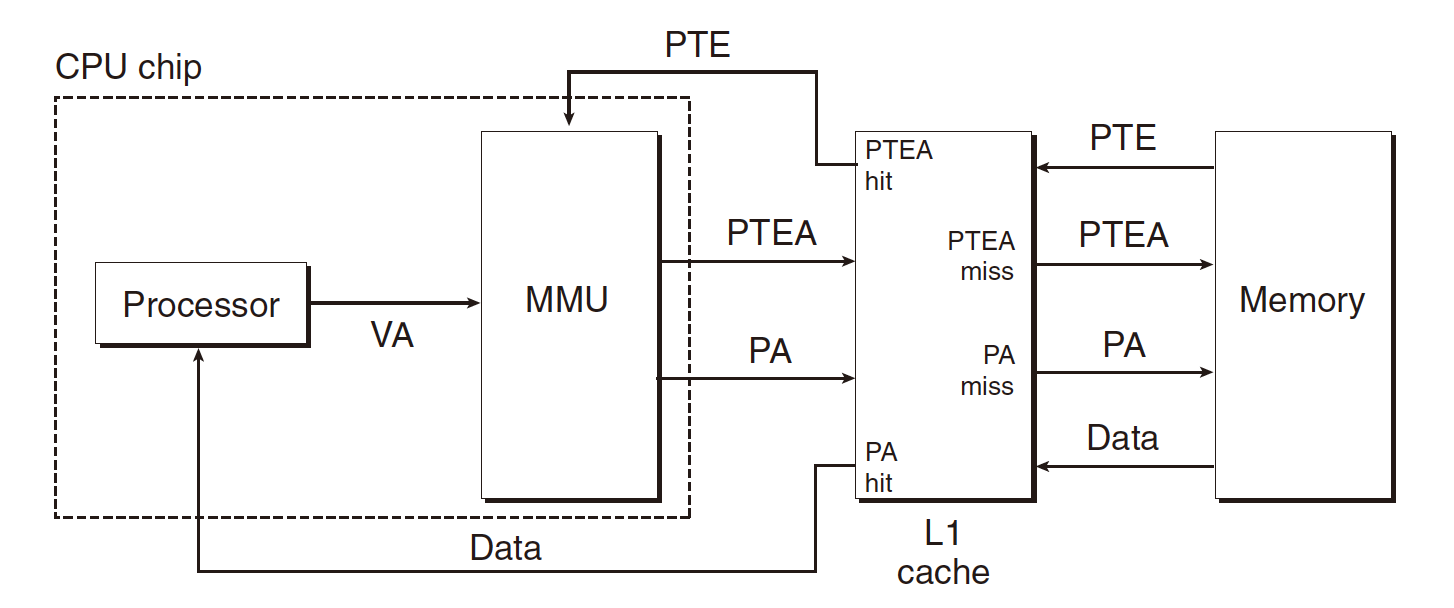
PTE data is same as other data cached in L1 cache, can be hit and miss.
7.7 Speeding up Translation with a TLB
Dut to the PT data will be easily evicted, and has a small delay, we can use a TLB to speed up.
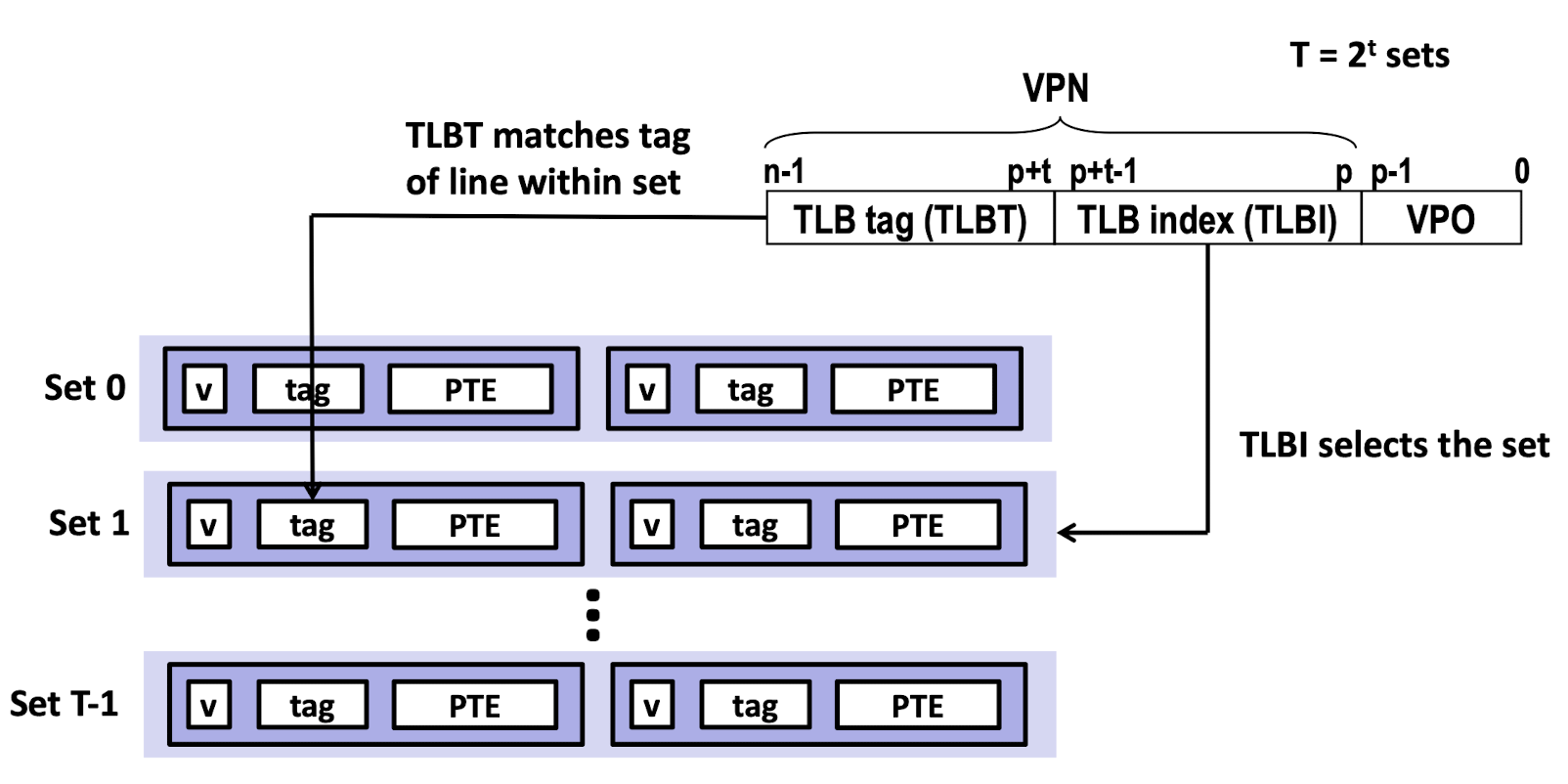
Translation Lookaside Buffer (TLB):
- Small set-associative hardware cache in MMU;
- Maps virtual page numbers to physical page numbers
- Contains complete page table entries for small number of pages
Accessing the TLB
TLB Hit
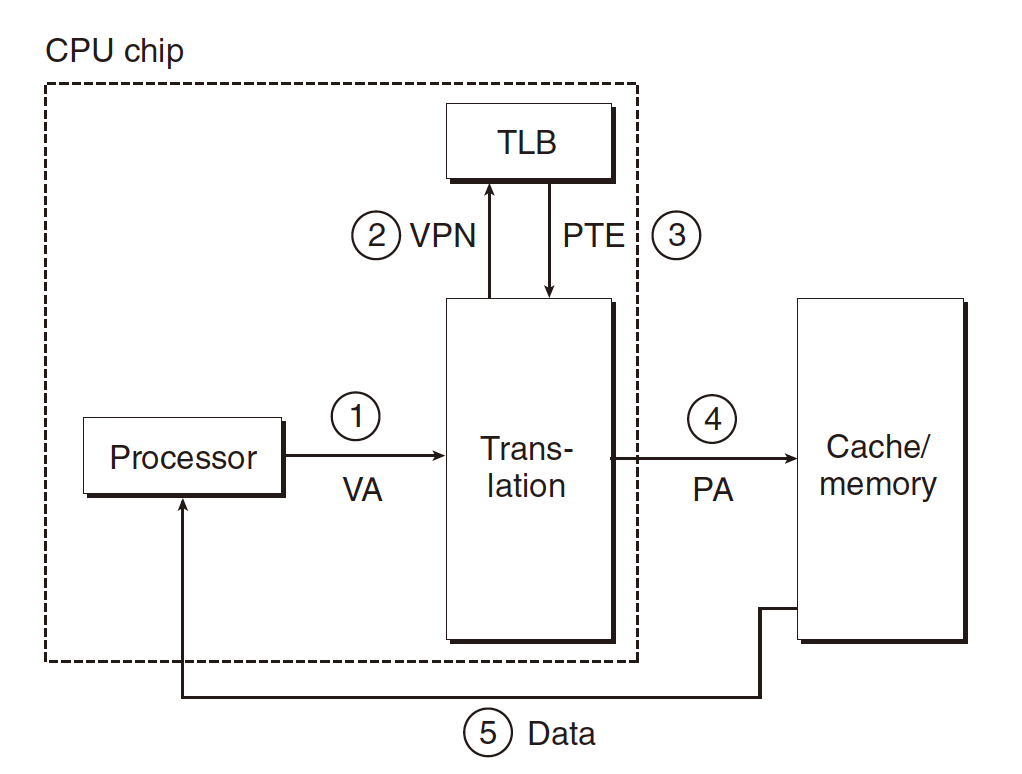
1.The CPU generates a virtual address.
2-3.The MMU fetches the appropriate PTE from the TLB;
4.The MMU translates the virtual address to a physical address and sends it to the cache/main memory;
5.The cache/main memory returns the requested data word to the CPU.
TLB Miss
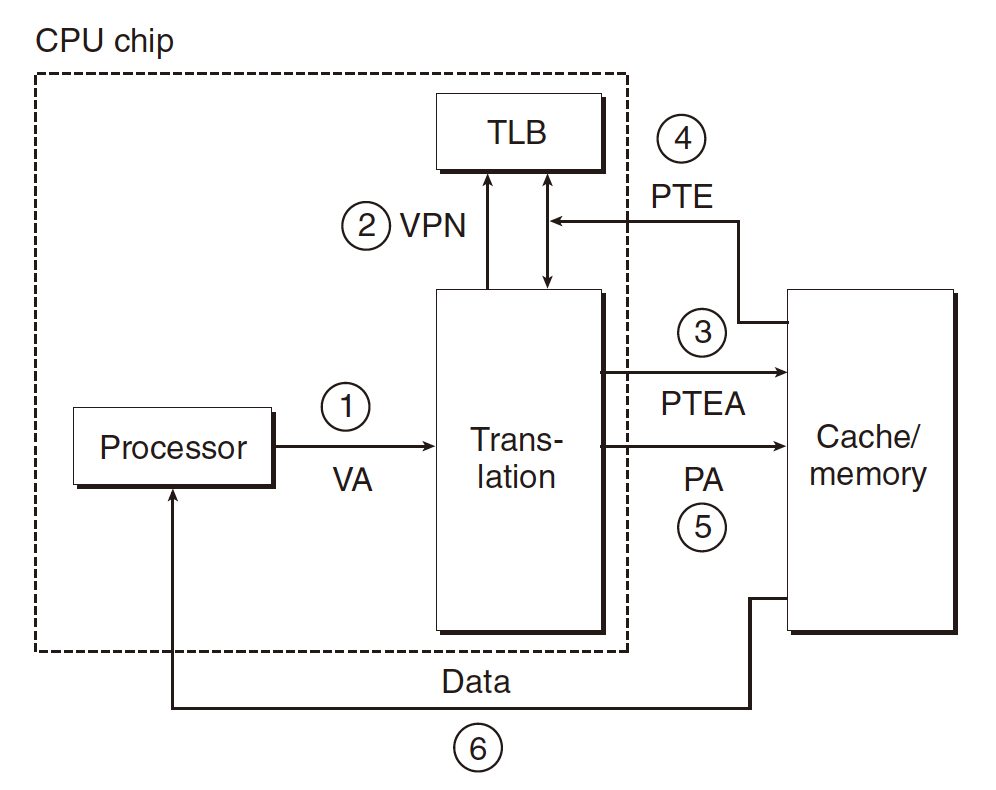
First the MMU must fetch the PTE from the L1 cache,
then the newly fetched PTE is stored in the TLB.
8 System-Level I/O
8.1 I/O Bus
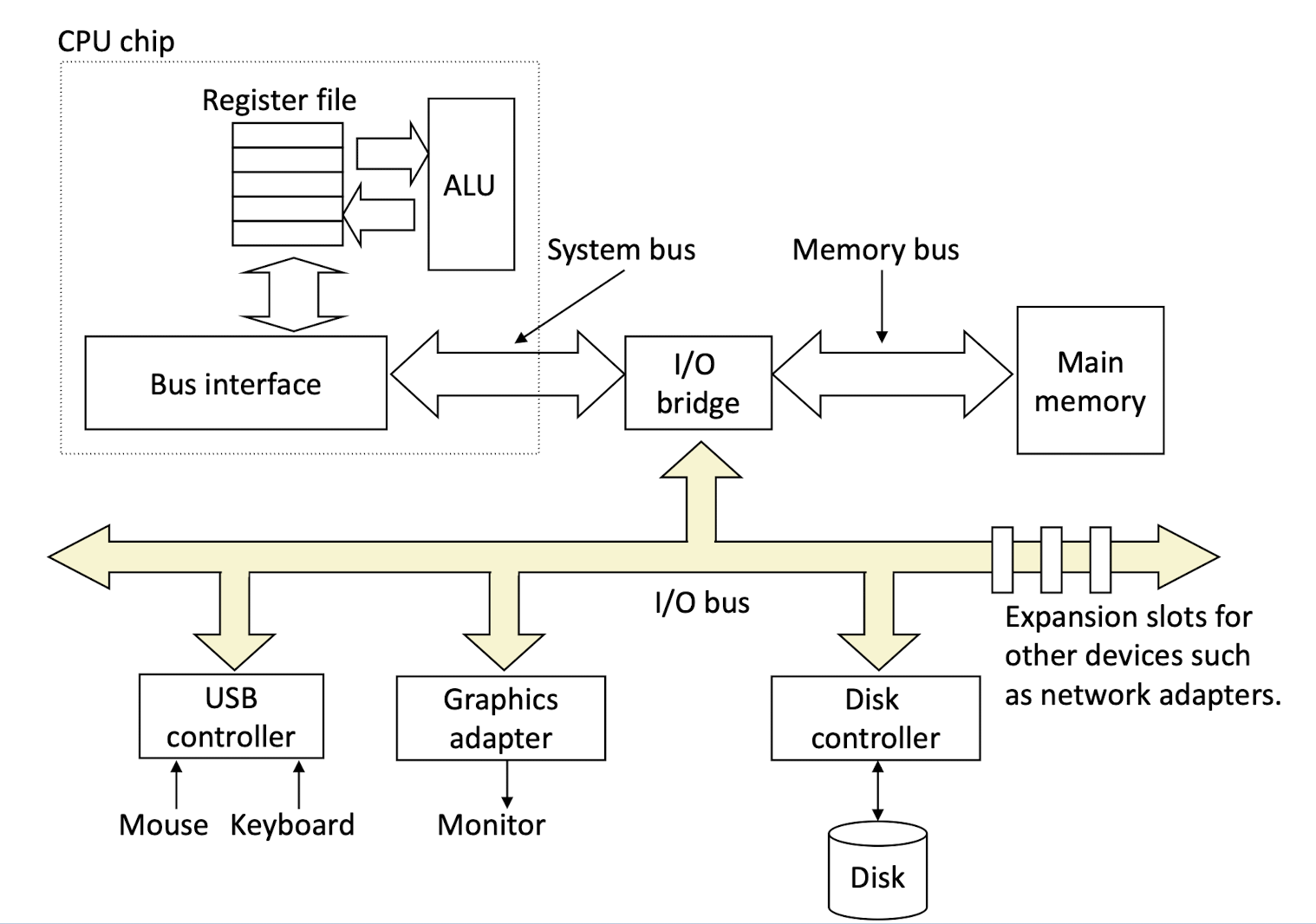
The purpose of the I/O bridge are
- Manage and coordinate different types of I/O devices and the main memory;
- To separate the signals within the CPU, ensure they will not interrupt each other.
8.2 How I/O devices interact with CPU
CPU is too fast, I/O devices are too slow.
Design principle: should not let CPU wait for I/O devices
- Interrupt-based:
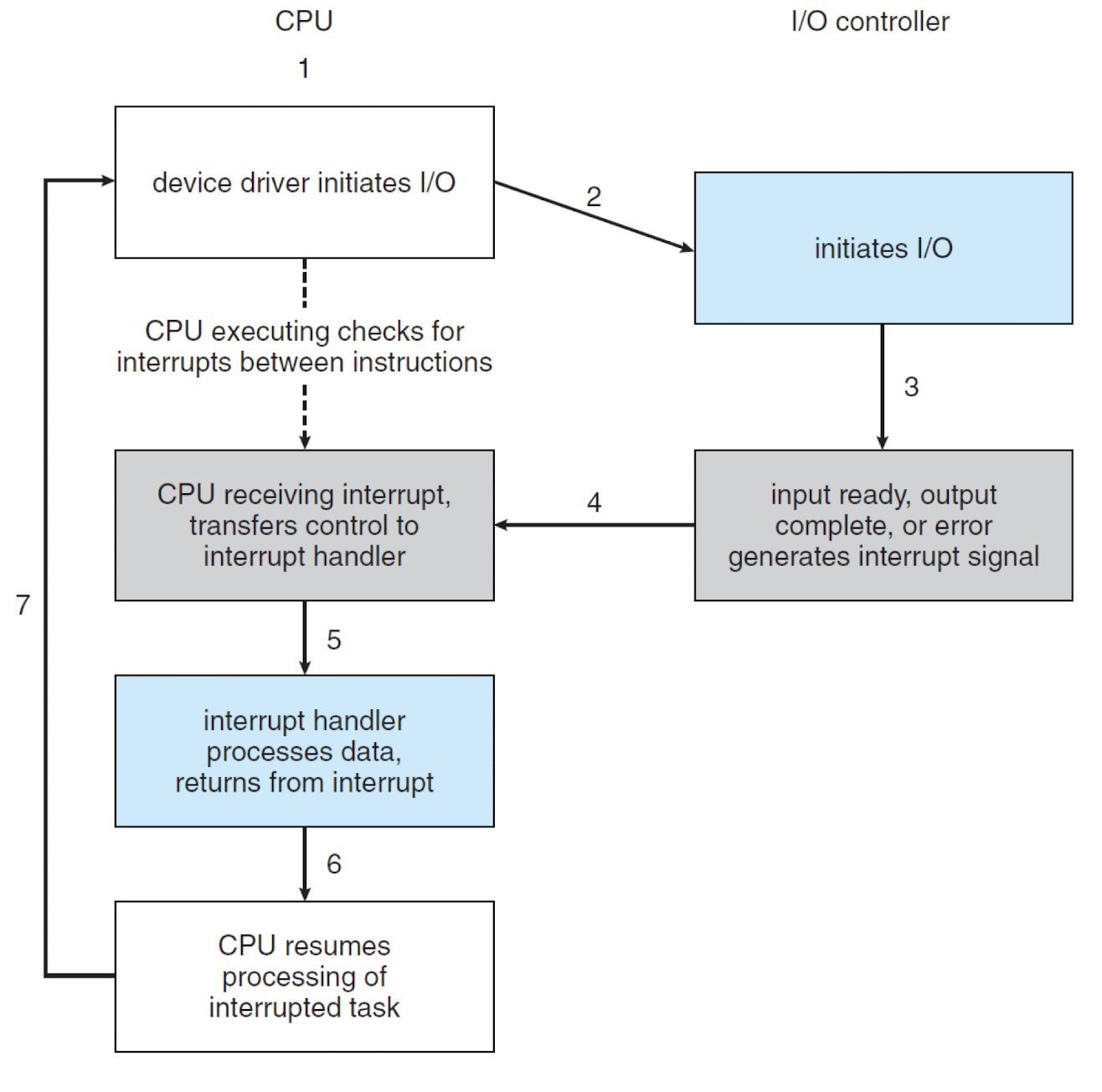
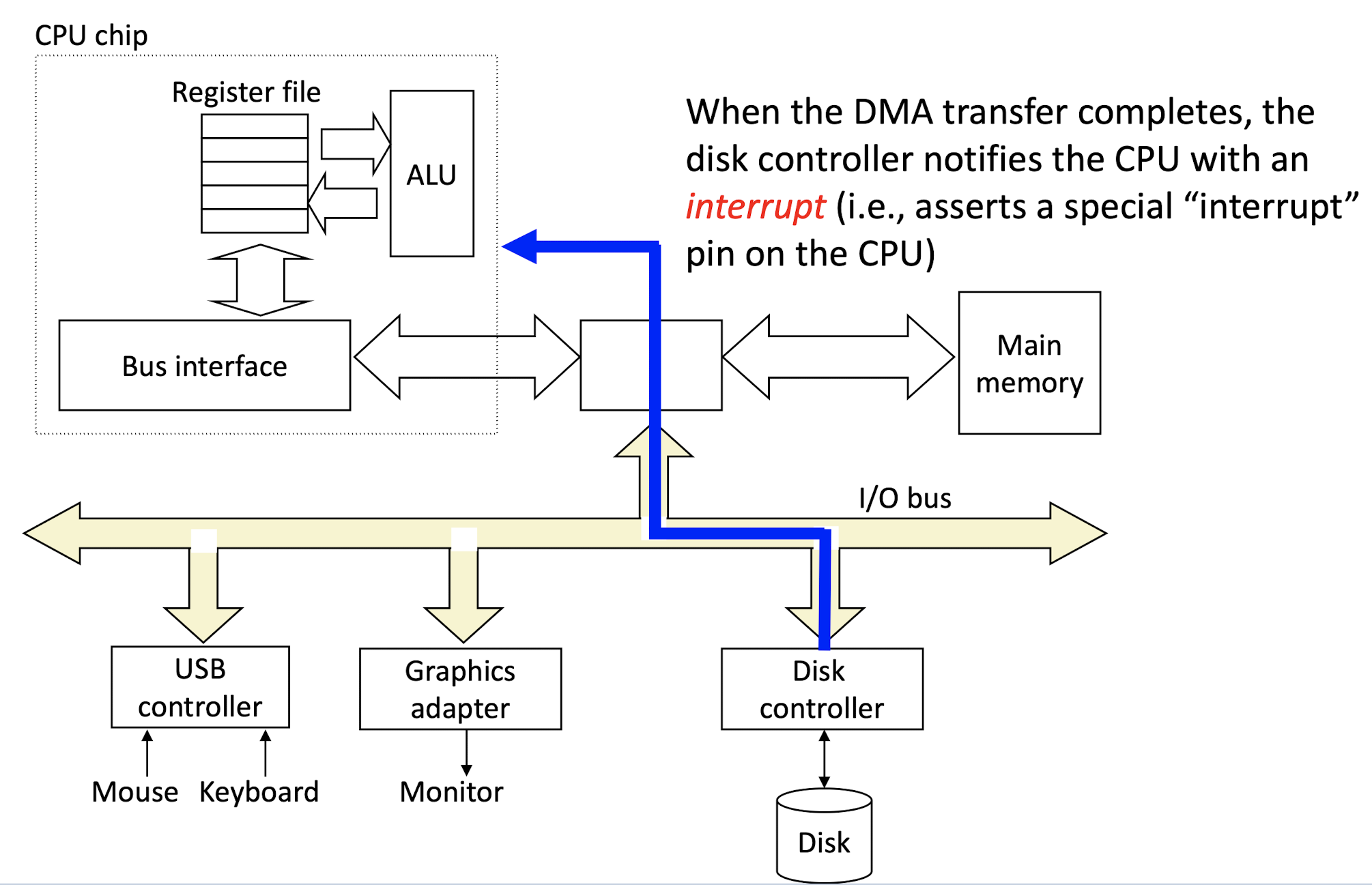
- DMA – Direct Memory Access, dedicated hardware helping CPU to move data between I/O devices and main memory
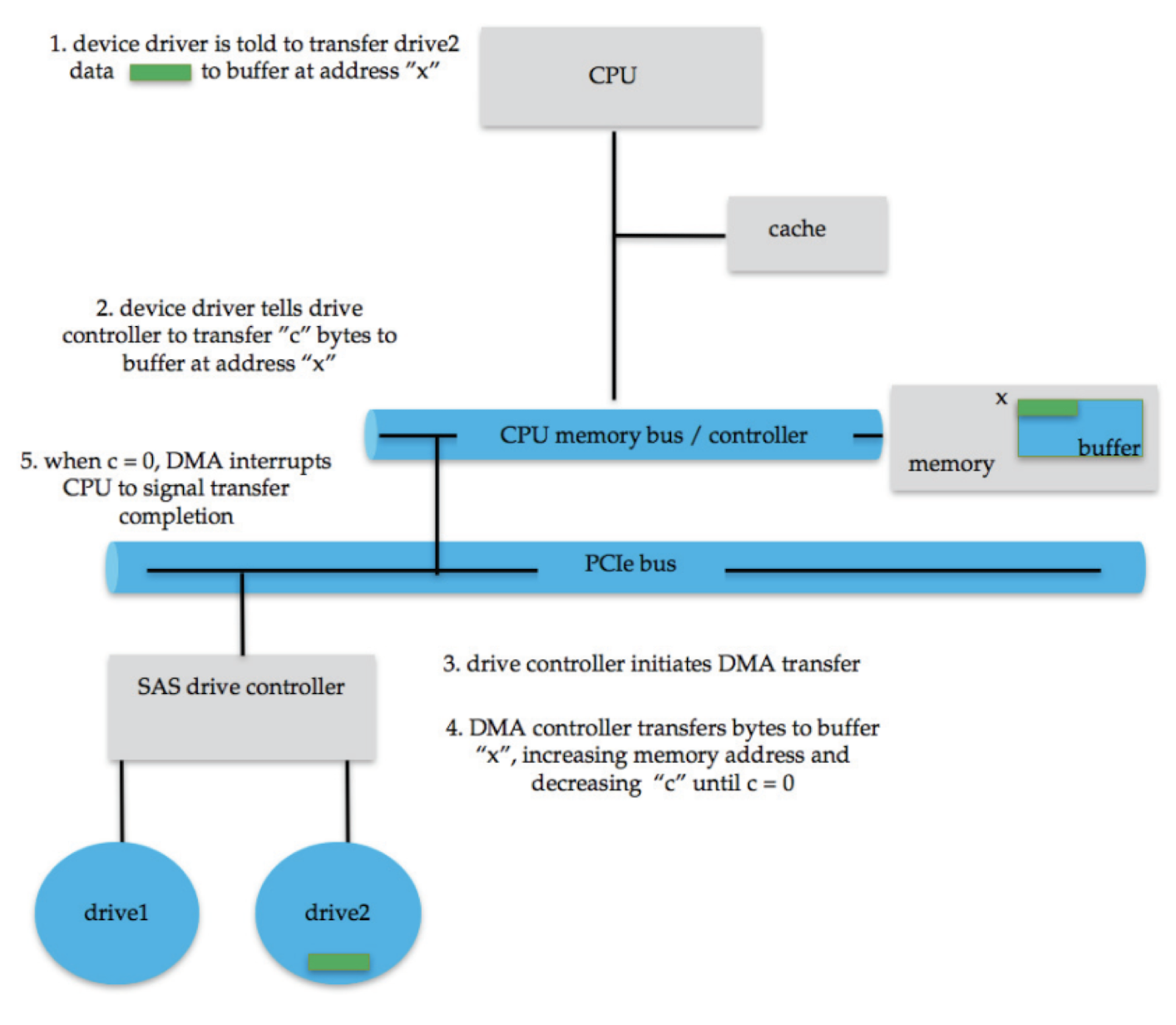
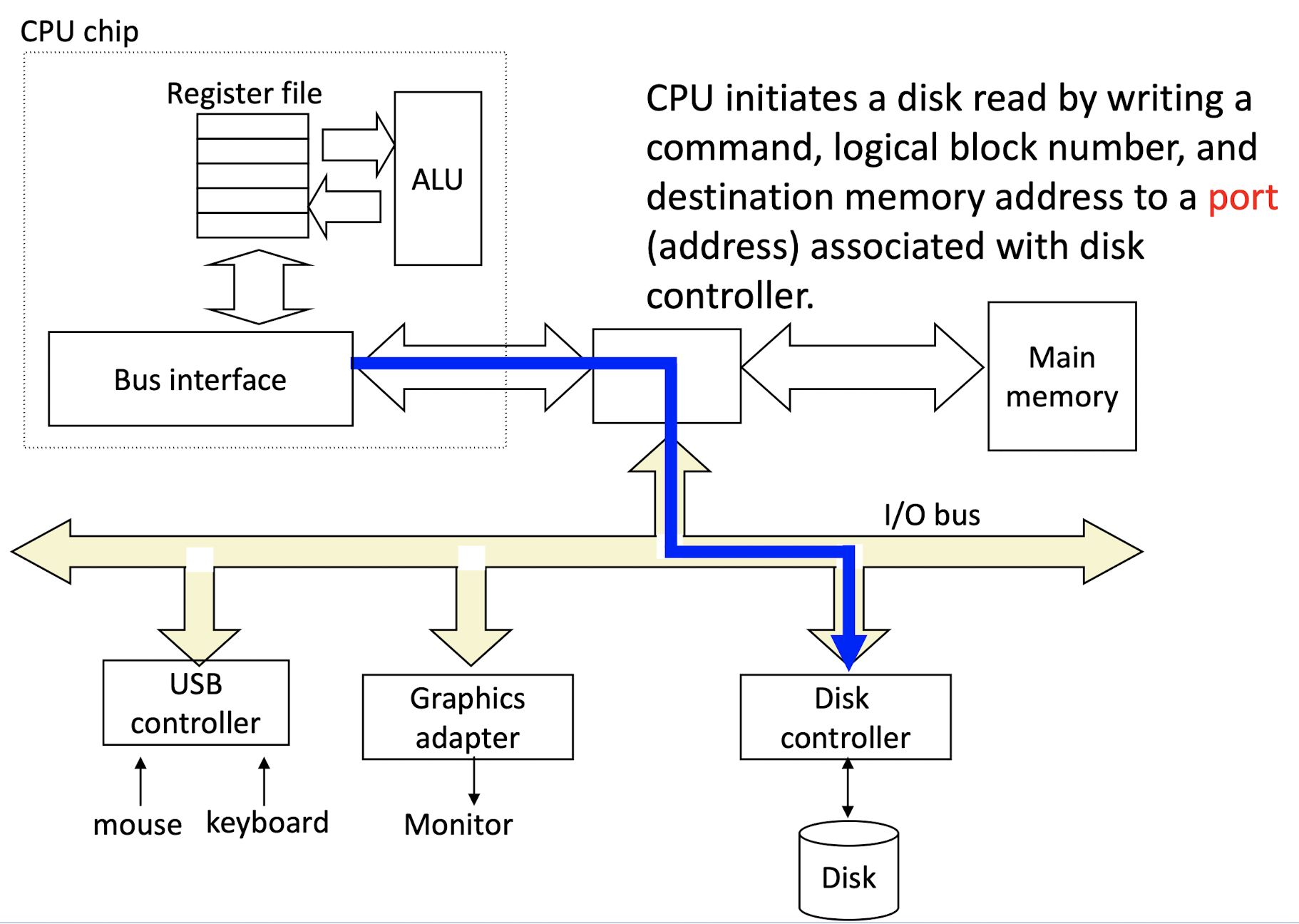
1.CPU sends signal about the address in Disk, and the destination memory address.
2.Disk sends data to main memory.
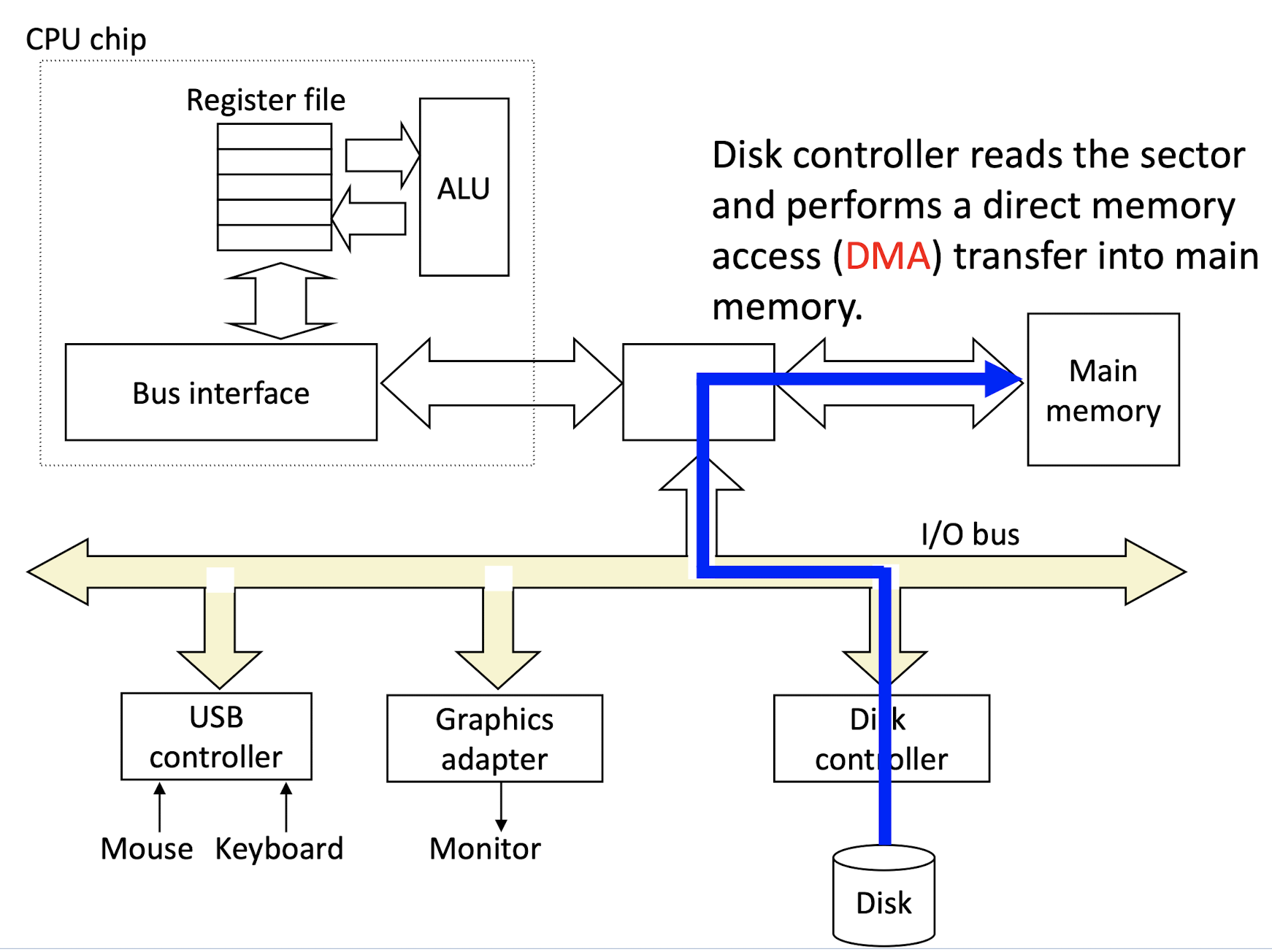
3.Disk sends interrupt to CPU to indicate thr transfer is complete.
8.3 Unix I/O Overview
- A file (in Unix/Linux) is a sequence of
mbytes; - All I/O devices are represented as files.
Regular Files
Used to store data
- Text files: with only ASCII or Unicode characters;
- sequence of chars terminated by newline char (‘
\n’)- Newline is
0xa, same as ASCII line feed character (LF)- End of line (EOL) indicators
- Linux and Mac OS: ‘
\n’ (0xa), line feed (LF)- Windows & Internet protocols: ‘
\r\n’ (0xd 0xa), Carriage return (CR) followed by line feed (LF)
- Binary files: are everything else, e.g., object files, JPEG images
Directories
Directory consists of an array of links, Each link maps a filename to a file
.(dot) is a link to itself..(dot dot) is a link to the parent directory in the directory hierarchymkdir: create empty directoryls: view directory contentsrmdir: delete empty directory
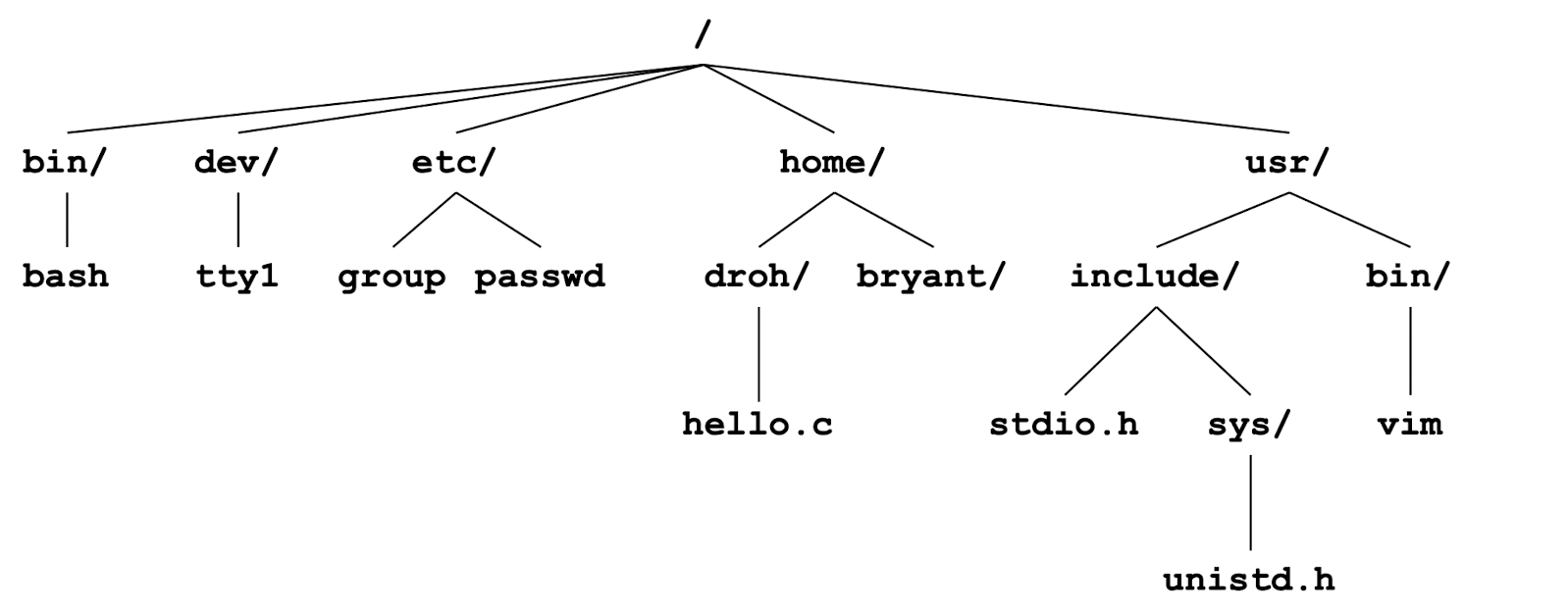
Directory Hierarchy:
All files are organized as a hierarchy anchored by root directory named
/(slash)
cd: Modified current working directory (for Change Directory).
Pathnames:
- Absolute pathname starts with ‘/’ and denotes path from root
/home/droh/hello.c
- Relative pathname denotes path from current working directory
../droh/hello.c
9 Network Programming
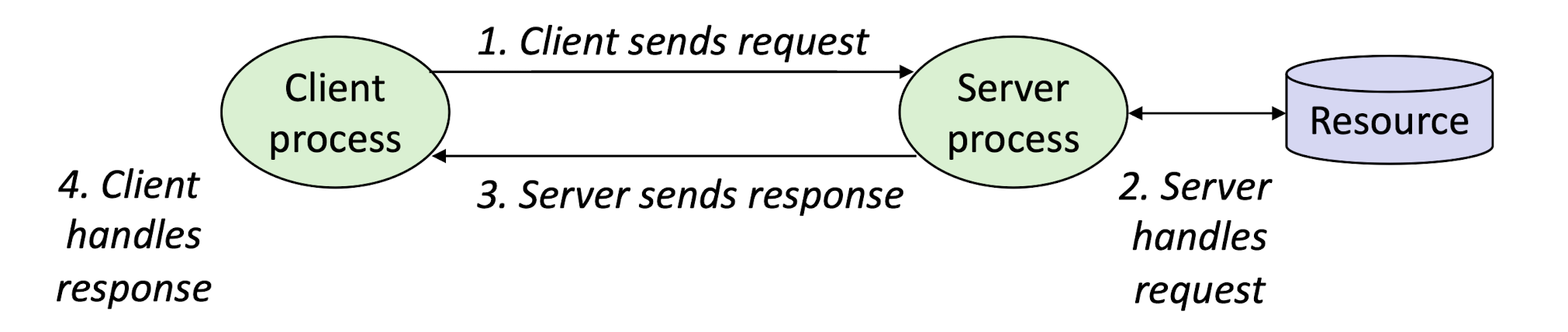
9.1 Client-Server Transaction
Server:
- process multiple client processes
- manages some resource and provides service to clients
- activated by request from client
Clients and servers are processes running on the same or different hosts.
9.2 Computer Networks
A network is a hierarchical system of boxes and wires organized by geographical proximity
SAN (System Area Network) spans cluster or machine room
LAN (Local Area Network) spans a building or campus
WAN (Wide Area Network) spans country or world
An internetwork (internet) is an interconnected set of
networks
The Global IP Internet (uppercase “I”) is the most famous example of an internet (lowercase “i”)
9.3 LAN & internet
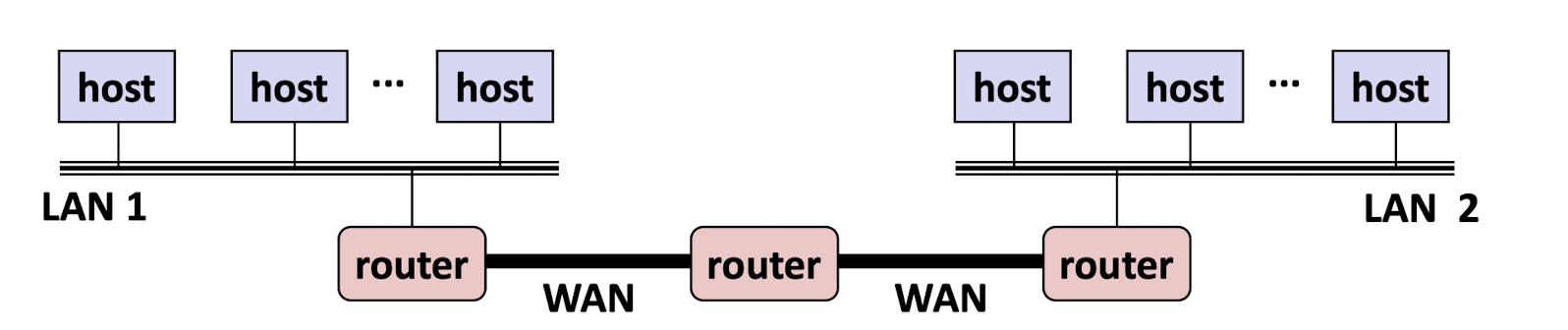
LAN: A collection of hosts attached to a single wire
internet: multiple LANs connected by routers
9.4 Logical Structure of an internet
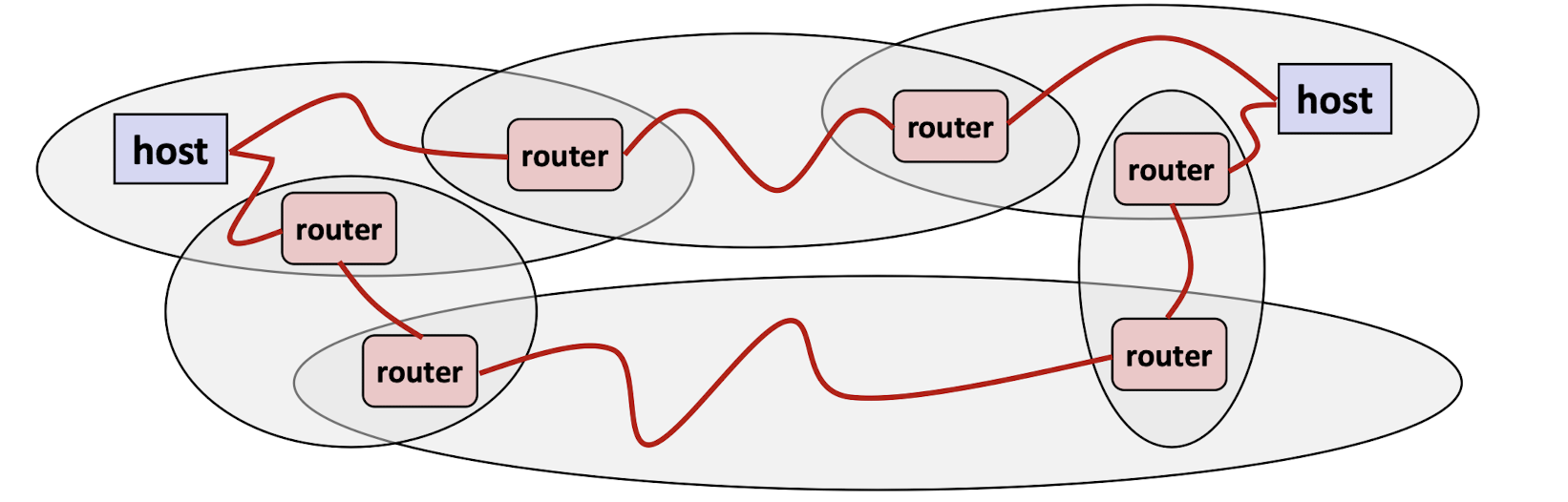
Ad hoc interconnection of networks
No particular topology;
Different packets may take different routes
9.5 IP address
To locate a computer in the network
MAC address
Each network interface has a unique MAC address;
hardcoded when the interface hardware is produced, can not be changed, like our ID card.IP address
Each computer is assigned an IP address, configurable, can be changed, like home address
The MAC address is bind with an IP address when your computer is connected to
some network, IP address can be different when you connect to different network.
IPv4: IP address is a 32-bit integerIPv6: IP address is a 128-bit integer
9.6 Domain
Human-friendly structured string of IP addresses;
- apollo.comp.polyu.edu.hk $\to$ 158.132.xxx.xxx
Mapping between domain names and IP addresses are stored on domain name servers, mapping service is provided by these servers.
9.7 Port number
a port number is used to uniquely identify a process on the computer;

9.8 Send Bits Across Incompatible LANs and WANs
Solution: an internet protocol running on hosts and routers
Protocol is a set of rules that governs how hosts and routers should
cooperate when they transfer data from network to networkdelivery mechanism
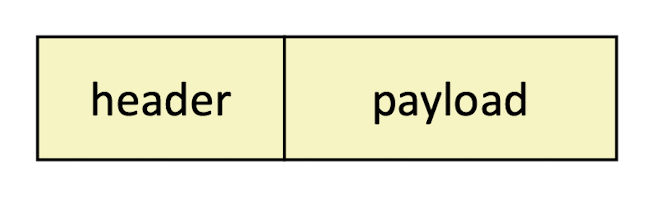
defines a standard transfer unit (packet)
Packet consists ofheaderandpayloadHeader: contains info such as packet size, source and destination addressesPayload: contains data bits sent from source host
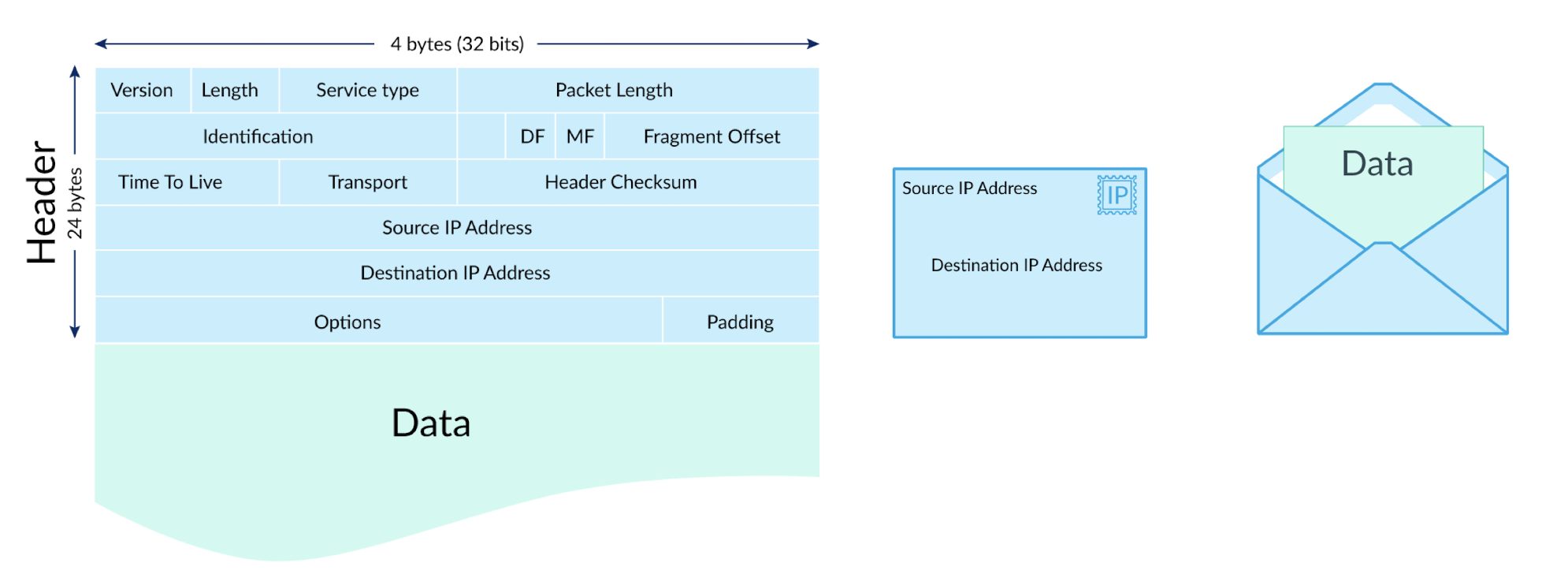
- Headers
- Pre-defined data structure containing important information for the data to be transmitted in the network, such as IP addresses, packet length, etc.
- Payload
- The data, usually a specified number of bytes
- To transmit large data, trunk them into smaller packets
References
B. Randal, D. R. O’Hallaron, Computer systems : a programmer’s perspective, Third edition. Boston: Pearson, 2016.
Slides of COMP1411 Introduction to Computer Systems, The Hong Kong Polytechnic University.
个人笔记,仅供参考,转载请标明出处
FOR REFERENCE ONLY
Made by Mike_Zhang