R学习1-基础
Made by Mike_Zhang
所有文章:
R学习1-基础
R学习2-I/O
R学习3-Vector List Matrix
R学习4-Data Frame
R学习5-Graphics
1 R Start
R: The R Project for Statistical Computing官网地址: https://www.r-project.org/
- 进入网站后点击 CRAN;
- 选择对应地区的mirror,如:TUNA Team, Tsinghua University
- 下载对应系统的安装包并安装。
- 打开R应用,显示R Console界面,如下图:
输入命令后按下回车,测试如下:1
2> 1+1
[1] 2
在R中,输出的结果为向量(Vector),上述例子中结果为只有一个元素向量,因此结果2被标记为[1],指向量的第一个元素。
2 Print Out
在输入完命令后按下回车,R会自动调用print()方法来输出结果在console中,用户也可以使用print()或者cat()方法来输出。
2.1 print()
如下:1
2
3
4> print(2^2)
[1] 4
> print(pi)
[1] 3.141593
但是print()方法有限制,其一次只能输出一个对象,不支持同时输出多个对象,如下:
1 | |
如要输出多个对象,则可以使用多个print()语句,并用分号(;)隔开:
1 | |
另一种方法就是使用cat()方法。
2.2 cat()
1 | |
此方法可以把多个对象结合起来连续输出,注意cat()方法输出时默认用空格隔开每个对象,并不是换行符(\n), 因此建议在此输出方法末尾加上换行符(\n)。
3 Variables
3.1 Assignment
- 变量赋值符:
<-(由一个less-than character<和 hyphen-连接而成,中间无空格)
如:
1 | |
变量无需定义即可赋值
- 强变量赋值符:
<<-
如:
1 | |
此符号把变量值赋值给一个全局变量(global variable),而不是局部变量(local variable)
注意:
=和->符号也支持变量的赋值,但是并不推荐使用,前者容易和比较符产生歧义,后者在表达式过长时不便于阅读。
3.2 List Variables
使用ls()或ls.str()方法来列出目前工作区定义了那些变量和方法。
3.2.1 ls()
1 | |
此方法会返回一个字符串向量,包含了定义的变量名和方法名。
若工作区内没有定义的变量名或者方法名,则:
1 | |
3.2.2 ls.str()
1 | |
此方法除返回名字外,也会返回变量的值。
但是ls()方法不会返回名字以点(.)开头的变量,如:
1 | |
如需要返回所有变量,则需要设置ls()的all.name参数为TRUE,如下:
1 | |
3.3 Remove Variables
rm()方法可以从工作区移除不需要的变量或者方法,如下:
1 | |
变量或方法一旦被移除,则不可以撤回。
也可以设置rm()方法的list参数为ls(),则可以移除整个工作区的变量以及方法,如下:
1 | |
注意!
谨慎使用rm(list=ls())方法。
不要在分享给他人的R文件中使用此方法,会有删除全部内容的风险!
4 Vector Creation
向量(Vector)是R的核心组成部分,其可以包含数字,字符串,逻辑值,但不可以是混合体。
使用c(...)语句可以初始化一个向量,如下:
1 | |
也可以通过此语句合并两个向量,组成一个新的向量,如:
1 | |
若用户尝试合并两个不同类型的向量,则R会尝试把它们转换成相同类型的向量,如下:
1 | |
上面例子中,R就把numeric的123转换成了character类型。
使用mode()方法可以查看变量的类型,如下:
1 | |
5 Basic Statistics
R中一些基础的数据分析方法:
mean():计算均值median():计算中位数sd():计算标准差var():计算方差
如下:
1 | |
若数据中出现了NA(not available),可能会造成方法返回NA,如下:
1 | |
可以设置上述几个方法的na.rm属性为TRUE,以让R忽略NA,如下:
1 | |
6 Sequences
6.1 n:m expression
1 | |
此方法的步长只能为1或-1。
6.2 seq()function
此方法有三个参数,规定起点,终点以及步长,如下:
1 | |
或者可以规定序列的长度,R会自动计算出适合的步长,如下:
1 | |
小数也适用起点与终点。
6.3 rep()function
此方法会重复输出指明的值,并返回一个向量,如下:1
2
3
4
5
6> rep(2,5)
[1] 2 2 2 2 2
> rep(1,0)
numeric(0)
> rep(pi,3)
[1] 3.141593 3.141593 3.141593
7 Comparing
R中的比较符有==,!=,<,>,<=,>=,比较表达式返回TRUE或者FALSE。
可以进行单个值之间的比较,如下:
1 | |
也可以进行向量间的比较,返回一个布尔类型的向量,如下:
1 | |
也可以进行向量和单个值的比较,R会让单个值逐个和向量中的元素进行比较,返回一个布尔类型的向量,如下:
1 | |
any方法:
向量中存在任何一个TRUE就返回TRUE,如下:
1 | |
all方法:
向量中所有都为TRUE才返回TRUE,如下:
1 | |
8 Vector Elements
注意:
在R中,向量的下标从1开始,不是0!
v[x]1
2
3
4
5
6
7> v <-c(1,2,3,4,5,6,7,8,9,10)
> v[2]
[1] 2
> v[1]
[1] 1
> v[0]
numeric(0)v[n:m]
为闭区间,两端都包括。1
2
3
4> v[2:3]
[1] 2 3
> v[4:10]
[1] 4 5 6 7 8 9 10注意:
若想访问向量的第1位到第n+1位元素,应为v[1:(n+1)],并不是v[1:n+1]。
v[c(a,b,c,...)]
通过data vector访问。1
2
3
4> v[c(1,3,5)]
[1] 1 3 5
> v[c(1:6)]
[1] 1 2 3 4 5 6v[-x]
忽略某些元素。1
2
3
4
5
6> v[-1]
[1] 2 3 4 5 6 7 8 9 10
> v[-5]
[1] 1 2 3 4 6 7 8 9 10
> v[-(1:5)]
[1] 6 7 8 9 10v[x<y]
通过逻辑表达式选取,若TRUE则选取,若FALSE则忽略。1
2
3
4> v[v>5]
[1] 6 7 8 9 10
> v[v %% 2 == 1]
[1] 1 3 5 7 9names()
通过names()方法,给某一向量的元素加上names属性,并通过此属性访问到对应的值。1
2
3
4
5
6
7
8
9
10
11> value <- c(1,2,3)
> names(value) <- c('one','two','three')
> value
one two three
1 2 3
> value['one']
one
1
> value[c('one','three')]
one three
1 3
9 Operator Precedence

自上而下为高优先级至低优先级
10 Functions
R中有自定义函数,语法如下:
1 | |
例如:
1 | |
可以使用lapply()方法调用方法,如下:
1 | |
11 R Editor Window
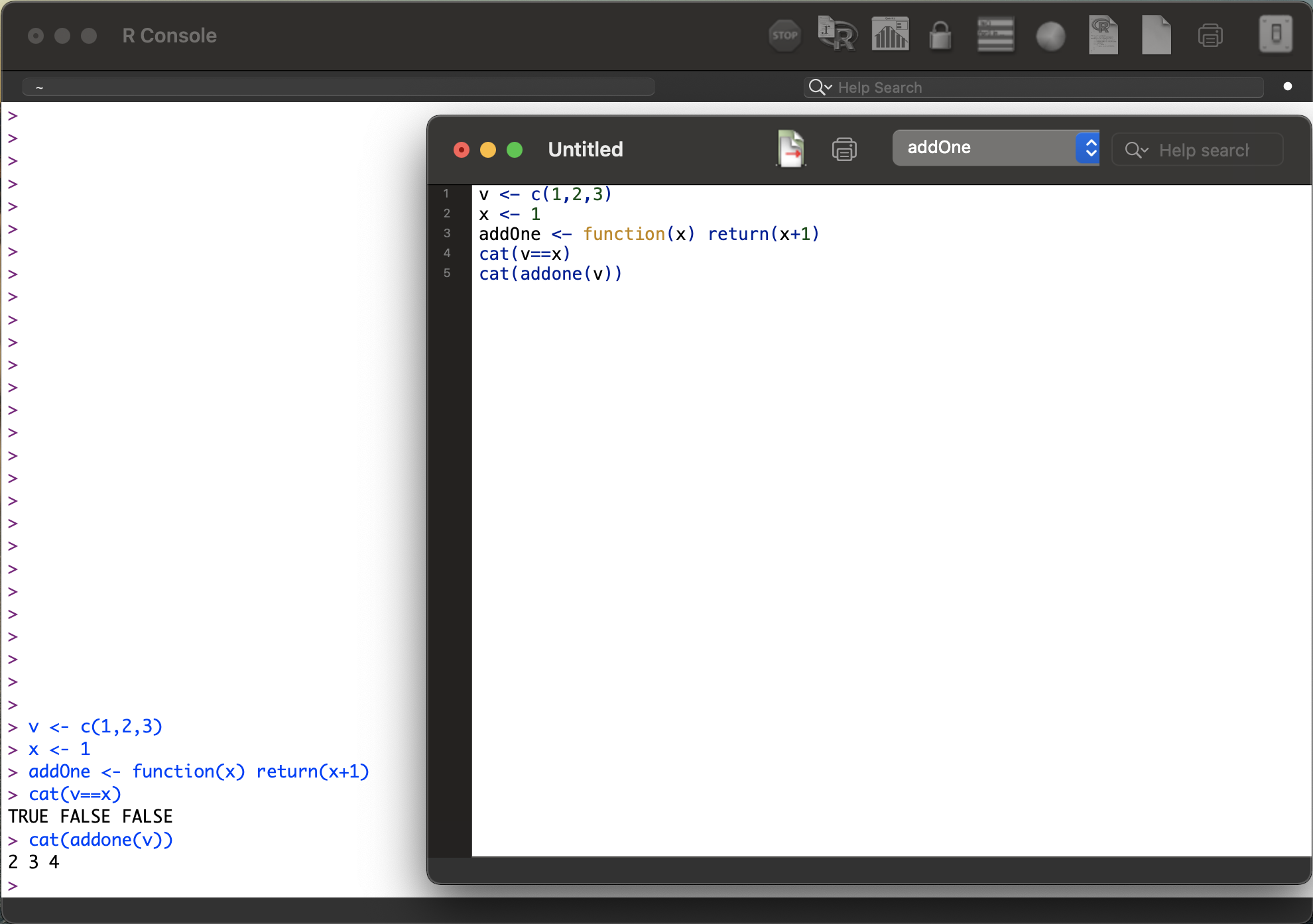
除了在R的console中编辑代码,也可以在编辑窗口中全部编写完成再运行,如下:
新建一个编辑窗口,输入全部代码;
鼠标放在某一行,按下cmd+enter,执行此行代码;
或选中某几行或全部代码,按下cmd+enter,执行选中的代码。
参考
P. Teetor, R Cookbook. Sebastopol: O’Reilly Media, Incorporated, 2011.
写在最后
初次接触R语言,相关的知识会继续学习,继续更新.
最后,希望大家一起交流,分享,指出问题,谢谢!
原创文章,转载请标明出处
Made by Mike_Zhang
